

sql关于group by之后把每一条记录的详情的某个字段值合并提取的方法
在利用group by写了统计语句之后,还有一个查看每一个记录详情的需求,
首先想到的是根据group by的条件去拼接查询条件,
但是条件有点多,拼接起来不仅麻烦,还容易出错,
所以想到要在group by之后同时把详情记录的ID给拼接成逗号分隔的字符串(‘1’,‘2’,‘3’)这种形式,这样再去取详情记录就很简单了
还是万能的博客园里面找到的方法:
select route_code,domain_id,type_id,COUNT(id0) as cnt, stuff( ( ----stuff函数用于删除指定长度的字符,并可以在指定的起点处插入另一组字符 select ','+cast(id0 as varchar)---字段拼接 from PMS_T_D_AssetInfo t where t.route_code=PMS_T_D_AssetInfo.route_code and t.domain_id=PMS_T_D_AssetInfo.domain_id and t.type_id=PMS_T_D_AssetInfo.type_id for xml path('') ) , 1, 1, '') as idStr --stuff将参数4的空字符串在参数1字符串的第1个(参数2)字符位置起替换掉1(参数3)个长度 from PMS_T_D_AssetInfo group by route_code,domain_id,type_id
得到的结果如下:
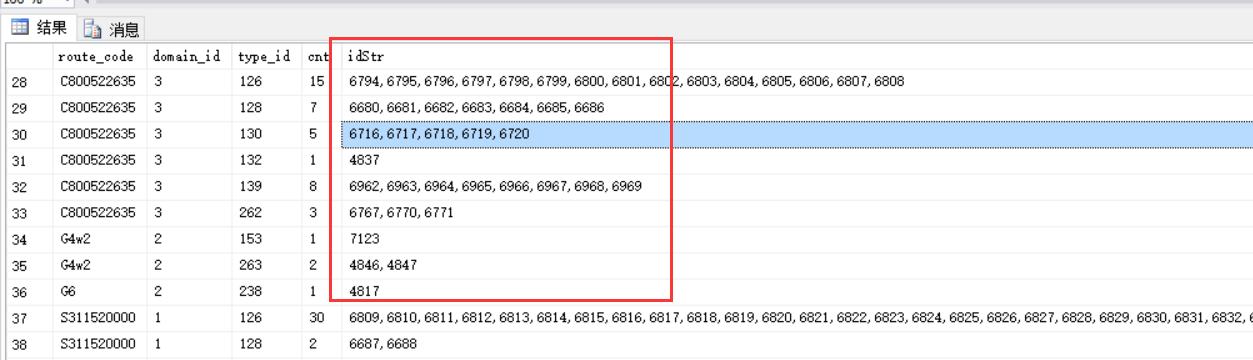
效果看上去很好,
但是,
统计数据大了之后,这个拼接字段会非常长,最后想想还是算了,还不如我直接拼接查询条件呢,
但是,这个方法还是不错的,在拼接字段明确有限的情况下可以用!
最后,
附上新认识的stuff函数简介:
一、作用
删除指定长度的字符,并在指定的起点处插入另一组字符。
二、语法
STUFF ( character_expression , start , length ,character_expression )
参数
character_expression
一个字符数据表达式。character_expression 可以是常量、变量,也可以是字符列或二进制数据列。
start
一个整数值,指定删除和插入的开始位置。如果 start 或 length 为负,则返回空字符串。如果 start 比第一个 character_expression 长,则返回空字符串。start 可以是 bigint 类型。
length
一个整数,指定要删除的字符数。如果 length 比第一个 character_expression 长,则最多删除到最后一个 character_expression 中的最后一个字符。length 可以是 bigint 类型。
返回类型
如果 character_expression 是受支持的字符数据类型,则返回字符数据。如果 character_expression 是一个受支持的 binary 数据类型,则返回二进制数据。
示例:
select STUFF('abcdefg',1,0,'1234') --结果为'1234abcdefg' select STUFF('abcdefg',1,1,'1234') --结果为'1234bcdefg' select STUFF('abcdefg',2,1,'1234') --结果为'a1234cdefg' select STUFF('abcdefg',2,2,'1234') --结果为'a1234defg'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号