day30 操作系统介绍 进程的创建
理论知识
操作系统(多道系统)
操作系统简单介绍
#一 操作系统的作用:
1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口
2:管理、调度进程,并且将多个进程对硬件的竞争变得有序
#二 多道技术:
1.产生背景:针对单核,实现并发
ps:
现在的主机一般是多核,那么每个核都会利用多道技术
有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个
cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:如内存中同时有多道程序
3.时间上的复用:复用一个cpu的时间片
强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样
才能保证下次切换回来时,能基于上次切走的位置继续运行
多道程序系统(重点*****)
多道批处理系统
多道程序设计技术(特点:时空复用-->任务切换,记录状态)
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
空间的复用:将内存分为几部分,每个部分放入一个程序,这样,同一时间内存中就有了多道程序。
时间的复用—>遇到io操作就切换任务(宏观上(伪)并行,微观上串行)
分时系统
分时技术(分时间片工作,及时响应,但是效率降低)-->(宏观上(伪)并行,微观上串行)
分时技术(多道技术对时间的复用方式(遇到I/O操作才切换,对于没有I/O中断的程序会一直执行,其他的短作业程序也要一直等待着)并不合理,所以出现了分时技术(依照时间来回切换,雨露均沾)
分时技术(概念):把处理机的运行时间分成很短的时间片,按时间片轮流把处理机分配给各联机作业使用。
分时系统的主要目标:对用户响应的及时性,即不至于用户等待每一个命令的处理时间过长。
注意:分时系统的分时间片工作,在没有遇到IO操作的时候就用完了自己的时间片被切走了,这样的切换工作其实并没有提高cpu的效率,反而使得计算机的效率降低了。为什么下降了呢?因为CPU需要切换,并且记录每次切换程序执行到了哪里,以便下次再切换回来的时候能够继续之前的程序,虽然我们牺牲了一点效率,但是却实现了多个程序共同执行的效果,这样你就可以在计算机上一边听音乐一边聊qq了。
实时系统
虽然多道批处理系统和分时系统能获得较令人满意的资源利用率和系统响应时间,但却不能满足实时控制与实时信息处理两个应用领域的需求。于是就产生了实时系统,即系统能够及时响应随机发生的外部事件,并在严格的时间范围内完成对该事件的处理。
现在的应用:
分时——现在流行的PC,服务器都是采用这种运行模式,即把CPU的运行分成若干时间片分别处理不同的运算请求 linux系统
实时——一般用于单片机上、PLC等,比如电梯的上下控制中,对于按键等动作要求进行实时处理
通用操作系统
操作系统的三种基本类型:多道批处理系统、分时系统、实时系统。
通用操作系统:具有多种类型操作特征的操作系统。可以同时兼有多道批处理、分时、实时处理的功能,或其中两种以上的功能。
进程
什么是进程(动态产生,动态消亡的)
程序是指令、数据及其组织形式的描述,进程是程序的实体、是线程的容器。
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。


第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)(python的文件)、数据区域(data region)(python文件中定义的一些变量数据)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。 第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。[3] 进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上。
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征:进程由程序、数据和进程控制块三部分组成。
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。
而进程是程序在处理机上的一次执行过程,它是一个动态的概念。
程序可以作为一种软件资料长期存在,而进程是有一定生命期的。
程序是永久的,进程是暂时的。
举例:就像qq一样,qq是我们安装在自己电脑上的客户端程序,其实就是一堆的代码文件,我们不运行qq,那么他就是一堆代码程序,当我们运行qq的时候,这些代码运行起来,就成为一个进程了。
进程的调度
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
先来先服务调度算法
短作业优先调度算法
时间片轮转法
多级反馈队列
进程的并发与并行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真正干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
并发:伪并行(并行也属于并发),看着像同时运行,其实是任务之间的切换(遇到io切换的会提高代码效率) ,单个cpu+多道技术(多道技术是针对单核而言的)就可以实现并发-->任务切换+保存状态(保存现场)
并行:真正的同时在运行,应用的是多核技术(多个cpu)-->同时运行,只有具备多个cpu才能实现并行
同步\异步\阻塞\非阻塞(重点)
进程状态介绍
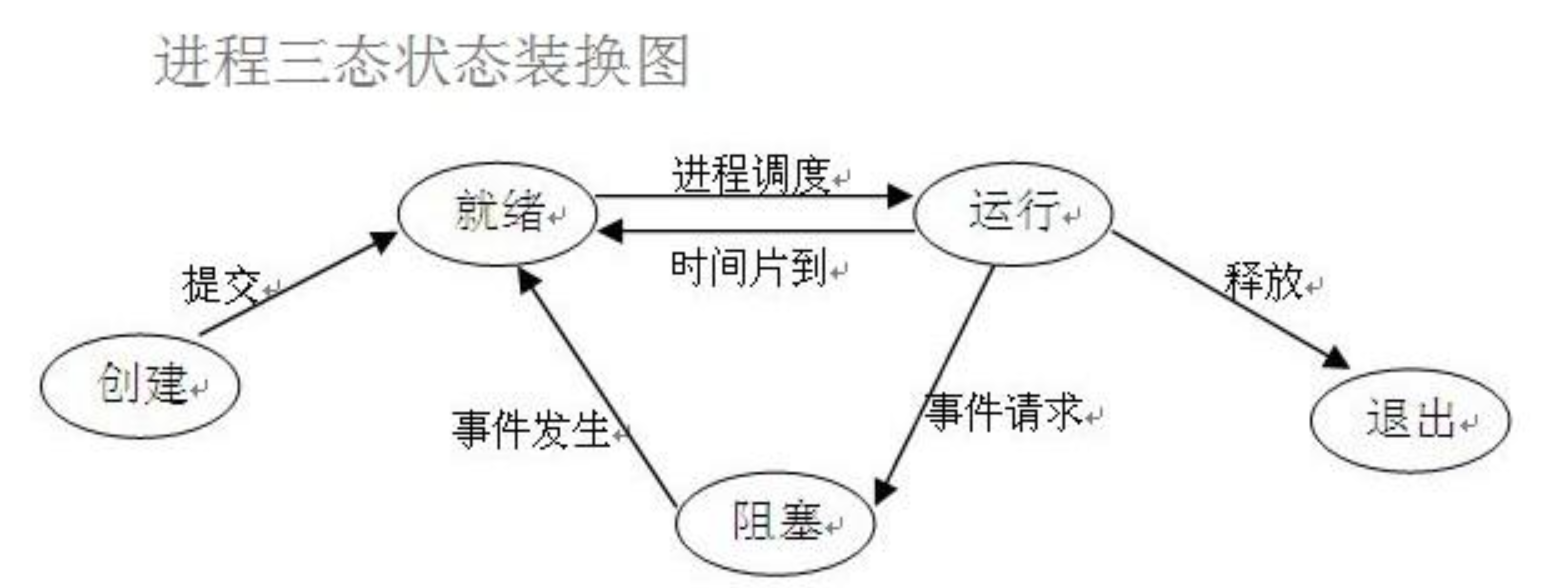
进程三状态:就绪(等待操作系统调度去cpu里面执行) 执行 阻塞
(1)就绪(Ready)状态 当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。 (2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。 (3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。 事件请求:input、sleep、文件输入输出、recv、accept等 事件发生:sleep、input等完成了 时间片到了之后有回到就绪状态,这三个状态不断的在转换。
同步和异步(同步==>串行 异步==>并行)(同步和异步是提交任务的方式)
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。其实就是一个程序结束才执行另外一个程序,串行的,不一定两个程序就有依赖关系。
所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
阻塞和非阻塞(阻塞非阻塞是任务的执行状态)
阻塞和非阻塞这两个概念与程序(线程)等待消息通知(无所谓同步或者异步)时的状态有关。也就是说阻塞与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的
同步\异步 与 阻塞\非阻塞
同步阻塞形式
异步阻塞形式
同步非阻塞形式
异步非阻塞形式
进程的创建、结束与并发的实现(了解)
不重要,省略了...
在python程序中的进程操作
multiprocessing模块
仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享。重点强调:进程没有任何共享状态,进程修改的数据,改动仅限于该进程内,但是通过一些特殊的方法,可以实现进程之间数据的共享。
process模块介绍
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 参数介绍: 1 group参数未使用,值始终为None 2 target表示调用对象,即子进程要执行的任务 3 args表示调用对象的位置参数元组,args=(1,2,'egon',) 4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} 5 name为子进程的名称 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号,Process(target=f1,args=(4,)) kwargs]指定的为传给target函数的关键字参数,是一个字典形式,Process(target=f1,kwargs={'n':4}) -->{'target的形参n作为key':值}
创建进程的两种方式
方式一:multiprocessing.Process
栗子:
#当前文件名称为test.py
from multiprocessing import Process
def func():
print(12345)
#windows 下才需要写这个,这和系统创建进程的机制有关系,不用深究,记着windows下要写就好啦
#首先我运行当前这个test.py文件,运行这个文件的程序,那么就产生了进程,这个进程我们称为主进程
if __name__ == '__main__':
#将函数注册到一个进程中,p是一个进程对象,此时还没有启动进程,只是创建了一个进程对象。并且func是不加括号的,因为加上括号这个函数就直接运行了对吧。
p = Process(target=func,)
#告诉操作系统,给我开启一个进程,func这个函数就被我们新开的这个进程执行了,而这个进程是我主进程运行过程中创建出来的,所以称这个新创建的进程为主进程的子进程,而主进程又可以称为这个新进程的父进程。
#而这个子进程中执行的程序,相当于将现在这个test.py文件中的程序copy到一个你看不到的python文件中去执行了,就相当于当前这个文件,被另外一个py文件import过去并执行了。
#start并不是直接就去执行了,我们知道进程有三个状态,进程会进入进程的三个状态,就绪,(被调度,也就是时间片切换到它的时候)执行,阻塞,并且在这个三个状态之间不断的转换,等待cpu执行时间片到了。
p.start()
#这是主进程的程序,上面开启的子进程的程序是和主进程的程序同时运行的,我们称为异步
print('*' * 10)
import time
from multiprocessing import Process
def f1():
time.sleep(3)
print('xxxx')
def f2():
time.sleep(3)
print('ssss')
# f1()
# f2()
#windows系统下必须写main,因为windows系统创建子进程的方式决定的,开启一个子进程,这个子进程 会copy一份主进程的所有代码,并且机制类似于import引入,这样就容易导致引入代码的时候,被引入的代码中的可执行程序被执行,导致递归开始进程,会报错
if __name__ == '__main__': #
p1 = Process(target=f1,)
p2 = Process(target=f2,)
p1.start()
p2.start()
if __name__ == '__main__':
看一个问题,说明linux和windows两个不同的操作系统创建进程的不同机制导致的不同结果:
#其实是因为windows开起进程的机制决定的,在linux下是不存在这个效果的,因为windows使用的是process方法来开启进程,他就会拿到主进程中的所有程序,而linux下只是去执行我子进程中注册的那个函数,不会执行别的程序,这也是为什么在windows下要加上执行程序的时候,要加上if __name__ == '__main__':,否则会出现子进程中运行的时候还开启子进程,那就出现无限循环的创建进程了,就报错了
类比
# file1.py 文件中的代码
def f1():
print('xxxx')
# f1() -->被import的时候会执行
if __name__ == '__main__':
f1() -->被import的时候不会执行
# file2.py 文件中的代码
import file1
同理
# file1.py 文件中的代码
def f1():
print('xxxx')
# p1 = Process(target=f1,) -->被创建(相当于被import)的时候会执行
# p1.start()
if __name__ == '__main__':
p1 = Process(target=f1,) -->被创建(相当于被import)的时候不会执行
p1.start()
# file2.py 文件中的代码
import file1
注意:在windows中Process()必须放到# if __name__ == '__main__':下(Linux可以不用)
Since Windows has no fork, the multiprocessing module starts a new Python process and imports the calling module. If Process() gets called upon import, then this sets off an infinite succession of new processes (or until your machine runs out of resources). This is the reason for hiding calls to Process() inside if __name__ == "__main__" since statements inside this if-statement will not get called upon import. 由于Windows没有fork,多处理模块启动一个新的Python进程并导入调用模块。 如果在导入时调用Process(),那么这将启动无限继承的新进程(或直到机器耗尽资源)。 这是隐藏对Process()内部调用的原,使用if __name__ == “__main __”,这个if语句中的语句将不会在导入时被调用。
join方法的例子:
让主进程加上join的地方等待(也就是阻塞住),等待子进程执行完之后,再继续往下执行我的主进程,好多时候,我们主进程需要子进程的执行结果,所以必须要等待。join感觉就像是将子进程和主进程拼接起来一样,将异步改为同步执行。
import time
from multiprocessing import Process
def f1(n):
time.sleep(2)
print('xxxx')
def f2(m):
time.sleep(2)
print('ssss')
# 情景1
if __name__ == '__main__':
p1 = Process(target=f1,args=(4,)) # args是元组,必须带逗号
p2 = Process(target=f2,kwargs={'m':4}) # kwargs这里的键必须写成目标函数f2的形参(字符串),否则报错
p1.start()
p2.start()
print('我是主进程!!!')
# 结果:瞬间打印 '我是主进程!!!',停顿2秒,再同时打印'xxxx'和'ssss'
# 情景2
if __name__ == '__main__':
p1 = Process(target=f1, args=(4,))
p2 = Process(target=f2,kwargs={'m': 4}) # kwargs这里的键必须写成目标函数f2的形参(字符串),否则报错
p1.start()
p2.start()
time.sleep(2)
print('我是主进程!!!')
# 结果:运行程序大概2秒后,几乎一起打印出三个的值
# xxxx
# ssss
# 我是主进程!!!
# 情景3
if __name__ == '__main__':
p1 = Process(target=f1, args=(4,))
p2 = Process(target=f2,kwargs={'m': 4}) # kwargs这里的键必须写成目标函数f2的形参(字符串),否则报错
p1.start()
p2.start()
p1.join() # 主进程等待子进程运行完才继续执行
p2.join()
print('我要等了...等我的子进程...')
print('我是主进程!!!')
# 结果:运行程序大概2秒后,几乎一起打印出所有的值(因为调用start就已经执行完拿到结果了)
# ssss
# xxxx
# 我要等了...等我的子进程...
# 我是主进程!!!
# 情景4
if __name__ == '__main__':
p1 = Process(target=f1,args=(4,))
p1.start()
p1.join() # 主进程等待子进程运行完才继续执行
print('开始p2拉')
p2 = Process(target=f2,kwargs={'m':4}) # kwargs这里的键必须写成目标函数f2的形参(字符串),否则报错
p2.start()
p2.join()
print('我要等了...等我的子进程...')
print('我是主进程!!!')
# 结果:等待2秒,前两个一起打印出来,再等待2秒,后3个一起打印出来
# xxxx
# 开始p2拉
# ssss
# 我要等了...等我的子进程...
# 我是主进程!!!
综上,join感觉就像是将子进程和(离他最近的)主进程拼接起来一样,将异步改为同步执行。
for循环开启多个进程
栗子
import time
from multiprocessing import Process
def f1(i):
# time.sleep(3)
print(i)
if __name__ == '__main__':
for i in range(20):
p1 = Process(target=f1,args=(i,))
p1.start()
结果:打印20个(0~19)数字,是乱序的.这是因为代码是CPU执行的,运行速度很快,瞬间就将代码执行完了,告诉操作系统我要创建20个进程,操作系统来决定谁先被创建(就绪),谁先被执行(时间片轮转,IO切换,都是操作系统来决定顺序的,告诉CPU去执行)
需求:使用for循环开启多个子进程,并且所有的子进程异步执行,然后所有的子进程全部执行完之后,我再执行主进程,怎么搞?看代码(按照编号去看注释)
#下面的注释按照编号去看,别忘啦!
import time
import os
from multiprocessing import Process
def func(x,y):
print(x)
# time.sleep(1) #进程切换:如果没有这个时间间隔,那么你会发现func执行结果是打印一个x然后一个y,再打印一个x一个y,不会出现打印多个x然后打印y的情况,因为两个打印距离太近了而且执行的也非常快,但是如果你这段程序运行慢的话,你就会发现进程之间的切换了。
print(y)
if __name__ == '__main__':
p_list= []
for i in range(10):
p = Process(target=func,args=('姑娘%s'%i,'来玩啊!'))
p_list.append(p)
p.start()
[ap.join() for ap in p_list] #4、这是解决办法,前提是我们的子进程全部都已经去执行了,那么我在一次给所有正在执行的子进程加上join,那么主进程就需要等着所有子进程执行结束才会继续执行自己的程序了,并且保障了所有子进程是异步执行的。
# p.join() #1、如果加到for循环里面,那么所有子进程包括父进程就全部变为同步了,因为for循环也是主进程的,循环第一次的时候,一个进程去执行了,然后这个进程就join住了,那么for循环就不会继续执行了,等着第一个子进程执行结束才会继续执行for循环去创建第二个子进程。
#2、如果我不想这样的,也就是我想所有的子进程是异步的,然后所有的子进程执行完了再执行主进程
#p.join() #3、如果这样写的话,多次运行之后,你会发现会出现主进程的程序比一些子进程先执行完,因为我们p.join()是对最后一个子进程进行了join,也就是说如果这最后一个子进程先于其他子进程执行完,那么主进程就会去执行,而此时如果还有一些子进程没有执行完,而主进程执行
#完了,那么就会先打印主进程的内容了,这个cpu调度进程的机制有关系,因为我们的电脑可能只有4个cpu,我的子进程加上住进程有11个,虽然我for循环是按顺序起进程的,但是操作系统一定会按照顺序给你执行你的进程吗,答案是不会的,操作系统会按照自己的算法来分配进
#程给cpu去执行,这里也解释了我们打印出来的子进程中的内容也是没有固定顺序的原因,因为打印结果也需要调用cpu,可以理解成进程在争抢cpu,如果同学你想问这是什么算法,这就要去研究操作系统啦。那我们的想所有子进程异步执行,然后再执行主进程的这个需求怎么解决啊
print('不要钱~~~~~~~~~~~~~~~~!')
方式二:自定义类,继承Process
栗子:
from multiprocessing import Process
class MyProcess(Process):# 自定义类,继承Process
def __init__(self,n): # 传参
super().__init__() #别忘了执行父类的init,等价于在__init__的括号中列出父类中的实例变量并绑定到自己的对象
self.n = n
def run(self): # 必须要重写的
print('宝宝and%s不可告人的事情'%self.n)
if __name__ == '__main__':
p1 = MyProcess('高望')
p1.start()
class MyProcess(Process): #自己写一个类,继承Process类
#我们通过init方法可以传参数,如果只写一个run方法,那么没法传参数,因为创建对象的是传参就是在init方法里面,面向对象的时候,我们是不是学过
def __init__(self,person):
super().__init__()
self.person=person
def run(self):
print(os.getpid())
print(self.pid)
print(self.pid)
print('%s 正在和女主播聊天' %self.person)
# def start(self):
# #如果你非要写一个start方法,可以这样写,并且在run方法前后,可以写一些其他的逻辑
# self.run()
if __name__ == '__main__':
p1=MyProcess('Jedan')
p2=MyProcess('太白')
p3=MyProcess('alexDSB')
p1.start() #start内部会自动调用run方法
p2.start()
# p2.run()
p3.start()
p1.join()
p2.join()
p3.join()
两种传参方式
进程的创建方式有两种,相对应的传参方式也是两种.
演示两种传参方式(对应着进程的两种创建方式)
# 演示两种传参方式(对应着进程的两种创建方式)
# 进程的创建方式1,传参方式1
from multiprocessing import Process
def f1(n): # 通过目标函数传参
print(n)
if __name__ == '__main__':
# p1 = Process(target=f1,args=('大力与奇迹',)) #创建进程对象,并传参
p1 = Process(target=f1,kwargs={'n':'大力'}) #创建进程对象,并传参
p1.start() #给操作系统发送了一个创建进程的信号,后续进程的创建都是操作系统的事儿了
# 进程的创建方式2,传参方式2
from multiprocessing import Process
class MyProcess(Process):
def __init__(self,n): # 通过自定义类的__init__传参
super().__init__() #别忘了执行父类的init
self.n = n
def run(self):
print('宝宝and%s不可告人的事情'%self.n)
if __name__ == '__main__':
p1 = MyProcess('高望')
p1.start()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号