基于kubeasz部署高可用kubernetes集群 (K8S学习-day2)
基于kubeasz部署高可用kubernetes集群
K8S高可用集群环境规划
单节点(master)部署

多节点高可用部署
在生产环境中,为了保证系统的稳定性、可用性以及可扩展性,K8S集群一般需要高可用进行部署(二进制程序),主要是指master节点和etcd节点的高可用,用于实现冗余。如果基于单点部署,一旦硬件或者虚拟主机出现故障,maser节点宕机,导致node节点无法和API server进行交互,不能实时报告状态,会导致K8S系统出现大量报错以及pod宕机无法自动修复等,从而影响业务。
在多master节点的集群环境中,为了解除耦合关系,node节点的kubelet和kube-proxy不会直接去连接master的API server,而是去连接负载均衡器(中间层,使用VIP通信),一般是haproxy(双机部署,keepalived做高可用),负载均衡器会对后端master定时进行健康检测,一旦有master节点异常,负载均衡器会将其踢出,不会将请求发往故障master,这样master节点的增加或减少不会影响node节点
在生产环境中,为了实现集群节点元数据存储的高可用和高性能,一般etcd节点会部署至少3台(推荐3台,如果太多会导致写放大),同时存储设备类型使用SSD存储,并且分布在不同的区域(例如机房的不同机柜),以达到相对高可用的目的。

服务器统计
| 类型 | IP规划 | 备注 |
|---|---|---|
| Ansible部署服务器(1台) | 192.168.100.111/24 | K8S集群部署服务器 |
| K8S master(3台) | 192.168.100.101-103/24 | K8S集群控制服务器,通过一个VIP做主备高可用 |
| Harbor镜像仓库(2台) | 192.168.100.104-105/24 | 高可用镜像服务器 |
| etcd(3台) | 192.168.100.106-108/24 | 高可用etcd服务器,为K8S集群存储元数据 |
| Haproxy负载均衡器(2台) | 192.168.100.109-110/24 | 高可用代理服务器,后端是多个master节点 |
| K8S node节点(3台) | 192.168.100.121-123/24 | 真正运行容器的服务器 |
服务器准备
注意,必须保证集群中每个主机的主机名都不同,否则node节点的kube-proxy无法获取到IP地址导致工作异常
如果是克隆的虚拟机,尽量保证集群每台主机的machinepid唯一,建议进行以下操作:
# rm -rf /etc/machine-id && dbus-uuidgen --ensure=/etc/machine-id && cat /etc/machine-id
服务器清单:
| 类型 | IP地址 | 主机名 | VIP地址 |
|---|---|---|---|
| K8S master1 | 192.168.100.101/24 | K8S-master01.test.cn | 192.168.100.188 |
| K8S master2 | 192.168.100.102/24 | K8S-master02.test.cn | 192.168.100.188 |
| K8S master3 | 192.168.100.103/24 | K8S-master03.test.cn | 192.168.100.188 |
| Harbor1 | 192.168.100.104/24 | K8S-harbor01.test.cn | |
| Harbor2 | 192.168.100.105/24 | K8S-harbor02.test.cn | |
| etcd节点1 | 192.168.100.106/24 | K8S-etcd01.test.cn | |
| etcd节点2 | 192.168.100.107/24 | K8S-etcd02.test.cn | |
| etcd节点3 | 192.168.100.108/24 | K8S-etcd03.test.cn | |
| Haproxy负载均衡器1 | 192.168.100.109/24 | K8S-ha01.test.cn | |
| Haproxy负载均衡器2 | 192.168.100.110/24 | K8S-ha02.test.cn | |
| K8S node节点1 | 192.168.100.121/24 | K8S-node01.test.cn | |
| K8S node节点2 | 192.168.100.122/24 | K8S-node02.test.cn | |
| K8S node节点3 | 192.168.100.123/24 | K8S-node03.test.cn | |
| K8S 部署节点(ansible) | 192.168.100.111/24 | K8S-deploy.test.cn |
集群网络规划:
| 类型 | 网络地址规划 |
|---|---|
| 物理机内网 | 192.168.100.0/24 |
| Pod | 10.200.0.0/16 |
| service | 10.100.0.0/16 |
K8S集群软件列表:
| 类型 | 版本 |
|---|---|
| 操作系统 | Ubuntu 22.04 LTS |
| kubeasz | 3.5.2 |
| K8S | 1.26.1/1.26.4 |
| calico | 3.24.5 |
| harbor | 2.5.6 |
基础环境准备
系统基础配置优化
主机名、 iptables、防⽕墙、内核参数与资源限制等系统配置
高可用负载均衡器(haproxy)ALB配置
apt安装软件包,生产环境可根据需求使用二进制安装:
root@K8S-ha01:~# apt update
root@K8S-ha02:~# apt update
root@K8S-ha01:~# apt install keepalived haproxy -y
root@K8S-ha02:~# apt install keepalived haproxy -y
配置keepalived:
root@K8S-ha01:~# find / -name keepalived.conf*
root@K8S-ha01:~# cp /usr/share/doc/keepalived/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
root@K8S-ha01:~# vi /etc/keepalived/keepalived.conf #确保以下配置
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface eth0
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.100.188 dev eth0 label eth0:0
192.168.100.189 dev eth0 label eth0:1
192.168.100.190 dev eth0 label eth0:2
192.168.100.191 dev eth0 label eth0:3
}
}
root@K8S-ha01:~# scp /etc/keepalived/keepalived.conf root@192.168.100.110:/etc/keepalived/keepalived.conf
root@K8S-ha02:~# vi /etc/keepalived/keepalived.conf #确保以下配置
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.100.188 dev eth0 label eth0:0
192.168.100.189 dev eth0 label eth0:1
192.168.100.190 dev eth0 label eth0:2
192.168.100.191 dev eth0 label eth0:3
}
}
root@K8S-ha02:~# systemctl restart keepalived.service
root@K8S-ha02:~# systemctl enable keepalived
root@K8S-ha02:~# ifconfig #确保配置的VIP都启用
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.110 netmask 255.255.255.0 broadcast 192.168.100.255
inet6 fe80::250:56ff:fe3d:cfdc prefixlen 64 scopeid 0x20<link>
ether 00:50:56:3d:cf:dc txqueuelen 1000 (Ethernet)
RX packets 45428 bytes 62791468 (62.7 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 24016 bytes 1553689 (1.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.188 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:3d:cf:dc txqueuelen 1000 (Ethernet)
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.189 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:3d:cf:dc txqueuelen 1000 (Ethernet)
eth0:2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.190 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:3d:cf:dc txqueuelen 1000 (Ethernet)
eth0:3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.191 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:3d:cf:dc txqueuelen 1000 (Ethernet)
root@K8S-master01:~# ping 192.168.100.188 #确保在master上可以ping通VIP
PING 192.168.100.188 (192.168.100.188) 56(84) bytes of data.
64 bytes from 192.168.100.188: icmp_seq=1 ttl=64 time=0.956 ms
64 bytes from 192.168.100.188: icmp_seq=2 ttl=64 time=0.405 ms
64 bytes from 192.168.100.188: icmp_seq=3 ttl=64 time=0.520 ms
root@K8S-ha01:~# systemctl restart keepalived.service
root@K8S-ha01:~# systemctl enable keepalived
root@K8S-ha01:~# ifconfig #确保VIP可以漂过来
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.109 netmask 255.255.255.0 broadcast 192.168.100.255
inet6 fe80::250:56ff:fe2e:2d01 prefixlen 64 scopeid 0x20<link>
ether 00:50:56:2e:2d:01 txqueuelen 1000 (Ethernet)
RX packets 7666 bytes 4848463 (4.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5382 bytes 540429 (540.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.188 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:2e:2d:01 txqueuelen 1000 (Ethernet)
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.189 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:2e:2d:01 txqueuelen 1000 (Ethernet)
eth0:2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.190 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:2e:2d:01 txqueuelen 1000 (Ethernet)
eth0:3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.191 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:50:56:2e:2d:01 txqueuelen 1000 (Ethernet)
root@K8S-ha02:~# ifconfig #确保没有VIP,否则是脑裂现象
配置haproxy:
root@K8S-ha01:~# cp /etc/haproxy/haproxy.cfg{,.org}
root@K8S-ha02:~# cp /etc/haproxy/haproxy.cfg{,.org}
root@K8S-ha01:~# vi /etc/haproxy/haproxy.cfg #最后增加以下配置
listen k8s-master-6443 #队列名称,必须唯一
bind 192.168.100.188:6443
mode tcp
server server1 192.168.100.101:6443 check inter 2000 fall 3 rise 5 #健康检测,检测间隔2000ms,失败重试3次后踢出停止转发,连续检测5次成功后加入队列进行转发
server server2 192.168.100.102:6443 check inter 2000 fall 3 rise 5
server server3 192.168.100.103:6443 check inter 2000 fall 3 rise 5
root@K8S-ha01:~# systemctl restart haproxy.service
root@K8S-ha01:~# systemctl enable haproxy
root@K8S-ha01:~# netstat -lntp #确保6443端口监听
root@K8S-ha01:~# scp /etc/haproxy/haproxy.cfg root@192.168.100.110:/etc/haproxy/
root@K8S-ha02:~# systemctl restart haproxy.service #此时haproxy02无法启动,因为内核不允许监听本机没有的IP地址之上
Job for haproxy.service failed because the control process exited with error code.
See "systemctl status haproxy.service" and "journalctl -xeu haproxy.service" for details.
root@K8S-ha02:~# haproxy -f /etc/haproxy/haproxy.cfg #查看具体报错原因,无法绑定端口
[WARNING] (25356) : parsing [/etc/haproxy/haproxy.cfg:23] : 'option httplog' not usable with proxy 'k8s-master-6443' (needs 'mode http'). Falling back to 'option tcplog'.
[NOTICE] (25356) : haproxy version is 2.4.22-0ubuntu0.22.04.1
[NOTICE] (25356) : path to executable is /usr/sbin/haproxy
[ALERT] (25356) : Starting proxy k8s-master-6443: cannot bind socket (Cannot assign requested address) [192.168.100.188:6443]
[ALERT] (25356) : [haproxy.main()] Some protocols failed to start their listeners! Exiting.
root@K8S-ha02:~# sysctl -a|grep bind
net.ipv4.ip_autobind_reuse = 0
net.ipv4.ip_nonlocal_bind = 0 #此参数为1表示内核可以监听本机没有IP地址的套接字
net.ipv6.bindv6only = 0
net.ipv6.ip_nonlocal_bind = 0
root@K8S-ha02:~# echo 'net.ipv4.ip_nonlocal_bind = 1' >>/etc/sysctl.conf
root@K8S-ha02:~# sysctl -p
root@K8S-ha01:~# echo 'net.ipv4.ip_nonlocal_bind = 1' >>/etc/sysctl.conf
root@K8S-ha01:~# sysctl -p
root@K8S-ha02:~# systemctl restart haproxy.service #无报错
root@K8S-ha02:~# systemctl enable haproxy
root@K8S-ha02:~# netstat -lntp #确保6443的TCP端口监听
安装运⾏时并部署镜像仓库harbor
安装容器运行时
kubernetes master节点和node节点的容器运行时使⽤ containerd, harbor节点的容器运行时使⽤ docker(⽬前harbor的安装脚本会强制检查docker及docker-compose是否安装)⽤于部署harbor,此处均使用脚本进行二进制安装:
harbor部署对docker和docker-compose的版本有要求,具体参考:https://github.com/goharbor/harbor
root@K8S-harbor01:~# cd /usr/local/src
root@K8S-harbor01:/usr/local/src# tar -xvf runtime-docker20.10.19-containerd1.6.20-binary-install.tar.gz
root@K8S-harbor01:/usr/local/src# bash runtime-install.sh docker #安装脚本内容在上一篇文章里
root@K8S-harbor01:/usr/local/src# docker version
root@K8S-harbor01:/usr/local/src# docker-compose version
root@K8S-harbor02:~# cd /usr/local/src/
root@K8S-harbor02:/usr/local/src# tar -xvf runtime-docker20.10.19-containerd1.6.20-binary-install.tar.gz
root@K8S-harbor02:/usr/local/src# bash runtime-install.sh docker
root@K8S-harbor02:/usr/local/src# docker version
root@K8S-harbor02:/usr/local/src# docker-compose version
部署harbor镜像仓库(https认证方式)
harbor是一个通过docker-compose编排的单机服务,官网下载地址:https://github.com/goharbor/harbor/releases
下载offline包,已经集成了各种镜像,无需联网,此处下载:harbor-offline-installer-v2.5.6.tgz
github下载慢的,可以使用代理下载:https://ghproxy.com/
私有镜像仓库harbor的分类(根据认证方式):
1)harbor直接使用IP访问,不推荐,IP变换后很麻烦
2)harbor使用http域名访问,不推荐,公司内部使用可以,不安全
3)https自签名证书,不推荐,自行签发证书不被docker、containerd或者浏览器信任,注意go版本比较新的系统需要用新的证书签发方式(SAN)
4)https商业机构签发,一般都是公司域名购买的证书,推荐使用
商业认证证书准备
下载购买的证书上传的服务器,或者公司已经购买的相关域名的证书,此处我的证书域名是www.houlai.tech;注意,证书需要下载nginx格式的,因为harbor是nginx做为前端访问的
准备harbor配置文件和证书
root@K8S-harbor01:/usr/local/src# mkdir /apps
root@K8S-harbor01:/usr/local/src# mv harbor-offline-installer-v2.5.6.tgz /apps/
root@K8S-harbor01:/usr/local/src# mv houlai.tech_nginx.zip /apps/ #拷贝证书
root@K8S-harbor01:/usr/local/src# cd /apps/
root@K8S-harbor01:/apps# tar -xvf harbor-offline-installer-v2.5.6.tgz
root@K8S-harbor01:/apps# unzip houlai.tech_nginx.zip
root@K8S-harbor01:/apps# cd harbor/
root@K8S-harbor01:/apps/harbor# mkdir certs #证书存放路径
root@K8S-harbor01:/apps/harbor# mv ../houlai.tech_nginx/houlai.tech_bundle.pem certs/
root@K8S-harbor01:/apps/harbor# mv ../houlai.tech_nginx/houlai.tech.key certs/
root@K8S-harbor01:/apps/harbor# cp harbor.yml.tmpl harbor.yml #harbor配置文件
root@K8S-harbor01:/apps/harbor# vi harbor.yml #修改以下配置
hostname: www.houlai.tech #证书的有效域名
certificate: /apps/harbor/certs/houlai.tech_bundle.pem #公钥位置
private_key: /apps/harbor/certs/houlai.tech.key #私钥位置
harbor_admin_password: 123456 #harbor登录密码
data_volume: /data #上传的镜像保存的路径,生产环境此目录需要单独磁盘或者云盘
部署harbor
root@K8S-harbor01:/apps/harbor# ./install.sh --help
Note: Please set hostname and other necessary attributes in harbor.yml first. DO NOT use localhost or 127.0.0.1 for hostname, because Harbor needs to be accessed by external clients.
Please set --with-notary if needs enable Notary in Harbor, and set ui_url_protocol/ssl_cert/ssl_cert_key in harbor.yml bacause notary must run under https. #此选项需要对harbor进行https认证,此处已经配置为https,因此不用加此选项
Please set --with-trivy if needs enable Trivy in Harbor #扫描harbor漏洞,一般启用
Please set --with-chartmuseum if needs enable Chartmuseum in Harbor #支持chart包,一般启用
root@K8S-harbor01:/apps/harbor# ./install.sh --with-trivy --with-chartmuseum
[Step 5]: starting Harbor ...
Creating network "harbor_harbor" with the default driver
Creating network "harbor_harbor-chartmuseum" with the default driver
Creating harbor-log ... done
Creating registry ... done
Creating harbor-portal ... done
Creating harbor-db ... done
Creating registryctl ... done
Creating redis ... done
Creating chartmuseum ... done
Creating trivy-adapter ... done
Creating harbor-core ... done
Creating nginx ... done
Creating harbor-jobservice ... done
✔ ----Harbor has been installed and started successfully.---- #harbor安装成功
root@K8S-harbor01:/apps/harbor/common/config/nginx# docker ps -a #默认启动了多个容器
root@K8S-harbor01:~# vi /etc/systemd/system/harbor.service #手动创建service启动文件
[Unit]
Description=Harbor
After=docker.service systemd-networkd.service systemd-resolved.service
Requires=docker.service
Documentation=http://github.com/goharbor/harbor
[Service]
Type=simple
Restart=on-failure
RestartSec=5
ExecStart=/usr/bin/docker-compose -f /apps/harbor/docker-compose.yml up
ExecStop=/usr/bin/docker-compose -f /apps/harbor/docker-compose.yml down
[Install]
WantedBy=multi-user.target
root@K8S-harbor01:~# systemctl daemon-reload
root@K8S-harbor01:~# systemctl enable harbor.service #开机自启动
root@K8S-harbor01:/apps/harbor# docker ps -a #查看容器都处于正常启动状态,确保所有容器状态是healthy
登录harbor
修改物理windows自己的hosts文件,保证www.houlai.tech 可以解析到harbor主机(192.168.100.104)
浏览器输入https://www.houlai.tech,访问harbor,如下图(用户名admin,密码123456)

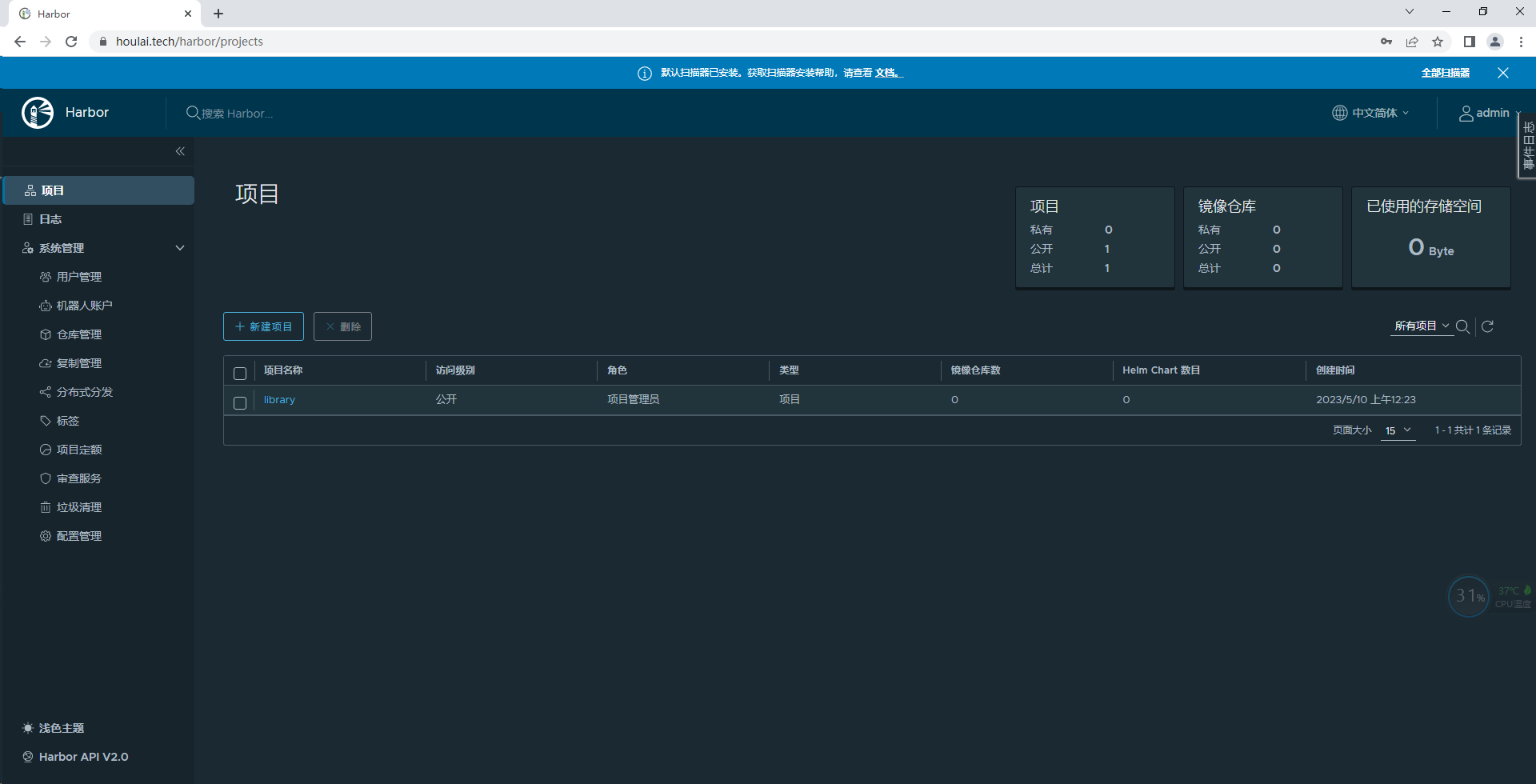
至此harbor部署完成
harbor中创建项目
浏览器登录harbor,点击新建项目-->项目名称 myrepo -->访问级别,点击公开(私有项目需要提供认证才能下载),确保可以创建项目,如下图所示:
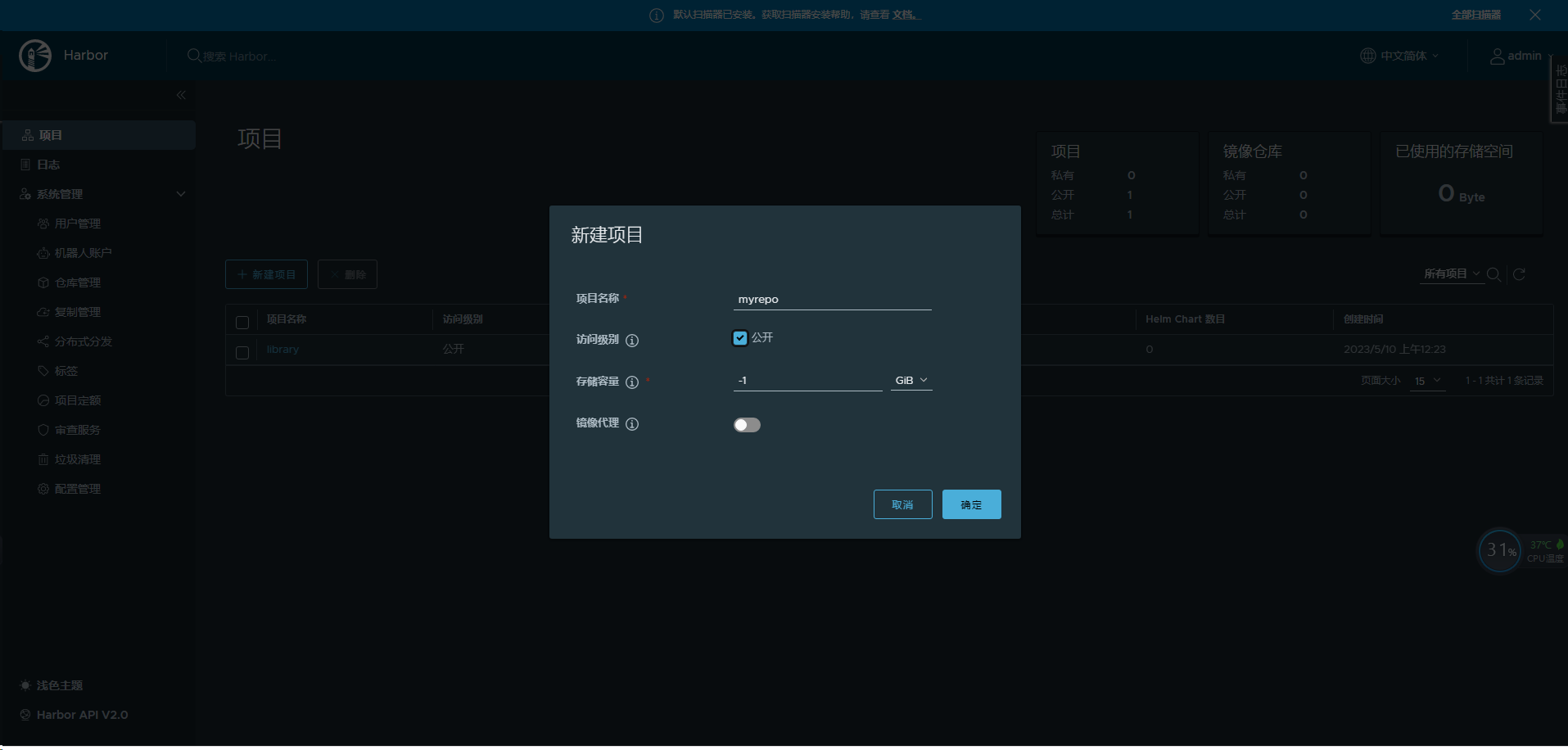

创建baseimages项目,用于存放基础镜像:

docker验证harbor
将harbor02作为客户端进行验证harbor的登录以及镜像上传和下载
root@K8S-harbor02:~# echo "192.168.100.104 www.houlai.tech" >>/etc/hosts
root@K8S-harbor02:~# docker login www.houlai.tech #docker登录,用户名admin,密码123456
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
root@K8S-harbor02:~# docker pull alpine
Using default tag: latest
latest: Pulling from library/alpine
Digest: sha256:21a3deaa0d32a8057914f36584b5288d2e5ecc984380bc0118285c70fa8c9300
Status: Downloaded newer image for alpine:latest
docker.io/library/alpine:latest
root@K8S-harbor02:~# docker tag alpine www.houlai.tech/baseimages/alpine #重新打标签
root@K8S-harbor02:~# docker push www.houlai.tech/baseimages/alpine #上传到harbor,必须确保能够上传成功
Using default tag: latest
The push refers to repository [www.houlai.tech/baseimages/alpine]
8d3ac3489996: Mounted from baseimages/apline
latest: digest: sha256:e7d88de73db3d3fd9b2d63aa7f447a10fd0220b7cbf39803c803f2af9ba256b3 size: 528
确保镜像可以上传到harbor,如下图:

root@K8S-harbor02:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
alpine latest c059bfaa849c 17 months ago 5.59MB
www.houlai.tech/baseimages/apline latest c059bfaa849c 17 months ago 5.59MB
root@K8S-harbor02:~# docker rmi -f c059bfaa849c #删除本地镜像
root@K8S-harbor02:~# docker pull www.houlai.tech/baseimages/alpine:latest #在harbor网页仓库alpine获取拉取命令
latest: Pulling from baseimages/alpine
59bf1c3509f3: Pull complete
Digest: sha256:e7d88de73db3d3fd9b2d63aa7f447a10fd0220b7cbf39803c803f2af9ba256b3
Status: Downloaded newer image for www.houlai.tech/baseimages/alpine:latest
www.houlai.tech/baseimages/alpine:latest
kubeasz部署⾼可⽤kubernetes:
K8S集群部署比较麻烦,生产环境推荐使用自动化部署项目kubeasz,方便自动部署和后期进行集群伸缩
项目地址:https://github.com/easzlab/kubeasz
kubeasz已通过CNCF一致性认证,CNCF一致性认证查询地址:https://github.com/cncf/k8s-conformance
kubeasz项目简介:
kubeasz致力于提供快速部署高可用k8s集群的工具, 同时也努力成为k8s实践、使用的参考书;基于二进制方式部署和利用ansible-playbook实现自动化;既提供一键安装脚本, 也可以根据安装指南分步执行安装各个组件。
kubeasz从每一个单独部件组装到完整的集群,提供最灵活的配置能力,几乎可以设置任何组件的任何参数;同时又为集群创建预置一套运行良好的默认配置,甚至自动化创建适合大规模集群的[BGP Route Reflector网络模式]
具体部署步骤和需要的软件版本清单请参考项目官方地址介绍:
需要使用的单独的部署节点来进行K8S集群部署,部署节点需要安装ansible以及提前进行ssh免密认证,一般负载均衡器和harbor比较重要,此处手动部署,其余master节点、node节点和etcd集群都是用kubeasz来进行自动部署
部署节点基本配置
此处部署节点是:192.168.100.111,部署节点的功能如下:
1)、从互联⽹下载安装资源
2)、可选将部分镜像修改tag后上传到公司内部镜像仓库服务器
3)、对master进⾏初始化
4)、对node进⾏初始化
5)、后期集群维护,包括:
添加及删除master节点
添加就删除node节点
etcd数据备份及恢复
安装ansible并进行ssh免密登录:
apt安装ansieble,并将部署节点的公钥拷贝至master、node、etcd节点
root@K8S-deploy:~# apt update
root@K8S-deploy:~# apt install ansible -y
root@K8S-deploy:~# ssh-keygen -t rsa-sha2-512 -b 4096 #生成密钥对
root@K8S-deploy:~# vi copy-sshkey.sh 使用脚本进行公钥拷贝
root@K8S-deploy:~# cat copy-sshkey.sh
#!/bin/bash
#目标主机列表
IP="
192.168.100.101
192.168.100.102
192.168.100.103
192.168.100.106
192.168.100.107
192.168.100.108
192.168.100.121
192.168.100.122
192.168.100.123
"
REMOTE_PORT="22"
REMOTE_USER="root"
REMOTE_PASS="123456"
for REMOTE_HOST in ${IP};do
REMOTE_CMD="echo ${REMOTE_HOST} is successfully!"
ssh-keyscan -p "${REMOTE_PORT}" "${REMOTE_HOST}" >> ~/.ssh/known_hosts #在本地添加远程主机的公钥信息,避免交互式应答
sshpass -p "${REMOTE_PASS}" ssh-copy-id "${REMOTE_USER}@${REMOTE_HOST}"
if [ $? -eq 0 ];then
echo ${REMOTE_HOST} 免秘钥配置完成!
ssh ${REMOTE_HOST} ln -sv /usr/bin/python3 /usr/bin/python
else
echo "免密钥配置失败!"
fi
done
root@K8S-deploy:~# chmod +x copy-sshkey.sh
root@K8S-deploy:~# apt install sshpass -y
root@K8S-deploy:~# bash copy-sshkey.sh #执行脚本进行批量进行免密认证
root@K8S-deploy:~# ssh 192.168.100.106 #验证免密登录
Welcome to Ubuntu 22.04 LTS (GNU/Linux 5.15.0-71-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Wed May 10 02:52:48 PM CST 2023
System load: 0.10107421875 Processes: 251
Usage of /: 7.1% of 119.94GB Users logged in: 1
Memory usage: 9% IPv4 address for eth0: 192.168.100.106
Swap usage: 0%
94 updates can be applied immediately.
To see these additional updates run: apt list --upgradable
Failed to connect to https://changelogs.ubuntu.com/meta-release-lts. Check your Internet connection or proxy settings
Last login: Wed May 10 14:49:46 2023 from 192.168.100.1
下载kubeasz项⽬及组件
root@K8S-deploy:~# wget https://github.com/easzlab/kubeasz/releases/download/3.5.2/ezdown #下载3.5.2版本,此文档一定下载此版本,否则之后会有问题
root@K8S-deploy:~# cp ezdown{,.org}
root@K8S-deploy:~# vi ezdown #此部署脚本需要运行docker,从docker官方仓库中下载项目已经打包好的镜像,搜索kubeasz,可自行修改需要安装的版本,前提是kubeasz的仓库里有此版本
DOCKER_VER=20.10.24
K8S_BIN_VER=v1.26.1
root@K8S-deploy:~# chmod +x ezdown
root@K8S-deploy:~# ./ezdown -D #下载kubeasz代码、二进制、默认容器镜像
e3e5579ddd43: Pushed
3.9: digest: sha256:3ec9d4ec5512356b5e77b13fddac2e9016e7aba17dd295ae23c94b2b901813de size: 527
3.5.2: Pulling from easzlab/kubeasz
Digest: sha256:dc2a5cd1b5f3f7d52e59b4868a6dfaca111f2d9bdeae044844e30efd3b67203e
Status: Image is up to date for easzlab/kubeasz:3.5.2
docker.io/easzlab/kubeasz:3.5.2
2023-05-11 23:05:31 INFO Action successed: download_all
root@K8S-deploy:~# ll -a /etc/kubeasz/ #kubeasz所有文件和配置路径
total 120
drwxrwxr-x 12 root root 4096 May 10 17:23 ./
drwxr-xr-x 101 root root 8192 May 10 17:24 ../
drwxrwxr-x 3 root root 23 May 3 17:43 .github/
-rw-rw-r-- 1 root root 301 Apr 16 11:38 .gitignore
-rw-rw-r-- 1 root root 5556 Apr 16 11:38 README.md
-rw-rw-r-- 1 root root 20304 Apr 16 11:38 ansible.cfg
drwxr-xr-x 4 root root 4096 May 10 17:23 bin/
drwxrwxr-x 8 root root 94 May 3 17:43 docs/
drwxr-xr-x 3 root root 4096 May 10 17:26 down/
drwxrwxr-x 2 root root 70 May 3 17:43 example/
-rwxrwxr-x 1 root root 26174 Apr 16 11:38 ezctl*
-rwxrwxr-x 1 root root 25343 Apr 16 11:38 ezdown*
drwxrwxr-x 10 root root 145 May 3 17:43 manifests/
drwxrwxr-x 2 root root 94 May 3 17:43 pics/
drwxrwxr-x 2 root root 4096 May 3 17:43 playbooks/
drwxrwxr-x 22 root root 4096 May 3 17:43 roles/
drwxrwxr-x 2 root root 48 May 3 17:43 tools/
部署K8S集群
kubeasz通过集群名称来管理和区分集群,必须唯一,每个集群会创建一个独立的文件夹保存集群的所有配置;注意需要确保部署节点到集群其他节点的网络是通的。
kubeasz通过本地已下载程序文件向需要的节点通过ansible拷贝所需文件
root@K8S-deploy:~# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# ./ezctl --help #查看集群管理帮助
Usage: ezctl COMMAND [args]
-------------------------------------------------------------------------------------
Cluster setups:
list to list all of the managed clusters
checkout <cluster> to switch default kubeconfig of the cluster
new <cluster> to start a new k8s deploy with name 'cluster'
setup <cluster> <step> to setup a cluster, also supporting a step-by-step way
start <cluster> to start all of the k8s services stopped by 'ezctl stop'
stop <cluster> to stop all of the k8s services temporarily
upgrade <cluster> to upgrade the k8s cluster
destroy <cluster> to destroy the k8s cluster
backup <cluster> to backup the cluster state (etcd snapshot)
restore <cluster> to restore the cluster state from backups
start-aio to quickly setup an all-in-one cluster with default settings
Cluster ops:
add-etcd <cluster> <ip> to add a etcd-node to the etcd cluster
add-master <cluster> <ip> to add a master node to the k8s cluster
add-node <cluster> <ip> to add a work node to the k8s cluster
del-etcd <cluster> <ip> to delete a etcd-node from the etcd cluster
del-master <cluster> <ip> to delete a master node from the k8s cluster
del-node <cluster> <ip> to delete a work node from the k8s cluster
Extra operation:
kca-renew <cluster> to force renew CA certs and all the other certs (with caution)
kcfg-adm <cluster> <args> to manage client kubeconfig of the k8s cluster
Use "ezctl help <command>" for more information about a given command.
root@K8S-deploy:/etc/kubeasz# ./ezctl new k8s-cluster01 #第一步,新建管理集群
2023-05-10 22:09:32 DEBUG generate custom cluster files in /etc/kubeasz/clusters/k8s-cluster01 #集群使用相关配置路径
2023-05-10 22:09:32 DEBUG set versions
2023-05-10 22:09:32 DEBUG cluster k8s-cluster01: files successfully created.
2023-05-10 22:09:32 INFO next steps 1: to config '/etc/kubeasz/clusters/k8s-cluster01/hosts' #ansible hosts文件
2023-05-10 22:09:32 INFO next steps 2: to config '/etc/kubeasz/clusters/k8s-cluster01/config.yml' #ansible yaml文件
配置用于集群管理的ansible hosts文件
root@K8S-deploy:/etc/kubeasz# cd /etc/kubeasz/clusters/k8s-cluster01/
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# ll #注意,这两个文件至关重要,任何小错误都会导致集群有问题
total 12
drwxr-xr-x 2 root root 37 May 10 22:09 ./
drwxr-xr-x 3 root root 27 May 10 22:09 ../
-rw-r--r-- 1 root root 7131 May 10 22:09 config.yml
-rw-r--r-- 1 root root 2307 May 10 22:09 hosts
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# cp hosts{,.org}
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# sed -i 's/192.168.1/192.168.100/g' hosts
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# vi hosts #修改为以下配置
# 'etcd' cluster should have odd member(s) (1,3,5,...)
[etcd]
192.168.100.106
192.168.100.107
192.168.100.108
# master node(s), set unique 'k8s_nodename' for each node
# CAUTION: 'k8s_nodename' must consist of lower case alphanumeric characters, '-' or '.',
# and must start and end with an alphanumeric character
[kube_master]
192.168.100.101 k8s_nodename='K8S-master01'
192.168.100.102 k8s_nodename='K8S-master02'
#192.168.100.3 k8s_nodename='master-03'
# work node(s), set unique 'k8s_nodename' for each node
# CAUTION: 'k8s_nodename' must consist of lower case alphanumeric characters, '-' or '.',
# and must start and end with an alphanumeric character
[kube_node]
192.168.100.121 k8s_nodename='K8S-node01'
192.168.100.122 k8s_nodename='K8S-node02'
# [optional] harbor server, a private docker registry
# 'NEW_INSTALL': 'true' to install a harbor server; 'false' to integrate with existed one
[harbor]
#192.168.100.8 NEW_INSTALL=false
# [optional] loadbalance for accessing k8s from outside
[ex_lb]
#192.168.100.6 LB_ROLE=backup EX_APISERVER_VIP=192.168.100.250 EX_APISERVER_PORT=8443
#192.168.100.7 LB_ROLE=master EX_APISERVER_VIP=192.168.100.250 EX_APISERVER_PORT=8443
# [optional] ntp server for the cluster
[chrony]
#192.168.100.1
[all:vars]
# --------- Main Variables ---------------
# Secure port for apiservers
SECURE_PORT="6443"
# Cluster container-runtime supported: docker, containerd
# if k8s version >= 1.24, docker is not supported
CONTAINER_RUNTIME="containerd"
# Network plugins supported: calico, flannel, kube-router, cilium, kube-ovn
CLUSTER_NETWORK="calico"
# Service proxy mode of kube-proxy: 'iptables' or 'ipvs'
PROXY_MODE="ipvs"
# K8S Service CIDR, not overlap with node(host) networking
SERVICE_CIDR="10.100.0.0/16"
# Cluster CIDR (Pod CIDR), not overlap with node(host) networking
CLUSTER_CIDR="10.200.0.0/16"
# NodePort Range
NODE_PORT_RANGE="30000-62767"
# Cluster DNS Domain
CLUSTER_DNS_DOMAIN="cluster.local"
# -------- Additional Variables (don't change the default value right now) ---
# Binaries Directory
bin_dir="/usr/local/bin"
# Deploy Directory (kubeasz workspace)
base_dir="/etc/kubeasz"
# Directory for a specific cluster
cluster_dir="{{ base_dir }}/clusters/k8s-cluster01"
# CA and other components cert/key Directory
ca_dir="/etc/kubernetes/ssl"
# Default 'k8s_nodename' is empty
k8s_nodename=''
编辑cluster config.yml⽂件
提前上传pause镜像到本地harbor:
root@K8S-harbor02:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9 #pause镜像至关重要,可以提前pull下来放到本地harbor上,保证后面可以顺利下载
3.9: Pulling from google_containers/pause
61fec91190a0: Pull complete
Digest: sha256:7031c1b283388d2c2e09b57badb803c05ebed362dc88d84b480cc47f72a21097
Status: Downloaded newer image for registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
root@K8S-harbor02:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9 www.houlai.tech/baseimages/pause:3.9
root@K8S-harbor02:~# docker push www.houlai.tech/baseimages/pause:3.9 #上传到本地harbor
The push refers to repository [www.houlai.tech/baseimages/pause]
e3e5579ddd43: Pushed
3.9: digest: sha256:0fc1f3b764be56f7c881a69cbd553ae25a2b5523c6901fbacb8270307c29d0c4 size: 526
config.yml是用于配置K8S集群的具体配置
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# cp config.yml{,.org}
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# vi config.yml #修改为以下配置,注意修改master的IP以及DNS相关配置、images配置等
############################
# prepare
############################
# 可选离线安装系统软件包 (offline|online)
INSTALL_SOURCE: "online"
# 可选进行系统安全加固 github.com/dev-sec/ansible-collection-hardening
OS_HARDEN: false
############################
# role:deploy
############################
# default: ca will expire in 100 years
# default: certs issued by the ca will expire in 50 years
CA_EXPIRY: "876000h"
CERT_EXPIRY: "438000h"
# force to recreate CA and other certs, not suggested to set 'true'
CHANGE_CA: false
# kubeconfig 配置参数
CLUSTER_NAME: "cluster1"
CONTEXT_NAME: "context-{{ CLUSTER_NAME }}"
# k8s version
K8S_VER: "1.26.1"
# set unique 'k8s_nodename' for each node, if not set(default:'') ip add will be used
# CAUTION: 'k8s_nodename' must consist of lower case alphanumeric characters, '-' or '.',
# and must start and end with an alphanumeric character (e.g. 'example.com'),
# regex used for validation is '[a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*'
K8S_NODENAME: "{%- if k8s_nodename != '' -%} \
{{ k8s_nodename|replace('_', '-')|lower }} \
{%- else -%} \
{{ inventory_hostname }} \
{%- endif -%}"
############################
# role:etcd
############################
# 设置不同的wal目录,可以避免磁盘io竞争,提高性能
ETCD_DATA_DIR: "/var/lib/etcd"
ETCD_WAL_DIR: ""
############################
# role:runtime [containerd,docker]
############################
# ------------------------------------------- containerd
# [.]启用容器仓库镜像
ENABLE_MIRROR_REGISTRY: true
# [containerd]基础容器镜像
SANDBOX_IMAGE: "www.houlai.tech/baseimages/pause:3.9"
# [containerd]容器持久化存储目录
CONTAINERD_STORAGE_DIR: "/var/lib/containerd" #此处一般挂载高性能固态盘,提高容器的运行速度
# ------------------------------------------- docker
# [docker]容器存储目录
DOCKER_STORAGE_DIR: "/var/lib/docker"
# [docker]开启Restful API
ENABLE_REMOTE_API: false
# [docker]信任的HTTP仓库
INSECURE_REG: '["http://easzlab.io.local:5000"]'
############################
# role:kube-master
############################
# k8s 集群 master 节点证书配置,可以添加多个ip和域名(比如增加公网ip和域名)
MASTER_CERT_HOSTS: #需要访问API server的IP都需要加上
- "192.168.100.188"
- "api.server.com"
#- "www.test.com"
# node 节点上 pod 网段掩码长度(决定每个节点最多能分配的pod ip地址)
# 如果flannel 使用 --kube-subnet-mgr 参数,那么它将读取该设置为每个节点分配pod网段
# https://github.com/coreos/flannel/issues/847
NODE_CIDR_LEN: 24
############################
# role:kube-node
############################
# Kubelet 根目录
KUBELET_ROOT_DIR: "/var/lib/kubelet"
# node节点最大pod 数
MAX_PODS: 110
# 配置为kube组件(kubelet,kube-proxy,dockerd等)预留的资源量
# 数值设置详见templates/kubelet-config.yaml.j2
KUBE_RESERVED_ENABLED: "no"
# k8s 官方不建议草率开启 system-reserved, 除非你基于长期监控,了解系统的资源占用状况;
# 并且随着系统运行时间,需要适当增加资源预留,数值设置详见templates/kubelet-config.yaml.j2
# 系统预留设置基于 4c/8g 虚机,最小化安装系统服务,如果使用高性能物理机可以适当增加预留
# 另外,集群安装时候apiserver等资源占用会短时较大,建议至少预留1g内存
SYS_RESERVED_ENABLED: "no"
############################
# role:network [flannel,calico,cilium,kube-ovn,kube-router]
############################
# ------------------------------------------- flannel
# [flannel]设置flannel 后端"host-gw","vxlan"等
FLANNEL_BACKEND: "vxlan"
DIRECT_ROUTING: false
# [flannel]
flannel_ver: "v0.19.2"
# ------------------------------------------- calico
# [calico] IPIP隧道模式可选项有: [Always, CrossSubnet, Never],跨子网可以配置为Always与CrossSubnet(公有云建议使用always比较省事,其他的话需要修改各自公有云的网络配置,具体可以参考各个公有云说明)
# 其次CrossSubnet为隧道+BGP路由混合模式可以提升网络性能,同子网配置为Never即可.
CALICO_IPV4POOL_IPIP: "Always"
# [calico]设置 calico-node使用的host IP,bgp邻居通过该地址建立,可手工指定也可以自动发现
IP_AUTODETECTION_METHOD: "can-reach={{ groups['kube_master'][0] }}"
# [calico]设置calico 网络 backend: brid, vxlan, none
CALICO_NETWORKING_BACKEND: "brid"
# [calico]设置calico 是否使用route reflectors
# 如果集群规模超过50个节点,建议启用该特性
CALICO_RR_ENABLED: false
# CALICO_RR_NODES 配置route reflectors的节点,如果未设置默认使用集群master节点
# CALICO_RR_NODES: ["192.168.1.1", "192.168.1.2"]
CALICO_RR_NODES: []
# [calico]更新支持calico 版本: ["3.19", "3.23"]
calico_ver: "v3.24.5"
# [calico]calico 主版本
calico_ver_main: "{{ calico_ver.split('.')[0] }}.{{ calico_ver.split('.')[1] }}"
# ------------------------------------------- cilium
# [cilium]镜像版本
cilium_ver: "1.12.4"
cilium_connectivity_check: true
cilium_hubble_enabled: false
cilium_hubble_ui_enabled: false
# ------------------------------------------- kube-ovn
# [kube-ovn]选择 OVN DB and OVN Control Plane 节点,默认为第一个master节点
OVN_DB_NODE: "{{ groups['kube_master'][0] }}"
# [kube-ovn]离线镜像tar包
kube_ovn_ver: "v1.5.3"
# ------------------------------------------- kube-router
# [kube-router]公有云上存在限制,一般需要始终开启 ipinip;自有环境可以设置为 "subnet"
OVERLAY_TYPE: "full"
# [kube-router]NetworkPolicy 支持开关
FIREWALL_ENABLE: true
# [kube-router]kube-router 镜像版本
kube_router_ver: "v0.3.1"
busybox_ver: "1.28.4"
############################
# role:cluster-addon
############################
# coredns 自动安装
dns_install: "no"
corednsVer: "1.9.3"
ENABLE_LOCAL_DNS_CACHE: false #此处改为禁用DNS缓存,开启的话pod里的/etc/resolv.conf会配置为LOCAL_DNS_CACHE的值
dnsNodeCacheVer: "1.22.13"
# 设置 local dns cache 地址
LOCAL_DNS_CACHE: "10.100.0.2" #coredns的service的clusterIP
# metric server 自动安装
metricsserver_install: "no"
metricsVer: "v0.5.2"
# dashboard 自动安装
dashboard_install: "no"
dashboardVer: "v2.7.0"
dashboardMetricsScraperVer: "v1.0.8"
# prometheus 自动安装
prom_install: "no"
prom_namespace: "monitor"
prom_chart_ver: "39.11.0"
# nfs-provisioner 自动安装
nfs_provisioner_install: "no"
nfs_provisioner_namespace: "kube-system"
nfs_provisioner_ver: "v4.0.2"
nfs_storage_class: "managed-nfs-storage"
nfs_server: "192.168.1.10"
nfs_path: "/data/nfs"
# network-check 自动安装
network_check_enabled: false
network_check_schedule: "*/5 * * * *"
############################
# role:harbor
############################
# harbor version,完整版本号
HARBOR_VER: "v2.6.3"
HARBOR_DOMAIN: "harbor.easzlab.io.local"
HARBOR_PATH: /var/data
HARBOR_TLS_PORT: 8443
HARBOR_REGISTRY: "{{ HARBOR_DOMAIN }}:{{ HARBOR_TLS_PORT }}"
# if set 'false', you need to put certs named harbor.pem and harbor-key.pem in directory 'down'
HARBOR_SELF_SIGNED_CERT: true
# install extra component
HARBOR_WITH_NOTARY: false
HARBOR_WITH_TRIVY: false
HARBOR_WITH_CHARTMUSEUM: true
环境初始化
本步骤主要完成:(playbook文件: /etc/kubeasz/playbooks/01.prepare.yml ,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/01-CA_and_prerequisite.md)
- (optional) role:os-harden,可选系统加固,符合linux安全基线,详见upstream
- (optional) role:chrony,可选集群节点时间同步
- role:deploy,创建CA证书、集群组件访问apiserver所需的各种kubeconfig
- role:prepare,系统基础环境配置、分发CA证书、kubectl客户端安装
root@K8S-deploy:/etc/kubeasz/clusters/k8s-cluster01# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# ./ezctl setup --help #查看具体安装步骤,依次按顺序执行来部署k8s各组件,具体每步含义可参考官网:https://github.com/easzlab/kubeasz,安装指南部分
Usage: ezctl setup <cluster> <step>
available steps:
01 prepare to prepare CA/certs & kubeconfig & other system settings
02 etcd to setup the etcd cluster
03 container-runtime to setup the container runtime(docker or containerd)
04 kube-master to setup the master nodes
05 kube-node to setup the worker nodes
06 network to setup the network plugin
07 cluster-addon to setup other useful plugins
90 all to run 01~07 all at once
10 ex-lb to install external loadbalance for accessing k8s from outside
11 harbor to install a new harbor server or to integrate with an existed one
examples: ./ezctl setup test-k8s 01 (or ./ezctl setup test-k8s prepare)
./ezctl setup test-k8s 02 (or ./ezctl setup test-k8s etcd)
./ezctl setup test-k8s all
./ezctl setup test-k8s 04 -t restart_master
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 01 #执行第一步,开始初始化,确保过程没有报错
部署etcd集群
本步骤完成etcd集群的安装(playbook文件:/etc/kubeasz/playbooks/02.etcd.yml,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/02-install_etcd.md)
kuberntes 集群使用 etcd 存储所有数据,是最重要的组件之一,注意 etcd集群需要奇数个节点(1,3,5...),本文档使用3个节点做集群。
注意:证书是在部署节点创建好之后推送到目标etcd节点上去的,以增加ca证书的安全性
root@K8S-deploy:/etc/kubeasz# ln -s /usr/bin/python3 /usr/bin/python #此步不做会报错
root@K8S-deploy:/etc/kubeasz# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# cat /etc/kubeasz/playbooks/02.etcd.yml
# to install etcd cluster
- hosts: etcd
roles:
- etcd
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 02 #执行第二步,安装etcd集群,确保过程没有报错
注意,如果想重新清除所有步骤,可以执行:(生产环境慎用,会清除所有K8S数据)
./ezctl destroy <cluster>
在任意一个etcd节点上验证etcd集群(确保是集群方式部署):
root@K8S-etcd02:~# export NODE_IPS="192.168.100.106 192.168.100.107 192.168.100.108"
root@K8S-etcd01:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done #验证etcd集群服务正常
https://192.168.100.106:2379 is healthy: successfully committed proposal: took = 14.376224ms
https://192.168.100.107:2379 is healthy: successfully committed proposal: took = 13.625962ms
https://192.168.100.108:2379 is healthy: successfully committed proposal: took = 12.641164ms
root@K8S-etcd01:~# cat /etc/systemd/system/multi-user.target.wants/etcd.service #确保生成的service文件内容对应变量均替换
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd
ExecStart=/usr/local/bin/etcd \
--name=etcd-192.168.100.106 \
--cert-file=/etc/kubernetes/ssl/etcd.pem \
--key-file=/etc/kubernetes/ssl/etcd-key.pem \
--peer-cert-file=/etc/kubernetes/ssl/etcd.pem \
--peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--initial-advertise-peer-urls=https://192.168.100.106:2380 \
--listen-peer-urls=https://192.168.100.106:2380 \
--listen-client-urls=https://192.168.100.106:2379,http://127.0.0.1:2379 \
--advertise-client-urls=https://192.168.100.106:2379 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=etcd-192.168.100.106=https://192.168.100.106:2380,etcd-192.168.100.107=https://192.168.100.107:2380,etcd-192.168.100.108=https://192.168.100.108:2380 \
--initial-cluster-state=new \
--data-dir=/var/lib/etcd \
--wal-dir= \
--snapshot-count=50000 \
--auto-compaction-retention=1 \
--auto-compaction-mode=periodic \
--max-request-bytes=10485760 \
--quota-backend-bytes=8589934592
Restart=always
RestartSec=15
LimitNOFILE=65536
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
部署容器运⾏时containerd
本步骤主要完成在master节点和node节点安装容器运行时containerd(playbook:/etc/kubeasz/playbooks/03.runtime.yml,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/03-container_runtime.md)
由于没有dns服务解析harbor服务器域名,因此需要在此步骤增加域名解析记录的分发,通过ansible分发
由于kubeasz项目目前没有集成nerdctl客户端,因此此处需要通过ansible分发nerdctl客户端
配置harbor镜像仓库域名解析(写入到/etc/hosts文件,通过ansible下发):
root@K8S-deploy:/etc/kubeasz# cp roles/containerd/tasks/main.yml{,.org}
root@K8S-deploy:/etc/kubeasz# vi roles/containerd/tasks/main.yml #添加以下两行,注意yaml格式缩进
- name: 添加域名解析记录
shell: "echo '192.168.100.104 www.houlai.tech' >>/etc/hosts"
自定义containerd配置文件(修改j2模板文件,通过ansible下发):
root@K8S-deploy:/etc/kubeasz# vi roles/containerd/templates/config.toml.j2 #此处不做修改,可以根据需求修改,例如镜像加速配置,可以改为自己的阿里云镜像加速地址
nerdctl客户端部署配置
提前准备nerdctl客户端的二进制文件到ansible指定的目录:
root@K8S-deploy:/etc/kubeasz# cd /usr/local/src
root@K8S-deploy:/usr/local/src# tar -xf nerdctl-1.3.0-linux-amd64.tar.gz
root@K8S-deploy:/usr/local/src# rm -rf nerdctl-1.3.0-linux-amd64.tar.gz
root@K8S-deploy:/usr/local/src# mv * /etc/kubeasz/bin/containerd-bin/ #确保nerdctl二进制存在
root@K8S-deploy:/usr/local/src# ll /etc/kubeasz/bin/containerd-bin/
total 159344
drwxr-xr-x 2 root root 4096 May 11 16:54 ./
drwxr-xr-x 4 root root 4096 May 10 17:23 ../
-rwxr-xr-x 1 root root 52255608 Mar 31 04:51 containerd*
-rwxr-xr-x 1 root root 21622 Apr 5 20:21 containerd-rootless-setuptool.sh*
-rwxr-xr-x 1 root root 7032 Apr 5 20:21 containerd-rootless.sh*
-rwxr-xr-x 1 root root 7352320 Mar 31 04:51 containerd-shim*
-rwxr-xr-x 1 root root 9469952 Mar 31 04:51 containerd-shim-runc-v1*
-rwxr-xr-x 1 root root 9486336 Mar 31 04:51 containerd-shim-runc-v2*
-rwxr-xr-x 1 root root 23079704 Mar 31 04:51 containerd-stress*
-rwxr-xr-x 1 root root 27126424 Mar 31 04:51 ctr*
-rwxr-xr-x 1 root root 24920064 Apr 5 20:22 nerdctl*
-rwxr-xr-x 1 root root 9431456 Mar 29 15:02 runc*
修改拷贝nerdctl相关的ansible配置文件:
root@K8S-deploy:/usr/local/src# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# vi roles/containerd/tasks/main.yml #添加nerdctl相关配置
- name: 准备containerd相关目录
file: name={{ item }} state=directory
with_items:
- "{{ bin_dir }}"
- "/etc/containerd"
- "/etc/nerdctl/" #nerdctl配置文件目录
- name: 下载 containerd 二进制文件
copy: src={{ base_dir }}/bin/containerd-bin/{{ item }} dest={{ bin_dir }}/{{ item }} mode=0755
with_items:
- containerd
- containerd-shim
- containerd-shim-runc-v1
- containerd-shim-runc-v2
- crictl
- ctr
- runc
- nerdctl #添加分发nerdctl
- containerd-rootless-setuptool.sh
- containerd-rootless.sh
tags: upgrade
- name: 创建 containerd 配置文件 #默认有,无需更改
template: src=config.toml.j2 dest=/etc/containerd/config.toml
tags: upgrade
- name: 创建 nerdctl 配置文件 #增加此项
template: src=nerdctl.toml.j2 dest=/etc/nerdctl/nerdctl.toml
tags: upgrade
准备nerdctl配置模板文件:
root@K8S-deploy:/etc/kubeasz# vi roles/containerd/templates/nerdctl.toml.j2 #修改为以下内容
namespace = "k8s.io"
debug = false
debug_full = false
insecure_registry = true
执行部署运行时
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 03 #确保执行过程无报错
验证运行时、nerdctl客户端、harbor镜像仓库上传和下载等
登录master节点验证:
root@K8S-master02:~# containerd -v #验证运行时
containerd github.com/containerd/containerd v1.6.14 9ba4b250366a5ddde94bb7c9d1def331423aa323
root@K8S-master02:~#
root@K8S-master02:~# nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
root@K8S-master02:~# nerdctl pull nginx #从docker官方下载nginx镜像
WARN[0000] skipping verifying HTTPS certs for "docker.io"
docker.io/library/nginx:latest: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:480868e8c8c797794257e2abd88d0f9a8809b2fe956cbfbc05dcc0bca1f7cd43: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:3f01b0094e21f7d55b9eb7179d01c49fdf9c3e1e3419d315b81a9e0bae1b6a90: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:448a08f1d2f94e8db6db9286fd77a3a4f3712786583720a12f1648abb8cace25: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:15a97cf85bb88997d139f86b2be23f99175d51d7e45a4c4b04ec0cbdbb56a63b: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:8db4caa19df89c606d39076b27fe163e1f37516f889ff5bfee1fce03056bb6b0: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:9c2d6be5a61d1ad44be8e5e93a5800572cff95601147c45eaa9ecf0d4cb66f83: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:9e3ea8720c6de96cc9ad544dddc695a3ab73f5581c5d954e0504cc4f80fb5e5c: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:bf36b64666794f28ea5c3d4d75add149c04e849342e3d45ca31aac9cf4715dd1: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:6b7e4a5c7c7ad54c76bc4861f476f3b70978beede9e752015202dd223383602b: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 46.3s
root@K8S-master02:~# nerdctl tag nginx www.houlai.tech/myrepo/nginx:v1 #重新打标签
root@K8S-master02:~# nerdctl login www.houlai.tech #登录本地harbor镜像仓库
Enter Username: admin
Enter Password:
WARN[0004] skipping verifying HTTPS certs for "www.houlai.tech"
WARNING: Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
root@K8S-master02:~# nerdctl push www.houlai.tech/myrepo/nginx:v1 #上传镜像到本地harbor镜像仓库
INFO[0000] pushing as a reduced-platform image (application/vnd.docker.distribution.manifest.list.v2+json, sha256:afb07a3b0803f4571305526b58869a02b411d36f36ae91d69208621dac955733)
WARN[0000] skipping verifying HTTPS certs for "www.houlai.tech"
index-sha256:afb07a3b0803f4571305526b58869a02b411d36f36ae91d69208621dac955733: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:3f01b0094e21f7d55b9eb7179d01c49fdf9c3e1e3419d315b81a9e0bae1b6a90: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:448a08f1d2f94e8db6db9286fd77a3a4f3712786583720a12f1648abb8cace25: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 1.5 s
root@K8S-node01:~# nerdctl pull www.houlai.tech/myrepo/nginx:v1 #在node节点验证不用登录即可下载本地harbor的镜像
WARN[0000] skipping verifying HTTPS certs for "www.houlai.tech"
www.houlai.tech/myrepo/nginx:v1: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:afb07a3b0803f4571305526b58869a02b411d36f36ae91d69208621dac955733: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:3f01b0094e21f7d55b9eb7179d01c49fdf9c3e1e3419d315b81a9e0bae1b6a90: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:448a08f1d2f94e8db6db9286fd77a3a4f3712786583720a12f1648abb8cace25: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:8db4caa19df89c606d39076b27fe163e1f37516f889ff5bfee1fce03056bb6b0: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:bf36b64666794f28ea5c3d4d75add149c04e849342e3d45ca31aac9cf4715dd1: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:15a97cf85bb88997d139f86b2be23f99175d51d7e45a4c4b04ec0cbdbb56a63b: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:9c2d6be5a61d1ad44be8e5e93a5800572cff95601147c45eaa9ecf0d4cb66f83: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:9e3ea8720c6de96cc9ad544dddc695a3ab73f5581c5d954e0504cc4f80fb5e5c: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:6b7e4a5c7c7ad54c76bc4861f476f3b70978beede9e752015202dd223383602b: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 5.1 s
部署K8S master节点
本步骤主要完成部署master节点的三个组件:kube-apiserver 、kube-scheduler、kube-controller-manager(playbook:/etc/kubeasz/playbooks/04.kube-master.yml,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/04-install_kube_master.md)
root@K8S-deploy:/etc/kubeasz# cat /etc/kubeasz/playbooks/04.kube-master.yml
# to set up 'kube_master' nodes
- hosts: kube_master
roles:
- kube-lb #四层负载均衡,监听在127.0.0.1:6443,转发到真实master节点apiserver服务
- kube-master
- kube-node #因为网络、监控等daemonset组件,master节点也推荐安装kubelet和kube-proxy服务
root@K8S-deploy:/etc/kubeasz# vi roles/kube-master/tasks/main.yml #可自定义配置,此处不做修改
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 04 #执行第4步,部署master节点
root@K8S-master02:~# cat /etc/kube-lb/conf/kube-lb.conf #master的负载均衡配置
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 192.168.100.101:6443 max_fails=2 fail_timeout=3s;
server 192.168.100.102:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
部署K8S node节点
本步骤主要完成node节点部署(playbook:/etc/kubeasz/playbooks/05.kube-node.yml,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/05-install_kube_node.md)
root@K8S-deploy:/etc/kubeasz# cat playbooks/05.kube-node.yml
# to set up 'kube_node' nodes
- hosts: kube_node
roles:
- { role: kube-lb, when: "inventory_hostname not in groups['kube_master']" }
- { role: kube-node, when: "inventory_hostname not in groups['kube_master']" }
root@K8S-deploy:/etc/kubeasz# vi roles/kube-node/tasks/main.yml #可自定义node配置,此处不做修改
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 05 #执行第5步,部署node节点
root@K8S-deploy:/etc/kubeasz# kubectl get node #执行完第5步,确保4个节点状态都是ready
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 19m v1.26.1
k8s-master02 Ready,SchedulingDisabled master 19m v1.26.1
k8s-node01 Ready node 75s v1.26.1
k8s-node02 Ready node 75s v1.26.1
部署K8S网络插件calico
本步骤主要完成网络插件calico部署(playbook:/etc/kubeasz/playbooks/06.network.yml,官方参考:https://github.com/easzlab/kubeasz/blob/master/docs/setup/06-install_network_plugin.md)
注意,calico部署主要是镜像下载,此处镜像默认已经下载到deploy服务器上,可以将此镜像传到本地harbor上,从本地镜像仓库进行拉取
在部署服务器已经运行了一个私有仓库(registry,5000端口监听)
root@K8S-deploy:/etc/kubeasz# docker images #部署服务器已经有calico镜像,共三个
REPOSITORY TAG IMAGE ID CREATED SIZE
registry 2 f5352b75f67e 41 hours ago 25.9MB
easzlab/kubeasz 3.5.2 857645a92187 3 months ago 182MB
easzlab/kubeasz-k8s-bin v1.26.1 f5cb65506fc7 3 months ago 1.17GB
easzlab/kubeasz-ext-bin 1.6.6 d9afe9272f6d 3 months ago 535MB
calico/kube-controllers v3.24.5 38b76de417d5 6 months ago 71.4MB
easzlab.io.local:5000/calico/kube-controllers v3.24.5 38b76de417d5 6 months ago 71.4MB
calico/cni v3.24.5 628dd7088041 6 months ago 198MB
easzlab.io.local:5000/calico/cni v3.24.5 628dd7088041 6 months ago 198MB
calico/node v3.24.5 54637cb36d4a 6 months ago 226MB
easzlab.io.local:5000/calico/node v3.24.5 54637cb36d4a 6 months ago 226MB
easzlab/pause 3.9 78d53e70b442 6 months ago 744kB
easzlab.io.local:5000/easzlab/pause 3.9 78d53e70b442 6 months ago 744kB
easzlab/k8s-dns-node-cache 1.22.13 7b3b529c5a5a 7 months ago 64.3MB
easzlab.io.local:5000/easzlab/k8s-dns-node-cache 1.22.13 7b3b529c5a5a 7 months ago 64.3MB
kubernetesui/dashboard v2.7.0 07655ddf2eeb 7 months ago 246MB
easzlab.io.local:5000/kubernetesui/dashboard v2.7.0 07655ddf2eeb 7 months ago 246MB
kubernetesui/metrics-scraper v1.0.8 115053965e86 11 months ago 43.8MB
easzlab.io.local:5000/kubernetesui/metrics-scraper v1.0.8 115053965e86 11 months ago 43.8MB
coredns/coredns 1.9.3 5185b96f0bec 11 months ago 48.8MB
easzlab.io.local:5000/coredns/coredns 1.9.3 5185b96f0bec 11 months ago 48.8MB
easzlab/metrics-server v0.5.2 f965999d664b 18 months ago 64.3MB
easzlab.io.local:5000/easzlab/metrics-server v0.5.2 f965999d664b 18 months ago 64.3MB
root@K8S-deploy:/etc/kubeasz# ss -tnl |grep 5000
root@K8S-deploy:/etc/kubeasz# lsof -i :5000 #registry程序运行的镜像仓库,也可以进行镜像分发
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
registry 4392 root 6u IPv6 63375 0t0 TCP *:5000 (LISTEN)
root@K8S-deploy:/etc/kubeasz# grep image: roles/calico/templates/calico-v3.24.yaml.j2 #这些镜像地址需要改为本地harbor地址
image: easzlab.io.local:5000/calico/cni:{{ calico_ver }}
image: easzlab.io.local:5000/calico/node:{{ calico_ver }}
image: easzlab.io.local:5000/calico/node:{{ calico_ver }}
image: easzlab.io.local:5000/calico/kube-controllers:{{ calico_ver }}
root@K8S-deploy:/etc/kubeasz# grep calico_ver clusters/k8s-cluster01/config.yml #查看calico_ver变量的值
root@K8S-deploy:/etc/kubeasz# echo "192.168.100.104 www.houlai.tech" >>/etc/hosts #添加harbor的域名解析
root@K8S-deploy:/etc/kubeasz# docker login www.houlai.tech #登录本地harbor
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
将calico的3个镜像重新打标签后上传到本地harbor:
root@K8S-deploy:/etc/kubeasz# docker tag easzlab.io.local:5000/calico/cni:v3.24.5 www.houlai.tech/baseimages/calico-cni:v3.24.5
root@K8S-deploy:/etc/kubeasz# docker tag easzlab.io.local:5000/calico/node:v3.24.5 www.houlai.tech/baseimages/calico-node:v3.24.5
root@K8S-deploy:/etc/kubeasz# docker tag easzlab.io.local:5000/calico/kube-controllers:v3.24.5 www.houlai.tech/baseimages/calico-kube-controllers:v3.24.5
root@K8S-deploy:/etc/kubeasz# docker push www.houlai.tech/baseimages/calico-cni:v3.24.5
The push refers to repository [www.houlai.tech/baseimages/calico-cni]
5f70bf18a086: Pushed
b3a0b0d29ccf: Pushed
a6b1c279d580: Pushed
67f6c44f5f9e: Pushed
af18e28a0eb7: Pushed
aa6df39249bf: Pushed
f8bda2d7bb4b: Pushed
7b09b9696e30: Pushed
deda2ebd5e37: Pushed
v3.24.5: digest: sha256:6d29e8402585431e5044ebddc70f19fe9c8a12d1f3651b12b7cd55407cbdebca size: 2196
root@K8S-deploy:/etc/kubeasz# docker push www.houlai.tech/baseimages/calico-node:v3.24.5
The push refers to repository [www.houlai.tech/baseimages/calico-node]
6ab78488a973: Pushed
928dad078487: Pushed
v3.24.5: digest: sha256:5c614b62b13d6a45826ea3ff72022be6aef7637198f8c1c83c2d2d547206a4a0 size: 737
root@K8S-deploy:/etc/kubeasz# docker push www.houlai.tech/baseimages/calico-kube-controllers:v3.24.5
The push refers to repository [www.houlai.tech/baseimages/calico-kube-controllers]
94bdfb9b7124: Pushed
24a4eecd61fd: Pushed
09319038a809: Pushed
f7e577921f19: Pushed
9cab0912bb98: Pushed
a52e3f04dc8c: Pushed
b8bf2f4e1d07: Pushed
ef82d1e1aaa1: Pushed
e8c4822d8639: Pushed
ed550b71315d: Pushed
3264ea6a9ecb: Pushed
v3.24.5: digest: sha256:b28b1820f9bce61688482d812be9bbd1a4b44aafcfa8150d0844a756767b0be1 size: 2613
修改calico的yaml配置文件中的镜像地址:
root@K8S-deploy:/etc/kubeasz# vi roles/calico/templates/calico-v3.24.yaml.j2 #修改以下4个地方
image: www.houlai.tech/baseimages/calico-cni:v3.24.5
image: www.houlai.tech/baseimages/calico-node:v3.24.5
image: www.houlai.tech/baseimages/calico-node:v3.24.5
image: www.houlai.tech/baseimages/calico-kube-controllers:v3.24.5
root@K8S-deploy:/etc/kubeasz# grep image: roles/calico/templates/calico-v3.24.yaml.j2 #确保镜像地址都已修改为本地镜像地址
image: www.houlai.tech/baseimages/calico-cni:v3.24.5
image: www.houlai.tech/baseimages/calico-node:v3.24.5
image: www.houlai.tech/baseimages/calico-node:v3.24.5
image: www.houlai.tech/baseimages/calico-kube-controllers:v3.24.5
root@K8S-deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 06 #执行第6步,安装网络插件calico,保证过程没有报错
node节点验证calico插件是否启动成功:
root@K8S-node01:~# calicoctl node status 确保都是Established,peer type是mesh,即网状结构,也就是3个节点都是互联的,通过相互自动学习路由来实现
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 192.168.100.101 | node-to-node mesh | up | 17:12:13 | Established |
| 192.168.100.102 | node-to-node mesh | up | 17:12:13 | Established |
| 192.168.100.122 | node-to-node mesh | up | 17:12:13 | Established |
+-----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
验证pod通信
将认证文件拷贝到master节点上:
root@K8S-master01:~# mkdir -pv /root/.kube/
root@K8S-deploy:/etc/kubeasz# scp /root/.kube/config 192.168.100.101:/root/.kube/
master节点进行管理;
root@K8S-master01:~# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 72m v1.26.1
k8s-master02 Ready,SchedulingDisabled master 72m v1.26.1
k8s-node01 Ready node 54m v1.26.1
k8s-node02 Ready node 54m v1.26.1
root@K8S-master01:~# vi /root/.kube/config #可以将API server地址执行HAPROXY的VIP
server: https://192.168.100.188:6443
root@K8S-master01:~# kubectl get node #验证VIP可以通信
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready,SchedulingDisabled master 74m v1.26.1
k8s-master02 Ready,SchedulingDisabled master 74m v1.26.1
k8s-node01 Ready node 56m v1.26.1
k8s-node02 Ready node 56m v1.26.1
创建测试pod验证pod跨主机通信
root@K8S-master01:~# kubectl run net-test1 --image=centos:7.9.2009 sleep 100000
pod/net-test1 created
root@K8S-master01:~# kubectl run net-test2 --image=centos:7.9.2009 sleep 100000
pod/net-test2 created
root@K8S-master01:~# kubectl run net-test3 --image=centos:7.9.2009 sleep 100000
pod/net-test3 created
root@K8S-master01:~# kubectl get pod -o wide #选择不同node上的pod进行测试
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
net-test1 1/1 Running 0 73s 10.200.154.65 k8s-node01 <none> <none>
net-test2 1/1 Running 0 68s 10.200.154.66 k8s-node01 <none> <none>
net-test3 1/1 Running 0 63s 10.200.165.129 k8s-node02 <none> <none>
root@K8S-master01:~# kubectl exec -it net-test1 bash #登录test1,验证和test3的通信
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@net-test1 /]# ping 8.8.8.8 #可以上网
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=48.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=127 time=48.4 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=127 time=48.4 ms
^C
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 48.410/48.421/48.439/0.012 ms
[root@net-test1 /]# ping 10.200.165.129 #和跨主机的test3可以通信
PING 10.200.165.129 (10.200.165.129) 56(84) bytes of data.
64 bytes from 10.200.165.129: icmp_seq=1 ttl=62 time=1.02 ms
64 bytes from 10.200.165.129: icmp_seq=2 ttl=62 time=0.572 ms
64 bytes from 10.200.165.129: icmp_seq=3 ttl=62 time=0.540 ms
^C
--- 10.200.165.129 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 0.540/0.712/1.026/0.224 ms
[root@net-test1 /]# ping www.baidu.com #主要,此时域名无法解析,因为dns没有安装
ping: www.baidu.com: Name or service not known
至此,K8S集群通过二进制方式进行高可用部署已经完成
K8S集群节点伸缩管理
集群管理主要包括:master、node、etcd节点的增加和删除以及监控当前集群状态
管理node节点
管理node节点,官方参考 https://github.com/easzlab/kubeasz/blob/master/docs/op/op-node.md
新增node节点
新增kube_node节点大致流程为:(参考playbook:/etc/kubeasz/playbooks/22.addnode.yml)
- [可选]新节点安装 chrony 时间同步
- 新节点预处理 prepare
- 新节点安装 container runtime
- 新节点安装 kube_node 服务
- 新节点安装网络插件相关
部署前需要提前在部署节点进行免密登录认证,此处扩展的node03(192.168.100.123)已经在之前做过认证:
root@K8S-deploy:~# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# ./ezctl add-node k8s-cluster01 192.168.100.123 #将192.168.100.123加入到k8s-cluster01集群的node节点,确保执行过程无报错
changed: [192.168.100.123]
TASK [calico : 下载calicoctl 客户端] **************************************************************************************************************************************************************************
changed: [192.168.100.123] => (item=calicoctl)
TASK [calico : 准备 calicoctl配置文件] *************************************************************************************************************************************************************************
changed: [192.168.100.123]
FAILED - RETRYING: 轮询等待calico-node 运行 (15 retries left).
TASK [calico : 轮询等待calico-node 运行] ***********************************************************************************************************************************************************************
changed: [192.168.100.123]
PLAY RECAP ***********************************************************************************************************************************************************************************************
192.168.100.123 : ok=82 changed=76 unreachable=0 failed=0 skipped=157 rescued=0 ignored=0
root@K8S-master01:~# kubectl get node #master上确认node添加
NAME STATUS ROLES AGE VERSION
192.168.100.123 Ready node 7m22s v1.26.1
k8s-master01 Ready,SchedulingDisabled master 3d10h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 3d10h v1.26.1
k8s-node01 Ready node 3d10h v1.26.1
k8s-node02 Ready node 3d10h v1.26.1
root@K8S-node03:~# calicoctl node status #验证节点calico状态
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 192.168.100.101 | node-to-node mesh | up | 04:31:04 | Established |
| 192.168.100.102 | node-to-node mesh | up | 04:31:04 | Established |
| 192.168.100.103 | node-to-node mesh | up | 04:31:04 | Established |
| 192.168.100.121 | node-to-node mesh | up | 04:31:04 | Established |
| 192.168.100.122 | node-to-node mesh | up | 04:31:04 | Established |
+-----------------+-------------------+-------+----------+-------------+
删除node节点
删除 node 节点流程:(参考playbook:/etc/kubeasz/playbooks/32.delnode.yml)
-
检测是否可以删除
-
迁移节点上的 pod(会驱逐节点pod)
-
删除 node 相关服务及文件
-
从集群删除 node
删除node操作:
root@K8S-deploy:/etc/kubeasz# ./ezctl del-node k8s-cluster01 192.168.100.123 #从集群中删除node03
TASK [run kubectl delete node 192.168.100.123] ***********************************************************************************************************************************************************
changed: [localhost]
TASK [remove the node's entry in hosts] ******************************************************************************************************************************************************************
changed: [localhost]
TASK [remove the node's entry in hosts] ******************************************************************************************************************************************************************
changed: [localhost]
PLAY RECAP ***********************************************************************************************************************************************************************************************
localhost : ok=12 changed=7 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
root@K8S-master01:~# kubectl get node #确认已删除node
NAME STATUS ROLES AGE VERSION
192.168.100.103 Ready,SchedulingDisabled master 68m v1.26.1
k8s-master01 Ready,SchedulingDisabled master 3d12h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 3d12h v1.26.1
k8s-node01 Ready node 3d11h v1.26.1
k8s-node02 Ready node 3d11h v1.26.1
root@K8S-deploy:/etc/kubeasz# vi /etc/kubeasz/clusters/k8s-cluster01/hosts #确保此文件中node03相关配置已清除,否则重新加入集群可能会失败,需要手动清除此文件中的node03相关配置
[kube_node]
192.168.100.121 k8s_nodename='K8S-node01'
192.168.100.122 k8s_nodename='K8S-node02'
root@K8S-node03:~# reboot #删完要重启node服务器,网络插件等需要重启才能删除干净
重新加入node节点
后面会用到node03,因此将node03重新加入到集群:
root@K8S-deploy:/etc/kubeasz# ./ezctl add-node k8s-cluster01 192.168.100.123
root@K8S-master01:~# kubectl get node #确保192.168.100.123重新加入集群
NAME STATUS ROLES AGE VERSION
192.168.100.103 Ready,SchedulingDisabled master 80m v1.26.1
192.168.100.123 Ready node 55s v1.26.1
k8s-master01 Ready,SchedulingDisabled master 3d12h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 3d12h v1.26.1
k8s-node01 Ready node 3d12h v1.26.1
k8s-node02 Ready node 3d12h v1.26.1
管理master节点
管理master节点,官方参考https://github.com/easzlab/kubeasz/blob/master/docs/op/op-master.md
新增master节点
新增kube_master节点大致流程为:(参考playbook:/etc/kubeasz/playbooks/23.addmaster.yml)
- [可选]新节点安装 chrony 时间同步
- 新节点预处理 prepare
- 新节点安装 container runtime
- 新节点安装 kube_master 服务
- 新节点安装 kube_node 服务
- 新节点安装网络插件相关
- 禁止业务 pod调度到新master节点
- 更新 node 节点 haproxy 负载均衡并重启
部署前需要提前在部署节点进行免密登录认证,此处扩展的mster03(192.168.100.103)已经在之前做过认证:
root@K8S-deploy:/etc/kubeasz# ./ezctl add-master k8s-cluster01 192.168.100.103 将192.168.100.103加入到k8s-cluster01集群的master节点,确保执行过程无报错
PLAY [kube_master,kube_node] *****************************************************************************************************************************************************************************
PLAY [localhost] *****************************************************************************************************************************************************************************************
PLAY RECAP ***********************************************************************************************************************************************************************************************
192.168.100.101 : ok=5 changed=3 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.102 : ok=5 changed=3 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.103 : ok=5 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.106 : ok=1 changed=0 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.107 : ok=1 changed=0 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.108 : ok=1 changed=0 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.121 : ok=5 changed=3 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.122 : ok=5 changed=3 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.123 : ok=5 changed=3 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
2023-05-15 11:11:45 INFO reconfigure and restart 'ex-lb' service
PLAY [ex_lb] *********************************************************************************************************************************************************************************************
skipping: no hosts matched
PLAY RECAP ***********************************************************************************************************************************************************************************************
root@K8S-master01:~# kubectl get node #确保192.168.100.103已经加入为master节点
NAME STATUS ROLES AGE VERSION
192.168.100.103 Ready,SchedulingDisabled master 44s v1.26.1
192.168.100.123 Ready node 23m v1.26.1
k8s-master01 Ready,SchedulingDisabled master 3d11h v1.26.1
k8s-master02 Ready,SchedulingDisabled master 3d11h v1.26.1
k8s-node01 Ready node 3d10h v1.26.1
k8s-node02 Ready node 3d10h v1.26.1
root@K8S-master03:~# calicoctl node status #验证calico状态
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 192.168.100.101 | node-to-node mesh | up | 03:11:20 | Established |
| 192.168.100.102 | node-to-node mesh | up | 03:11:41 | Established |
| 192.168.100.121 | node-to-node mesh | up | 03:12:05 | Established |
| 192.168.100.122 | node-to-node mesh | up | 03:11:54 | Established |
| 192.168.100.123 | node-to-node mesh | up | 04:31:04 | Established |
+-----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
root@K8S-node03:~# cat /etc/kube-lb/conf/kube-lb.conf #node节点验证将新加的master03已经更新到负载均衡配置里
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 192.168.100.103:6443 max_fails=2 fail_timeout=3s; #新加入的master节点加入后端转发
server 192.168.100.101:6443 max_fails=2 fail_timeout=3s;
server 192.168.100.102:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
root@K8S-node03:~# /etc/kube-lb/sbin/kube-lb -h #node节点的负载均衡器就是nginx
nginx version: nginx/1.22.1
Usage: nginx [-?hvVtTq] [-s signal] [-p prefix]
[-e filename] [-c filename] [-g directives]
Options:
-?,-h : this help
-v : show version and exit
-V : show version and configure options then exit
-t : test configuration and exit
-T : test configuration, dump it and exit
-q : suppress non-error messages during configuration testing
-s signal : send signal to a master process: stop, quit, reopen, reload
-p prefix : set prefix path (default: /usr/local/nginx/)
-e filename : set error log file (default: logs/error.log)
-c filename : set configuration file (default: conf/nginx.conf)
-g directives : set global directives out of configuration file
删除master节点
删除master 节点流程:(参考playbook:/etc/kubeasz/playbooks/33.delmaster.yml)
- 检测是否可以删除
- 迁移节点 pod
- 删除 master 相关服务及文件
- 删除 node 相关服务及文件
- 从集群删除 node 节点
- 从 ansible hosts 移除节点
- 在 ansible 控制端更新 kubeconfig
- 更新 node 节点 haproxy 配置
升级集群
K8S集群是二进制文件部署,因此升级K8S主要就是替换二进制文件,相同大版本基础上升级任意小版本,比如当前安装集群为1.26.1,可以方便的升级到任何1.26.x版本;不建议跨大版本升级,一般大版本更新时k8s api有一些变动,新版本二进制可能不支持某些参数和配置,同时部署在k8s pod中的资源对象会有版本升级,变为不支持,因此大版本升级前需要在测试环境查看资源对象版本的更新变化,这些资源对象可能需要重建
建议生产环境进行集群版本升级在业务低峰期进行,因为升级过程中会停服务,可能会进行pod驱逐,导致部分pod访问不了
root@K8S-master01:~# kubectl api-resources #查看资源对象
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
persistentvolumes pv v1 false PersistentVolume
pods po v1 true Pod
podtemplates v1 true PodTemplate
replicationcontrollers rc v1 true ReplicationController
resourcequotas quota v1 true ResourceQuota
secrets v1 true Secret
serviceaccounts sa v1 true ServiceAccount
services svc v1 true Service
mutatingwebhookconfigurations admissionregistration.k8s.io/v1 false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io/v1 false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io/v1 false CustomResourceDefinition
apiservices apiregistration.k8s.io/v1 false APIService
controllerrevisions apps/v1 true ControllerRevision
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
statefulsets sts apps/v1 true StatefulSet
tokenreviews authentication.k8s.io/v1 false TokenReview
localsubjectaccessreviews authorization.k8s.io/v1 true LocalSubjectAccessReview
selfsubjectaccessreviews authorization.k8s.io/v1 false SelfSubjectAccessReview
selfsubjectrulesreviews authorization.k8s.io/v1 false SelfSubjectRulesReview
subjectaccessreviews authorization.k8s.io/v1 false SubjectAccessReview
horizontalpodautoscalers hpa autoscaling/v2 true HorizontalPodAutoscaler
cronjobs cj batch/v1 true CronJob
jobs batch/v1 true Job
certificatesigningrequests csr certificates.k8s.io/v1 false CertificateSigningRequest
leases coordination.k8s.io/v1 true Lease
endpointslices discovery.k8s.io/v1 true EndpointSlice
events ev events.k8s.io/v1 true Event
flowschemas flowcontrol.apiserver.k8s.io/v1beta3 false FlowSchema
prioritylevelconfigurations flowcontrol.apiserver.k8s.io/v1beta3 false PriorityLevelConfiguration
ingressclasses networking.k8s.io/v1 false IngressClass
ingresses ing networking.k8s.io/v1 true Ingress
networkpolicies netpol networking.k8s.io/v1 true NetworkPolicy
runtimeclasses node.k8s.io/v1 false RuntimeClass
poddisruptionbudgets pdb policy/v1 true PodDisruptionBudget
clusterrolebindings rbac.authorization.k8s.io/v1 false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io/v1 false ClusterRole
rolebindings rbac.authorization.k8s.io/v1 true RoleBinding
roles rbac.authorization.k8s.io/v1 true Role
priorityclasses pc scheduling.k8s.io/v1 false PriorityClass
csidrivers storage.k8s.io/v1 false CSIDriver
csinodes storage.k8s.io/v1 false CSINode
csistoragecapacities storage.k8s.io/v1 true CSIStorageCapacity
storageclasses sc storage.k8s.io/v1 false StorageClass
volumeattachments storage.k8s.io/v1 false VolumeAttachment
此处从1.26.1升级到1.26.4:
下载1.26.4版本的二进制文件和源码包上传到部署节点:
Client Binaries:https://dl.k8s.io/v1.26.4/kubernetes-client-linux-amd64.tar.gz
Server Binaries:https://dl.k8s.io/v1.26.4/kubernetes-server-linux-amd64.tar.gz
Node Binaries:https://dl.k8s.io/v1.26.4/kubernetes-node-linux-amd64.tar.gz
Source Code:https://dl.k8s.io/v1.26.4/kubernetes.tar.gz
root@K8S-deploy:/etc/kubeasz# cd /usr/local/src
root@K8S-deploy:/usr/local/src# tar -xf kubernetes-node-linux-amd64.tar.gz
root@K8S-deploy:/usr/local/src# tar -xf kubernetes-client-linux-amd64.tar.gz
root@K8S-deploy:/usr/local/src# tar -xf kubernetes-server-linux-amd64.tar.gz
root@K8S-deploy:/usr/local/src# tar -xf kubernetes.tar.gz
root@K8S-deploy:/usr/local/src/kubernetes# cd server/bin/
root@K8S-deploy:/usr/local/src/kubernetes/server/bin# \cp kube-apiserver kube-controller-manager kube-scheduler kubectl kubelet kube-proxy /etc/kubeasz/bin/ #拷贝二进制文件到部署目录
root@K8S-deploy:/usr/local/src/kubernetes/server/bin# /etc/kubeasz/bin/kube-apiserver --version #验证版本
Kubernetes v1.26.4
#注意,如果跨大版本升级,需要提前查看是否需要提前修改配置文件里的部分参数
root@K8S-deploy:/usr/local/src/kubernetes/server/bin# cd /etc/kubeasz/
root@K8S-deploy:/etc/kubeasz# ./ezctl upgrade k8s-cluster01 #对所有节点进行批量升级,确保升级过程没有报错
TASK [kube-node : Setting worker role name] **************************************************************************************************************************************************************
changed: [192.168.100.123]
changed: [192.168.100.122]
changed: [192.168.100.121]
PLAY RECAP ***********************************************************************************************************************************************************************************************
192.168.100.101 : ok=48 changed=35 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
192.168.100.102 : ok=48 changed=36 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
192.168.100.103 : ok=52 changed=38 unreachable=0 failed=0 skipped=3 rescued=0 ignored=0
192.168.100.121 : ok=29 changed=20 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.122 : ok=29 changed=20 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
192.168.100.123 : ok=28 changed=19 unreachable=0 failed=0 skipped=3 rescued=0 ignored=0
root@K8S-master01:~# kubectl get node #确认升级后版本
NAME STATUS ROLES AGE VERSION
192.168.100.103 Ready,SchedulingDisabled master 4h v1.26.4
192.168.100.123 Ready node 160m v1.26.4
k8s-master01 Ready,SchedulingDisabled master 3d15h v1.26.4
k8s-master02 Ready,SchedulingDisabled master 3d15h v1.26.4
k8s-node01 Ready node 3d14h v1.26.4
k8s-node02 Ready node 3d14h v1.26.4
部署kubernetes 内部域名解析服务-CoreDNS:
K8S集群中⽬前常⽤的dns组件有kube-dns和coredns以及早期skyDNS(K8S1.1之前的早期版本) ,到k8s版本 1.17.X都可以使⽤, kube-dns和coredns⽤于解析k8s集群中service name所对应得到IP地址,从kubernetes v1.18开始不⽀持使⽤kube-dns(参考:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.18.md#kubeadm kube-dns is deprecated and will not be supported in a future version (#86574, @SataQiu) [SIG Cluster Lifecycle])。
部署coredns
coredns官网地址:https://coredns.io/
github地址:https://github.com/coredns/coredns
https://github.com/coredns/deployment/tree/master/kubernetes #部署coredns清单⽂件地址
可以提前将coredns相关镜像上传到本地harbor:
root@K8S-master01:~/20230416-cases/1.coredns# nerdctl pull coredns/coredns:1.9.4 #互联网拉取镜像
WARN[0000] skipping verifying HTTPS certs for "docker.io"
docker.io/coredns/coredns:1.9.4: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:b82e294de6be763f73ae71266c8f5466e7e03c69f3a1de96efd570284d35bb18: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:490711c06f083f563700f181b52529dab526ef36fdac7401f11c04eb1adfe4fd: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:a81c2ec4e946de3f8baa403be700db69454b42b50ab2cd17731f80065c62d42d: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:8f16f0bc6a9b0a6c4f176312d4edb4d2ce9bf05be1321a681f876733a228e9a9: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:c6824c7a0594e5640ccb153e26696a9f13919ea95bad5c91e43ae298868af828: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 10.8s
root@K8S-master01:~/20230416-cases/1.coredns# nerdctl tag coredns/coredns:1.9.4 www.houlai.tech/baseimages/coredns:1.9.4 #重新打标签
root@K8S-master01:~/20230416-cases/1.coredns# nerdctl login www.houlai.tech #登录本地harbor
Enter Username: admin
Enter Password:
WARN[0004] skipping verifying HTTPS certs for "www.houlai.tech"
WARNING: Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
root@K8S-master01:~/20230416-cases/1.coredns# nerdctl push www.houlai.tech/baseimages/coredns:1.9.4 #上传镜像到本地harbor
INFO[0000] pushing as a reduced-platform image (application/vnd.docker.distribution.manifest.list.v2+json, sha256:c5786b43be1d391702d4aebaa470f3d0d882f2e6aeb2184ac63082d292c06cfa)
WARN[0000] skipping verifying HTTPS certs for "www.houlai.tech"
index-sha256:c5786b43be1d391702d4aebaa470f3d0d882f2e6aeb2184ac63082d292c06cfa: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:490711c06f083f563700f181b52529dab526ef36fdac7401f11c04eb1adfe4fd: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:a81c2ec4e946de3f8baa403be700db69454b42b50ab2cd17731f80065c62d42d: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 0.6 s
root@K8S-master01:~# cd ~/20230416-cases/1.coredns/
root@K8S-master01:~/20230416-cases/1.coredns# cat coredns-v1.9.4.yaml #部署coredns的yaml文件,注意修改ClusterIP为集群的service网段地址、image地址为本地harbor地址
# __MACHINE_GENERATED_WARNING__
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
#forward . /etc/resolv.conf {
forward . 223.6.6.6 {
max_concurrent 1000
}
cache 600
loop
reload
loadbalance
}
myserver.online {
forward . 172.16.16.16:53
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: www.houlai.tech/baseimages/coredns:1.9.4 #修改为本地harbor地址
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 256Mi
cpu: 200m
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.100.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP
root@K8S-master01:~/20230416-cases/1.coredns# kubectl apply -f coredns-v1.9.4.yaml #部署coredns
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
root@K8S-master01:~/20230416-cases/1.coredns# kubectl get pod -A -o wide|grep coredns #确保coredns的pod运行正常
kube-system coredns-7b7bb6d7f6-6jswl 1/1 Running 0 2m8s 10.200.165.134 k8s-node02 <none> <none>
kube-system coredns-7b7bb6d7f6-c2bzm 1/1 Running 0 2m8s 10.200.140.194 192.168.100.123 <none> <none>
root@K8S-master01:~/20230416-cases/1.coredns# kubectl get svc -A #确保kube-dns的service正常,此处kube-dns即coredns,名称仍然沿用之前的kube-dns,不要修改
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 4d9h
kube-system kube-dns ClusterIP 10.100.0.2 <none> 53/UDP,53/TCP,9153/TCP 22m
测试域名解析
root@K8S-master01:~/20230416-cases/1.coredns# kubectl get pod -A|grep test
default net-test1 1/1 Running 0 43s
default net-test2 1/1 Running 0 37s
default net-test3 1/1 Running 0 32s
root@K8S-master01:~/20230416-cases/1.coredns# kubectl exec -it net-test1 bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@net-test1 /]# ping www.baidu.com #可以域名访问互联网
PING www.a.shifen.com (110.242.68.4) 56(84) bytes of data.
64 bytes from 110.242.68.4 (110.242.68.4): icmp_seq=1 ttl=127 time=11.5 ms
64 bytes from 110.242.68.4 (110.242.68.4): icmp_seq=2 ttl=127 time=11.6 ms
^C
--- www.a.shifen.com ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 11.582/11.601/11.620/0.019 ms
[root@net-test1 /]# cat /etc/resolv.conf #验证DNS为coredns的clusterip
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.100.0.2
options ndots:5
部署dashboard:
部署kubernetes的web管理界面dashboard,常用的有:K8S官方dashboard、rancher 、kuboard 、KubeSphere
kubernetes 官⽅dashboard
gitub地址:https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/web-ui-dashboard/
部署yaml文件地址:https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
部署dashboard-v2.7
在官方yaml文件查找images:相关镜像,下载dashboard相关镜像并上传到本地harbor仓库:
root@K8S-master01:~# nerdctl pull kubernetesui/metrics-scraper:v1.0.8
root@K8S-master01:~# nerdctl pull kubernetesui/dashboard:v2.7.0
root@K8S-master01:~# nerdctl tag kubernetesui/dashboard:v2.7.0 www.houlai.tech/baseimages/dashboard:v2.7.0
root@K8S-master01:~# nerdctl tag kubernetesui/metrics-scraper:v1.0.8 www.houlai.tech/baseimages/metrics-scraper:v1.0.8
root@K8S-master01:~# nerdctl push www.houlai.tech/baseimages/dashboard:v2.7.0
root@K8S-master01:~# nerdctl push www.houlai.tech/baseimages/metrics-scraper:v1.0.8
root@K8S-master01:~# cd /root/20230416-cases/2.dashboard-v2.7.0
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# vi dashboard-v2.7.0.yaml #修改image为本地harbor路径
image: www.houlai.tech/baseimages/dashboard:v2.7.0 #195行
image: www.houlai.tech/baseimages/metrics-scraper:v1.0.8 #281行
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
- --token-ttl=3600 #修改会话保持时间为1小时
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# kubectl apply -f dashboard-v2.7.0.yaml -f admin-user.yaml -f admin-secret.yaml #创建dashboard资源对象
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# kubectl get pod -n kubernetes-dashboard -o wide #确保dashboard相关容器运行正常,并查看运行在哪个node
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dashboard-metrics-scraper-6567d96d78-xv2ts 1/1 Running 0 16m 10.200.140.203 192.168.100.123 <none> <none>
kubernetes-dashboard-78bc64dc98-mjt84 1/1 Running 0 16m 10.200.154.85 k8s-node01 <none> <none>
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# kubectl get svc -n kubernetes-dashboard #查看node上映射端口
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.100.222.45 <none> 8000/TCP 17m
kubernetes-dashboard NodePort 10.100.233.25 <none> 443:30000/TCP 17m
在浏览器通过node节点IP访问dashboard:

获取token并登录dashboard:
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# kubectl get secrets -A #找到admin的secret
NAMESPACE NAME TYPE DATA AGE
kube-system calico-etcd-secrets Opaque 3 2d22h
kubernetes-dashboard dashboard-admin-user kubernetes.io/service-account-token 3 38m
kubernetes-dashboard kubernetes-dashboard-certs Opaque 0 38m
kubernetes-dashboard kubernetes-dashboard-csrf Opaque 1 38m
kubernetes-dashboard kubernetes-dashboard-key-holder Opaque 2 38m
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# kubectl describe secrets -n kubernetes-dashboard dashboard-admin-user #获取token自动并复制,去浏览器登录
通过token登录:

基于Kubeconfig⽂件登录 dashboard
可以将token字段添加到kubeconfig文件,然后下载到需要登录dashboard的物理机上即可
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# cp /root/.kube/config /opt/kubeconfig
root@K8S-master01:~/20230416-cases/2.dashboard-v2.7.0# vi /opt/kubeconfig #将token字段添加到最后,注意缩进
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjQwT1VVT0ZhXzdBdDljR0hDeEJmZnFLenFtNlV1WEtJb0hsbUNmYmQyYUUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdXNlciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbi11c2VyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYjg3MzZkOWUtOWUyZC00ODY4LWJiNmMtZDJkNDU2ZGJlMzM2Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmFkbWluLXVzZXIifQ.ZrkHNKTWuW_T6ANjMfC5lTfsf75QI1-GE-IiRemcLKYL_L7tY_8rEohgbsI44Ddo8pEG13wFvKXtfZpiTBN5qK-q4N6Zs4RpafYqJSQbuLMFqG-mjZr0KYD4X3E2nLBPpGQHbrjZUbJ9yHgYn9JlNG0IouzqGxkwd31NLlQUlt3fmpO2MGHkmjm0Cspeh2oKJW7xFxoVR-3VvnEZFDdoDh4AN7lZwAfTXk39jOqdeR74s0mJXObVJYMtUYL3ugb6XF0FDl2qWgq9QCthl3ExxzPL0SlPFnOtCWPIUgxIlfSIID0Xjgyau0taYgZWq-ip4IyZ2EZaLKBKDIq-ljUupQ
将/opt/kubeconfig下载到物理机,从浏览器登录dashboard选择kubconfig文件登录

rancher
参考文档:https://rancher.com/docs/rancher/v1.6/zh/
快速开始:https://rancher.com/docs/rancher/v1.6/zh/quick-start-guide/
kuboard
官方地址:https://kuboard.cn/
github地址:https://github.com/eip-work/kuboard-press
部署kuboard
部署kuboard有两种方式:单机部署和集群部署(跑在K8S集群中)
单机部署:
root@K8S-master01:~# docker run -d \
--restart=unless-stopped \
--name=kuboard \
-p 80:80/tcp \
-p 10081:10081/tcp \
-e KUBOARD_ENDPOINT="http://192.168.100.101:80" \
-e KUBOARD_AGENT_SERVER_TCP_PORT="10081" \
-v /root/kuboard-data:/data \
swr.cn-east-2.myhuaweicloud.com/kuboard/kuboard:v3
集群部署:
K8S中部署kuboard前需要提供存储类用来保存kuboard产生的数据,此处在harbor1上创建目录提供nfs存储
root@K8S-harbor01:~# apt update
root@K8S-harbor01:~# apt install nfs-server -y
root@K8S-harbor01:~# mkdir -p /data/k8sdata/kuboard
root@K8S-harbor01:~# vi /etc/exports
root@K8S-harbor01:~# systemctl restart nfs-server.service
root@K8S-harbor01:~# systemctl enable nfs-server
修改yaml文件并部署:
root@K8S-master01:~/20230416-cases# cd 3.kuboard
root@K8S-master01:~/20230416-cases/3.kuboard# cat kuboard-all-in-one.yaml #注意修改NFS存储的路径
---
apiVersion: v1
kind: Namespace
metadata:
name: kuboard
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations: {}
labels:
k8s.kuboard.cn/name: kuboard-v3
name: kuboard-v3
namespace: kuboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s.kuboard.cn/name: kuboard-v3
template:
metadata:
labels:
k8s.kuboard.cn/name: kuboard-v3
spec:
#affinity:
# nodeAffinity:
# preferredDuringSchedulingIgnoredDuringExecution:
# - preference:
# matchExpressions:
# - key: node-role.kubernetes.io/master
# operator: Exists
# weight: 100
# - preference:
# matchExpressions:
# - key: node-role.kubernetes.io/control-plane
# operator: Exists
# weight: 100
volumes:
- name: kuboard-data
nfs:
server: 192.168.100.104 #nfs服务器地址
path: /data/k8sdata/kuboard #nfs路径
containers:
- env:
- name: "KUBOARD_ENDPOINT"
value: "http://kuboard-v3:80"
- name: "KUBOARD_AGENT_SERVER_TCP_PORT"
value: "10081"
image: swr.cn-east-2.myhuaweicloud.com/kuboard/kuboard:v3
volumeMounts:
- name: kuboard-data
mountPath: /data
readOnly: false
imagePullPolicy: Always
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: kuboard
ports:
- containerPort: 80
name: web
protocol: TCP
- containerPort: 443
name: https
protocol: TCP
- containerPort: 10081
name: peer
protocol: TCP
- containerPort: 10081
name: peer-u
protocol: UDP
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
#dnsPolicy: ClusterFirst
#restartPolicy: Always
#serviceAccount: kuboard-boostrap
#serviceAccountName: kuboard-boostrap
#tolerations:
# - key: node-role.kubernetes.io/master
# operator: Exists
---
apiVersion: v1
kind: Service
metadata:
annotations: {}
labels:
k8s.kuboard.cn/name: kuboard-v3
name: kuboard-v3
namespace: kuboard
spec:
ports:
- name: web
nodePort: 30080
port: 80
protocol: TCP
targetPort: 80
- name: tcp
nodePort: 30081
port: 10081
protocol: TCP
targetPort: 10081
- name: udp
nodePort: 30081
port: 10081
protocol: UDP
targetPort: 10081
selector:
k8s.kuboard.cn/name: kuboard-v3
sessionAffinity: None
type: NodePort
root@K8S-master01:~/20230416-cases/3.kuboard# kubectl apply -f kuboard-all-in-one.yaml #部署kuboard
namespace/kuboard created
deployment.apps/kuboard-v3 created
service/kuboard-v3 created
root@K8S-master01:~/20230416-cases/3.kuboard# kubectl get pod -A -o wide|grep kuboard #确认kuboard的pod运行正常以及node的IP
kuboard kuboard-v3-d5c68b7d6-9hdz7 1/1 Running 0 7m9s 10.200.165.139 k8s-node02 <none> <none>
物理机浏览器访问node2的30080端口:http://192.168.100.122:30080/,默认用户名:admin,密码: Kuboard123


默认没有任何集群的信息,需要手动导入,点击添加集群,有两种方式当如,.kubeconfig(无需创建agent)和agent方式(需要在集群中创建kuboard agent),此处采用.kubeconfig方式:
root@K8S-master01:~/20230416-cases/3.kuboard# cat ~/.kube/config #根据提示将内容粘贴到浏览器

导入完成后,选择kuboard-admin角色,点击集群概要,可以在此对集群进行管理

卸载kuboard:
root@K8S-master01:~/20230416-cases/3.kuboard# kubectl delete -f kuboard-all-in-one.yaml
namespace "kuboard" deleted
deployment.apps "kuboard-v3" deleted
service "kuboard-v3" deleted
KubeSphere
KubeSphere是青云开发并开源的项目,是较为重量级的产品,官网地址:https://www.kubesphere.io/
部署KubeSphere
快速部署:https://www.kubesphere.io/zh/docs/v3.3/quick-start/
通常部署KubeSphere可以分为两种:
1)完全从零开始,K8S集群本身也是由KubeSphere来创建
2)在K8s集群上部署KubeSphere
此处采用第二种方法,我们的K8S集群已经提前创建好了
部署前需要我们自己创建好存储类,此处以NFS为例(在harbor1上共享目录):
root@K8S-harbor01:~# mkdir -pv /data/volumes
root@K8S-harbor01:~# echo "/data/volumes *(rw,no_root_squash)" >>/etc/exports
root@K8S-harbor01:~# exportfs -av #重新导出共享目录
创建NFS存储类(确保以下三个yaml文件执行):
root@K8S-master01:~# cd 20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases/
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# cat 1-rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: nfs
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# cat 2-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
#name: managed-nfs-storage
name: nfs-csi
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # or choose another name, must match deployment's env PROVISIONER_NAME'
reclaimPolicy: Retain #PV的删除策略,默认为delete,删除PV后立即删除NFS server的数据
mountOptions:
#- vers=4.1 #containerd有部分参数异常
#- noresvport #告知NFS客户端在重新建立网络连接时,使用新的传输控制协议源端口
- noatime #访问文件时不更新文件inode中的时间戳,高并发环境可提高性能
parameters:
#mountOptions: "vers=4.1,noresvport,noatime"
archiveOnDelete: "true" #删除pod时保留pod数据,默认为false时为不保留数据
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# cat 3-nfs-provisioner.yaml #注意NFS路径
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: nfs
spec:
replicas: 1
strategy: #部署策略
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
#image: k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
image: registry.cn-qingdao.aliyuncs.com/zhangshijie/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.100.104
- name: NFS_PATH
value: /data/volumes
volumes:
- name: nfs-client-root
nfs:
server: 192.168.100.104
path: /data/volumes
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# kubectl apply -f 1-rbac.yaml
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# kubectl apply -f 2-storageclass.yaml
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# kubectl apply -f 3-nfs-provisioner.yaml
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# kubectl get pod -A|grep nfs #确保nfs这个pod正常
nfs nfs-client-provisioner-6f9c7fc695-rf7vz 1/1 Running 0 47s
root@K8S-master01:~/20230416-cases/4.KubeSphere/1.nfs-stroageclass-cases# kubectl get storageclasses.storage.k8s.io #确保存储类正常
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi (default) k8s-sigs.io/nfs-subdir-external-provisioner Retain Immediate false 98s
存储类部署完成后,开始根据官方教程在K8S上进行最小化安装KubeSphere
参考文档https://www.kubesphere.io/zh/docs/v3.3/installing-on-kubernetes/introduction/overview/
需要下载官方的两个yaml文件到本地:默认最小化安装,可以在yaml文件中修改需要安装的组件,可选插件参考:https://www.kubesphere.io/zh/docs/v3.3/pluggable-components/。可选插件既可以在安装kubesphere时部署,或者在安装完成后在web页面进行启用
https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/kubesphere-installer.yaml
https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/cluster-configuration.yaml
安装过程中可以查看安装日志:
# kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
此处进行最小化安装,不启用插件,安装前建议将node节点调整为4C8G:
root@K8S-master01:~# cd 20230416-cases/4.KubeSphere/
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl apply -f kubesphere-installer.yaml
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl apply -f cluster-configuration.yaml
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get pod -A -o wide |grep kubesphere #确保这个pod成功并正常运行
kubesphere-system ks-installer-fcf648dcb-2p8rb 1/1 Running 0 2m43s 10.200.140.207 192.168.100.123 <none> <none>
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f #查看安装日志
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get pod -A -o wide|grep console #console的pod运行起来后可以通过node访问前端页面
kubesphere-system ks-console-68769fccc6-6fp5z 1/1 Running 0 5m34s 10.200.154.90 k8s-node01 <none> <none>
kubesphere-system ks-console-68769fccc6-f27l2 1/1 Running 0 5m34s 10.200.165.142 k8s-node02 <none> <none>
kubesphere-system ks-console-68769fccc6-zwwl7 1/1 Running 0 5m34s 10.200.140.209 192.168.100.123 <none> <none>
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get svc -A|grep console #查看node端口为30880
kubesphere-system ks-console NodePort 10.100.208.31 <none> 80:30880/TCP 6m58s
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get pod -A|grep kubesphere #确保kubesphere相关所有pod运行正常
kubesphere-controls-system default-http-backend-864f4f5c6b-xj8mp 1/1 Running 0 19m
kubesphere-controls-system kubectl-admin-c6988866d-hhw2c 1/1 Running 0 11m
kubesphere-monitoring-system kube-state-metrics-8c877c9db-fktnf 3/3 Running 0 16m
kubesphere-monitoring-system node-exporter-285ht 2/2 Running 0 16m
kubesphere-monitoring-system node-exporter-427vt 2/2 Running 0 16m
kubesphere-monitoring-system node-exporter-ccvvt 2/2 Running 0 16m
kubesphere-monitoring-system node-exporter-cv8vz 2/2 Running 0 16m
kubesphere-monitoring-system node-exporter-f8qtv 2/2 Running 0 16m
kubesphere-monitoring-system node-exporter-nkhpx 2/2 Running 0 16m
kubesphere-monitoring-system prometheus-k8s-0 2/2 Running 0 15m
kubesphere-monitoring-system prometheus-k8s-1 2/2 Running 0 15m
kubesphere-monitoring-system prometheus-operator-845b8fb9df-8chpd 2/2 Running 0 16m
kubesphere-system ks-apiserver-5cd88dfbc5-72kp6 1/1 Running 0 19m
kubesphere-system ks-apiserver-5cd88dfbc5-j6sph 1/1 Running 0 19m
kubesphere-system ks-apiserver-5cd88dfbc5-msvkc 1/1 Running 0 19m
kubesphere-system ks-console-68769fccc6-6fp5z 1/1 Running 0 19m
kubesphere-system ks-console-68769fccc6-f27l2 1/1 Running 0 19m
kubesphere-system ks-console-68769fccc6-zwwl7 1/1 Running 0 19m
kubesphere-system ks-controller-manager-55fdd48f88-98rpm 1/1 Running 0 19m
kubesphere-system ks-controller-manager-55fdd48f88-ghj5n 1/1 Running 0 19m
kubesphere-system ks-controller-manager-55fdd48f88-kktl2 1/1 Running 0 19m
kubesphere-system ks-installer-fcf648dcb-2p8rb 1/1 Running 0 23m
kubesphere-system redis-64bf76657c-njxgj 1/1 Running 0 21m
登录KubeSphere:
通过 NodePort (IP:30880) 使用默认帐户和密码 (admin/P@88w0rd) 访问 Web 控制台。


点击左上角平台管理-》集群管理:

启用服务网格
可以在web页面启用服务网格:点击定制资源定义,搜索clusterconfiguration,点进去,点击 ks-installer 右侧的 ,选择编辑 YAML,在该配置文件中,搜索 servicemesh,并将 enabled 的 false 改为 true。完成后,点击右下角的确定,保存配置。
,选择编辑 YAML,在该配置文件中,搜索 servicemesh,并将 enabled 的 false 改为 true。完成后,点击右下角的确定,保存配置。



点解确定后,可以在后台查看日志:
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
暴露prometheus:
默认无法从K8S集群外部访问prometheus,可以将其暴露出来通过node节点访问:
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get svc -A |grep prometheus #默认没有暴露
kubesphere-monitoring-system prometheus-k8s ClusterIP 10.100.78.43 <none> 9090/TCP,8080/TCP 27m
kubesphere-monitoring-system prometheus-operated ClusterIP None <none> 9090/TCP 26m
kubesphere-monitoring-system prometheus-operator ClusterIP None <none> 8443/TCP 27m
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl edit svc -n kubesphere-monitoring-system prometheus-k8s #编辑sevice进行端口暴露,只将type从ClusterIP改为NodePort即可
type: NodePort #修改此处,51行
root@K8S-master01:~/20230416-cases/4.KubeSphere# kubectl get svc -A |grep prometheus #取人9090和8080端口已暴露
kubesphere-monitoring-system prometheus-k8s NodePort 10.100.78.43 <none> 9090:49809/TCP,8080:58317/TCP 35m
kubesphere-monitoring-system prometheus-operated ClusterIP None <none> 9090/TCP 34m
kubesphere-monitoring-system prometheus-operator ClusterIP None <none> 8443/TCP 35m
通过node节点暴露的49809端口在浏览器访问prometheus:

卸载kubesphere:
# kubectl delete statefulsets.apps -n kubesphere-logging-system elasticsearchlogging-data
# kubectl delete statefulsets.apps -n kubesphere-logging-system elasticsearchlogging-discovery
# kubectl delete statefulsets.apps -n kubesphere-system openldap
# kubectl delete daemonsets.apps -n kubesphere-monitoring-system node-exporter
#
4.KubeSphere# ./delete.sh
4.KubeSphere# kubectl get pv | awk '{print $1}'
4.KubeSphere# kubectl delete pv PV-NAME

 浙公网安备 33010602011771号
浙公网安备 33010602011771号