Pytorch深度学习环境配置 | NVIDIA-driver + Pytorch + miniconda
本贴为实战,看理论请移步【地表最强】深度学习环境配置攻略 | 【nvidia-driver】, 【cuda toolkit】, 【cudnn】, 【pytorch】
为了验证我的环境配置方法没有问题,我特意租了两小时云服务器来从0配置环境。
- 云服务器厂家:Ucloud
- ubuntu22.04
- 3090 * 2
1. 装 NVIDIA-driver
参考:https://zhuanlan.zhihu.com/p/366882419
1.1 禁用ubuntu自带的Nouveau驱动
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
输入
blacklist nouveau
options nouveau modeset=0
使其生效:
sudo update-initramfs -u
重启
reboot
验证
lspci | grep nouveau
如果没有输出内容,就说明成功了:

如果出现一大堆东西,说明失败了
1.2. 下载驱动
nvidia显卡驱动下载网址 (不太全,但能找到常用的显卡驱动)
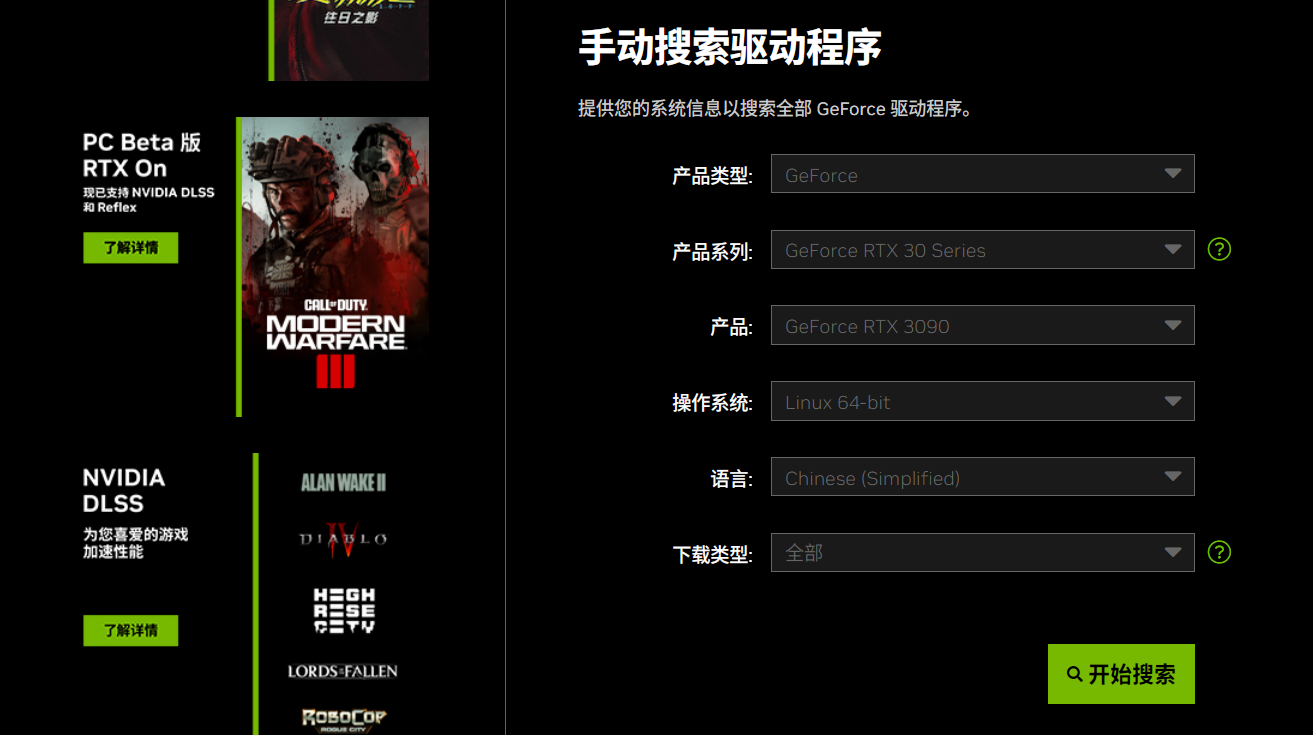
然后根据显卡型号和要装的pytorch版本,选择合适的驱动(不知道怎么选择就看这里)
综合考虑下来,我选择这个版本:

点【获取下载】,弹出如下界面:

把鼠标放到【立即下载】处,右键,选择【复制链接地址】
然后回到shell
wget https://cn.download.nvidia.com/XFree86/Linux-x86_64/535.113.01/NVIDIA-Linux-x86_64-535.113.01.run
1.3. 安装驱动
chmod +x NVIDIA-Linux-x86_64-535.113.01.run
./NVIDIA-Linux-x86_64-535.113.01.run
我弹出如下报错:【unable to find the development tool cc】

说明缺少依赖项【gcc】
sudo apt update #更新apt源。这一步不做后面用apt下载东西会报错
sudo apt-get install build-essential
然后中途弹出个这个
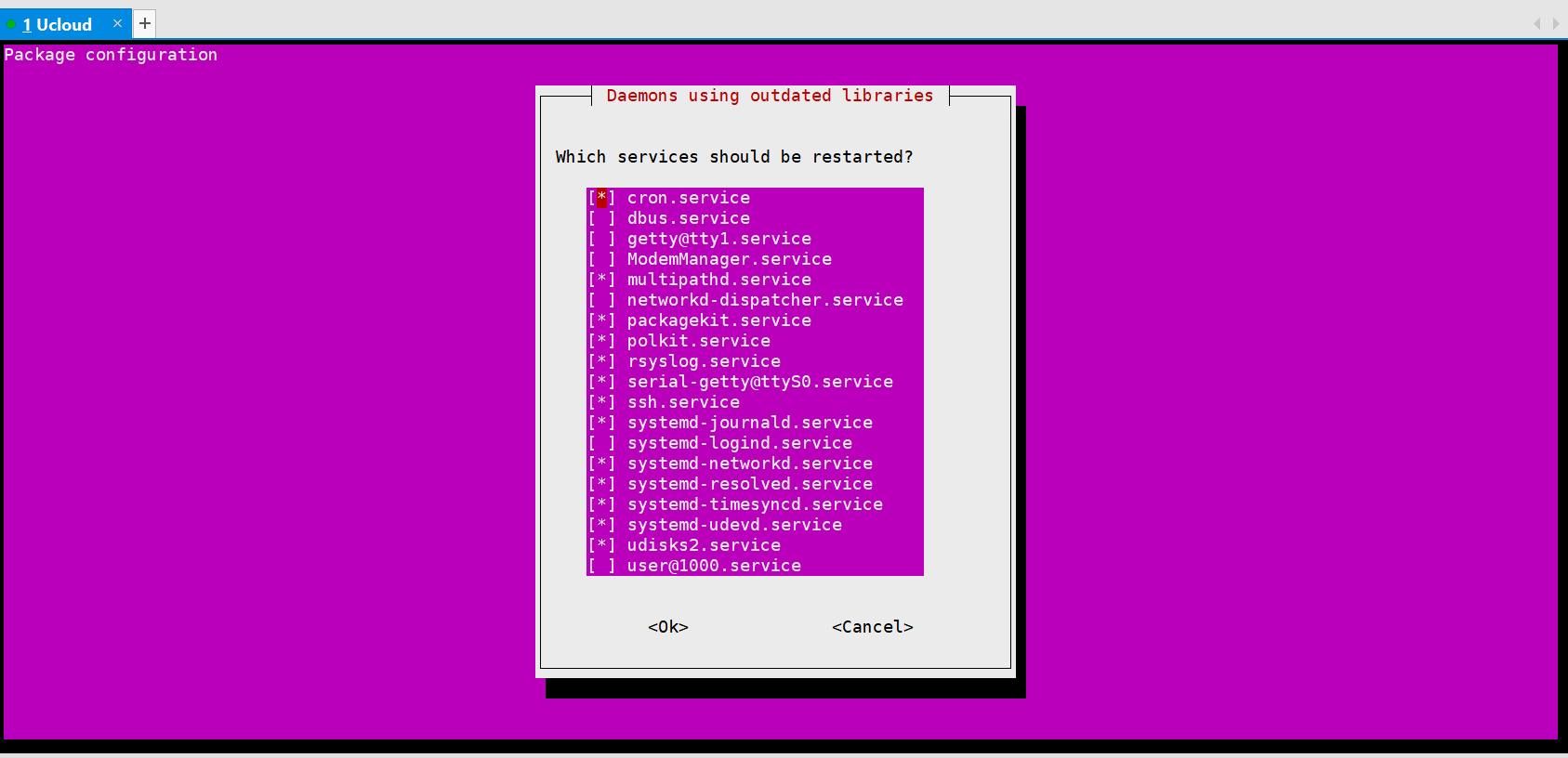
直接回车,就会回到shell界面
然后验证一下:
gcc --version

ok,然后再次安装driver:

一路回车,回到shell,验证:
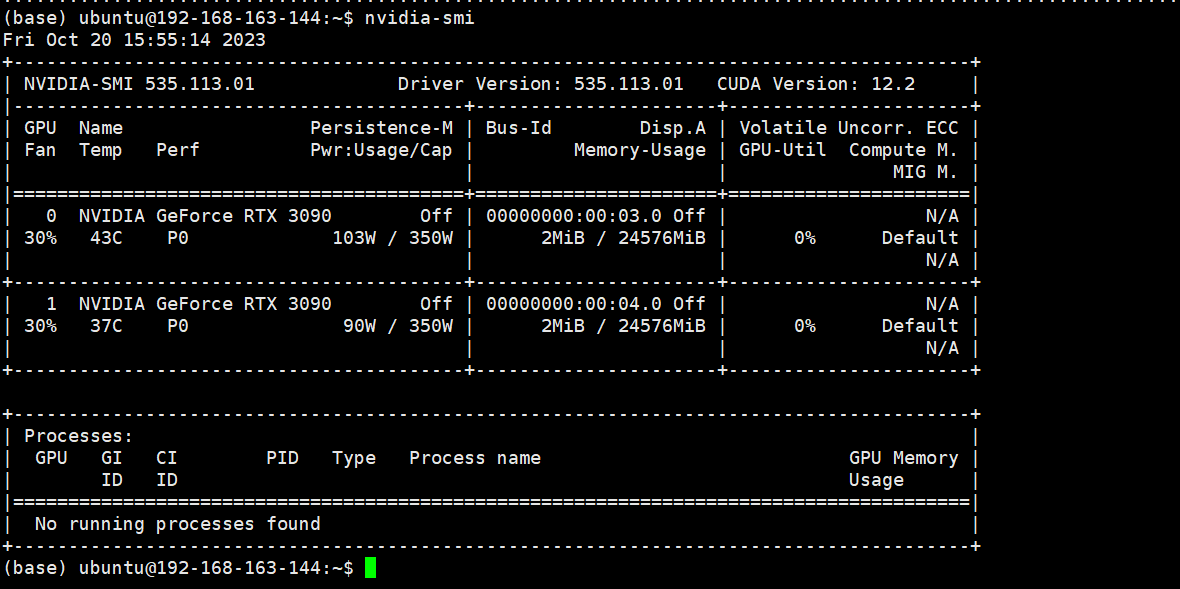
nice!driver安装成功。
手动分割线------------------------------------------------------------------------------------------------
安装driver时可能还会报另一个错:【Unable to find the development tool 'make'】,这就说缺少依赖项【cmake】
sudo apt update #更新apt源。这一步不做后面用apt下载东西会报错
sudo apt-get install cmake
cmake --version
2. 安装GPU版本的Pytorch
2.1. 装miniconda
去这里找miniconda
我选了这个版本

然后把鼠标放在【Miniconda3 Linux 64-bit】上,右键,点击【复制链接地址】
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
中间有一步是创建安装文件夹,记得输入你的文件夹名字:
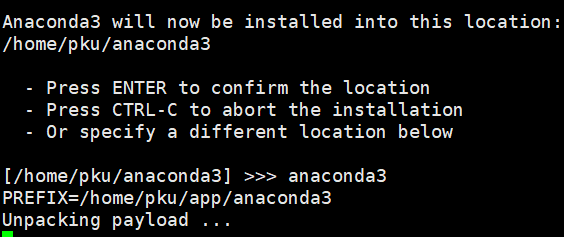
然后安装完之后,关掉当前shell,再重新打开一个shell,出现 (base) 就算成功。

2.2. 创建自带python的虚拟环境
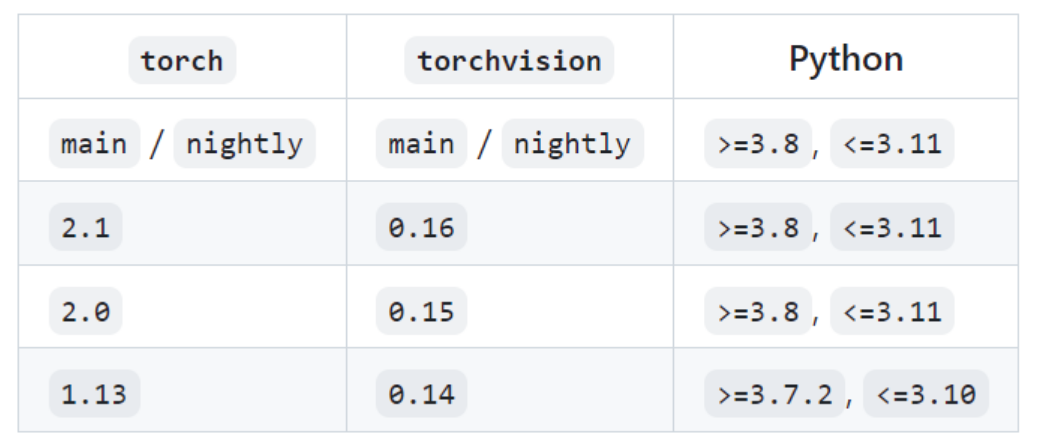
根据我们要安装的pytorch版本,选择相应的python版本。(不知道怎么选择?看这里)
例如,我这里要装pytorch 2.1,根据下表,我选择安装python10(不新不旧,最兼容)
conda create -n pytorch-cuda12.1 python=3.10
conda activate pytorch-cuda12.1
python -V (验证python版本)
2.3. 在虚拟环境中装pytorch(GPU版本)
Pytorch官网提供了conda 和 pip 两种安装方法.
我不推荐conda安装,理由如下:
- 有逆天大坑,一步小心就安装成了cpu版本
- 容易被卡在 【solving environment】 这一步(Byd卡我一个下午,我才意识到不对劲)
- 好不容易能下载了,速度贼慢
所以我推荐用pip安装。还记得我们这个虚拟环境里自带了python10吗,所以这个环境里也会自带 pip。
然后,根据官网的pip安装方法:(我选的linux,cuda12.1,pip)
pip3 install torch torchvision torchaudio

云服务器网速很好,一下就安装完了。

另外,在安装过程中,我注意到pytorch自动安装了它所需要的cuda runtime toolkit = 12.1 和 cudnn =8.9.2:
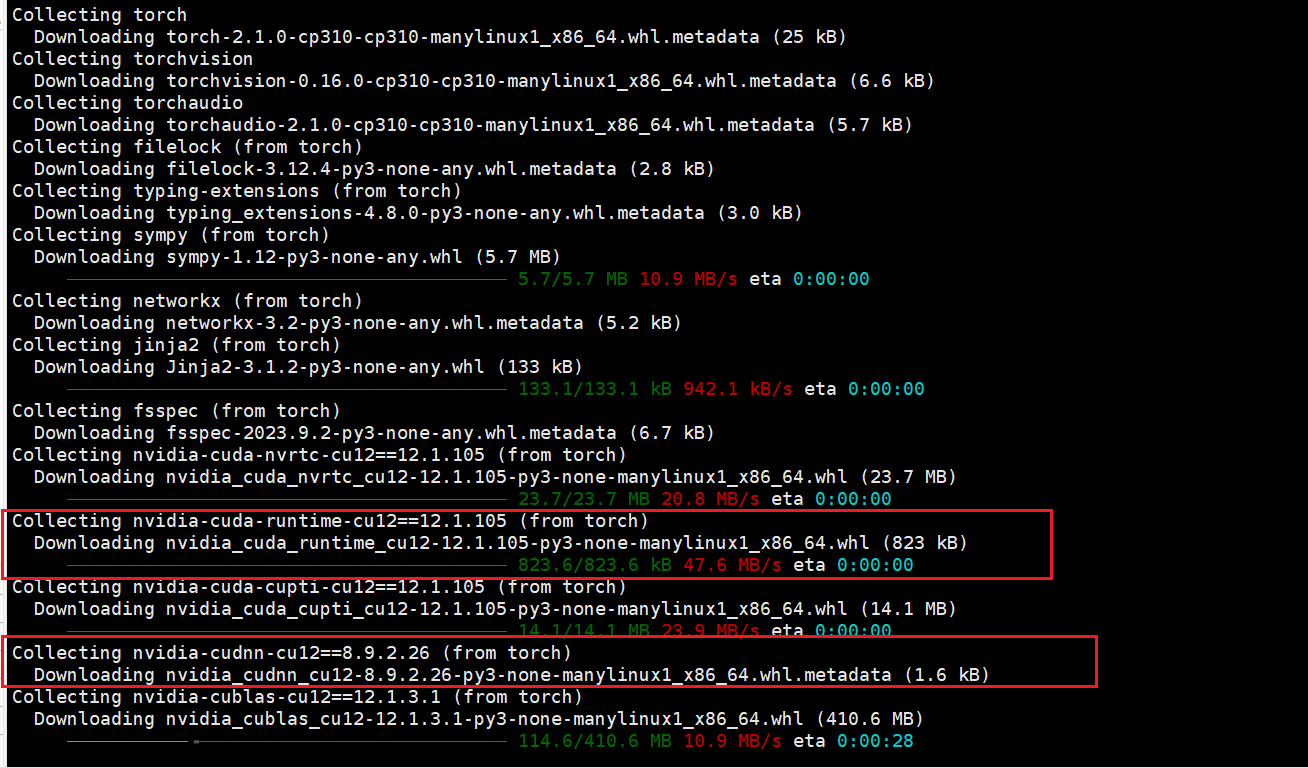
所以,我们不需要再手动安装cuda和cudnn了。
(不是不需要,是不能! 手动安装cuda和cudnn反而会让pytorch找不到它真正需要的cuda和cudnn,产生报错)
2.4. (optional) 在虚拟环境中装 jupyter
这一步可选,我个人喜欢用 jupyter notebook 写代码,所以我会装一个。
# 先确保你在你想要操作的虚拟环境中
pip install jupyter
jupyter notebook
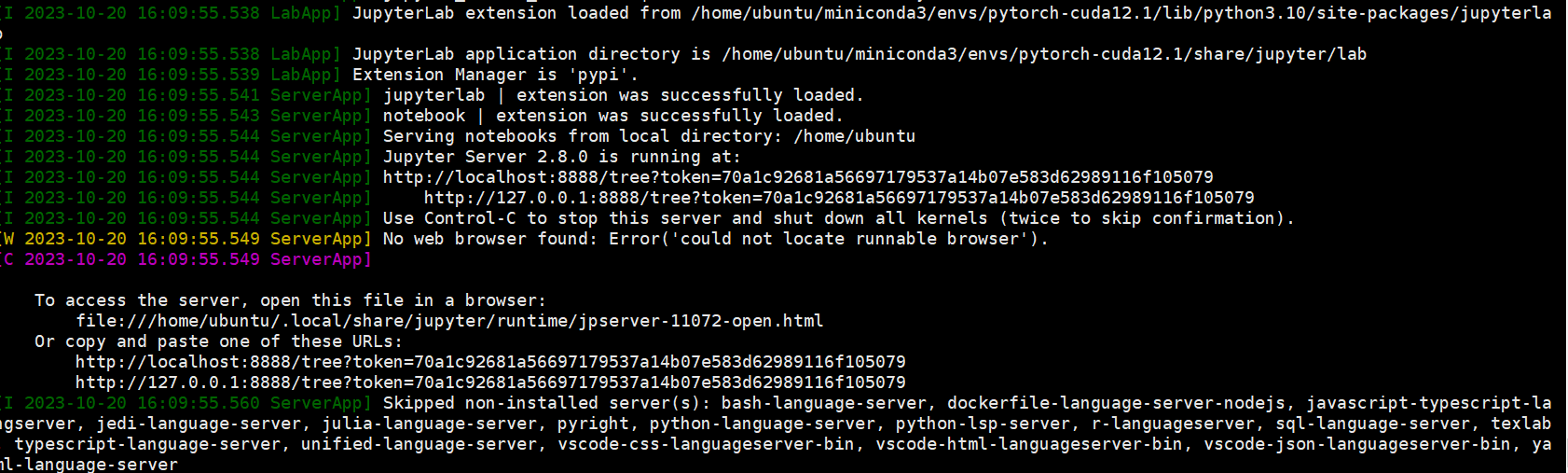
我一般是把服务器的端口远程映射到我的win小笔记上,然后再笔记本上写代码,服务器上跑代码:
在win笔记本上,打开 cmd,输入
ssh -L 8888:localhost:8888 ubuntu@117.50.197.39
# 8888是jupyte notebook的端口,看上图可以明白。
# ubuntu是我的用户名
# 117.50.197.39 是我的服务器公网ip地址(怎么看?在shell中 输入 `curl cip.cc`)
然后复制上图中的一个网址到win的浏览器中即可打开jupyter notebook。
http://localhost:8888/tree?token=70a1c92681a56697179537a14b07e583d62989116f105079
3. 用代码做验证
3.1. 基本测试:
import torch
print(torch.cuda.is_available())
print(torch.__version__)
print(torch.__path__)
print(torch.version.cuda)
torch.backends.cudnn.version()
# GPU
x = torch.randn(1, 3, 224, 224).cuda()
conv = torch.nn.Conv2d(3, 3, 3).cuda()
out = conv(x)
print(out.sum())
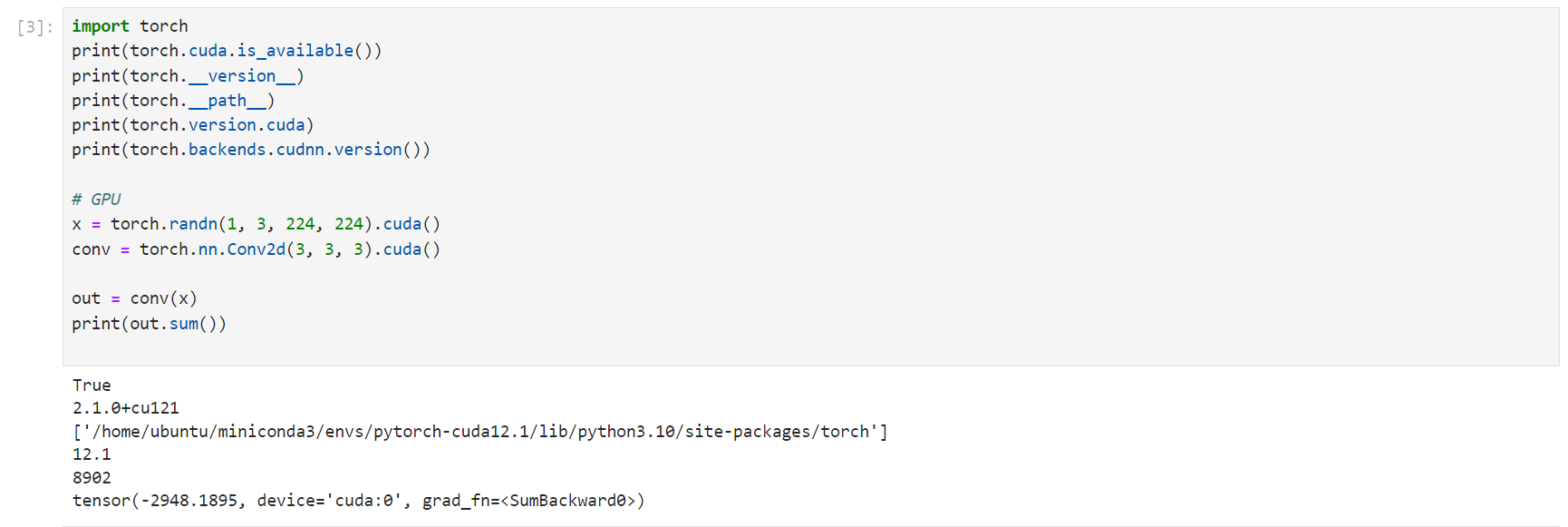
主要看
print(torch.cuda.is_available())
返回true,就说明通过基本测试。
返回false,可能的原因:
- 你没有GPU
- pytorch下载了cpu版本
- 没安装driver或者driver版本不对不兼容
3.2. 进阶测试
还记得我之前说的:
所以,我们不需要再手动安装cuda和cudnn了。
(不是不需要,是不能! 手动安装cuda和cudnn反而会让pytorch找不到它真正需要的cuda和cudnn,产生报错)
如果是手动安装的cuda和cudnn,那么也可以通过 基本测试
但是一旦涉及到调用cudnn,就会报错。
所以我copy了一位大佬搭建的一个简单的小网络的代码,来进行测试。
测试成功的话,就会正确地输出epoch:
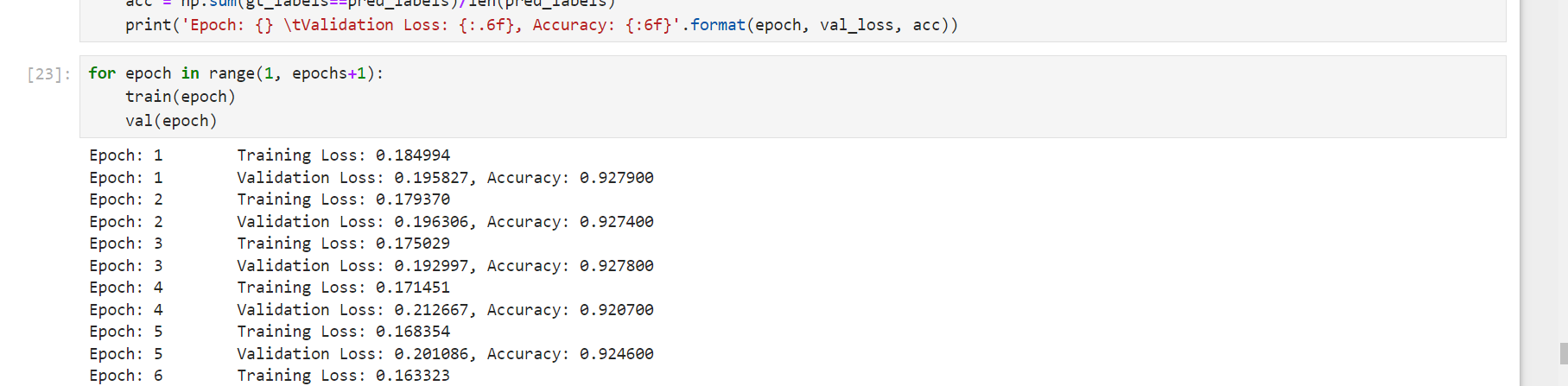
测试代码:
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 配置GPU,这里有两种方式
## 方案一:使用os.environ
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #多卡可以改成 '0,1,2,3'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
## 配置其他超参数,如batch_size, num_workers, learning rate, 以及总的epochs
batch_size = 256
num_workers = 4 # 对于Windows用户,这里应设置为0,否则会出现多线程错误
lr = 1e-4
epochs = 20
# 首先设置数据变换
from torchvision import transforms
image_size = 28
data_transform = transforms.Compose([
transforms.ToPILImage(),
# 这一步取决于后续的数据读取方式,如果使用内置数据集读取方式则不需要
transforms.Resize(image_size),
transforms.ToTensor()
])
## 读取方式一:使用torchvision自带数据集,下载可能需要一段时间
# from torchvision import datasets
# train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
# test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)
## 读取方式二:读入csv格式的数据,自行构建Dataset类
# csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
class FMDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28,28,1)
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float)
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)
print('读取完毕!')
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
数据读取成功的话会是这样:

测试代码继续:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
self.fc = nn.Sequential(
nn.Linear(64*4*4, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64*4*4)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
model = model.cuda() #单卡训练
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法,之后的课程中会进一步讲解
criterion = nn.CrossEntropyLoss()
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(test_loader.dataset)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
save_path = "./FashionModel.pkl"
torch.save(model, save_path)
4.常见问题:
**pytorch自带的cuda能用 nvcc -V 来验证吗?
不能,但可以用代码看
import torch
print(torch.version.cuda) # 看自带的cuda版本
torch.backends.cudnn.version() # 看自带的cudnn版本
搞不清楚driver,cuda,cudnn,pytorch,python的版本对应关系怎么办?
看这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号