【Spring系列】- Spring循环依赖
Spring循环依赖
😄生命不息,写作不止
🔥 继续踏上学习之路,学之分享笔记
👊 总有一天我也能像各位大佬一样
🏆 一个有梦有戏的人 @怒放吧德德
🌝分享学习心得,欢迎指正,大家一起学习成长!
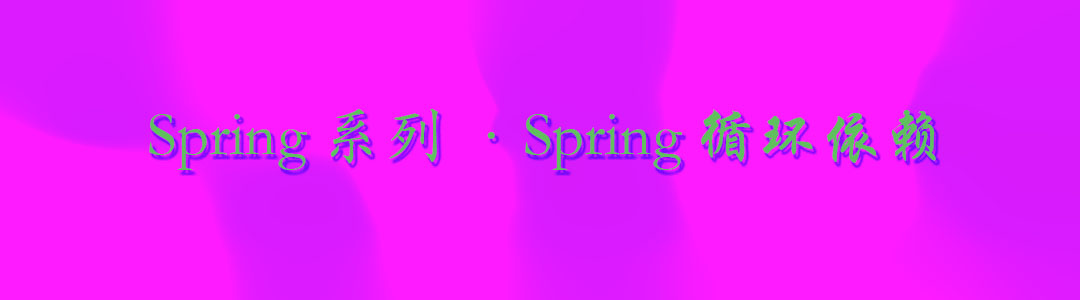
什么是循环依赖?
什么是循环依赖呢?简单来说就是beanA依赖于beanB,beanB依赖于beanA(也就是A类中使用了B类,B类使用了A类)。在bean创建的生命周期中,当创建了beanA的时候,会检索A对象内部中需要填充的对象,发现A中是需要用到B对象,会先去单例池中寻找,如果没有找到,就会去创建B的bean对象。在beanB的生命周期中,创建方式依然是相同的,因此也会去填充beanA,发现单例池中并没有A的bean对象,这样就造成了循环依赖。
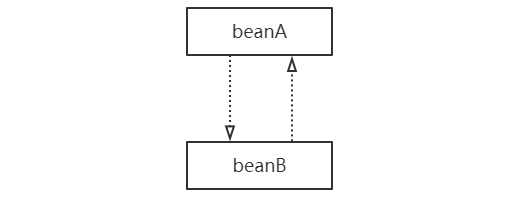
我们可以看看两个相互依赖的bean的生命周期
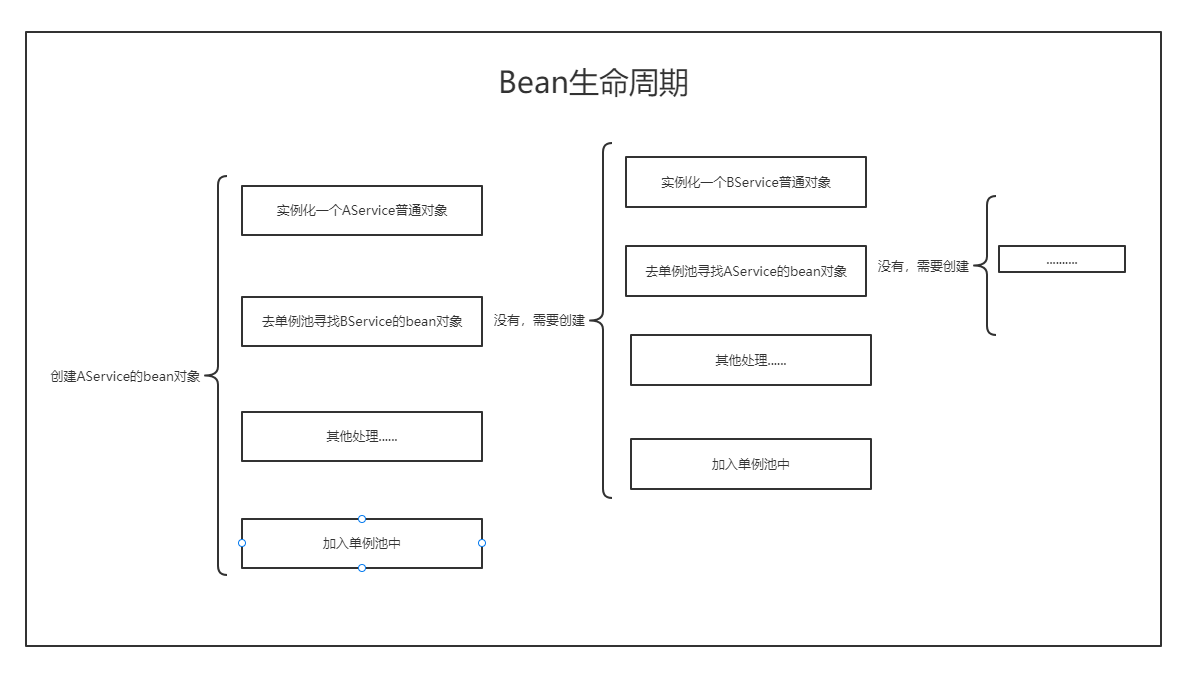
如何解决循环依赖
两个bean对象在还没有创建成bean对象就由于相互的依赖而进入的循环,那么,要如何去解开他们的循环呢?在spring中会使用三级缓存。在springboot中有许多的解决方法,比如加配置,加注解等等操作。
打破循环依赖
想要打破循环依赖,就只需要一个缓存即可,也就是使用一个Map集合。简单的说就是将所需的对象存入里面,在检测单例池没有所需的bean对象的时候,就通过beanName去查找一级缓存,这里要特别注意的是,一级缓存此时存储的是普通对象,是通过构造方法实例化的对象。
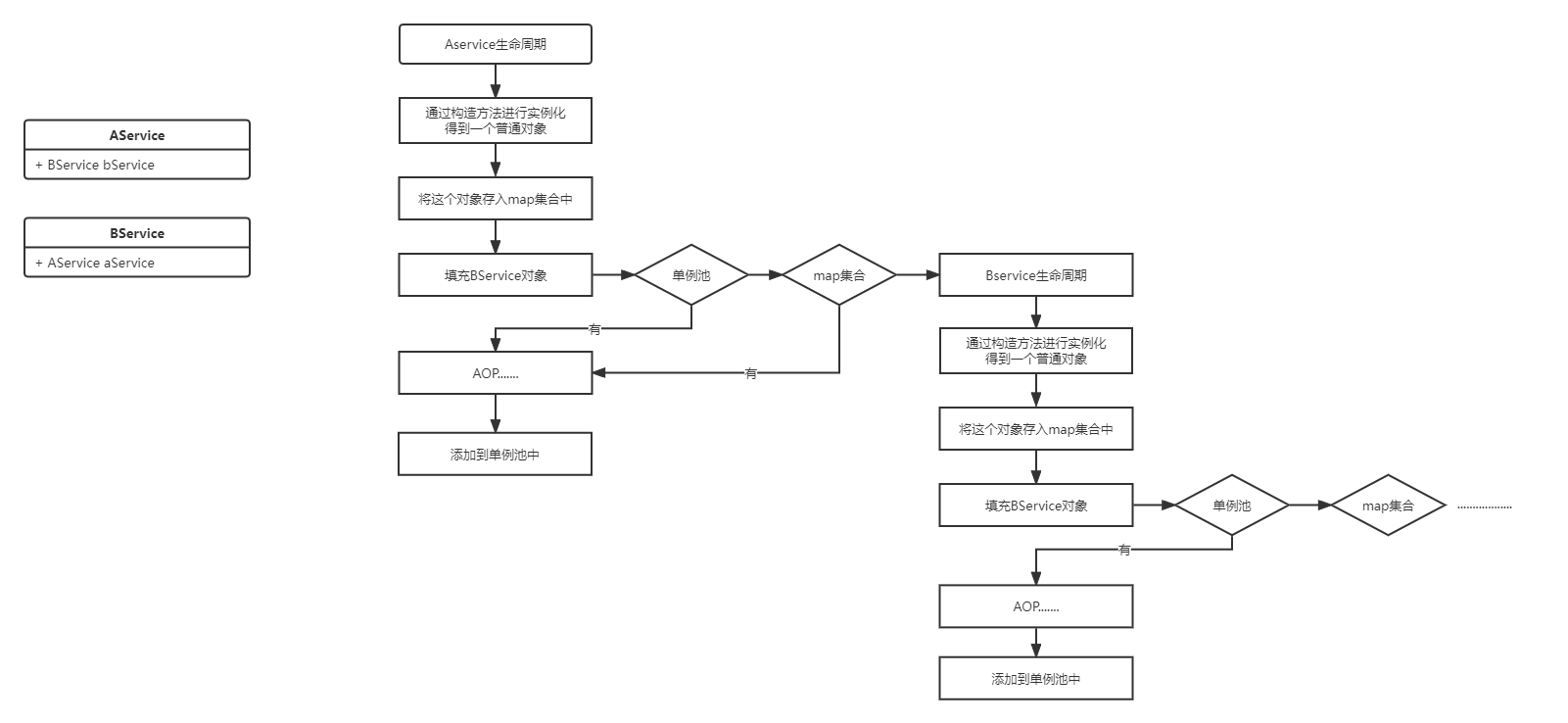
使用map来存储对象,可见能够解除循环依赖,但是这里存储的是普通对象,而不是一个代理对象。那么要如何解决呢?
提前AOP
可以通过提前AOP来得到代理对象,再把代理对象存到map集合中。在实例化普通对象后,直接进行AOP,生成代理对象,再将代理对象存到map集合中,然后在后面也就不需要进行aop了。但是,并不是每次都将AOP提前的,是在发现了循环依赖才是需要去将AOP提前。
判断是否循环依赖
要判断是否循环依赖也不是很难,就只需要一个集合creatingSet<'beanName'>。在实例化对象之前将这个bean的名字存到set集合中,表示这个bean对象正在创建中,等待依赖他的对象实例化后,会去判断set集合中是否有所依赖的beanName,如果有的话,就表示出现了循环依赖,这样就可以进行提前AOP。然而,在bean对象创建完毕并且添加到单例池之后,就要去吧set集合把这个beanName移除掉,不然就会造成每次都需要提前AOP。
一级缓存
一级缓存singletonObjects存放的是已经初始化好的bean,即已经完成初始化好的注入对象的代理
二级缓存
通过提前AOP获得的代理对象,是不能够直接加入到单例池中的。因为生成的代理对象是需要利用到普通对象的,而这时候的普通对象是不完整的(没有通过完整的生命周期),里面的属性可能是为空的。也会造成这个代理对象不是单例的。我们可以采用二级缓存earlySingletonObjects,将提前AOP生成的代理存放到earlySingletonObjects集合中。
在填充属性的时候,先到单例池寻找,没找到就去creatingSet看是否存在循环依赖,存在循环依赖之后就去earlySingletonObjects寻找是否有代理对象,没有再去提前AOP创建代理对象,并存入缓存中。在最后填充其他属性之后从二级缓存中去get代理对象,存入单例池中。
三级缓存
打破循环并不是只通过二级缓存,而是还需要一个三级缓存singletonFactory。addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));spring在创建bean的时候就会生成lambda表达式,存到三级缓存中。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
而执行lambda表达式就会去执行wrapIfNecessary这个方法
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
这个方法就能够去创建代理对象
Object proxy = this.createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
三级缓存主要才是用来解决循环依赖。在实例化对象的时候就将lambda表达式存入三级缓存中,singletonFActories.put("beanName", addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)));这个表达式的bean实际上就是普通对象,最后会生成的是代理对象。当遇到循环依赖的时候,就会先去二级缓存找再去三级缓存找,并且一定会找到,找到的是lambda表达式,然后去执行lambda表达式去生成代理对象最后当道二级缓存中。
博文推荐
Spring 循环依赖及三级缓存_程序源程序的博客-CSDN博客_三级缓存
👍创作不易,如有错误请指正,感谢观看!记得点赞哦!👍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号