【持久层框架】- SpringData - JPA
SpringData - JPA
😄生命不息,写作不止
🔥 继续踏上学习之路,学之分享笔记
👊 总有一天我也能像各位大佬一样
🏆 一个有梦有戏的人 @怒放吧德德
🌝分享学习心得,欢迎指正,大家一起学习成长!

JPA简介
JPA 即Java Persistence API。是一款持久层框架,中文名Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。JPA的对象关系映射(ORM)模型是基于Hibernate。是一款面向对象的ORM框架,JPA不需要关心数据库字段,通过注解将数据库表与实体完成映射,在java中的操作只需要对实体进行操作即可。
什么是ORM?
ORM(Object-Relational Mapping) 表示对象关系映射。在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中。只要有一套程序能够做到建立对象与数据库的关联,操作对象就可以直接操作数据库数据,就可以说这套程序实现了ORM对象关系映射。也就是说ORM是建立了一个实体与数据库表的关系,使得开发者对实体的直接操作而不是对数据库的操作,但操作实体也就等同于操作了数据库。
ORM框架还有:MyBatis、Hibernate
SpringData-JPA
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。
它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现
在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
SpringBoot整合JPA
接下来通过一个案例简单学习一下JPA,并且在案例中学习一些相关知识。
导入依赖
需要导入jpa坐标和mysql依赖包
<dependencies>
<!--jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--Mysql依赖包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
编写配置文件
先配置数据源,采用mysql8.0。还包括配置jpa的相关配置。主要是配置jpa的sql日志打印和自动创建表格。
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/springboot_demo?useUnicode=true&useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai
username: root
password: 12356
jpa:
show-sql: true
hibernate:
ddl-auto: create # 自动创建表格,之后改成update
jpa的底层是通过hibernate执行的,通过配置ddl-auto能够自动创建表,但是这个不建议使用,如果是create,在项目运行的时候就会把存在的表删除在添加。详情如下:
ddl-auto属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有4种
- create 启动时删数据库中的表,然后创建,退出时不删除数据表
- create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在报错
- update 如果启动时表格式不一致则更新表,原有数据保留
- validate 项目启动表结构进行校验 如果不一致则报错
接下来就可以开始体验jpa了
创建实体类
可见通过注解可以实现实体与数据库的直接映射,jpa操作的就是这些实体就等同操作数据库的表结构。
package com.jpa.demo.domain;
import lombok.Data;
import javax.annotation.Generated;
import javax.persistence.*;
import java.io.Serializable;
/**
* @author: lyd
* @description: 实体User
* @Date: 2022/10/2
*/
@Data
@Entity
@Table(name = "sys_user")
public class User implements Serializable {
@Id
@Column(name = "user_id")
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增
private Long id;
private String username;
private String nickName;
private String password;
}
- @Data:lombok下的注解,主要是方便开发,减少对get、set、tostring的编写。这个需要导入相应的依赖坐标。
- @Entity:声明是一个实体。
- @Table(name = "sys_user"):指明数据库中表的名字实现实体与数据表映射。
- @Id:声明主键。
- @Column(name = "user_id"):指明是表中的哪个字段。
- @GeneratedValue(strategy = GenerationType.IDENTITY): GenerationType.IDENTITY:实现自增
启动项目
当我们启动项目的时候,数据库会自动创建表结构。

看一下数据库,发现表已经自动创建
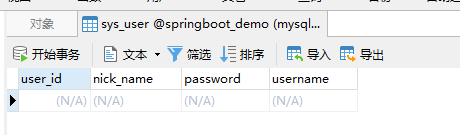
对表操作
增加数据
首先需要创建UserRepository接口,要通过继承JpaRepository<T, ID>,提供实体类和id的类型。
/**
* @author: lyd
* @description: UserRepository
* @Date: 2022/10/2
*/
@Repository
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {
}
编写测试类
通过调用save方法即可完成保存操作
package com.jpa.demo.test;
import com.jpa.demo.domain.User;
import com.jpa.demo.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.junit.jupiter.api.Test;
/**
* @author: lyd
* @description: 测试类
* @Date: 2022/10/2
*/
@SpringBootTest
public class JpaTest {
@Autowired
private UserRepository userRepository;
@Test
void InsertTest() {
User user = new User();
user.setNickName("怒放吧德德");
user.setUsername("lyd_code");
user.setPassword("lyd_open");
User save = userRepository.save(user);
System.out.println(save);
}
}
运行结果
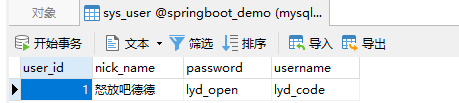
查看数据
通过findAll就可以直接获取得到所有的数据。
@Test
void QueryTest() {
List<User> all = userRepository.findAll();
all.forEach(System.out::println);
}
就能在控制台中看到:

分页查找
jpa也是实现了分页操作的方法。通过PageRequest.of(0,1)可以完成分页。
@Test
void PageRequestTest() {
userRepository.findAll(PageRequest.of(0,1)).forEach(System.out::println);
}
其底层对数据库的操作就会加上limit.

根据ID查找
返回是Optional类,User类型的数组
@Test
void FindByIdTest() {
Optional<User> user = userRepository.findById(1L);
System.out.println(user);
}
Java8 新特性Optional类
Optional 类新特性Optional 类是一个可以为null的容器对象
如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象
Optional 是个容器:它可以保存类型T的值,或仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测
Optional 类的引入很好的解决空指针异常
方法命名规则自定义查询
方法命名规则查询就是根据方法的名字,就能创建查询。需要按照Spring Data JPA提供的方法命名规则定义方法的名称,就可以完成查询工作。Spring Data JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询。通过jpa的规则要求来实现自己命名查询。
按照Spring Data JPA 定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
编写Repository
根据一定的规则来编写方法命名。jpa会自动识别方法名称进行操作。
package com.jpa.demo.repository;
import com.jpa.demo.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @author: lyd
* @description: UserRepository
* @Date: 2022/10/2
*/
@Repository
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {
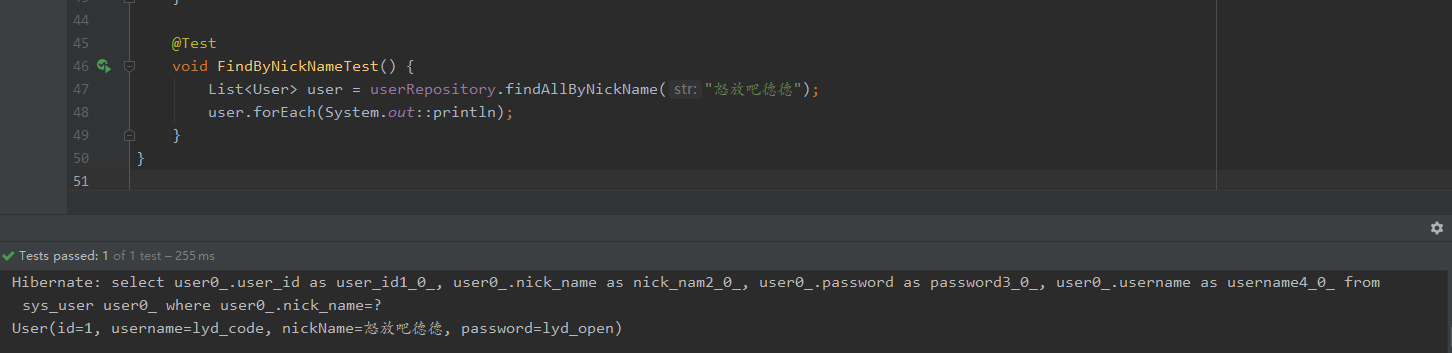
//根据nickname查询
List<User> findAllByNickName(String str);
}
通过测试可以看到如下结果:
在编写repository的时候会有一些规则提示,也就是只有符合这些规则才能够被识别。这里只是展现了findxxx,实际上还有许多。
具体的关键字,使用方法和生产成SQL如下表所示
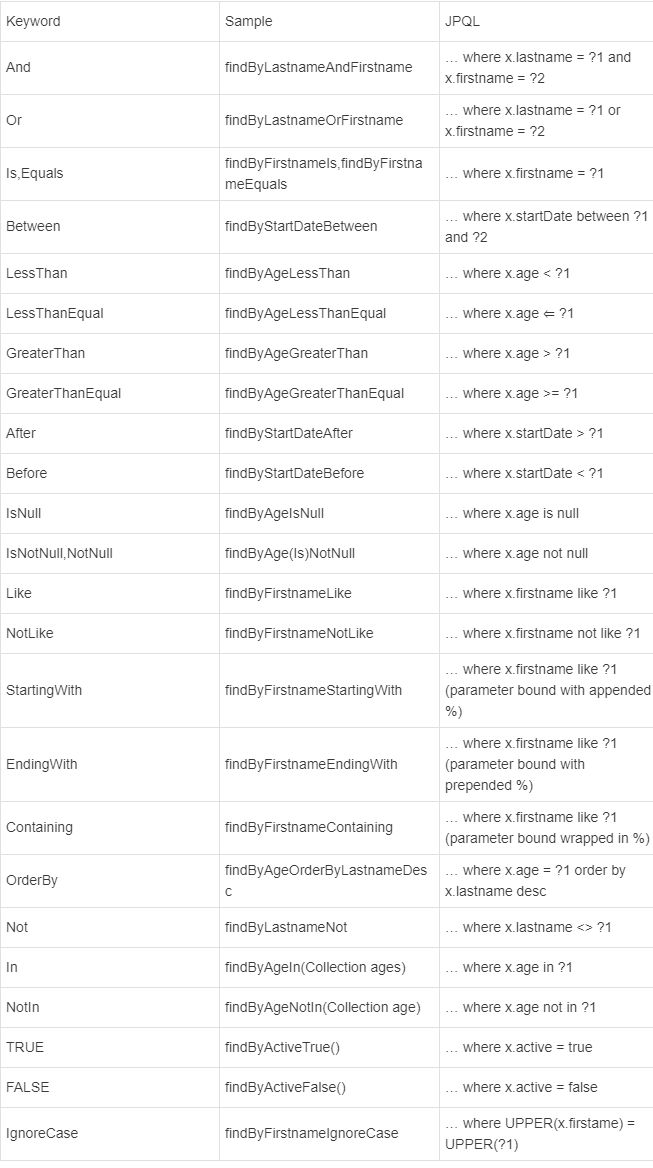
使用JPQL的方式查询(注解式SQL)
通过Query注解可以实现更多灵活的条件查询等SQL·操作。@Query 注解的使用非常简单,只需在方法上面标注该注解,同时提供一个JPQL查询语句即可,并且,在这些SQL语句中都是使用实体来进行操作,并非数据库的表结构来操作。
计数
通过Query可以写自己的SQL语句
@Query("select count(u) from User u") // 这里使用的是实体,并不是数据库的表名和字段
Integer countUser();
测试
@Test
void CountUser() {
Integer integer = userRepository.countUser();
System.out.println(integer);
}
结果

参数传递
在通过注解写SQL的时候,也需要是携带参数的,而Query通过?占位符来获得传来的参数数据,通过参数的位置定位哪个参数。
//修改数据 一定加上@Modifying 注解
@Transactional
@Modifying
@Query("update User set username=?1 where id=?2")
int updateUsernameByIds(String username,Long id);
结果

也可以使用原生的SQL,只需要加上 nativeQuery = true 即可。
实体关系对应
jpa中实体包括一对一,一对多,多对多,多对一关系,并且提供了相应的注解。接下来通过案例来实现关系。
一对一
首先创建部门表,使用户指向一个部门。
package com.jpa.demo.domain;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
/**
* @author: lyd
* @description: 部门
* @Date: 2022/10/2
*/
@Entity
@Data
@Table(name="sys_dept")
public class Dept implements Serializable {
@Id
@Column(name = "dept_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
在User实体中加字段,通过OneToOne注解完成。
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL) //设置关联操作为ALL
@JoinColumn(name = "dept_id")
private Dept dept;
这里的关联级别也是有多个,一般设置为all就行
- ALL:所有操作都进行关联操作
- PERSIST:插入操作时才进行关联操作
- REMOVE:删除操作时才进行关联操作
- MERGE:修改操作时才进行关联操作
这样就可以编写测试
@Test
void OneToOneTest() {
User user = new User();
user.setNickName("爱国德德");
user.setUsername("lyd_code_studio");
user.setPassword("lyd_open");
Dept dept = new Dept();
dept.setName("研发部");
user.setDept(dept);
User save = userRepository.save(user);
System.out.println(save);
}
通过测试可得数据库结果,
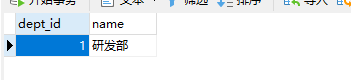

通过关联,会在两个表中进行插入,删除也是会删除两个表中数据。
一对多
@OneToMany:
作用:建立一对多的关系映射
属性:
targetEntityClass:指定多的多方的类的字节码
mappedBy:指定从表实体类中引用主表对象的名称。
cascade:指定要使用的级联操作
fetch:指定是否采用延迟加载
orphanRemoval:是否使用孤儿删除
创建一个文章表来实现一对多关系,一个用户可以发表多个文章,一个文章只属于一个用户,因此在用户表中是一对多,在文章表就是多对一。
通过@ManyToOne注解完成关系
package com.jpa.demo.domain;
import lombok.Data;
import javax.persistence.*;
/**
* @author: lyd
* @description: 文章表
* @Date: 2022/10/2
*/
@Data
@Entity
@Table(name="yun_article")
public class Article {
@Id
@Column(name = "article_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 50) // 映射为字段,值不能为空
private String title;
@Basic(fetch = FetchType.LAZY) // 懒加载
@Column(nullable = false) // 映射为字段,值不能为空
private String content;
@ManyToOne(cascade={CascadeType.MERGE,CascadeType.REFRESH},optional=false)//可选属性optional=false,表示user不能为空。删除文章,不影响用户
@JoinColumn(name="user_id")//设置在article表中的关联字段(外键)
private User user;
}
在user实体这边就是一对多关系,并且通过注解完成。
@OneToMany(mappedBy = "user",cascade=CascadeType.ALL,fetch=FetchType.LAZY)
//级联保存、更新、删除、刷新;延迟加载。当删除用户,会级联删除该用户的所有文章
//拥有mappedBy注解的实体类为关系被维护端
private Set<Article> articles;
测试,需要创建ArticleRepository
@Test
void OneToMany() {
User user = userRepository.getById(1L);
Article article1=new Article();
article1.setTitle("如何写好博客");
article1.setContent("如何写好博客");
article1.setUser(user);
articleRepository.save(article1);
Article article2=new Article();
article2.setTitle("如何更进一步学习");
article2.setContent("不断地卷");
article2.setUser(user);
articleRepository.save(article2);
}
运行结果

数据库中
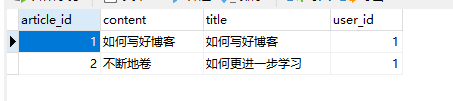
多对多
JPA中使用@ManyToMany来注解多对多的关系,由一个关联表来维护。这个关联表的表名默认是:主表名+下划线+从表名。(主表是指关系维护端对应的表,从表指关系被维护端对应的表)。这个关联表只有两个外键字段,分别指向主表ID和从表ID。字段的名称默认为:主表名+下划线+主表中的主键列名,从表名+下划线+从表中的主键列名。通过@JoinTable来实现中间表。
创建角色表
package com.jpa.demo.domain;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Set;
/**
* @author: lyd
* @description: 角色表
* @Date: 2022/10/2
*/
@Data
@Entity
@Table(name = "sys_role")
public class Role implements Serializable {
@Id
@Column(name = "role_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToMany(mappedBy = "roles")
private Set<User> users;
private String name;
@Column(name = "level")
private Integer level = 3;
private String description;
}
在用户表中
@ManyToMany
@JoinTable(name = "sys_users_roles",
joinColumns = {@JoinColumn(name = "user_id",referencedColumnName = "user_id")},
inverseJoinColumns = {@JoinColumn(name = "role_id",referencedColumnName = "role_id")})
private Set<Role> roles;
测试
@Test
void ManyToMany() {
Role role = new Role();
role.setName("USER");
role.setLevel(2);
role.setDescription("管理员");
roleRepository.save(role);
Set<Role> roles = new HashSet<>();
roles.add(role);
User user = new User();
user.setPassword("lyd_code");
user.setNickName("怒放德德");
user.setUsername("lyd_code");
user.setRoles(roles);
User save = userRepository.save(user);
System.out.println(save);
}
在数据库中的中间表就能够看到如下数据。
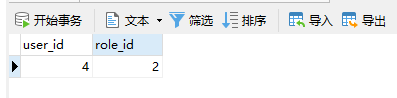
文章推荐
- 元动力文档合集 - SPRING-DATA-JPA
- CSDN:https://blog.csdn.net/cmx1060220219/article/details/106259423
- CSDN:https://blog.csdn.net/localhost01/article/details/83422893
👍创作不易,如有错误请指正,感谢观看!记得点赞哦!👍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号