nosql的衍生与数据库的拆分
nosql简单介绍
Redis:开源、免费、非关系型数据库、K-V数据库、内存数据库,支持持久化、事务和备份,集群(支持16个库)等高可用功能。并且性能极高(可以达到100000+的QPS),易扩展,丰富的数据类型,所有操作都是单线程,原子性的。
SQL:关系型数据库,表与表之间建立关联关系
nosql:非关系型数据库,数据与数据之间没有关联关系。就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题
nosql类型:
- 键值(key-value)存储数据库
- 列存储数据库:键仍然存在,但是指向了多个列,HBase (eg:博客平台(标签和文章),日志)
- 文档型数据库 MongoDb (eg:淘宝商品的评价)
- 图形数据库 Neo4j (eg:好友列表)
扩展:
MongoDB是一个基于分布式文件存储的数据库。有C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系型数据库和非关系型数据库之间的产品,是非关系数据库当中功能最丰富,最像关系型数据库的。
文档(document)是MongoDB中数据的基本单元,非常类似于关系型数据库系统中的行(但是比行要复杂的多);
集合(collection)就是一组文档,如果说MongoDB中的文档类似于关系型数据库中的行,那么集合就如同表;
使用场景:
- 数据模型比较简单
- 需要灵活更强的IT系统
- 对数据库性能要求比较高
- 不需要高度的数据一致性
- 对于给定的key,比较容易映射复杂值的环境
数据库的拆分逻辑
数据拆分前其实是要首先做准备工作的,然后才是开始数据拆分
第一步:采用分布式缓存redis、memcached等降低对数据库的读操作。
第二步:如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读、写分离原则。
第三步:当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
数据库拆分原则:就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
数据库拆分步骤:
-
第一步,首选垂直拆分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面 。比如淘宝中期开始的数据库端按照业务垂直拆分:按照业务交易数据库、用户数据库、商品数据库、店铺数据库等进行拆分。
采用垂直拆分优点:
- 拆分后业务清晰,拆分规则明确。
- 系统之间整合或扩展容易。
- 数据维护简单。
缺点:
- 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
- 事务处理复杂。
-
第二步:其次才是水平拆分(即口语当中的 分库分表)
水平拆分的典型场景就是大家熟知的分库分表。
垂直拆分后遇到单机瓶颈,可以使用水平拆分。
垂直拆分
垂直拆分是把不同的表拆到不同的数据库中。
数据库垂直拆分(按照功能模块拆分)
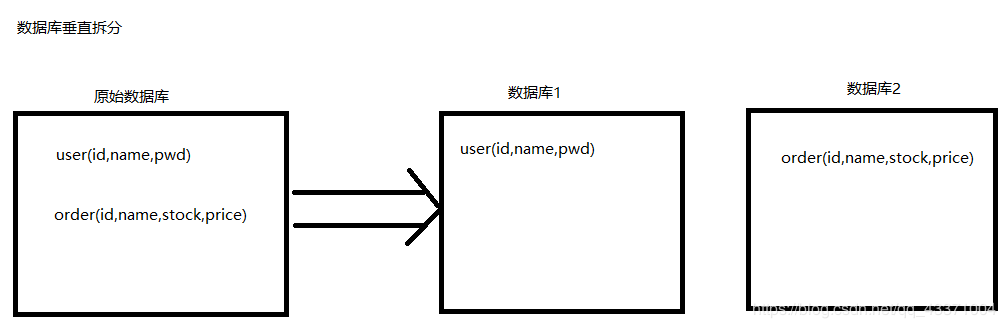
数据库表的垂直拆分
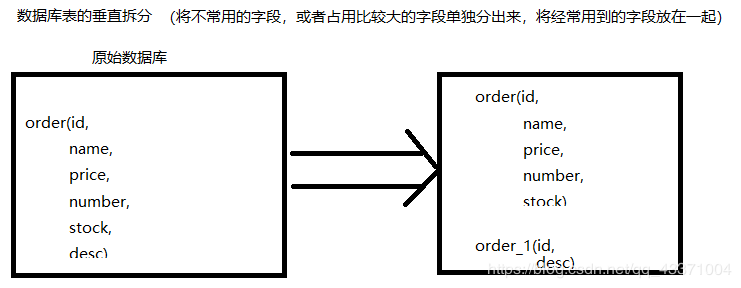
水平拆分
而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。
简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他
数据库水平拆分(根据某种规则划分,比如对id取余)
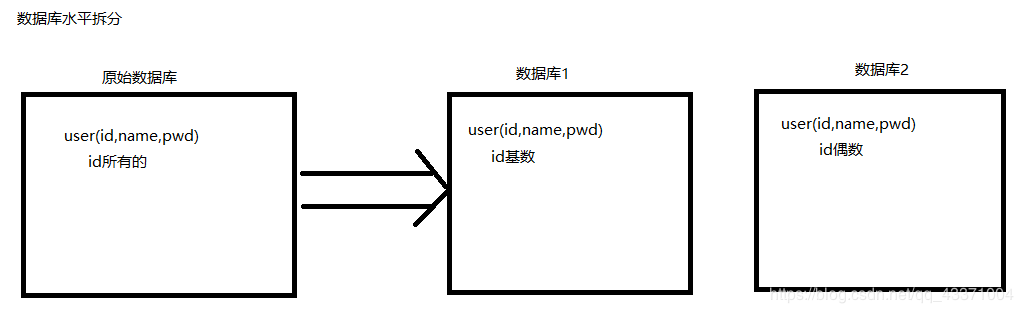
数据库表的水平拆分

小结:
1.优先考虑缓存降低对数据库的读操作。
2.再考虑读写分离,降低数据库写操作。
3.最后开始数据拆分,切分模式: 首先垂直(纵向)拆分、再次水平拆分。
4.首先考虑按照业务垂直拆分。
5.再考虑水平拆分:先分库(设置数据路由规则,把数据分配到不同的库中)
6.最后再考虑分表,单表拆分到数据1000万以内。
为什么使用NOSQL?
单机 MySQL 的美好时代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。
在那个时候,更多的都是静态网页,动态交互类型的网站不多。

DAL : Data Access Layer(数据访问层 – Hibernate,MyBatis)
上述架构下,我们来看看数据存储的瓶颈是什么?
- 数据量的总大小一个机器放不下时。
- 数据的索引(B+ Tree)一个机器的内存放不下时。
- 访问量(读写混合)一个实例不能承受。
Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。
开始比较流行的是通过文件缓存(×)来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。

Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。
Mysql的master-slave模式成为这个时候的网站标配了。
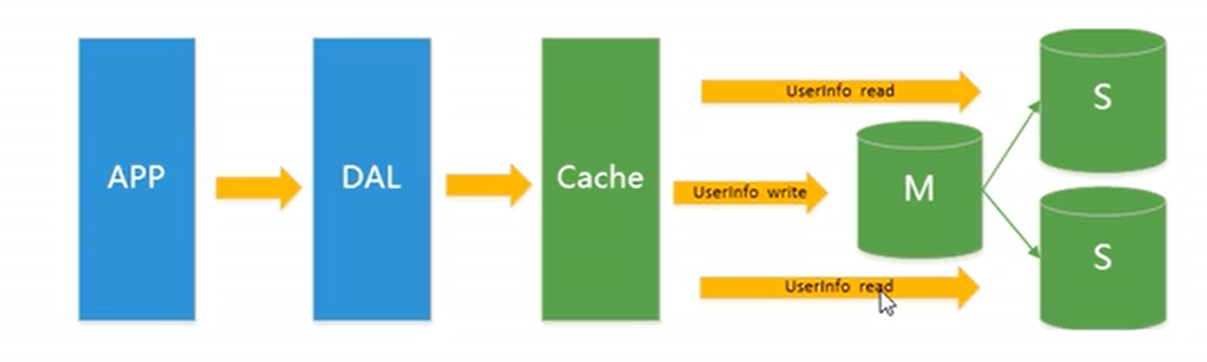
分库分表/水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈。
由于数据量的持续猛增,由于MyISAM在写数据的时候会使用表锁,在高并发写数据的情况下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
ps:这就是为什么 MySQL 在 5.6 版本之后使用 InnoDB 做为默认存储引擎的原因 – MyISAM 写会锁表,InnoDB 有行锁,,并且是事务优先,发生冲突的几率低,并发性能高。
四种NoSQL对比


 浙公网安备 33010602011771号
浙公网安备 33010602011771号