ETL工具之Kettle使用方法
一、Kettle 简介
1.1、Kettle是什么
Kettle是一款国外开源的ETL工具,纯Java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,Transformation和Job,transformation完成针对数据的基础转换,Job则完成整个工作流的控制。
Kettle,现在已经更名为PDI(Pentaho Data Integration-Pentaho,即数据集成)。
1.2、Kettle的特点
- 无代码拖拽式构建数据管道
Kettle采用拖拽组件、连线、配置的方式来构建数据管道,透过超过200个不同的组件,用户可以在不编写一句代码就能轻松完成对数据源读取,对数据进行关联、过滤、格式转换、计算、统计、建模、挖掘、输出到不同的数据目标。极大程度地降低开发技术门槛和有效减低开发和维护成本。
- 多数据源对接
- 关系型数据库支持类型包括:AS/400,DB2,Google BigQuery,Greenplum,Hive,Impala,MS SQL Server,MySQL,Oracle,PostgreSQL,SAP,Snowflake,SparkSQL,Sybase,Teradata, Vertica等。
- 大数据源支持包括:Avro,Cassanddra,HBase,HDFS,MongoDB,ORC, Parquet, Splunk等。
- 文件格式支持包括:CSV, TXT, JSON, Excel, XML等。
- 流数据支持包括:AMPQ,JMS,Kafka,Kinesis,MQTT。
- 其他数据源对接包括:HL7,S3,SAS,Salesforce,HCP,REST等。
- 数据管道可视化
Kettle支持用户在数据管道任何一个步骤对当前数据进行查看(Examine),并可以在线以表格和图表(例如:柱状图、饼图等)输出步骤的数据,甚至可以支持不落地直接把任何一个步骤的数据以JDBC的方式提供给第三方应用访问。
- 模板化开发数据管道
Kettle提供了一个叫MDI的功能,MDI全称是Metadata Injection元数据注入,用户可以透过MDI把数据转换模板化,然后把像数据表名、文件路径、分隔符、字符集等等这些变量放在一个表或者文件里,然后利用MDI把这些变量注入数据转换模板,Kettle就能够自动生成所需要的数据转换了。这个功能为很多客户节省了大量的开发时间。
- 可视化计划任务
- Kettle提供可视化方式配置任务计划(Schedule),用户可透过Spoon或网页端的Pentaho User Console来配置和维护任务具体的执行时间、间隔、所使用的参数值、以及具体运行的服务器节点。
- 用户亦可以透过Spoon或Pentaho User Console查看任务计划列表;当然,用户也可以透过Spoon或Pentaho User Console对任务执行情况进行实时监控。
- 深度Hadoop支持
- Kettle针对Hadoop主流厂家预置专用的对接插件,支持的Hadoop版本包括Cloudera,Hortonworks,AWS EMR,Google Dataproc等,用户除了可以透过插件轻松对接Hadoop集群的数据源(HDFS,Hive,HBase,Impala等)以外,Pentaho还提供与Kerberos、Sentry和Ranger等Hadoop企业级安全机制对接,以满足企业安全要求。
- 另外,Pentaho Data Integration的Pentaho MapReduce提供用户以无编码方式定义MapReduce任务;同时,用户亦可以在作业中执行Sqoop、Pig、MapReduce、Oozie和Spark任务。
- 数据任务下压Spark集群
Kettle提供了把数据转换任务下压到Spark来执行的AEL(Adaptive Execution Layer)功能,搭建好的数据管道会被AEL转成Spark任务来执行,这样数据就不需要离开集群,而是在集群里透过Spark强大的分布式处理能力来进行处理。
- 数据挖掘与机器学习支持
- 最新版的Pentaho9.1预置了超过20种数据挖掘算法类的转换步骤,用户可以轻松把把机器学习集成到数据管道里,用来做数据模型训练和进行预测分析。
- 预置算法包括:决策树、深度学习、线性回归、逻辑回归、Naive贝尔斯、随机森林等等,用户也可以利用Pentaho Data Integration作数据预备,然后把数据以dataframe的方式输入到Python或R中进行模型训练或预测。
1.3、Kettle核心组件
- Spoon
Spoon是构建ETL Jobs和Transformations的工具。Spoon以拖拽的方式图形化设计,能够通过spoon调用专用的数据集成引擎或者集群。
- Pan
Pan是一个后台执行的程序,没有图形界面,类似于时间调度器。
- chef
任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。
- Kitchen
批量使用由Chef设计的任务。
二、Kettle 安装与部署
2.1、下载
Kettle官方网址:Home - Hitachi Vantara,目前最新是9.2版本的。
进入官网后选择 –>Data Integration,找到Downloads,看到稳定版本为Data Integration 8.2,选择进行下载即可。
2.2、安装
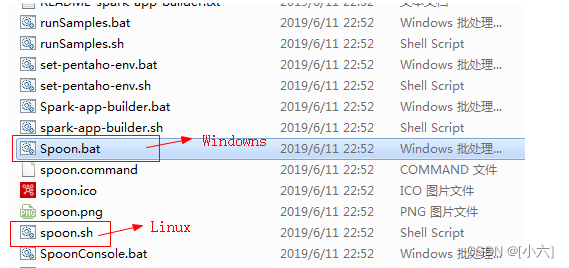
- 下载好的压缩包进行解压

- 打开解压之后的data-integration文件夹

- Windows系统,点击Spoon.bat运行;Linux系统点击Spoon.sh运行
2.3、环境变量配置
因为Kettle是纯Java开发的,因此下载以后需要配置一下环境变量。需要先安装JDK,准备好Java软件的运行环境,安装jdk1.8版本即可,具体操作可参考百度。
2.4、常见问题
- 启动Kettle后,页面右上角不出现Connect。
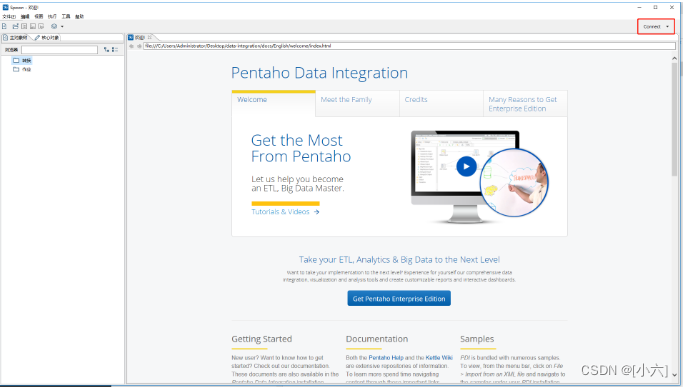
解决方法:打开系统盘用户目录下的repositories.xml配置文件,将乱码内容删除,并删除.spoonrc文件,重启Kettle。
2、可视化界面spoon.bat打不开,JVM提示不能正常启动
解决方法:
- 检查环境变量的配置
- 检查JDK版本,新版本最好用1.6以上
- 新安装了高版本jdk,环境变量也没问题,但是java -version 版本还是老的,那就检查一下原版本的的快捷方式java.exe还在不在,在的话就删掉。
- 以文本方式打开spoon.bat ,修改内存配置
3、连接数据库找不到驱动问题(以MySQL为例)
提示错误:
[mysql] : org.pentaho.di.core.exception.KettleDatabaseException:
Error occured while trying to connect to the database
Driver class ‘org.gjt.mm.mysql.Driver’ could not be found, make sure the ‘MySQL’ driver (jar file) is installed.
org.gjt.mm.mysql.Driver
解决办法:把mysql-connector-java-5.1.37-bin.jar拷贝到 \\pdi-ce-6.0.1.0-386\data-integration\lib下面,然后重新启动spoon即可。
三、Kettle 运行界面与基本概念
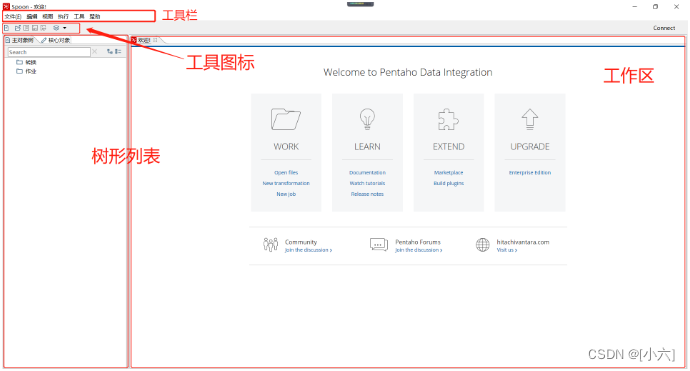
3.1、运行界面
3.2、基本概念
1)可视化编程
Kettle可以被归类为可视化编程语言(Visual Programming Languages,VPL),因为Kettle可以使用图形化的方式定义复杂的ETL程序和工作流。
Kettle里的图就是转换和作业。
可视化编程一直是Kettle里的核心概念,它可以让你快速构建复杂的ETL作业和减低维护工作量,它通过隐藏很多技术细节,使IT领域更贴近与商务领域。
2)转换(Transformation)
- 转换是ETL解决方案中最主要的部分,它处理抽取、转换、加载各种对数据行的操作。
- 转换包含一个或多个步骤(step),如读取文件、过滤数据行、数据清洗或将数据加载到数据库。
- 转换里的步骤通过跳(hop)来连接,跳定义一个单向通道,允许数据从一个步骤向另一个步骤流动。
- 在Kettle里,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
- 数据流有的时候也被称之为记录流。
3)步骤(Step)
Kettle里面的,Step步骤(控件)是转换里的基本的组成部分。一个步骤有如下几个关键特性:
- 步骤需要有一个名字,这个名字在转换范围内唯一。
- 每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)。
- 步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。
- 大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
4)跳(Hop)
Kettle里面的跳即步骤之间带箭头的连线,跳定义了步骤之间的数据通路。

- 跳实际上是两个步骤之间的被称之为行集的数据行缓存(行集的大小可以在转换的设置里定义)。
- 当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。
- 当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
5)数据行——数据类型
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
- String:字符类型数据
- Number:双精度浮点数。
- Integer:带符号长整型(64位)。
- BigNumber:任意精度数据。
- Date:带毫秒精度的日期时间值。
- Boolean:取值为true和false的布尔值。
- Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据。
6)数据行——元数据
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。通常包含下面一些信息。
- 名称:行里的字段名应用是唯一的。
- 数据类型:字段的数据类型。
- 格式:数据显示的方式,如Integer的#、0.00。
- 长度:字符串的长度或者BigNumber类型的长度。
- 精度:BigNumber数据类型的十进制精度。
- 货币符号:¥。
- 小数点符号:十进制数据的小数点格式。不同文化背景下小数点符号是不同的,一般是点(.)或逗号(,)。
- 分组符号:数值类型数据的分组符号,不同文化背景下数字里的分组符号也是不同的,一般是点(.)或逗号(,)或单引号(’)。
7)日志——I O R W U E
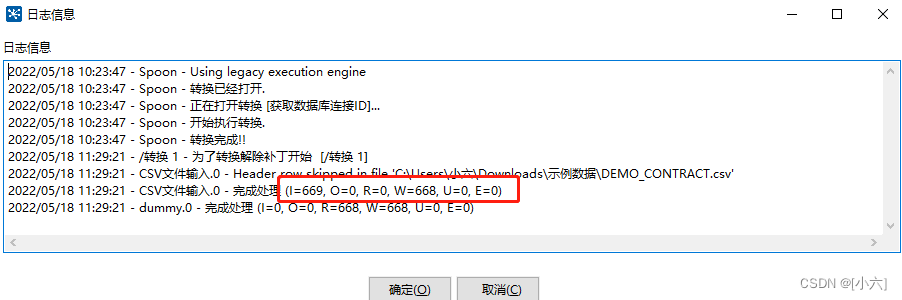
(I=669, O=0, R=0, W=668, U=0, E=0)
I 是指当前 (步骤) 生成的记录(从表输入、文件读入)
O 是指当前 (步骤) 输出的记录数(输出到文件、表)
R 是指当前 (步骤) 从前一步骤读取的记录数
W 是指当前 (步骤) 向后面步骤抛出的记录数
U 是指当前 (步骤) 更新过的记录数
E 是指当前 (步骤) 处理的记录数
四、Kettle 读取CSV文件
4.1、输入
就是用来抽取数据或生成数据的操作。是ETL操作的E(Extraction)。
4.2、CVS文件
是一种带有固定格式的文本文件。
假设我们的目的是读取 CSV 文件,在 Excel 中输出。当然,这种简单操作完全不需要 Kettle,Excel 直接就可以打开并转换。练习的目的是从易到难,逐步掌握 Kettle 的用法。
CSV 文件是一种常见的文本文件,一般含有表头和行项目。大多数数据处理型软件都含有对 CSV 格式的支持。进入 Spoon 的主界面,通过菜单 [文件] –> [新建] –> [转换] 新建一个转换。
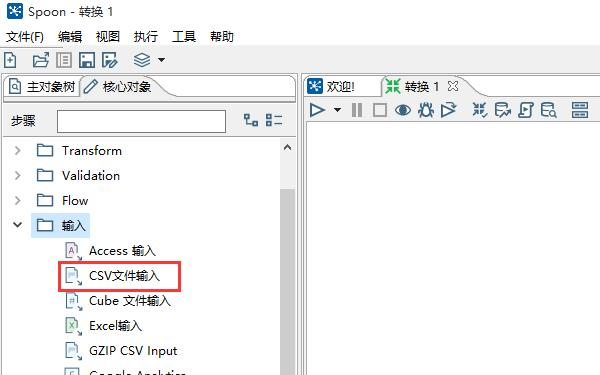
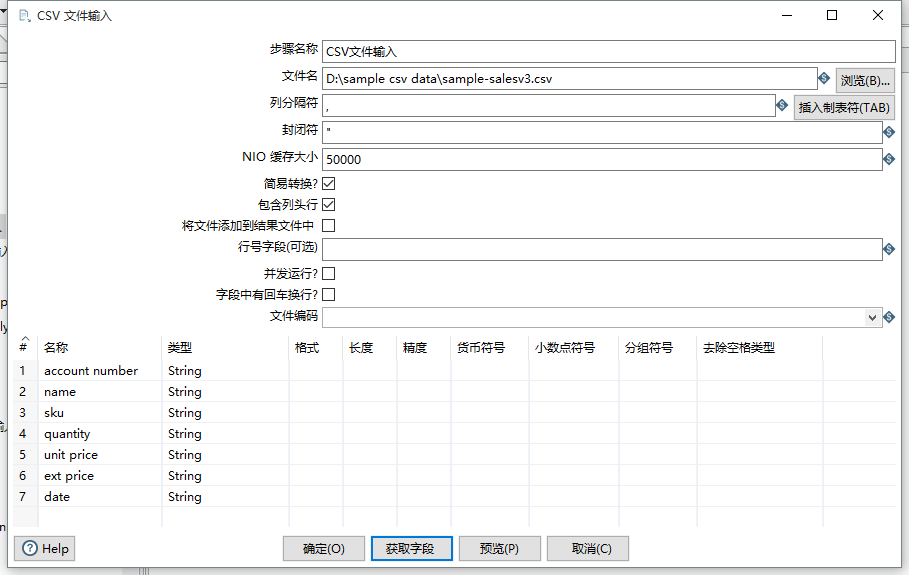
在左边的核心对象中,找到输入文件夹下面的CSV文件输入,将其拖到右边的工作区。双击CSV文件输入图标,通过浏览按钮找到 想要读取的 CSV 文件:
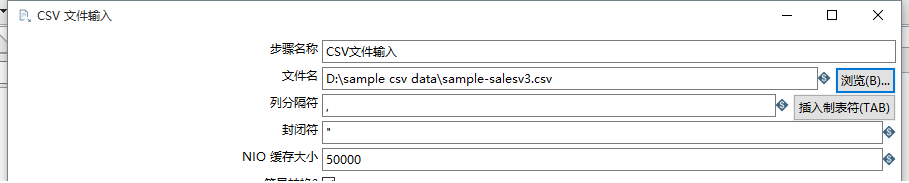
点击对话框中的 “获取字段” 按钮,自动获得 CSV 文件各列的表头。之所以可以这样,是因为 “包含列头行” 默认选中。点击 “预览” 按钮可以预览数据。如果是中文,注意文件的编码。
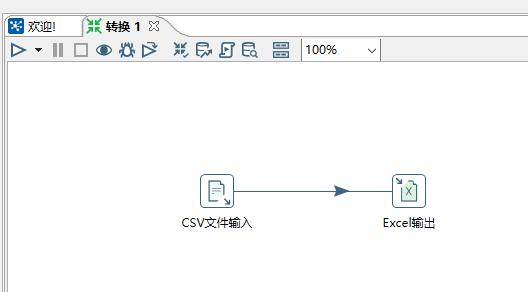
在左边导航区的 “输出” 文件夹下,将 “Excel输出” 步骤拖放到右边的工作区。选中步骤 “CSV文件输入”,通过 shift+鼠标拖动,连接两个步骤,此时界面如下:
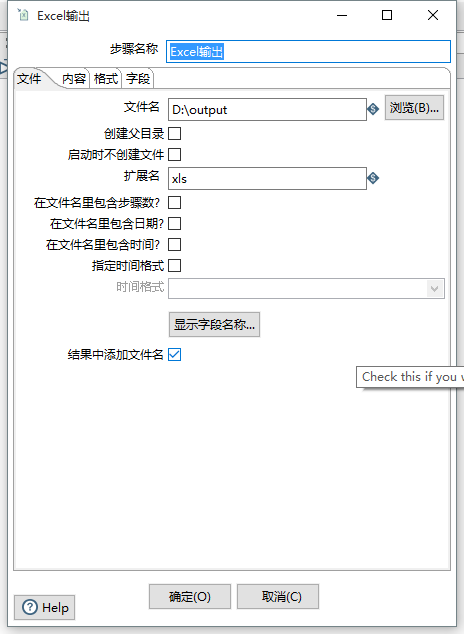
双击 “Excel输出”,设置文件名和扩展名:
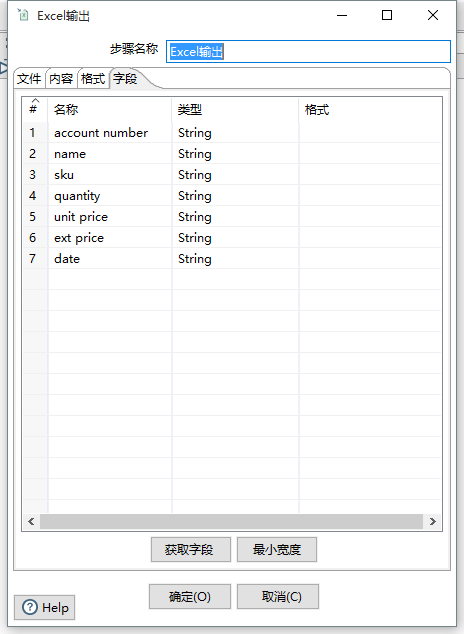
切换到 “字段” 页签,点击 “获取字段” 按钮,获取需要输出的字段,可以删除不想要的字段,然后点击 “确定” 按钮:
运行之前保存,转换被保存为扩展名为 ktr 的文件,这个文件是 xml 格式的文本文件,可以用 spoon 打开。然后点击 “运行”,即可以将 CSV 文件转换成 Excel 文件。
4.3、多个文件输入
在导航区 “核心对象” 中,找到 “输入” 文件夹下 “获取文件名”,拖到工作区。设置如下:
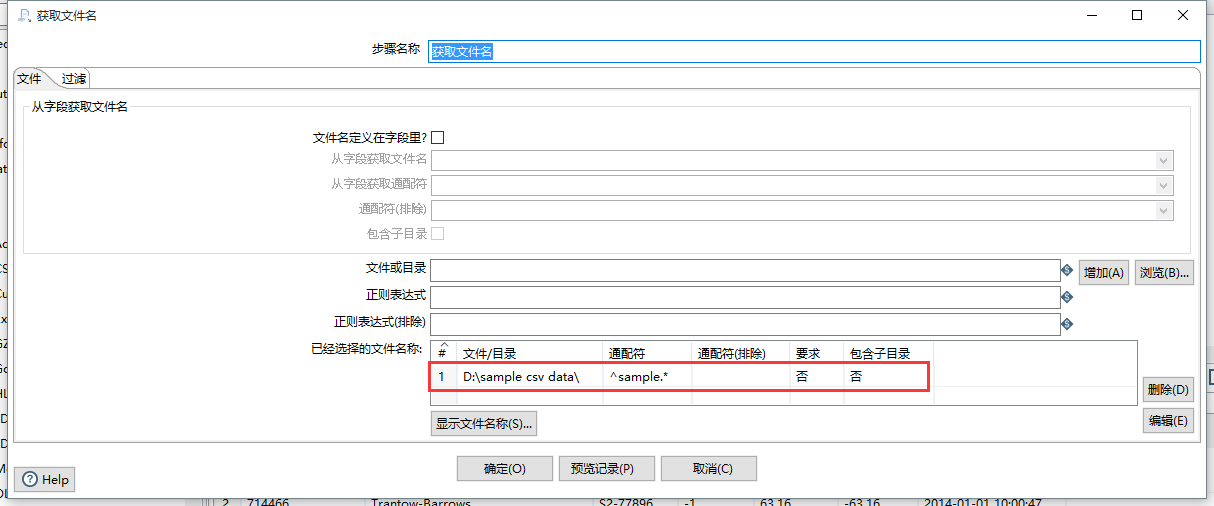
点击 “预览记录” 按钮,查看包含的文件,两个文件都被读取到。filename 是在下一步要使用的文件路径,属于输出的变量。
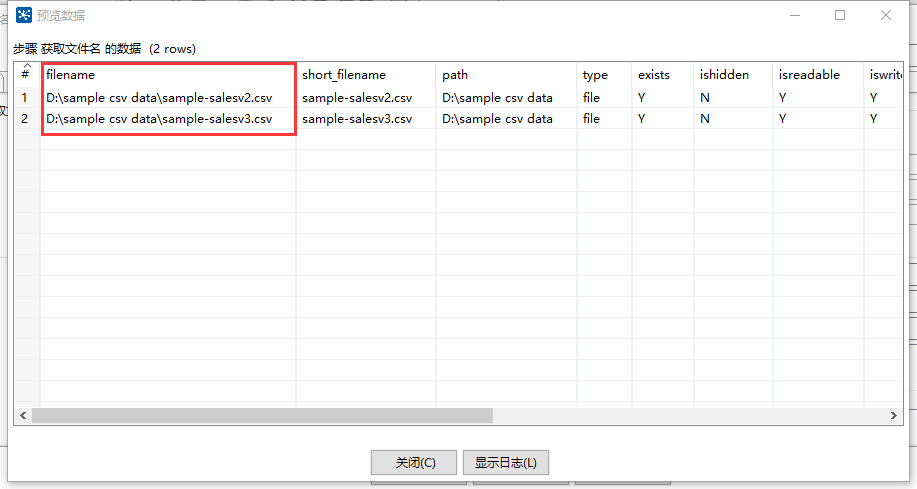
将 “获取文件名” 步骤连接至 “CSV文件输入” 步骤。此时,“CSV文件输入” 步骤的界面中,文件名字段为数据来源于前一步骤,选择 filename。其他相同。
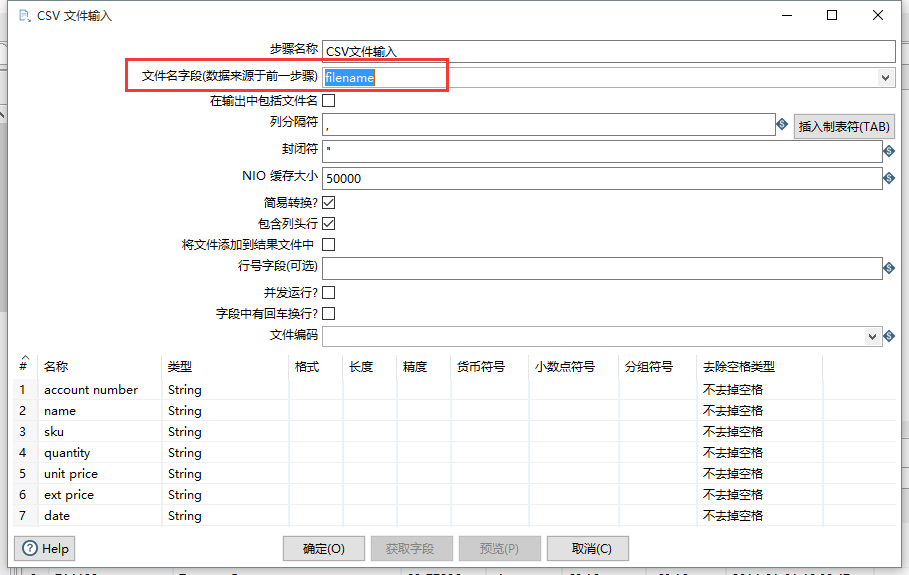
运行,可以把两个 CSV 文件中的数据加载并输出到 Excel 文件中。输入的文件格式,比如文本文件、Excel 文件大体类似。
五、Kettle 导入文件夹下的多个文件
5.1、任务描述
在一个文件夹下有几百个文本文件,每个文件内容的格式相同,都是有固定分隔符的两列,每个文件有几千行记录。
Kettle的转换处理数据流,其中有一个“文本文件输入”的输入对象,可以使用它在导入文件数据时添加上文件名字段,而且支持正则表达式同时获取多个文件名,正好适用此场景。
5.2、操作过程
1. 新建一个转换
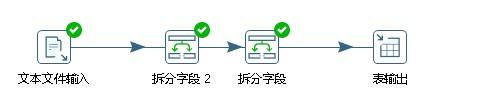
包含“获取文件名”、“拆分字段2”、“拆分字段”、“表输出”四个步骤,如下图所示。

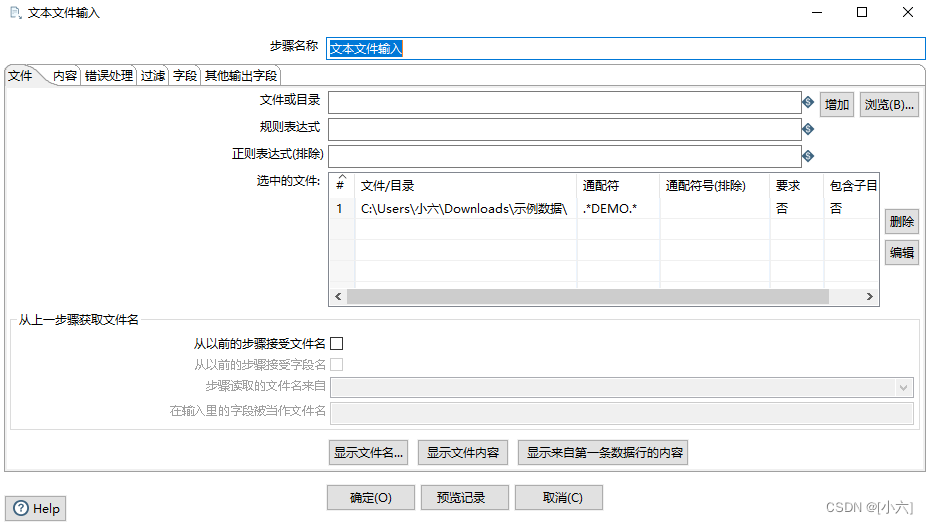
2. “文本文件输入”
如下图所示。 正则表达式.*test.* 意思是查找以test开头的文件。
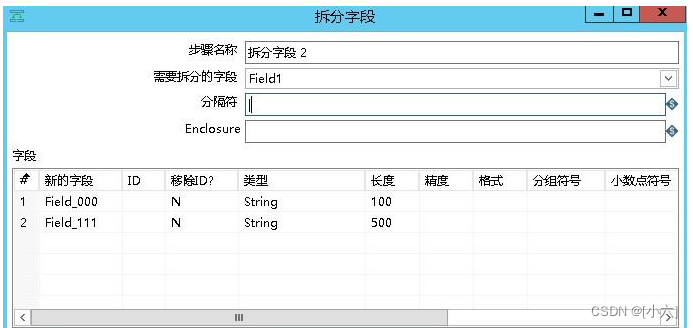
3.拆分字段
按照分隔符“|”将字段field_1拆成field_000和field_111
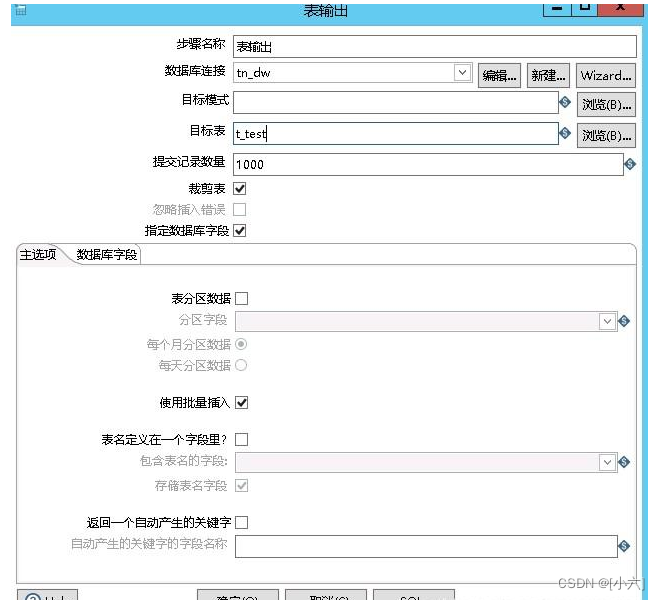
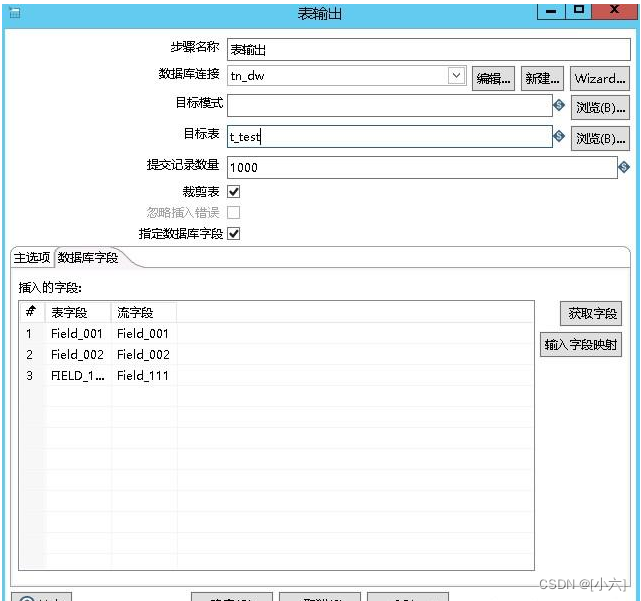
5.表输出
6.启动运行
六、Kettle 创建数据库连接
6.1、任务描述书
抽取数据库数据,第一步是创建数据库连接,为数据操作提供桥梁。
为了方便抽取MySQL的“demodb”数据库中的数据表,需要创建一个数据库连接,访问“demodb”数据库。
6.2、实现思路
- 建立数据库连接
- 设置数据库连接参数
- 测试和预览数据库连接
- 建立共享/停止共享数据库连接
6.3、操作过程
1)建立数据库连接
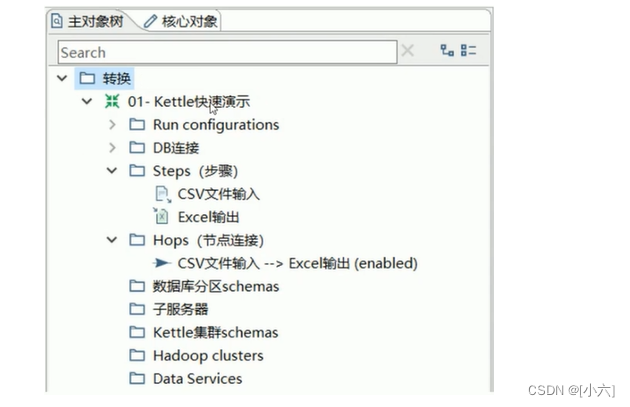
数据库连接必须在转换工程或任务工程中才能创建,使用Ctrl+N快捷键,首先创建【demodb数据库连接】转换工程。
在【demodb数据库连接】转换工程中,单击【主对象树】选项卡,展开【转换】对象数(按钮表示收起状态,按钮表示展开状态),右键单击【demodb数据库连接】下的【DB连接】对象,弹出快捷菜单。如图所示:
6.4、设置参数
- 单击【新建】选项,弹出创建【数据库连接】对话框。
- 数据库连接参数包含【一般】【高级】【选项】【连接池】和【集群】5类参数。
- 其中,【一般】参数是必填项,多数情况只需进行【一般】参数设置,即可完成创建数据库连接,其他四项是可选项。
- 由于【高级】【选项】【连接池】绝大多数情况下采用默认值,一般不需要再设置其参数,本篇教程主要介绍【一般】参数和【集群】参数的设置。
1)【一般】参数
【一般】参数分为【连接名称】【连接类型】【连接方式】【设置】四部分参数设置。因为【连接类型】参数设置不同,【连接方式】【设置】参数设置也会有所不同,所以必须按照【连接类型】【连接方式】【设置】的顺序进行参数设置。
2)【集群】参数
指单个数据库连接能够连接抽取多个数据库的数据,单击【集群】参数项,进行【集群】参数设置。如图所示:
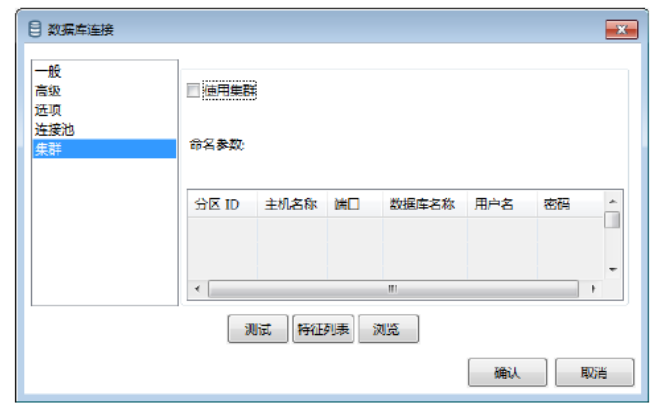
在【集群】参数设置中,勾选【使用集群】选项后,才能在【命名参数】表中设置集群参数。【分区ID】参数是指用不同的ID名称标识各个数据库,可以是英文字母、数字、中文等字符或组合。
参数设置完之后,单击【测试】按钮,弹出数据库连接测试是否成功的对话框。若正确,则显示正确连接到数据库信息;若错误,则显示错误连接到数据库的信息,需要重新设置正确的参数。
七、Kettle 建立共享/停止共享数据库连接
为了避免反复创建相同的数据库连接,在多个不同的转换工程或作业任务中共用相同的数据库,可以考虑建立共享的数据库连接。
7.1、建立共享
在建立好的数据库连接装换工程中,单击【主对象树】选项卡,展开【转换】对象树,单击>按钮,展开【DB连接】对象,右键单击数据库连接的名称。
单击【共享】选项,数据库连接共享成功,其他转换工程或任务工程即可共享使用。需要注意的是,共享后的数据库连接名称为粗体字体显示。
7.2、停止共享
数据库连接既可以共享,也可以停止共享。
与共享操作类似,单击【主对象树】选项卡,在【转换】对象树中,单击>按钮展开【DB连接】对象,右键单击显示为粗体字体的数据库连接名称,在弹出快捷菜单中单击【停止共享】选项,即可停止共享该数据库连接。
八、Kettle 表输入
8.1、任务描述
数据表是指具有统一名称,并且类型、长度、格式等元素相同的数据集合,在数据库中,数据是以数据表的形式存储的。
表输入的作用是抽取数据库中的数据表,并获取表中的数据。
为方便查看和统计学生的数学考试分数,需要通过表输入抽取某年级某次考试的数据成绩。
8.2、实现思路
- 建立【表输入】转换工程
- 设置【表输入】组件参数
- 预览数据
8.3、操作过程
1)建立表输入转换工程
在demodb数据库中的“数学成绩”表,字段说明如表所示。
|
字段名称 |
说明 |
字段名称 |
说明 |
|
序号 |
表示记录的顺序号 |
数学 |
表示数学考试分数 |
|
学号 |
表示学生在学校的唯一编号 |
考试时间 |
表示考试的日期和时间 |
使用Ctrl+N快捷键,创建【表输入】转换工程,对所使用到的表进行数据库连接创建操作,并测试结果为成功。
在【表输入】转换工程中,单击【核心对象】选项卡,展开【输入】对象,选中【表输入】组件,并拖拽到右边工作区中。
双击【表输入】组件,弹出【表输入】对话框,如图所示。
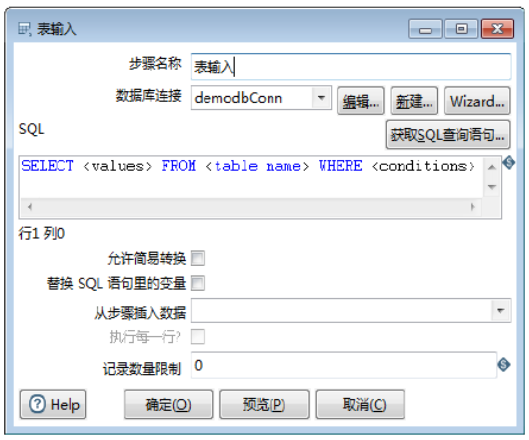
2)设置参数
在【表输入】对话框中,设置有关参数,获取MySQL的demodb数据库中的“数学成绩”表,步骤如下:
1)设置组件名称。设置【步骤名称】为默认值“表输入”。
2)设置数据库连接。单击【数据库连接】下拉框,选择所创建的链接。
浏览数据表。单击【获得SQL查询语句…】按钮,弹出【数据库浏览器】对话框,单击按钮展开数据库,再单击俺就展开【表】数据表,显示所需要浏览的表(本教程以demodbConn数据库中的数学成绩表为例)。选择【数学成绩】表。
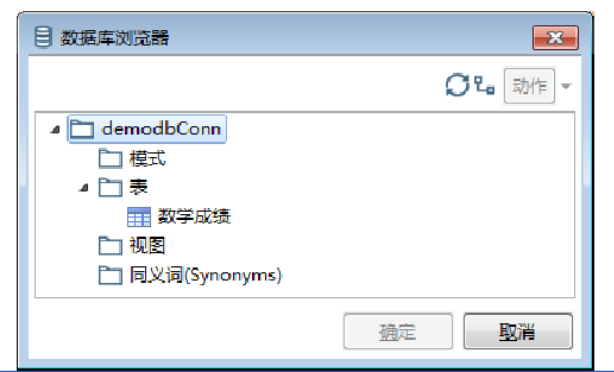
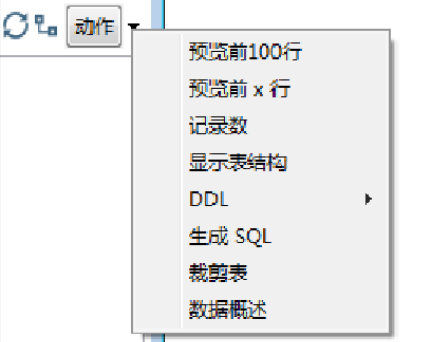
查看选中的数据表信息。单击【动作】按钮,弹出快捷菜单选项,可以分别预览数据库表的数据、记录数、表结构、生成SQL语句、裁剪表和查看表的有关信息等,如图所示。
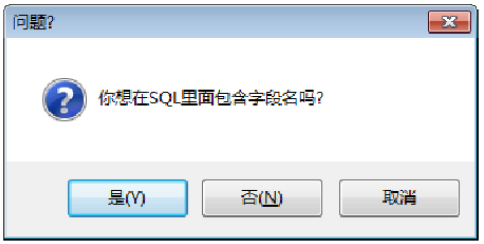
确认获取数据表的SQL查询语句。单击【确定】按钮,弹出【问题?】对话框,显示【你想在SQL里面包含字段名吗?】提示信息,如图所示。
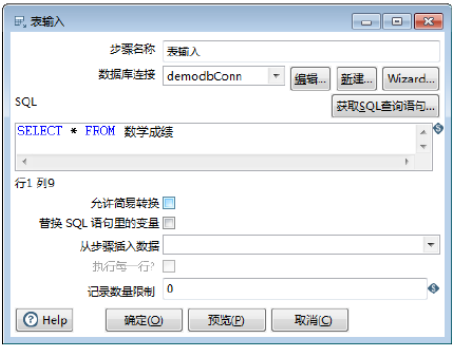
单击【否】按钮,在【SQL】表达式参数中获取的是简单的SQL查询语句,如图所示,其他参数采用默认值,此时完成【表输入】组件参数的设置。
8.4、预览结果数据
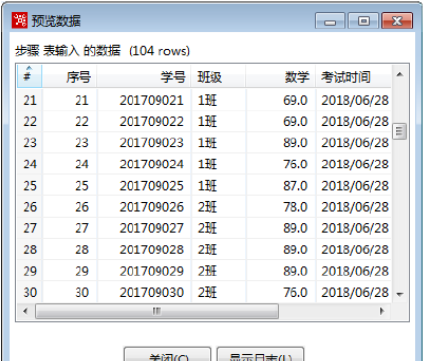
单击【预览】按钮,在弹出【输入预览记录数量】对话框中,预览记录数量采用默认值,单击【确认】按钮。弹出【预览数据】对话框,展示表输入的数据,如图所示。
九、Kettle Excel输入
9.1、任务描述
Excel采用表格的形式,数据展示直观,操作方便。
与文本文件不同,Excel文件中采用工作表存储数据,一个文件有多张不同名称的工作表,分别存放相同字段或不同字段的数据。
为方便浏览表中的明细数据,需要通过Excel输入抽取相应的数据。
9.2、实现思路
- 建立【Excel输入】转换工程。
- 设置【Excel输入】组件参数。
- 预览结果数据。
9.3、操作过程
1)建立Excel输入转换工程
本教程以“物理成绩.xls”文件为例,字段说明如下表所示:
|
字段名称 |
说明 |
字段名称 |
说明 |
|
序号 |
表示记录的顺序号 |
物理 |
表示物理考试分数 |
|
学号 |
表示学生在学校的唯一编号 |
考试时间 |
表示考试的日期和时间 |
使用Ctrl+N快捷键,创建【Excel输入】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖拽到右边工作区中,如图所示。
2)设置参数
双击【Excel输入】组件,弹出【Excel输入】对话框,其中显示默认的【文件】对话框,如图所示。
在【Excel输入】对话框中,包含组件的基础参数,以及【文件】【工作表】【内容】【错误处理】【字段】【其他输出字段】6个选项卡的参数。
在组件的基础参数中,【步骤名称】参数表示【Excel输入】组件名称,在单个转换工程中,名称必须唯一,采用默认值“Excel输入”。
【文件】【工作表】【字段】选项卡的参数是必填项(没有设置参数时,选项卡名称签名会显示“!”,表示是必填项,设置参数后“!”会消失),并且必须按照【文件】【工作表】【字段】选项卡的顺序设置,其他为可选项。
- 【文件】选项卡参数
在【文件】选项卡中,设置参数,并导入“物理成绩.xls”文件,步骤如下:
a)浏览导入Excel文件。单击【浏览(B)…】按钮,在计算机上浏览并导入“物理成绩.xls”文件,如图所示。

b)添加并编辑Excel文件。单击【增加】,将浏览导入至【文件或目录】输入框中的“E:\data\物理成绩.xls”文件,添加至【选中的文件】表中,如图所示。
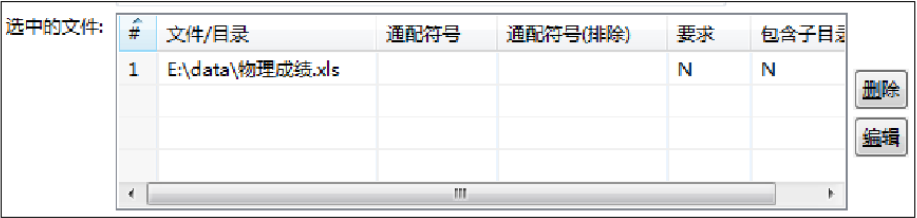
如果选中的文件有问题,那么单击【删除】或【编辑】按钮,可对选中的Excel文件进行编辑。其中,单击【选中的文件】表的行号,再单击【删除】按钮,即可删除选中所在行的文件。
c)查看被选中的文件名称.。单击【显示文件名称…】按钮,弹出【文件读取】对话框,查看被选中读取的文件,如图所示。
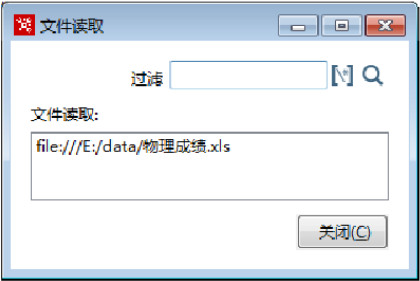
重复上述 a)~ c)个步骤可添加多个Excel文件,并查看读取的文件名称。
另外,如果需要导入同一个目录下的多份名称类似的文件,如导入同一个目录下名称分别为“物理成绩.xls”“物理成绩1.xls”和“物理成绩2.xls”的文件,可以使用通配符的方式导入。
具体操作为,在【选中的文件】参数表中,在【文件或目录】输入框中键入“E:\data”,在【通配符号】输入框中输入“物理成绩*.\xls”,可以一次性读入这3个文件,如图所示。

- 【工作表】选项卡参数
单击【工作表】选项卡,如图所示。
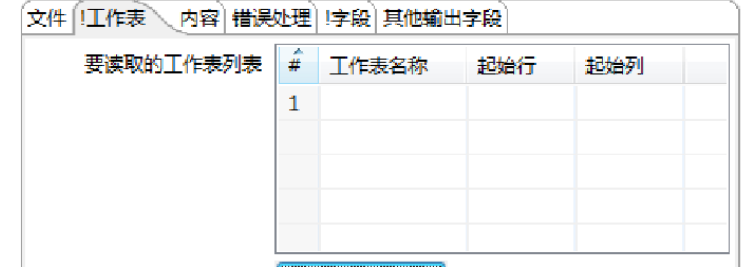
在【要读取的工作表列表】表中设置工作表参数,获取导入的Excel文件的工作表,【工作表】选项卡参数的说明如表所示。
|
参数名称 |
说明 |
|
工作表名称 |
表示Excel文件的工作表名称。可以是一个Excel文件、多个工作表,也可以是多个Excel文件、多个工作表。不同的文件,工作表名称可以相同。默认值为空。 |
|
起始行 |
表示要读取的工作表中的开始行,行号是从0开始。默认值为空。 |
|
起始列 |
表示要读取的工作表中的开始列,列号是从0开始。默认值为空。 |
如果导入的Excel文件中的每个工作表的字段结构都相同,那么在【要读取的工作表列表】表中的第1行,不设置任何工作表名称(即【工作表名称】输入栏留空),只需设置第1行的【起始行】和【起始列】输入栏参数,这样的设置是读取所有的工作表,即第1行
将用于所有工作表。
在【工作表】选项卡中,设置导入的Excel文件的工作表参数,步骤如下:
a)获取选中文件的工作表。单击【获取工作表名称…】按钮,弹出【输入列表】对话框,左边【可用项目】列表列出选中文件的所有工作表,如“物理成绩.xls”文件的“Sheet1”工作表,而右边【你的选择】列表列出被选中的工作表,如图所示。
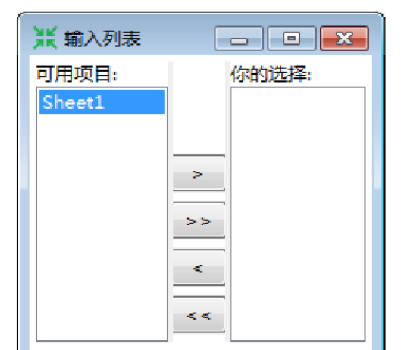
b)选择工作表。在【输入列表】对话框中,单击中间的【>】【>>】【<】【<<】按钮,可以在左、右列表中,选中或移除工作表,有关按钮说明如表所示
|
按钮 |
说明 |
|
> |
表示右移按钮,选择左边【可用项目】列表中一个工作表,移到右边【你的选择】列表中。 |
|
< |
表示左移按钮,将右边【你的选择】列表中的一个工作表移回到左边【可用项目】列表中,与【>】按钮操作相反。 |
|
>> |
表示右移批处理按钮,将左边【可用项目】列表中的所有工作表,移到右边【你的选择】列表中。 |
|
<< |
表示左移批处理按钮,将右边【你的选择】列表中的所有工作表,移回到左边【可用项目】列表中,与【>>】按钮操作相反。 |
在【输入列表】对话框中,将左边【可用项目】工作表“Sheet1”选中移到右边【你的选择】表中。
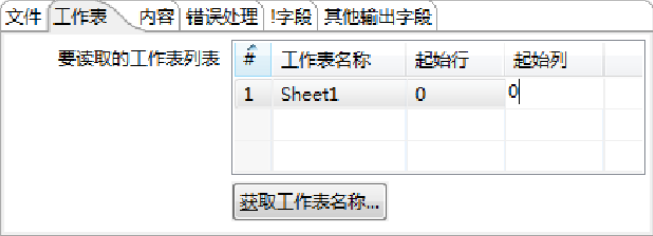
c)设置选中的工作表参数。单击【确定】按钮,将【你的选择】列表选中的“Sheet1”工作表添加至【要读取的工作表列表】表中进行参数设置,【起始行】和【起始列】参数都设置为“0”,此时完成【工作表】选项卡参数的设置,如图所示。
- 【字段】选项卡参数
单击【字段】选项卡如图所示。
在【字段】选项卡中,设置“物理成绩.xls”文件中字段的参数,步骤如下。
a)获取字段。单击【获取头部数据的字段…】按钮,添加字段到【字段】表中设置字段参数,如图所示。
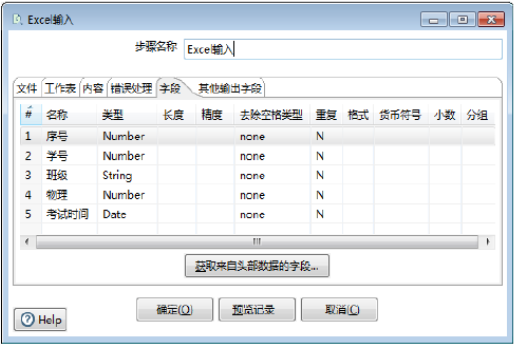
b)设置字段参数。对字段参数进行设置,如图所示,此时完成【字段】选项卡参数的设置。
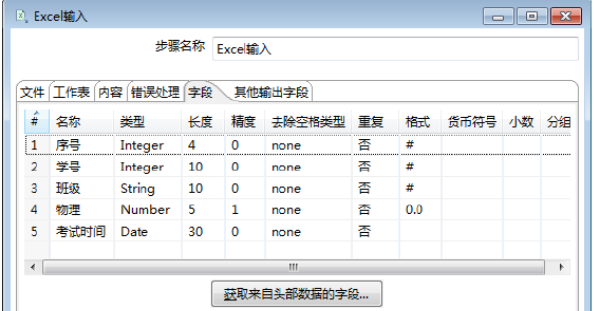
需要说明的是,如果有些Excel文件的文件头部没有字段数据,那么系统会自动生成默认的字段名称,也可以重新编辑字段名称,字段的类型、长度等,字段的属性也可以进行编辑。
当获取字段后,【Excel输入】对话框下方【预览记录】按键的字体显示为黑色,说明此时可以预览数据。
- 【内容】选项卡参数
单击【内容】选项卡,如图所示。
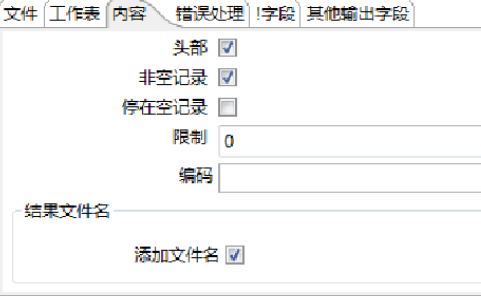
对读取Excel文件内容进行参数设置,一般按照缺省值配置,参数的说明如表所示。
|
参数名称 |
说明 |
|
头部 |
表示对选中的工作表是否包含表头行。默认值为√。 |
|
非空记录 |
表示是否在输出中不出现空行(记录)。默认值为√。 |
|
停在空记录 |
表示当读取记录遇到空行时,选择是否停止读取文件的当前工作表。默认值为空。 |
|
限制 |
表示限制生成的记录数量。当设置为0时,结果不受限制。默认值为0. |
|
编码 |
表示读入的文本文件编码。第一次使用时,Kettle会在系统中搜索可用的编码。使用Unicode的,请指定UTF-8或UTF-16。默认值为Kettle系统的编码。 |
- 【错误处理】选项卡参数
单击【错误处理】选项卡,如图所示,可对获取Excel文件时产生的错误处理参数进行设置,检查和定位错误位置,一般按照缺省值配置。
- 【其他输出字段】选项卡参数
单击【其他输出字段】选项卡,如图所示。
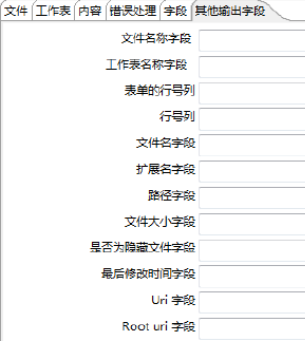
对Excel文件的其他输出字段参数进行设置,用于指定处理文件的附加信息,默认值为空,一般按照缺省值配置,有关参数的说明如表所示。
|
字段参数 |
说明 |
|
文件名称字段 |
表示指定完整的文件名称和扩展名的字段。默认值为空。 |
|
工作表名称字段 |
表示指定要使用的工作表名称的字段。默认值为空。 |
|
表单的行号列 |
表示指定要使用的当前工作表行号字段。默认值为空。 |
|
行号列 |
表示指定写入行数的字段。默认值为空。 |
|
文件名字段 |
表示指定文件名但没有路径信息、但有扩展名的字段。默认值为空。 |
|
扩展字段 |
表示指定文件名扩展名的字段。默认值为空。 |
|
路径字段 |
表示指定以操作系统格式包含路径的字段。默认值为空。 |
|
文件大小字段 |
表示指定文件数据大小的字段。默认值为空。 |
|
是否为文件隐藏字段 |
表示文件是否为隐藏的字段(布尔值)。默认值为空。 |
|
Uri字段 |
表示指定包含Uri的字段。默认值为空。 |
|
Root Uri字段 |
表示指定仅包含Uri的根部分的字段。默认值为空。 |
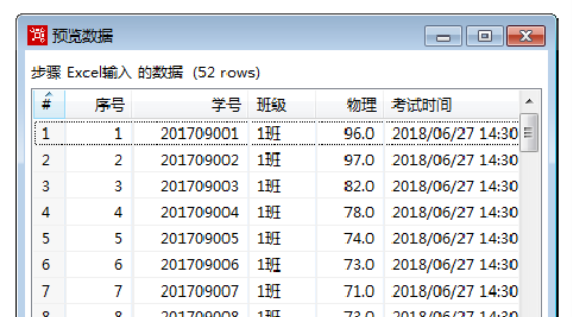
设置好字段参数后,单击【预览记录】按钮,弹出【预览数据数量】对话框,要预览的行数采用默认值,并单击【确定】按钮。
弹出【预览数据】对话框,展示Excel输入的数据,如图所示。
十、Kettle 生成记录
10.1、任务描述
在数据统计中,往往要生成固定行数和列数的记录,用于存放统计总数。
为方便记录1-12月份商品的销售总额,需要通过生成记录,生成一个月销售总额的数据表,包括商品名称和销售总额两个字段,记录销售的商品和当月商品统计销售总额,共生成12条记录。
10.2、实现思路
- 建立【生成记录】转换工程。
- 设置【生成记录】组件参数。
- 预览结果数据。
10.3、操作过程
1、建立【生成记录】转换工程
使用ctrl+N快捷键,创建【生成记录】转换工程,单击【核心对象】,展开【输入】对象,选中【生成记录】组件,并拖拽到右边工作区中,如图所示:
2、设置参数
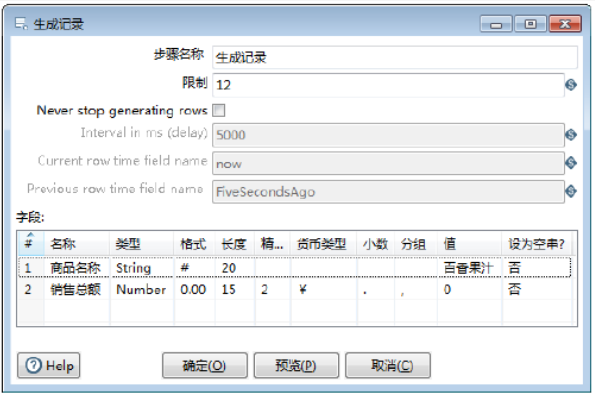
双击【生成记录】组件,弹出创建【生成记录】对话框,如图所示:
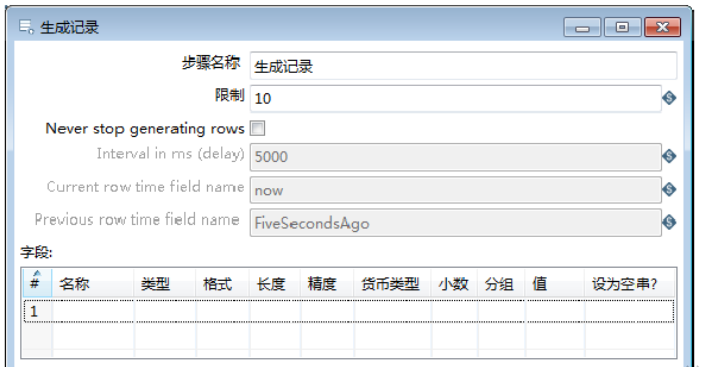
该组件参数包含两种,分别是基础参数:步骤名称、限制、“Never stop generating rows”和【字段】:名称、类型、格式、长度、精度、货币类型、小数、分组、值、设为空串?。
根据需要设置好相关参数后,生成12条记录的商品销售总额表,步骤如下:
1)确定组件名称。【步骤名称】参数保留默认值。
2)确定表的记录数。【限制】参数设置为“12”。
3)设置字段参数。在【字段】表中,对个字段的参数进行设置,如图所示,此时完成【生成记录】组件参数的设置。
3、预览数据结果
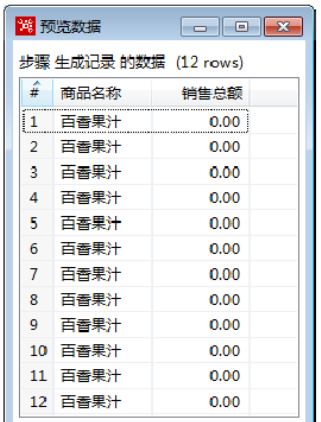
单击【预览(P)】按钮,弹出【输入预览记录数】对话框,预览记录数采用默认值,单击【确定】按钮。弹出【预览数据】对话框,展示生成记录的数据,如图所示:
十一、Kettle 生成随机数
11.1、任务描述
在工作中,往往需要生成随机数验证码,作为数据或文件的验证码。
为方便给授权用户验证文件,需要通过生成随机数,生成一组MD5信息授权码,作为数据文件的认证授权码。
11.2、实现思路
- 建立【生成随机数】转换工程
- 设置【生成随机数】组件参数
- 预览结果参数
11.3、操作过程
1、简历生成随机数转换工程
使用ctrl+N快捷键,创建【生成随机数】转换工程,单击【核心对象】,展开【输入】对象,选中【生成随机数】组件,并拖拽到右边工作区中,如图所示:
2、设置参数
双击【生成随机数】组件,弹出【生成随机值】对话框,如图所示:
【生成随机数】组件的参数,包含组件的基础参数和【字段】表参数。
在【生成随机值】对话框中,设置参数,随机生成一组MD5信息授权码,步骤如下:
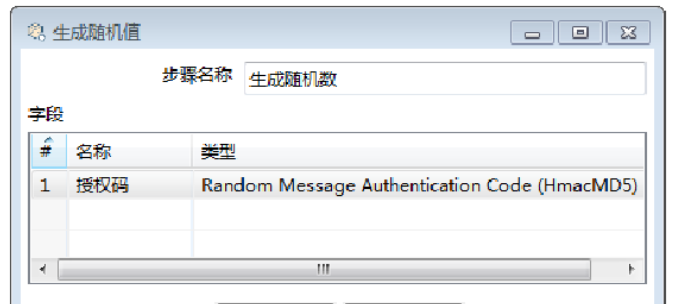
1)确定组件名称。【步骤名称】参数保留默认值“生成随机值”。
2)设置字段参数。在【字段】表中第1行,设置字段名称和类型。
①点击【名称】参数输入框,键盘键入“授权码”。
②单击【类型】参数输入框,弹出【选择数据类型】对话框,选择【Random Message Authentication Code(HmacMD5)】类型,如图所示。
3、预览结果数据
在【生成随机数】转换工程中,单击【生成随机数】组件,再从工作区上方调出【转换调试窗口】对话框,展示生成随机数的数据,如图所示。
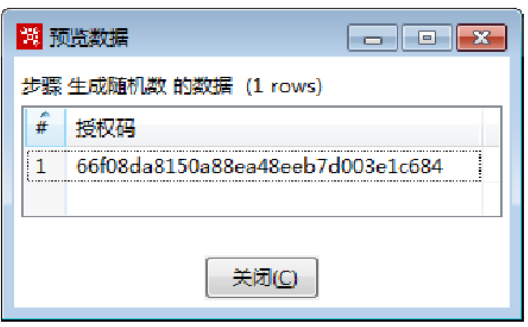
单击【快速启动】按钮,弹出【预览数据】对话框,展示生成随机数的授权码数据,如图所示。
十二、Kettle 获取系统信息
12.1、相关概念
系统信息是指Kettle系统环境的信息,包括了计算机系统的日期、星期等时间类型信息,计算机名称、IP地址等设备信息,Kettle系统转换过程中的信息等。
为方便读取计算机上到本月最后一天的交易数据文件,需要通过获取系统信息,获得当月最后一天的时间以及当前计算机名称与IP地址等系统信息。
12.2、实现思路
- 建立【获取系统信息】转换工程。
- 设置【获取系统信息】组件参数。
- 预览结果数据。
12.3、操作过程
1)建立获取系统信息转换工程
使用Ctrl+N快捷键,创建【获取系统信息】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【获取系统信息】组件,并拖拽到右边工作区中,如图所示:
2)设置参数
双击【获取系统信息】组件,弹出【获取系统信息】对话框,如图所示:
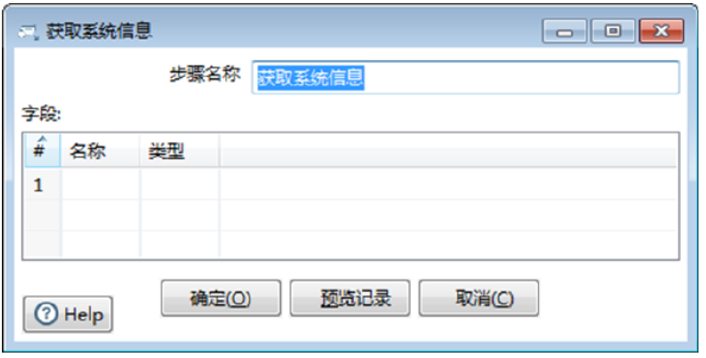
【获取系统信息】组件的参数包含组件的基础参数,以及【字段】表参数。
在【获取系统信息】对话框中,设置参数,获取当月最后一天的时间,以及当前的计算机名称与IP地址等系统信息,步骤如下:
1)确定组件名称。【步骤名称】参数保留默认值。
2)设置字段参数。在【字段】表中,设置字段参数。
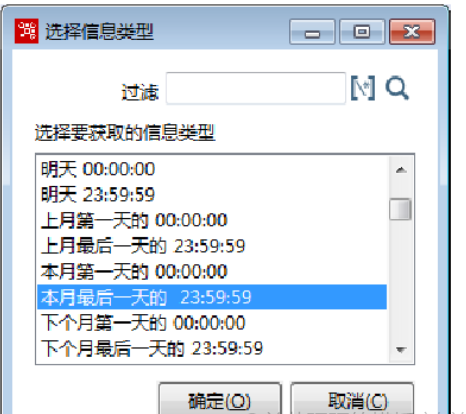
①设置第1行参数。【名称】参数设置为“当月最后一天”。单击【类型】输入框,弹出【选择信息类型】对话框。选择“本月最后一天的23::59:59”类型,如图所示,并单击【确定】按钮。
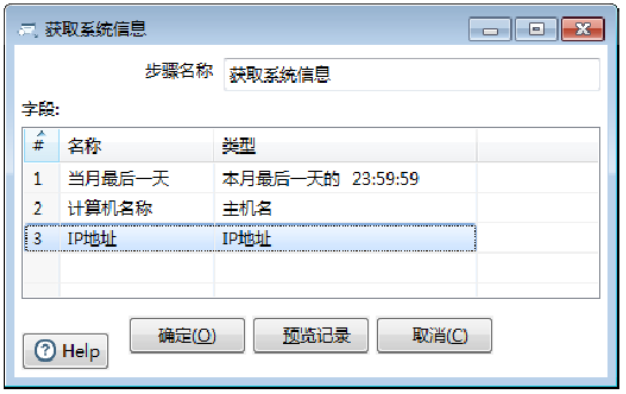
②设置第2行参数。与设置第1行参数类似,第2行参数的【名称】参数设置为“计算机名称”,【类型】参数设置为“主机名”。
③设置第3行参数。与设置第1行参数类似,第3行参数的【名称】参数设置为“IP地址”,【类型】参数设置为“IP地址”,如图所示,此时已完成【获取系统信息】组件的参数设置。
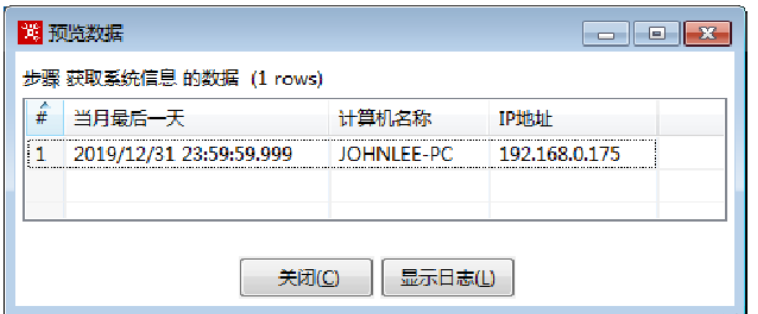
3)预览结果数据
单击【浏览记录】按钮,弹出【Enter preview size】对话框,预览记录数采用默认值,单击【确定】按钮。弹出【预览数据】对话框,展示获取系统信息的数据,如图所示。
十三、Kettle 排序记录
13.1、任务描述
排序是对数据中的无序记录,按照自然或客观规律,根据关键字段大小递增或递减的次序,对记录重新排列的过程。
为了得出学生的成绩排名,需要对“2019年11月月考数学成绩.xls”文件,使用【排序记录】组件,对学生的成绩从低到高排序。
13.2、实现思路
- 建立【排序记录】转换工程。
- 设置【排序记录】组件参数。
- 预览结果数据。
13.3、操作过程
1)建立排序记录转换工程
使用Ctrl+N快捷键,创建【排序记录】转换工程,接着创建【Excel输入】组件,设置参数,导入““2019年11月月考数学成绩.xls”文件,预览数据,如图所示,其中“数学”字段数据处于无序状态。
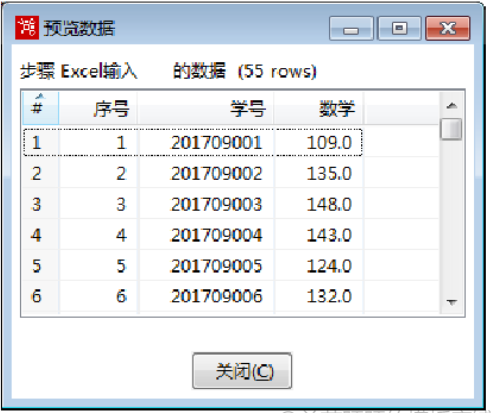
在【排序记录】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【排序记录】组件,并拖拽至右边工作区中。由【Excel输入】组件指向【排序记录】组件,建立节点连接,如图所示:
2)设置参数
双击【排序记录】组件,弹出【排序记录】对话框,如图所示:
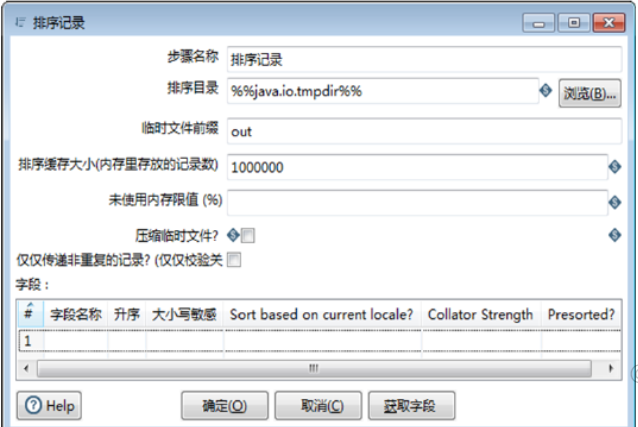
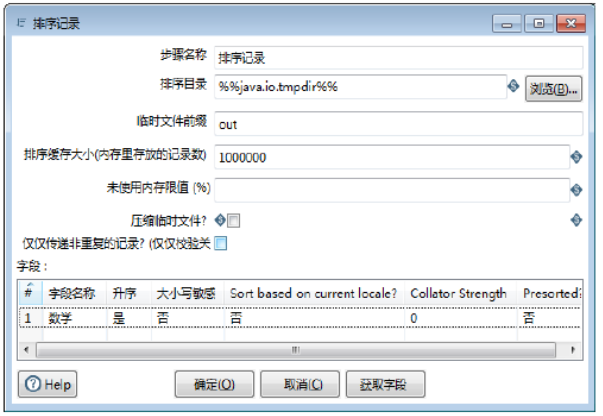
【排序记录】组件的参数包含了组件的基础参数和【字段】表参数,有关参数的说明如表所示。其中,【字段】表参数是设置参与排序的字段参数,可以对多个字段设置参数。
在【排序目录】对话框中,设置参数,将“数学”字段的数据按照从低到高进行排序,步骤如下:
1)确定组件名称。【步骤名称】参数保留默认值“排序记录”。
2)确定排序目录。【排序目录】参数保留默认值“%%java.io.tmpdir%%”。
3)设置排序字段参数。在【字段】表中,对各字段的参数进行设置,此时完成【排序目录】组件参数的设置,如图所示:
3)预览结果数据
在【排序记录】排序工程中,单击【排序记录】组件,再点击预览数据,展示排序后的数据,如图所示:
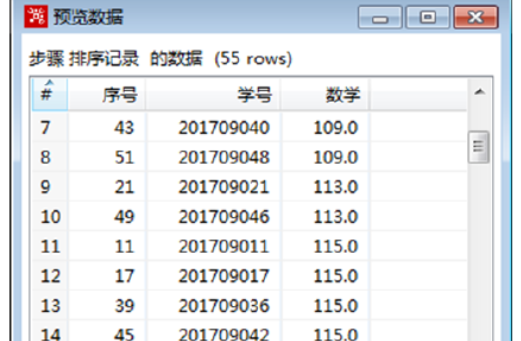
十四、Kettle 去除重复记录
14.1、任务描述
由于输入或其他错误的原因,数据文件中可能出现两条或多条数据完全相同的记录,这些相同的记录成为重复记录。
重复的记录属于“脏数据”,会造成数据统计和分析不正确,必须清洗掉重复记录。
由于在“期考成绩.xls”文件中,发现存在序号不同,但是学号、各科考试成绩完全相同的记录,所以需要使用【去除重复记录】组件,去除这些重复的数据。
14.2、实现思路
- 建立【去除重复记录】转换工程。
- 设置【去除重复记录】组件参数。
- 预览结果数据。
14.3、操作过程
1)建立去除重复记录转换工程
- 在去除重复记录(简称“去重”)之前,必须使用关键字段对数据记录进行排序,确定哪些记录属于重复记录。
- 使用Ctrl+N快捷键,创建【去除重复记录】转换工程。接着创建【Excel输入】组件,设置参数,导入“期考成绩.xls”文件。
- 接着创建【排序记录】组件,并由【Excel输入】组件指向【排序记录】组件,简历节点连接,如图所示:
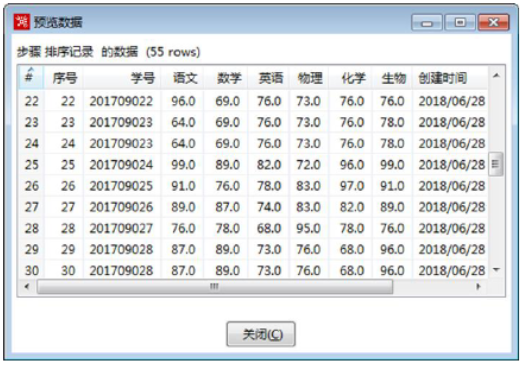
- 双击【排序记录】组件,对“学号”字段按照升序进行排序后预览数据,如图所示,除了“序号”字段数据外,“学号”分贝为“201709023”“201709028”的数据各有两条记录,并且对应的“语文”“数学”等考试科目和“创建时间”的数据也相同。
![]()
- 在【去除重复记录】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【去除重复记录】组件,并拖拽至右边工作区中,并由【排序记录】组件指向【去除重复记录】组件,建立节点连接,如图所示:
2)设置参数
双击【去除重复记录】组件,弹出【去除重复记录】对话框,如图所示:
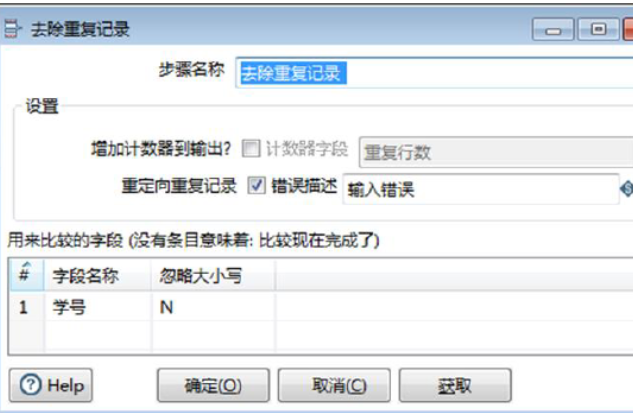
【去除重复记录】组件的参数包含了组件的基础参数和【用来比较的字段】表参数。
在【去除重复记录】对话框中,设置参数,去除学号相同的记录,步骤如下:
1)确定组件名称。【步骤名称】参数保留默认值“去除重复记录”。
2)确定计数器字段。【增加计数器到输出】设置为“√”,【计数器字段】设置为“重复行数”。
3)确定错误描述。【重定向重复记录】设置为“√”,【错误描述】设置为“重复输入”。
4)设置用来比较字段参数,在【用来比较的字段】表中,【字段名称】设置为“学号”,【忽略大小写】设置为“N”,此时完成【去除重复记录】组件参数的设置,如图所示。
3)预览结果数据
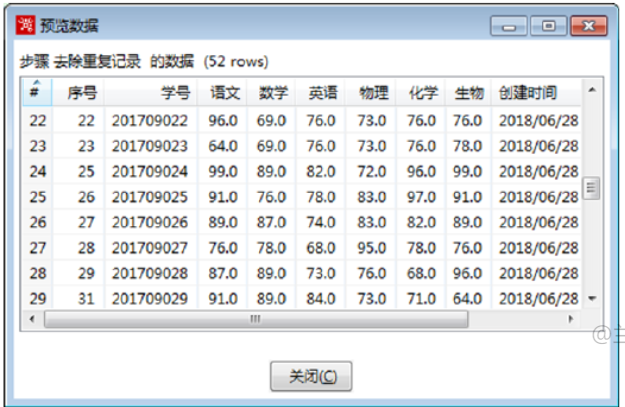
在【去除重复记录】转换工程中,单击【去除重复记录】组件,点击预览去除重复记录后的数据,如图所示:
十五、Kettle 替换NULL值
15.1、任务描述
在Kettle转换过程中,默认情况下,会将控制当做NULL值处理。如果数据类型字段出现NULL值,那么在计算时就会出现错误。
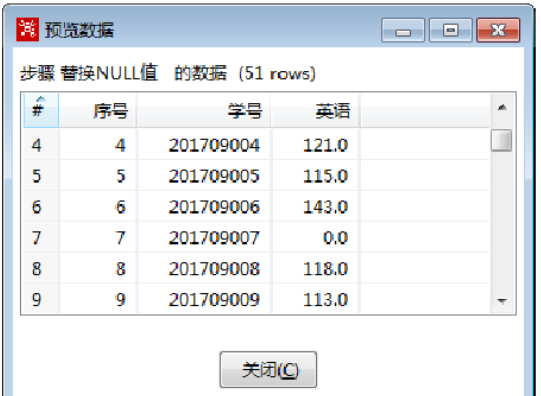
在“2019年11月月考英语成绩.xls”文件中,学号为“201709007”的同学没有参加考试,根据规定高考时分数将按零分处理,需要使用【替换NULL值】组件,使用“0”替换该同学的英语考试分数。
15.2、实现思路
1)建立【替换NULL值】转换工程。
2)设置【替换NULL】组件参数
3)预览结果数据。
15.3、操作过程
1)建立替换NULL值转换工程
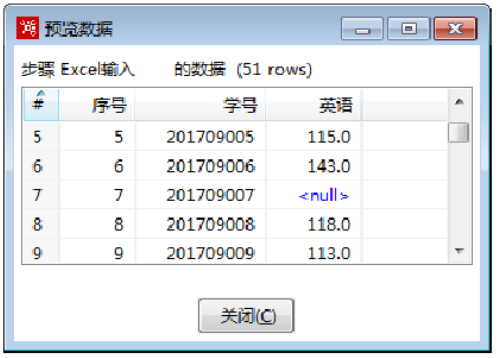
使用Ctrl+N快捷键,创建【替换NULL值】转换工程。接着创建【Excel输入】组件,设置参数,导入“2019年11月月考英语成绩.xls”文件,预览数据,“学号”字段数据为“201709007”所对应的“英语”字段数据为“<null>”即(NULL),如图所示:
在【替换NULL值】转换工程中,单击【核心对象】选项卡,展开【应用】对象,选中【替换NULL值】组件,并拖拽至右边工作区中。由【Excel输入】组件指向【替换NULL值】组件,建立节点连接,如图所示:
2)设置参数
双击【替换NULL值】组件,弹出【替换NULL值】对话框,如图所示:
【替换NULL值】组件的参数包含了组件的基础参数和【替换所有字段的null值】【选择字段】【选择值类型】3种方式设置的参数,每种方式有多个不同的参数,有关参数的说明如表所示。
|
基础参数名称 |
说明 |
|
作业名称 |
表示【替换NULL值】组件名称,在单个转换工程中,名称必须唯一,默认值是【替换NULL值】组件名称。 |
|
选择字段 |
表示对所有记录的、指定字段的NULL值进行值替换的方式。默认值为空。 |
|
选择值类型 |
表示对所有记录、指定的数据类型的NULL值进行替换的方式。默认值为空。 |
下图这3种方式只能三选一,默认是【替换所有字段的null值】方式,勾选【选择字段】参数后,通过【字段】表设置具体参数;勾选【选择值类型】参数后,通过【值类型】表设置具体参数。
|
参数名称 |
说明 |
|
替换所有字段的NULL值 |
表示对所有记录、所有字段的NULL值进行替换方式,默认的替换方式。具体如下: 1)值替换为:表示用来替换NULL的值,默认值为空。 2)设置空字符串:表示是否设置空字符串,默认值为空。 3)掩码(日期):表示日期字段的掩码格式,默认值为空。 |
|
字段 |
表示勾选【选择字段】参数后,使用【字段】表设置参数,具体如下: 1)字段:表示输入流的字段名称,单击下拉框选择设置。 2)值替换为:表示要替换NULL的值。 3)转换掩码(日期):表示日期字段的掩码格式,默认值为空。 4)设置空字符串:表示是否设置空字符串,选项有:是、否,默认值为空。 |
|
值类型 |
表示勾选【选择值类型】参数后,使用【值类型】表设置参数,具体如下: 1)字段:表示输入流的字段名称,单击下拉框选择设置。 2)值替换为:表示要替换NULL的值。 3)转换掩码(日期) :表示日期字段的掩码格式,默认值为空。 4)设置空字符串:表示是否设置空字符串,选项有:是、否,默认值为空。 |
在【替换NULL值】对话框中,设置参数,用“0”替换“英语”字段的数据“null”,步骤如下:
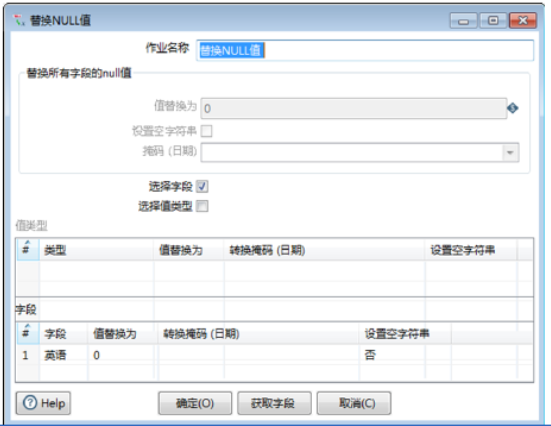
1)确定组件名称。【步骤名称】参数保留默认值“替换NULL值”。
2)选择【选择字段】方式设置字段参数。【选择字段】设置为“√”,并在【字段】表中,对字段的参数进行设置。此时完成【替换NULL值】组件参数的设置,如图所示。
3)预览结果数据
在【替换NULL值】转换工程中,单击【替换NULL值】组件,预览替换NULL值后的数据,如图所示:
十六、Kettle 过滤记录
16.1、任务描述
在数据处理时,往往要对数据所述类别、区域和时间等进行限制,将限制范围外的数据过滤掉。
为了统计2班的考试人数和成绩,需要对“2019年10月年级月考数学成绩.xls”文件,使用【过滤记录】组件,过滤掉不是2班的数据。
16.2、实现思路
- 建立【过滤记录】转换工程。
- 设置【过滤记录】组件参数。
- 预览结果数据。
16.3、操作过程
1)建立过滤记录转换工程
使用Ctrl+N快捷键,创建【过滤记录】转换工程。接着创建【Excel输入】组件,设置参数,导入“2019年10月年级月考数学成绩.xls”文件,预览数据,如图所示,文件包括有1班、2班的数据。
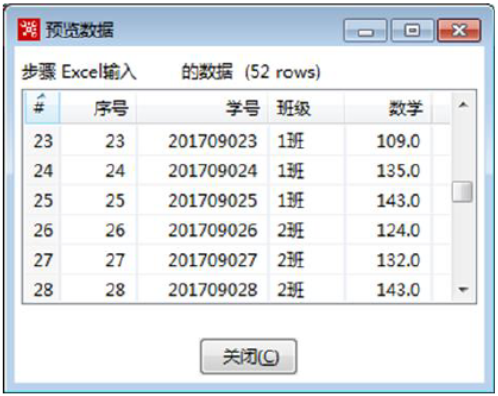
在【过滤记录】转换工程中,单击【核心对象】选项卡,展开【流程】对象,选中【过滤记录】组件,并拖拽至右边工作区中。由【Excel输入】组件指向【过滤记录】组件,建立节点连接,如图所示:
2)设置参数
双击【过滤记录】组件,弹出【过滤记录】对话框,如图所示:
【过滤记录】组件的参数包含组件的基础参数和【条件】表达式参数,有关参数的说明如表所示。
|
参数名称 |
说明 |
|
|
基础参数 |
步骤名称 |
表示【过滤记录】组件名称,在单个转换工程中,名称必须唯一,默认值为【过滤记录】组件名称。 |
|
发送true数据给步骤 |
表示当条件为true时,记录被发送到此组件(步骤)。此参数也可以在与下一个组件(步骤)进行节点连接是设置,默认值为空。 | |
|
发送false数据给步骤 |
表示当条件为false时,记录被发送到此组件(步骤)。此参数也可以在与下一个组件(步骤)进行节点连接是设置,默认值为空。 | |
|
条件 |
表示过滤条件的表达式,在【条件】表达式输入框中设置表达式中各个参数默认值为空。 | |
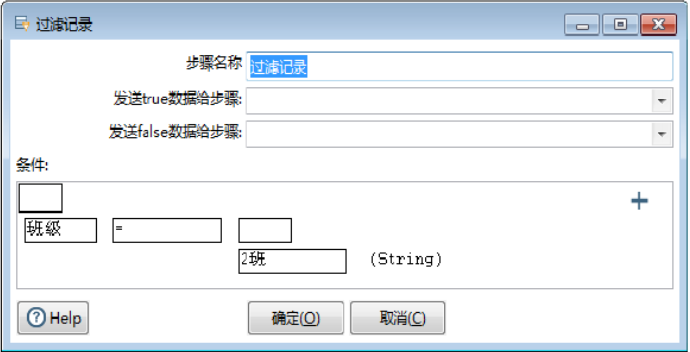
条件表达式是由条件函数(运算符)构成的一个赋值语句,格式为:<字段><条件函数><表达式>,格式的中间为比较函数,左边为字段,右边是值表达式,如a=5、a>(b+2)、a<=10等。为了方便读者理解,在【条件】表达式输入框中,增加了条件表达式设置的指向说明,如图所示:

1)增加子条件
单击+图表可以增加子条件,这时在【条件】表达式输入框中,显示出增加的条件表达式,初次生成的是一条“null=[ ]”的空表达式,如图所示:

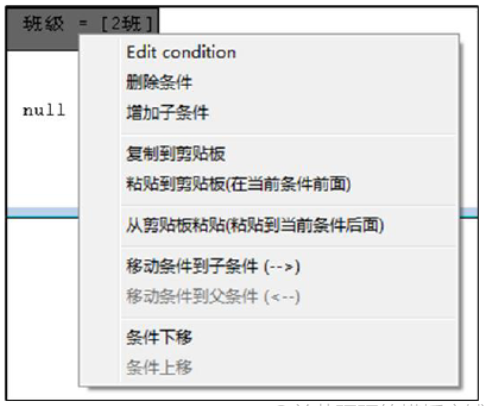
单击“null=[ ]”空表达式,可对该表达式进行设置,如图所示,点击“向上”按钮可以向上切换回条件表达式。

右键单击子条件表达式,弹出右键快捷菜单,可以对子条件进行编辑、删除、复制、粘贴、移动位置等操作,如图所示:
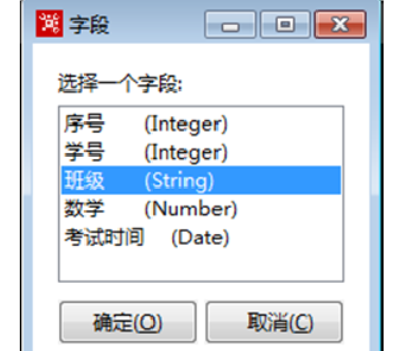
2)选择输入流的字段
单击“选择输入流字段”指向的【<field>】字段输入框,弹出【字段】对话框,列出输入流字段表,选择需要过滤的字段,选中“班级”字段,如图所示,单击下方【确定】按钮,确定输入流字段。
3)选择比较函数
单击“比较函数”指向的【=】函数输入框,弹出【函数】对话框,并列出过滤比较函数,有关过滤比较函数的说明如表所示(部分):
|
函数名称 |
说明 |
|
REGEXP |
表示正则表达式,判断表达式字段是否与模式匹配。 |
|
IN NULL |
表示为空,判断表达式字段是否为空。 |
|
IS NOT NULL |
表示不为空,判断表达式字段是否不为空。 |
|
IN LIST |
表示在列表中,判断表达式字段是否在指定的list列表中。 |
|
CONTAINS |
表示包含,判断表达式字段是否包含右边的值。 |
|
STARTS WITH |
表示以什么开始,判断表达式字段是否以右边的值开始。 |
|
ENDS WITH |
表示以什么结束,判断表达式字段是否以右边的值结束。 |
|
LIKE |
表示包括,判断表达式字段是否包括右边的值。 |
|
TRUE |
表示真,判断表达式字段是否为真。 |
选择“=”的过滤比较函数,单击【确定】,确认过滤比较函数。
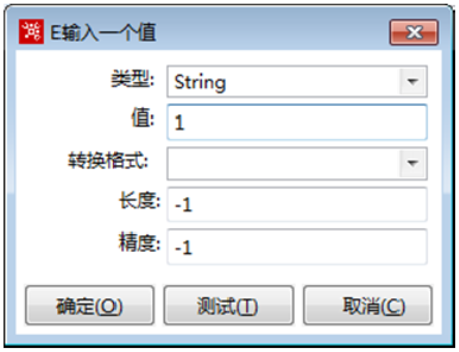
4)输入比较的值
单击“输入要比较的值”指向的【<vallue>】值输入框,弹出【E输入一个值】对话框,输入比较的值。
*有关【E输入一个值】对话框中的参数的说明如表所示。需要注意,若设置“输入要比较的值”指向的【<value>】值参数,则不能设置“选择要比较的字段”指向的【<field>】字段参数,二者只能选其一。
|
参数名称 |
说明 |
|
类型 |
表示值的类型。类型选项有:BigNumber、Binary、Boolean、Date、Integer、Internet、Address、Number、String、Timestamp。默认值为String。 |
|
值 |
表示值,可以是具体值或表达式,默认值为1. |
|
转换格式 |
表示值的转换格式,默认值为空。 |
|
长度 |
表示值的长度,默认值为-1。 |
|
精度 |
表示值的精度,默认值为-1。 |
5)选择比较字段
单击“选择要比较的字段”指向的【<field>】字段输入框,弹出类似的【字段】对话框,选中要比较的字段,单击确定按钮,确定要比较的字段。同样,若设置了“选择要比较的字段”指向的【<field>】字段参数,则不能设置“输入要比较的值”指向的【<value>】值参数,二者只能选其一。
6)条件取反
鼠标移向“条件取反”指向的输入框,显示出黑底红字的“NOT”,单击该输入框并移开鼠标,此时显示白底黑字的“NOT”,表示条件取反,即若表达式为true,则条件为false。
若表达式为false,则条件true。“条件取反”指向的输入框为一个奇偶输入框,单击取反,再次单击则取正。
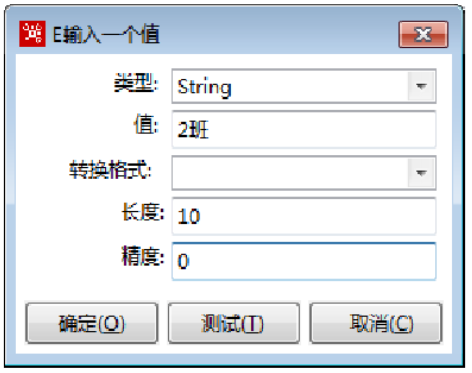
在导入的“2019年10月年级月考数学成绩.xls”文件中,过滤掉不是2班的数据,对条件表达式按照下表的设置。
|
输入流【<filed>】字段 |
【=】比较函数 |
【<Value>】输入一个值 |
|
班级 |
= |
单击【<field>】输入框,弹出【E输入一个值】对话框,对参数进行设置,如下图所示。 |
此时完成【过滤记录】组件参数的设置,如图所示:
3)预览结果数据
在【过滤记录】转换工程中,单击【过滤记录】组件,预览过滤记录后的数据,如图所示:
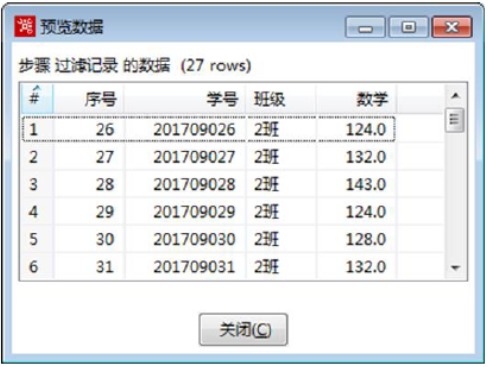
十七、Kettle 值映射
17.1、任务描述
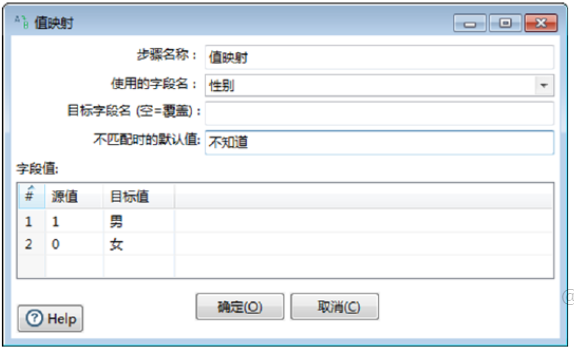
- 在数据处理系统中,为了加快处理速度、减少内存和存储空间消耗,往往使用数字、字母,或他们的组合表示真实的数据含义,例如,用“1”和“0”分别表示性别,难以直接看懂。
- 在某校学生的“学籍信息.xls”文件中,性别字段数据分别用“1”和“0”表示。为了更加直观、一目了然地读懂学生的学籍信息,需要使用【值映射】组件,还原其对应的值“男”或“女”。
- kettle值映射能够解决这一需求。
17.2、实现思路
- 建立【值映射】转换工程。
- 设置【值映射】组件参数。
- 预览结果数据。
17.3、操作过程
1)建立值映射转换工程
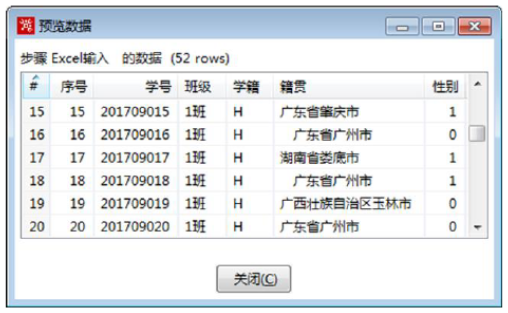
使用Ctrl+N快捷键,创建【值映射】转换工程。接着创建【Excel输入】组件,设置参数,导入“学籍信息.xls”文件,预览数据,如图所示。
- 当前数据中,“性别”字段的数据,以“0”或“1”表示;
- “学籍”字段的数据,以“H”或“J”表示;
- “籍贯”字段有一些数据前面有空格。
![]()
在【值映射】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【值映射】组件,并拖拽至右边工作区中。由【Excel输入】组件指向【值映射】组件,建立节点连接,如图所示。
2)设置参数
双击【值映射】组件,弹出【值映射】对话框,如图所示。
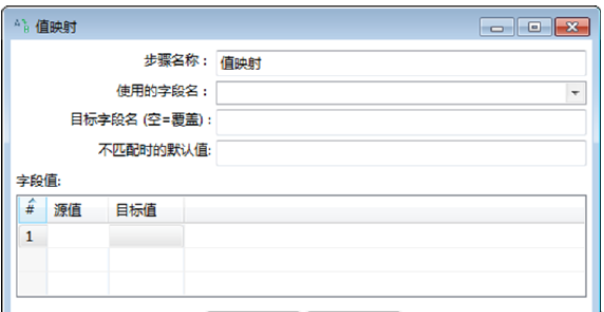
将“性别”字段中“1”“0”数据分别用“男”“女”映射替换,对参数进行设置。此时完成【值映射】组件参数的设置,如图所示。
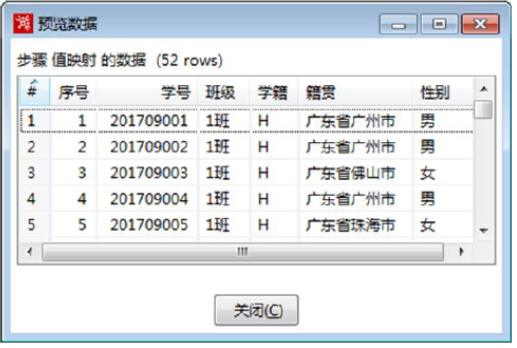
3)预览结果数据
在【值映射】转换工程中,单击【值映射】组件,预览进行值映射操作后的数据,如图所示。
十八、Kettle 字符串替换
18.1、任务描述
字符串替换与值映射非常类似,不同之处在于字符串替换的字段值是字符串,值映射的字段可以是多种数据类型。
由于在“学籍信息.xls”文件中,学籍数据用“H”或“J”表示,需要使用【字符串替换】组件,分别还原其对应的值“户籍生”和“借读生”。
18.2、实现思路
- 建立【字符串替换】转换工程。
- 设置【字符串替换】组件参数。
- 预览结果数据。
18.3、操作过程
1)建立字符串替换转换工程
使用Ctrl+N快捷键,创建【字符串替换】转换工程。接着创建【Excel输入】组件,设置参数,导入“学籍信息.xls”文件。
在【字符串替换】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【字符串替换】组件,并拖拽至右边工作区中。由【Excle输入】组件指向【字符串替换】组件,建立节点连接,如图所示。
2)设置参数
双击【字符串替换】组件,弹出【字符串替换】对话框,如图所示。
【字符串替换】组件的参数包含组件的基础参数和【字段】表参数,有关参数说明如表所示。
|
参数名称 |
说明 |
|
|
基础参数 |
步骤名称 |
表示【字符串替换组件名称】,在单个转换工程中,名称必须唯一。默认值是【字符串替换】组件名称。 |
|
字段 |
表示对将要进行字符串替换的字段参数,使用一个【字段】表对字段参数进行设置,有关参数说明如下所示。 | |
|
输入流字段 |
表示要进行字符串替换的输入流字段。默认值为空。 | |
|
输出流字段 |
表示进行字符串替换后的输出流字段,为空时覆盖原来要进行替换的输入流字段,默认值为空。 | |
|
使用正则表达式 |
表示是否使用正则表达式,选项有:Y、N。默认值为空。 | |
|
搜索 |
表示是否搜索此次字符串的匹配值,默认值为空。 | |
|
使用…替换 |
表示要替换匹配值的字符串数据,默认值为空。 | |
|
设置为空串? |
表示是否设置空字符串,选项有:Y、N。默认值为空。 | |
|
使用字段值替换 |
表示使用一个字段值替换字符串,默认值为空。 | |
|
整个单词匹配 |
表示是否要整个单词都匹配,选项有:Y、N,默认值为空。 | |
|
大小写敏感 |
表示是否区分大小写,选项有:Y、N,默认值为空。 | |
|
In Unicode |
表示是否设置Unicode,选项有:Y、N,默认值为空。 | |
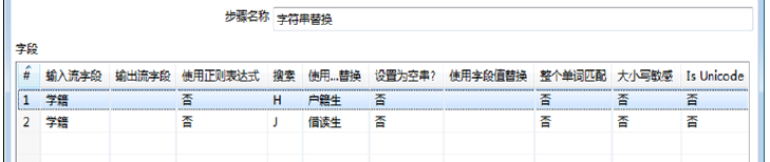
在【字符串替换】对话框中,设置参数,对输入数据中“学籍”字段中数据“H”和“J”,分别使用“户籍生”和“借读生”进行替换,步骤如下:
1)确认组件名称。【步骤名称】保留默认值,设置为“字符串替换”。
2)确定字段参数。对【字段】表的参数进行设置。此时完成【字符串替换】组件参数的设置,如图所示。
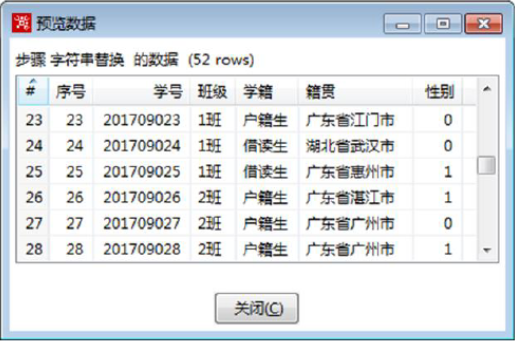
3)预览结果数据
在【字符串替换】转换工程中,单击【字符串替换】组件,预览字符串替换后的数据,如图所示。
十九、Kettle 字符串操作
19.1、任务描述
在数据输入过程中,有时候不小心输入的多余的空格、错误的字符等,字符串操作是指将数据中不需要的字符处理掉,Kettle字符串操作可以解决这一需求。
由于在“学籍信息.xls”文件中,学生学籍信息的籍贯字段数据前后有多余的空格,需要使用【字符串操作】,去除这些空格,规范学籍信息。
19.2、实现思路
- 建立【字符串操作】转换工程。
- 设置【字符串操作】组件参数。
- 预览结果数据。
19.3、操作过程
1)建立字符串操作转换工程
使用Ctrl+N快捷键,创建【字符串操作】转换工程。接着创建【Excel输入】组件,设置参数,导入“学籍信息.xls”文件。
在【字符串操作】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【字符操作】组件,并拖拽至右边工作区中。由【Excel输入】组件指向【字符串操作】组件,建立节点连接,如图所示。
2)设置参数
双击【字符串操作】组件,弹出【String operations】对话框,如图所示。
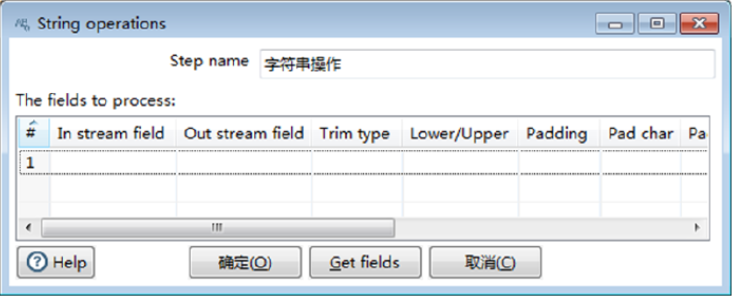
【字符串操作】组件的参数包含组件的基础参数和【The fields to process】表字段参数,有关参数的说明如表所示。

在【String operations】对话框中,设置参数,删除“籍贯”字段数据中的空格,步骤如下:
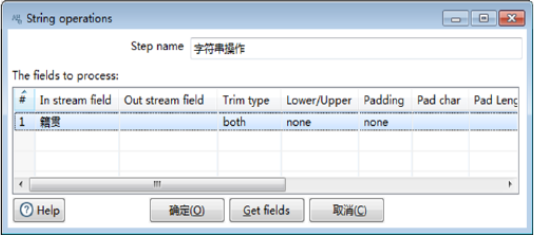
1)确定组件名称。【Step name】参数保留默认值“字符串操作”。
2)设置字符串操作的字段参数。在【The fields to process】表中设置字段参数,在表第1行,单击【In steam field】输入框,在输入流字段中选中“籍贯”字段,单击【Trim type】输入框,在选项中选中“both”,其他参数使用默认值。此时完成【字符串操作】组件参数的设置,如图所示。
3)预览结果数据
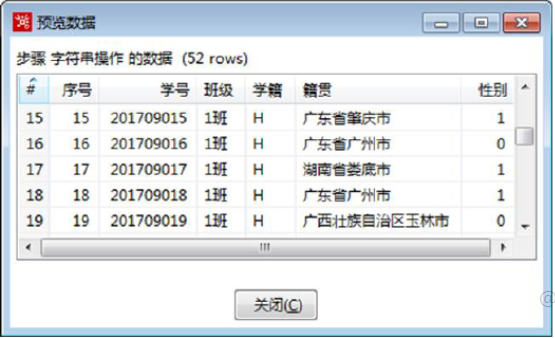
在【字符串操作】转换工程中,单击【字符串操作】组件,预览进行字符串操作后的数据,如图所示。
二十、Kettle 分组
20.1、任务描述
在进行数据统计中,往往要对类别、区域、型号等范围进行统计,分组是对指定的字段或字段集合的数据进行分组统计,Kettle分组组件可以解决这一需求。
为了了解各班级和学生的学业情况,需要对“2019年10月月考英语成绩.xls”文件,使用【分组】组件,统计各班的人数和平均分数。
20.2、实现思路
- 建立【分组】转换工程。
- 设置【分组】组件参数。
- 预览结果数据。
20.3、操作过程
1)建立分组转换工程
在分组之前,必须使用关键字段对数据记录进行排序,确定哪些记录分组在一起。参考Kettle 排序记录的操作过程,建立排序并浏览“2019年10月月考英语成绩.xls”文件数据。
使用Ctrl+N快捷键,创建【分组】转换工程。接着创建【Excel输入】组件,设置参数,导入“2019年10月月考英语成绩.xls”文件。
再创建【排序记录】组件,并由【Excel输入】组件指向【排序记录】组件,建立节点连接,如图所示。
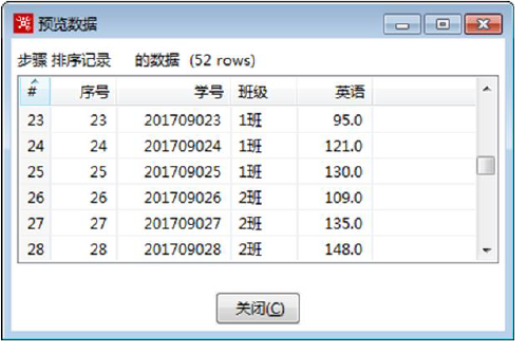
双击【排序记录】组件,设置“班级”字段参数,按照生序排序,预览排序记录数据,如图所示,“1班”和“2班”分别被排序在一起。
在【分组】转换工程中,单击【核心对象】选项卡,展开【统计】对象,找到【分组】组件,并拖拽到右边工作区中,并由【排序记录】组件指向【分组】组件,建立节点连接,如图所示。
2)设置参数
双击【分组】组件,弹出【分组】对话框,如图所示。
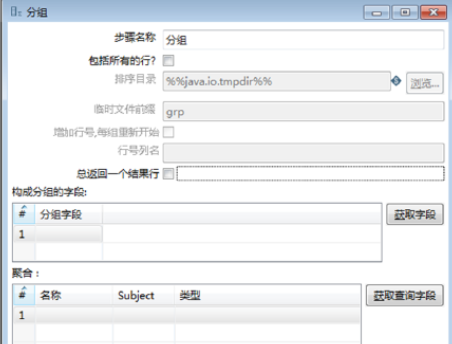
【分组】组件参数包含组件的基础参数,以及【构成分组的字段】和【聚合】字段参数,参数说明如表所示。
|
参数名称 |
说明 |
|
|
基础参数 |
步骤名称 |
表示分组的组件名称,在单个转换工程中,名称必须唯一。默认值是【分组】的组件名称。 |
|
包括所有的行 |
表示是否包括所有记录。使用勾选框设置参数,希望在输出中包含所有记录,则勾选,只想输出聚合记录,则不勾选。默认值为空。 | |
|
排序目录 |
表示指定存储临时文件的目录。分组的记录数超过5000个时,必须指定搞一个目录。此参数只有勾选【包括所有的行】参数后才能设置,默认值是系统的标准临时目录%%java.io.tmpdir%%。 | |
|
临时文件前缀 |
表示命名临时文件的文件前缀,只有勾选【包括所有的行】参数后才能设置。默认值为grp。 | |
|
添加行号,在每个组中重新启动 |
表示是否添加一个记录号,在每个组中从1重新启动。勾选此参数时所有记录都包含在输出中,且每个记录都有一个记录号。此参数在勾选【包括所有的行】参数后才有效。默认值为空。 | |
|
行号列名 |
表示要为每个新组添加记录的字段名称。默认值为空。 | |
|
总返回一个结果行 |
表示是否即使没有输入记录,也返回结果记录。当没有输入记录时,返回计数为0。如果只想有输入时才输出结果记录,则此参数不勾选。默认值为空。 | |
|
构成分组的字段 |
表示分组的字段参数。分组的字段可以有多个,使用一个【构成分组的字段】表设置【分组字段】参数,可以设置多个分组子段。需要注意的是,如果没有分组的字段,那么该表留空来计算整个数据集的聚合函数。默认值为空。 | |
|
聚合 |
表示聚合字段的参数,使用一个【聚合】表来设置聚合字段名称、聚合方法和输出结果新字段名称,有关聚合字段的参数说明如下内容所示。 | |
|
名称 |
表示聚合字段的名称,输出结果的新字段名称,默认值为空。 | |
|
Subject |
表示对其使用聚合方法的对象字段,默认值为空。 | |
|
类型 |
表示聚合方法。在下拉框中选取聚合方法,默认值为空。 | |
|
值 |
表示聚合的值,默认值为空。 | |
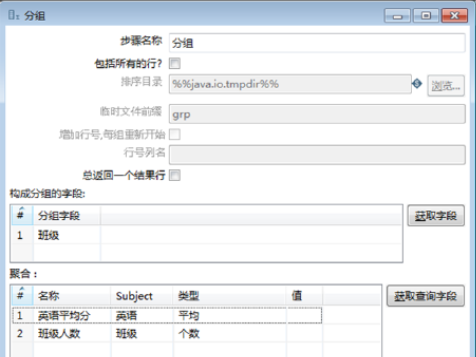
在【分组】对话框中,设置参数,分组统计各班的人数和平均分数,步骤如下:
1)设置组件名称。【步骤名称】参数采用默认值“分组”。
2)确定分组字段。在【构成分组字段】表的第1行,【分组字段】设置为“班级”。
3)确定聚合字段并设置参数。对【聚合】表的参数进行设置。此时完成【分组】组件参数的设置,如图所示。
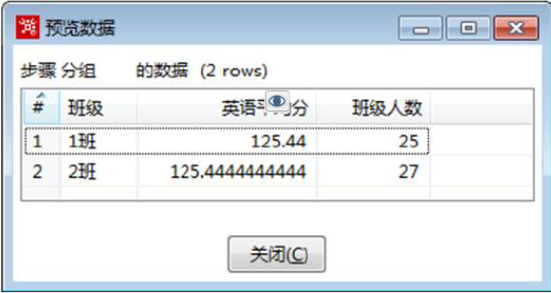
3)预览结果数据
在【分组】转换工程中,单击【分组】组件,预览数据分组后的结果,如图所示。
二十一、Kettle 多线程数据优化
这篇文章重点介绍多线程使用同步的配置思想,希望对大家有所帮助。
21.1、 表输出的多线程实例。
步骤的多线程执行方法是通过设置步骤的“更改开始复制数量”属性来实现。如果是表格输出控件,选择”ChangeNunberofCopiestoStart..”,然后在Numberofcopies的输入框中填入并发的线程数量。
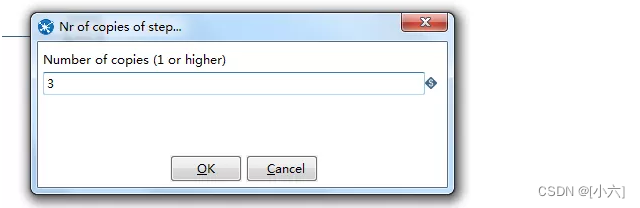
单向程测试:数据量10W,单线程14分钟。
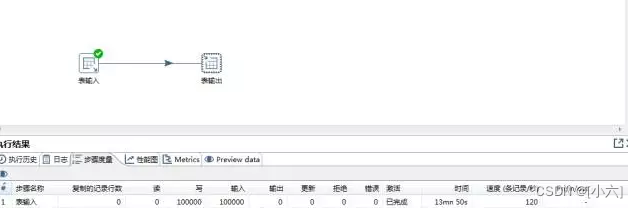
多线程测试:3线程7分钟的运行,效率加倍。“TableOutput这一步同时执行了3个线程,而TableInput则以轮询的方式将数据流按行发送到3个“表输出”线程。
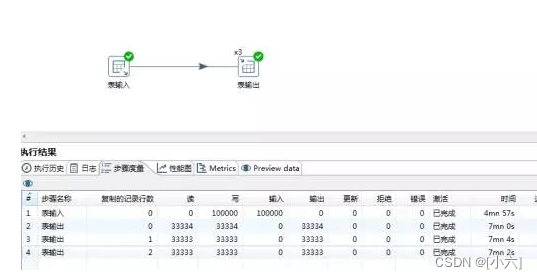
通过以上示例,您可以清楚地看到多线程相对于单线程而言效率的提升。
但是,在多线程”insert/update”场景中,如果更新的key并非惟一,则有可能产生死锁(多个线程一次更新同一行的数据)
通过以上示例,您可以清楚地看到多线程相对于单线程而言效率的提升。
但是,在多线程”insert/update”场景中,如果更新的key并非惟一,则有可能产生死锁(多个线程一次更新同一行的数据)
21.2、 ODS概要

是完全提取还是递增式提取,同步化使用?
配置的示例:
其中一种是增量式的增量条件,另一种是完全抽取,不需要抽取条件。
21.3、 实施步骤
1、从组态表中读取待提取的资料表。
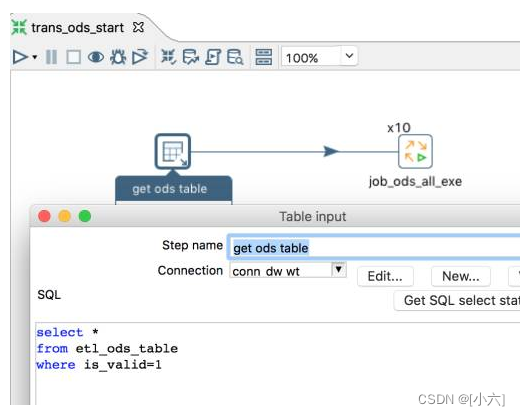
2、job_ods_all_exe同时执行10个线程,收到前一步传递的表名.数据库名称.提取类型等参数。
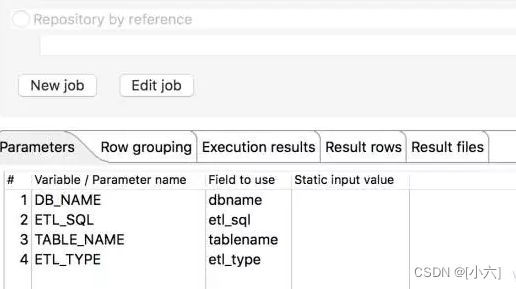
3、job_ods_all_exe,是否按ETL_TYPE分发数据是递增式提取还是完全抽取。
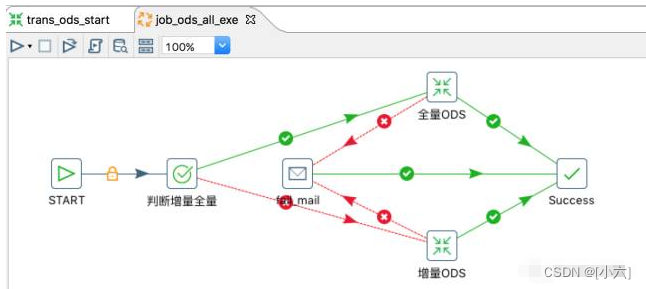
4、全量ODS和递增ODS实现逻辑:
二步是通过“表输入”步骤查询数据,全量是直接将表truncate为truncate,然后插入数据;deltaODS是使用插入更新的方式。
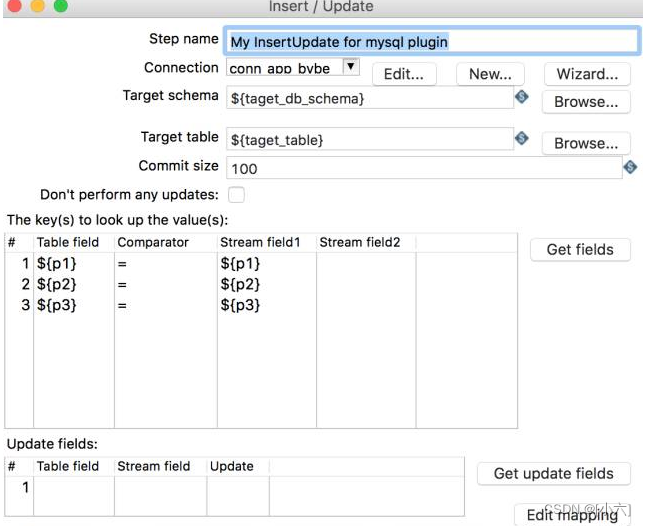
有两个必须插入一个更新控件:key.更新的字段,key可以将字段以传参的形式传递,需要扩展etl_ods_table表字段,配置源表的key,通常配置三个key字段就足够了;kettle自带的“insert/update”控件的update域是必选项,这是无法做到通用的,因为不可能所有同步表字段都是相同的,这需要定制插件,将updatefield变成必需项:
21.4、 其他配置项目
1、目标表配置:为etl_ods_table表中为每一个同步表配置一个目标表,用一个变量来表示目标表用:${taget_db_schema}.${taget_table_name},因此,可重复使用组件,提高总体灵活性。
2、资料库连结:设定源表与目标资料表使用资料表连结,以参数化方式,以资料库连结方式,设定资料表结构:
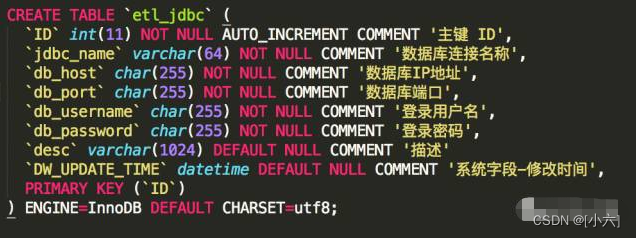
并且为etl_ods_table配置一个表,源表和目标表的数据量。据库连接的ID,查询同步表的信息时,数据库连接的也同时通过参数传递。
二十二、Kettle windows定时调度作业
本教程使用的kettle版本是7.0,调度之前务必先执行验证作业或转换是可以成功执行的。
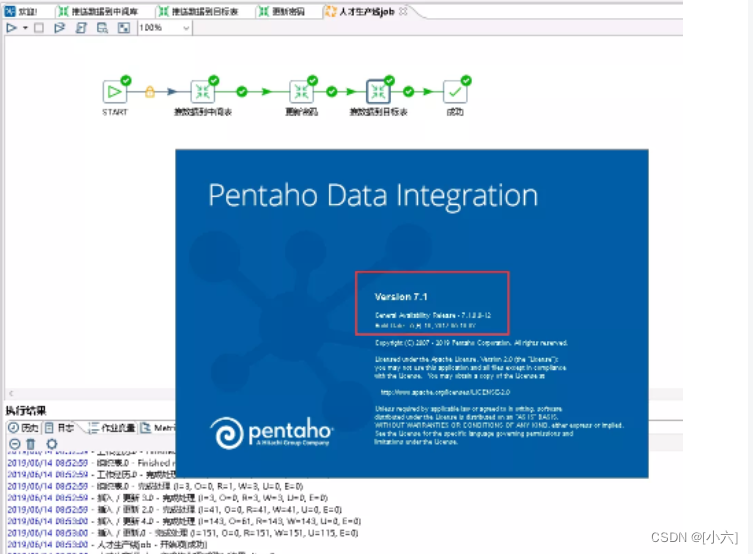
22.1、 编写kettle.bat脚本
(kitchen.bat 后面可以是-也可以是/然后再加options,而options 后面可以是=也可以是:也可以是空格)
D:cd D:\kettle\pdi-ce-7.1.0.0-12\data-integration
kitchen.bat -rep=product -user=admin -pass=admin -dir=/ -job=人才生产线job -level=basic>D:\kettle\JOB.log
顺便解释一下:
1、首先cd 是进入到kettle安装执行文件目录下
-rep 表示仓库名,也就是你的资源库的名称,我的资源库名称就是 product
-user 资源库用户名 这里就是admin
-pass 资源库密码 默认是admin ,为了安全我们可以更改密码
-dir 就是你的job在资源库中存放目录 支持中文的目录
-job job的名称 这里我的job名称就是:人才生产线job(job名字不要带后缀,不然提示找不到job错误)
-level 日志的级别 我们普通的写basic就可以了,就是最基本的
最后面就是日志了,针对job跑起来的相关信息都会保存在job.log中
2、针对相关的更多参数如下(options):
/rep : Repository name
/user : Repository username
/pass : Repository password
/job : The name of the job to launch
/dir : The directory (dont forget the leading /)
/file : The filename (Job XML) to launch
/level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing)
/logfile : The logging file to write to
/listdir : List the directories in the repository
/listjobs : List the jobs in the specified directory
/listrep : List the available repositories
/norep : Do not log into the repository
/version : show the version, revision and build date
/param : Set a named parameter <NAME>=<VALUE>. For example -param:FOO=bar
/listparam : List information concerning the defined parameters in the specified job.
/export : Exports all linked resources of the specified job. The argument is the name of a ZIP file.
注意:
保存kitchen.bat文件时,刚开始选的编码是utf8,此时中文乱码(后改为Unicode也是乱码),最后改为ANSI就可以了。
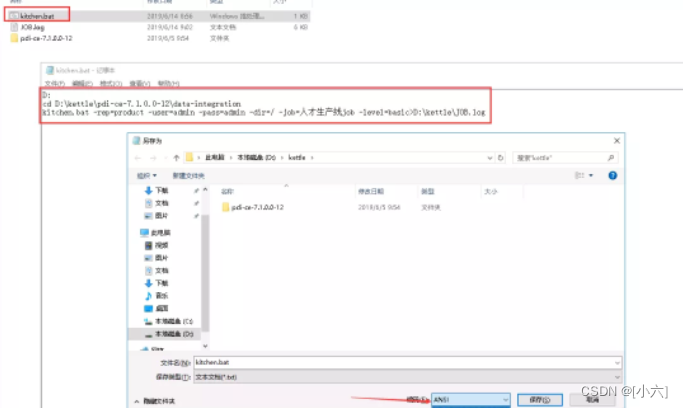
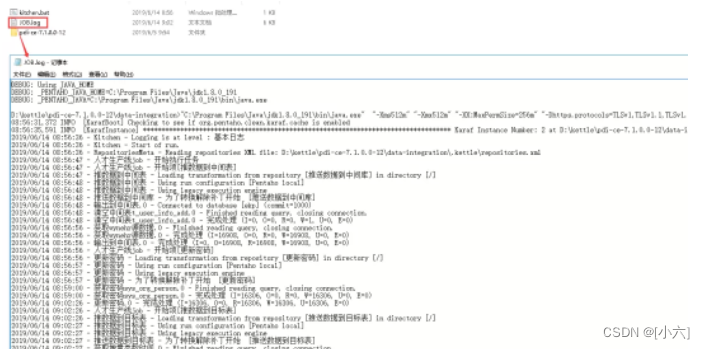
22.2、 cmd测试bat脚本
完成bat脚本以后,双击测试一下,会跳出cmd命令窗口,此时打开JOB.log日志记录,会发现已经在执行作业了,等待完成以后,cmd窗口会自动关闭。接下来就是Windows的定时任务来管理调度bat脚本了。
22.3、 windows下建立执行任务
(我的服务器是Windows Server 2016 Datacenter)
打开控制面板–管理工具–任务计划程序
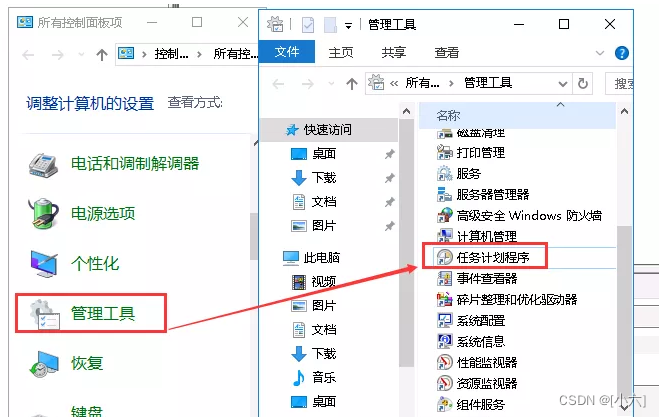
打开右侧的创建基本任务,填写作业名称,然后下一步打开触发器:
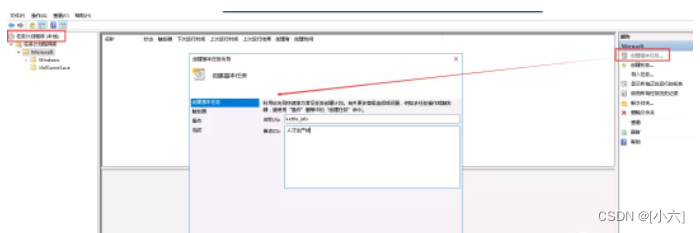
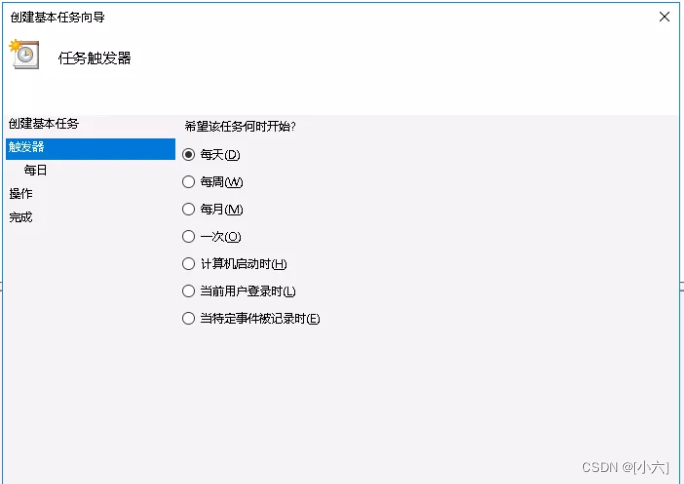
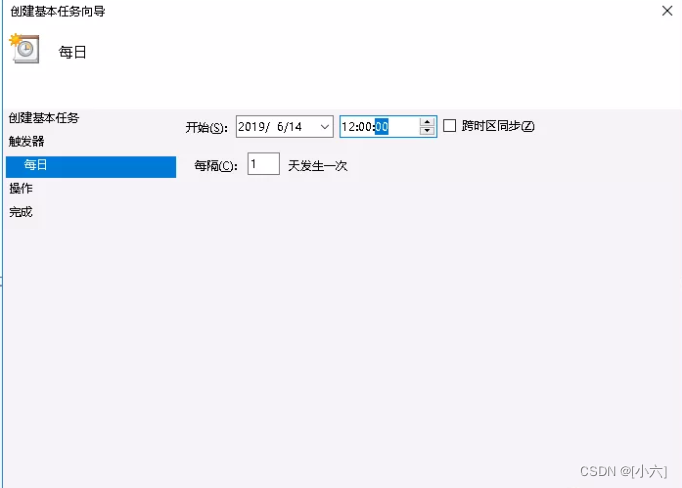
打开触发器,根据自己的需求选择执行频率,然后下一步打开具体的设置:
打开操作,下一步打开具体设置(选择需要执行的bat脚本),下一步完成:
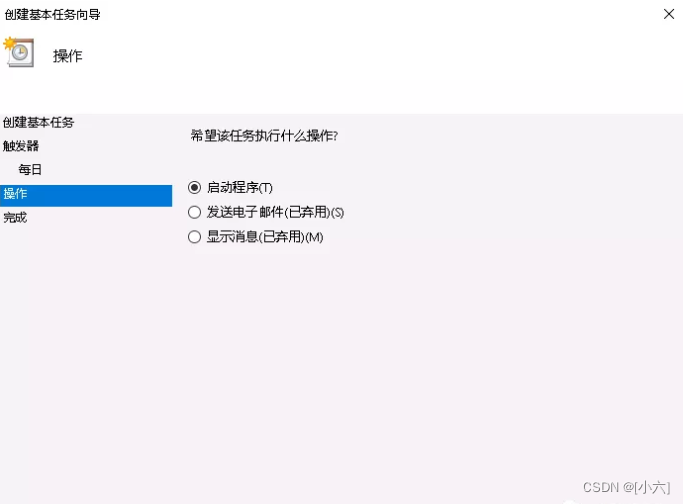
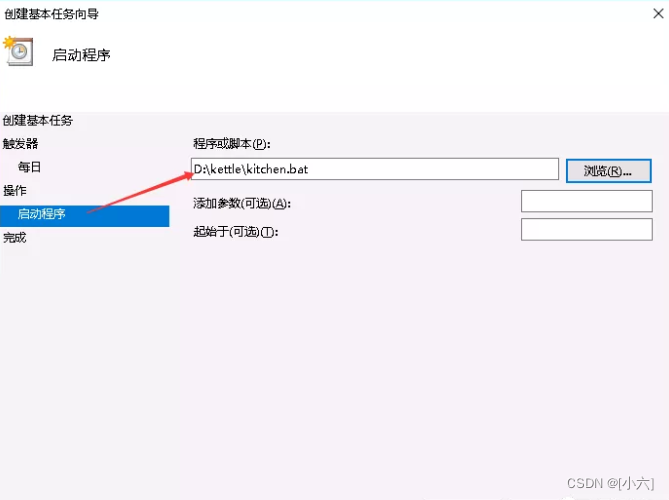
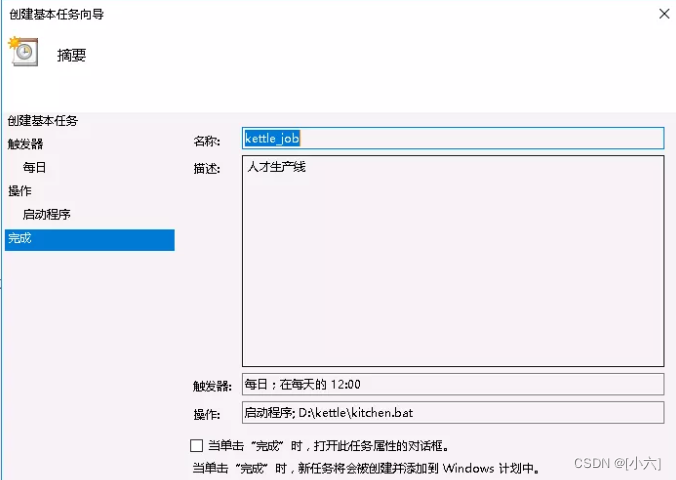
至此,Windows计划任务调度kettle作业完成。
二十三、Kettle 增量同步
增量同步的总体思路是:首先,获取此表的增量数据。
如何获得增量?源表需要一个时间字段来代表该记录的最新更新时间(只要该记录发生变化,时间字段就会更新)。
当然,最好有一个时间字段。如果没有,您可能需要进行全表比较等操作;通常,业务系统的表中有主键。在我们获得增量数据后,我们需要判断记录的新插入或更新记录。
如果是更新记录,我们需要先将数据加载到中间表,然后根据主键删除目标表中现有的数据,最后将此增量数据插入目标表。
本教程简单介绍了如何通过kettle实现简单的数据增量同步。
job如下:
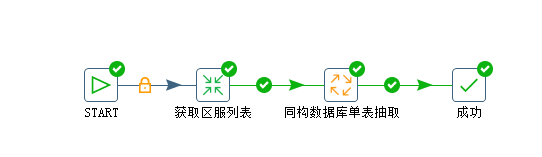
如下转换:获取区服列表,将id列表保存到结果(内存)
job: 同构数据库单表抽取(每个输入执行一次)
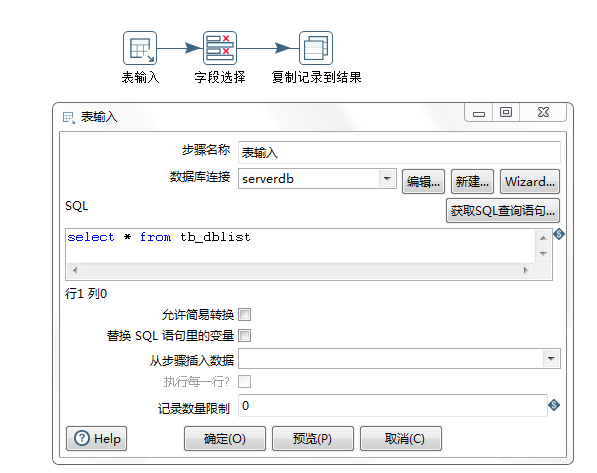
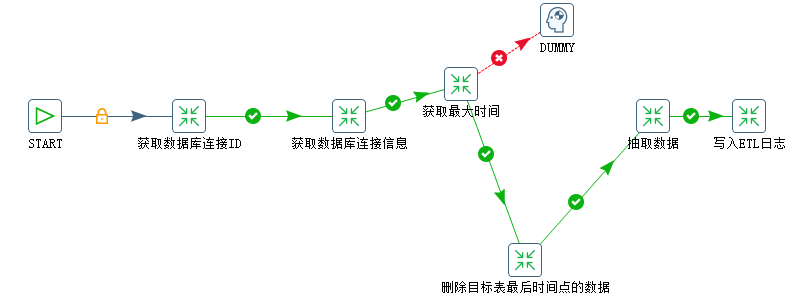
同构数据库单表抽取(job) 的具体实现如下:
转换:获取数据库连接ID
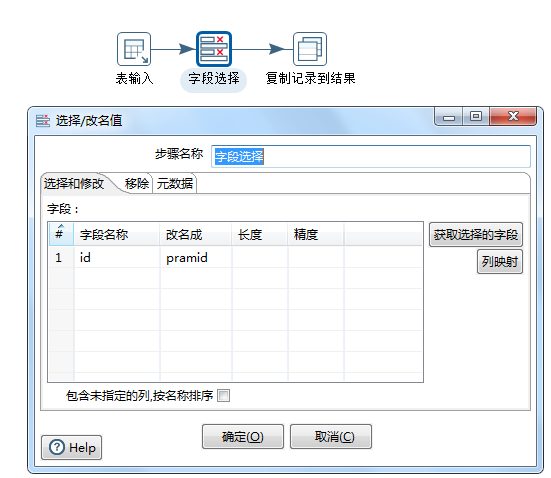
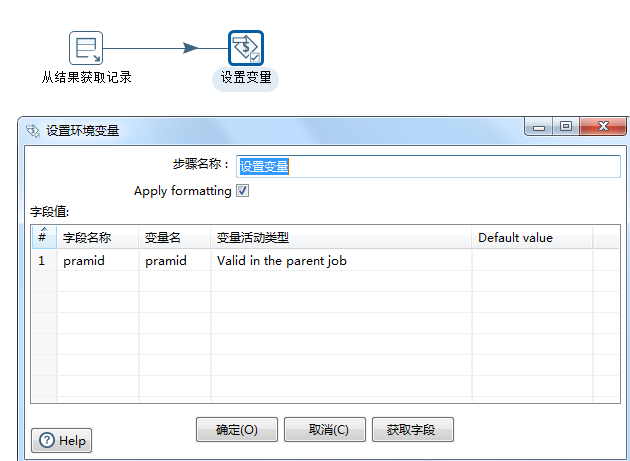
从结果获取本次输入id,并设置为变量parmid
转换:获取数据库连接信息
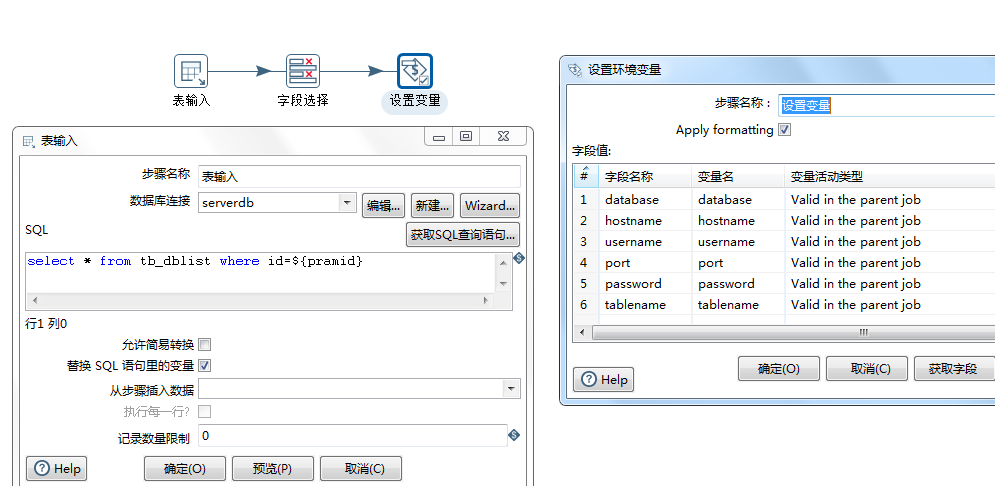
转换:获取最大时间
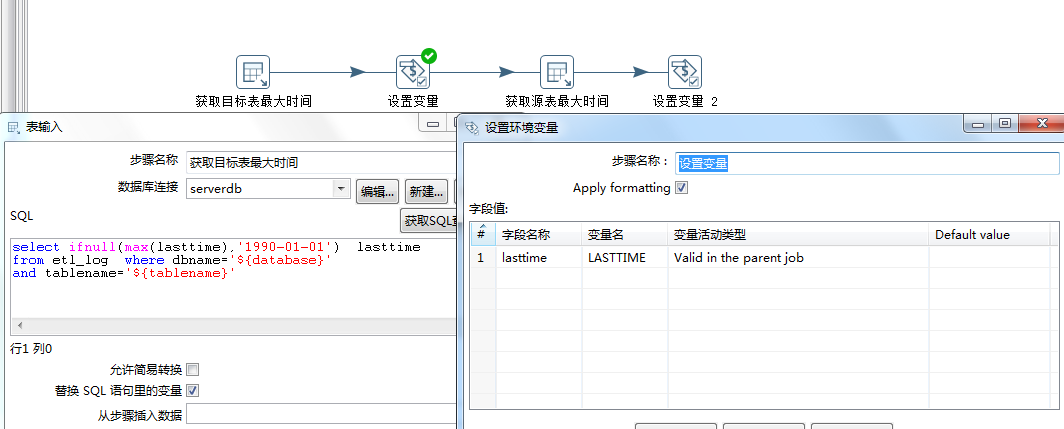
获取目标的最大时间并设置变量
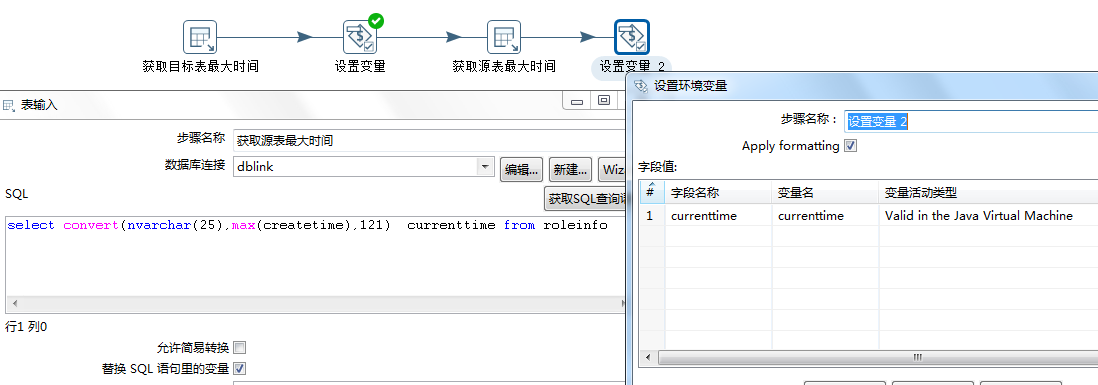
获取源表最大时间并设置变量,注(源数据库连接dblink为动态连接)
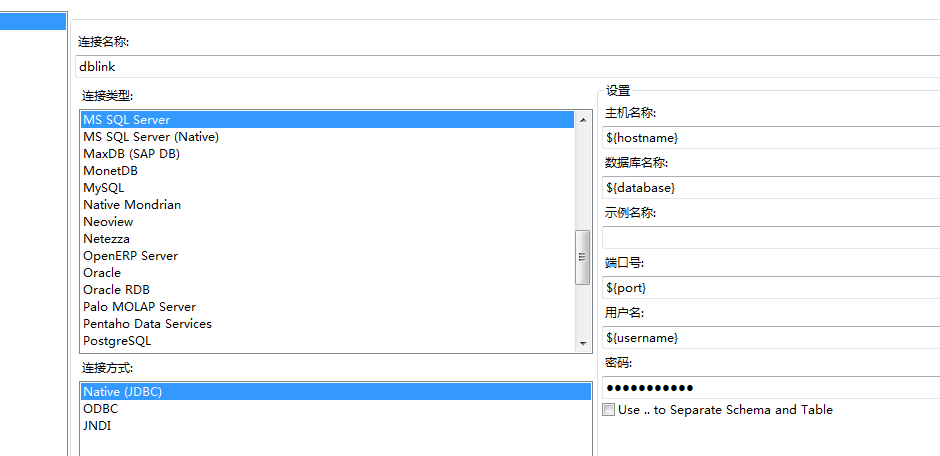
dblink:
转换:删除目标表最后时间点的数据(防止同一秒中出现多条记录,漏数据)
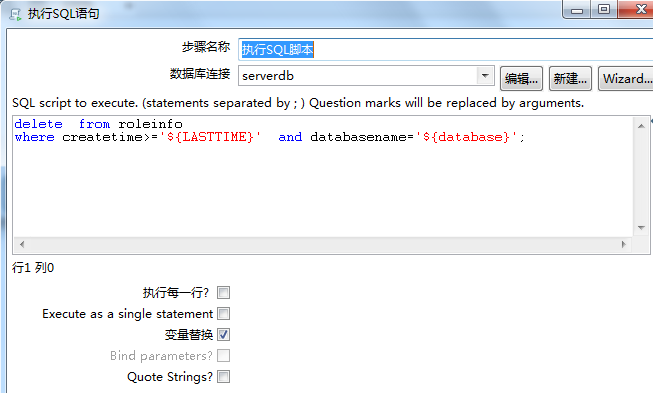
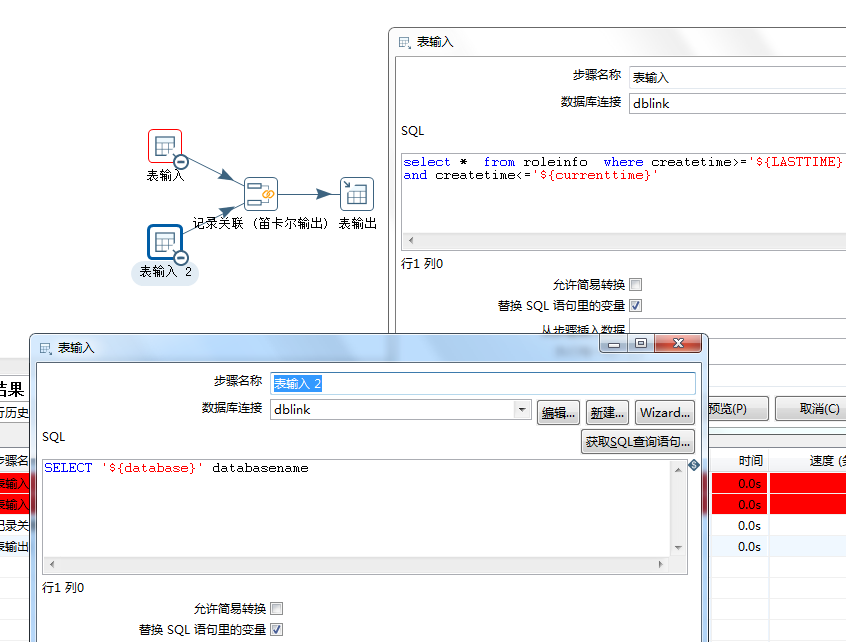
转换:抽取数据
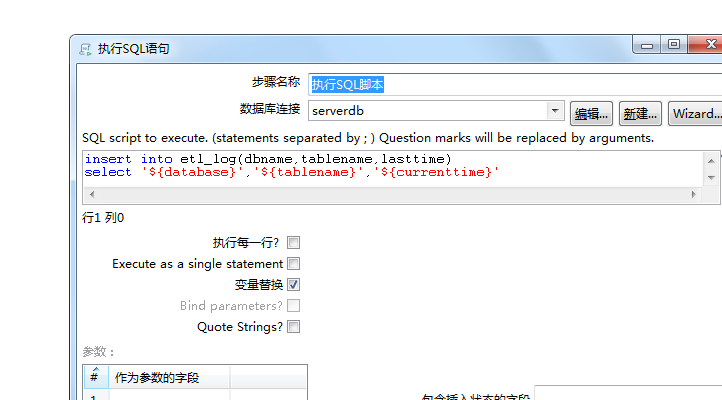
转换:写入ETL日志

 浙公网安备 33010602011771号
浙公网安备 33010602011771号