

python_day4
文件
文件编码
思考:计算机只能识别:0和1,那么我们丰富的文本文件是如何被计算机识别,并存储在硬盘中呢?
使用编码技术(密码本)将内容翻译成0和1存入
编码技术:即记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别的内容:
例如:UTF-8,GBK这种
1.0 文件的读取
内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U盘等设备。为了便于数据的管理和检索,引入了"文件"的概念
对文件的操作:
1、打开文件
2、读写文件
3、关闭文件
打开文件
open()打开函数
open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加
encoding:编码格式(推荐使用UTF-8)
f = open("hello.txt",'r',encoding="UTF-8")
#encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
模式:
r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
w:打开一个文件只用于写入。如果该文件已存入则打开文件,并从头开始编辑。原有内容会被删除
a:打开一个文件用于追加。如果该文件已存在,新的内容将被写入到已有内容之后。如果该文件不存在,则创建文件进行写入
读操作相关的方法
read()方法:
文件对象.read(num)
#num 表示要从文件中堆区的数据的长度(单位是字节),如果没有传入num,那么表示读取文件中所有的数据
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回一个列表,且每一行数据为一个元素
f = open('python.txt')
content = f.readlines()
print(content)
#关闭文件
f.close()
一次读取一行的方法
line1 = f.readline()
line2 = f.readline()
一次读取一行
循环读取
for line in open("python.txt","r"):
print(line)
#每一个line临时变量,就记录了文件的一行数据
文件的关闭操作:
time.sleep(50000) # 让程序暂停执行
f.close()
文件的关闭
f.close()
with open("python.txt","r",encoding = "UTF-8") as f:
f.readlines()
#通过在with open 的语句块中对文件进行操作
#可以在操作完成后自动关闭close文件,避免遗忘掉close方法

要是打开文件后,没有用f.close()关闭文件,文件就会一直被占用
#查找一个文本内容某个单词出现的次数
for line in f:
line = line.strip() #去除开头和结尾的空格以及换行符
words = line.split(" ")
print(words)
写文件操作:
# 1、打开文件
f = open('python.txt','w',encodint = "UTF-8")
# 2、文件写入
f.write('hello world')
# 3、内容刷新
f.flush()
直接调用write,内容并未真正写入文件,而是会积攒到程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率低下
注意:"w":文件存在时,它会把内容清空,写我们想写的东西
追加写入快速操作
#1、打开文件,通过a模式打开即可
f = open('python.txt','a',encoding = 'UTF-8')
# 2、文件写入
f.write("hello world")
#3、内容刷新
f.flush()
用a模式时,如果不存在文件:会创建文件
如果文件已经存在,则会追加写入
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段
try:
可能发生错误的代码
except:
如果出现异常执行的代码
例如:
快速入门:
try:
f=open("linux.txt",'r')
except:
f=open("linux.txt",'w')
捕获异常;
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
print(e)
如果尝试执行的代码的异常类型和想要异常捕获的类型不一致,则无法捕获异常
- 一般try下方只放一行尝试执行的代码。
捕获多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写
try:
print(1/0)
except (NameError,ZeroDivisionError) as e:
print('ZeroDivision错误...')
print(e)
捕获全部异常
try:
except Exception as e:
异常的else
else表示的是如果没有异常要执行的代码
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,没有异常的时候执行的代码')
异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件
try:
f=open("test.py",'r')
except Exception as e:
f = open("test.txt",'w')
else:
print("无异常")
finally:
f.close()
异常的传递性:当函数1没有捕获异常,这个异常就会传递到下面的函数,直到main函数捕获这个异常,这就是异常的传递性。
当所有函数都没有捕获异常的时候,程序就会报错
模块
Python 模块(Module),是一个Python文件,以.py结尾。模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的作用:python中有很多各种不同的模块,每一个模块都可以帮助我们实现一些功能,可以人为一个模块就是一个工具包
模块就是一个python文件,里面有类、函数、变量等,我们可以拿过来用
模块的导入方式:
[from 模块名] import [模块|类|变量|函数|*] [as 别名]
常用的组合形式:
import 模块名
from 模块名 import 类、变量、方法等
from 模块名 import *
import 模块名 as 别名
from 模块名 import 功能名 as 别名
import 模块名
import 模块名
import 模块名1,模块名2
模块名.功能名()
例如:
import time
time.sleep(5) # 程序等待5ms
新建一个Python文件,命名为my_module.py,并定义test函数
然后在别的软件里面
import my_module
my_module.test(10,20) #调用其函数
不想在导入模块的时候执行那个函数调用
在my_module.py 文件里面
def test(a,b):
print(a+b)
if __name__ =='__main__' #有这句话就能在我们右键运行的时候测试我们函数,在正常文件导入这个模块时调用,又不执行我们的测试函数
test(1,2)
在my_module.py文件中执行时,if后面判断将是true
在
——all——变量
如果一个模块中有'all'变量,当使用'from xxx import *' 导入时,只能导入这个列表中的元素
# my_module.py
__all__=['test_A'] #这个里面是你能导入的函数名
def test_A():
print('testA')
def test_B():
print('testB')
from my_module import *
test
test_A()
python 包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个
__init__.py文件,该文件夹可用于包含多个模块,从逻辑上看,包的本质依然是模块
my_module1.py
my_module2.py -->__init__.py => Package包
包的作用:当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块
新建包'my_package'
新建包内模块:'my_module'和'my_module2'
模块内代码如下
[new]->[Python Package] =>输入包名=》新建功能模块
import 包名.模块名
包名.模块名.目标
import my_package.my_module1
引入了包中的模块
my_package.my_module1.info_print1()
或者可以通过这个:
from my_package import my_module
my_module.print()
更具体的导入
from my_package.my_module import print
print()
导入包
注意:必须在
__init__.py 文件中添加 __all__ = [],控制允许导入的模块列表
# 包中的__all__和模块中的__all__一样有着控制功能
from 包名 import *
模块名.目标
form my_package import *
#包中的my_module模块的info_print()方法
my_module.info_print()
# 包中的my_module模块的info_print()方法
可以直接在包里面的
package
__init__ = [],在[]中放入这个包里面的模块名
# 通过__all__变量,控制import *,控制import能导入的内容
什么是第三方包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
def print_file_info(file_name):
f = None
try:
f = open(file_name,"r",encoding="UTF-8")
content = f.read()
print("文件的全部内容如下:")
print(content)
except Exception as e:
print(f"程序出现异常了,原因是,{e}")
finally:
if f:#如果变量是None
f.close()
数据可视化
json:一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
JSON本质上是一个带有特定格式的字符串
主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互
import json
#准备符合格式json格式要求的python数据
data= [{"name":"老王","age":16},{"name":"张三","age":17}]
#通过json.dumps(data)方法把Python数据转化为了json数据
data = json.dumps(data)
#通过json.loads(data)方法把json数据转化为python数据
data = json.loads(data)
# 导入json模块
import json
#准备列表,列表中每一个元素都是字典,将其转换为JSON
data = [{"name":"张大山","age" : 11},{"name":"刘德华","age" : 20},{"name":"李大钊","age" : 30}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
#准备字典,将字典转换为JSON
d = {"name":"周杰伦","addr":"台北"}
json_str = json.dumps(d,ensure_ascii=False)
print(type(json_str))
print(json_str)
#将Json字符串转变回python数据类型
l = json.loads(json_str)
print(type(l))
print(l)
pyecharts模块
如果想要做出数据可视化效果图,可以借助pyecharts模块来完成
#导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
#得到折线图
line = Line()
#添加x轴数据
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,20,10])
#生成图标
line.render()
pyecharts配置选项
pyecharts模块中有很多的配置选项,常用到2个类别的选项:
- 全局配置选项
- 系列配置选项
#set_global_opts方法
#这里全局配置选项可以通过set_global_opts方法进行配置,相应的选项和选项的功能如下:
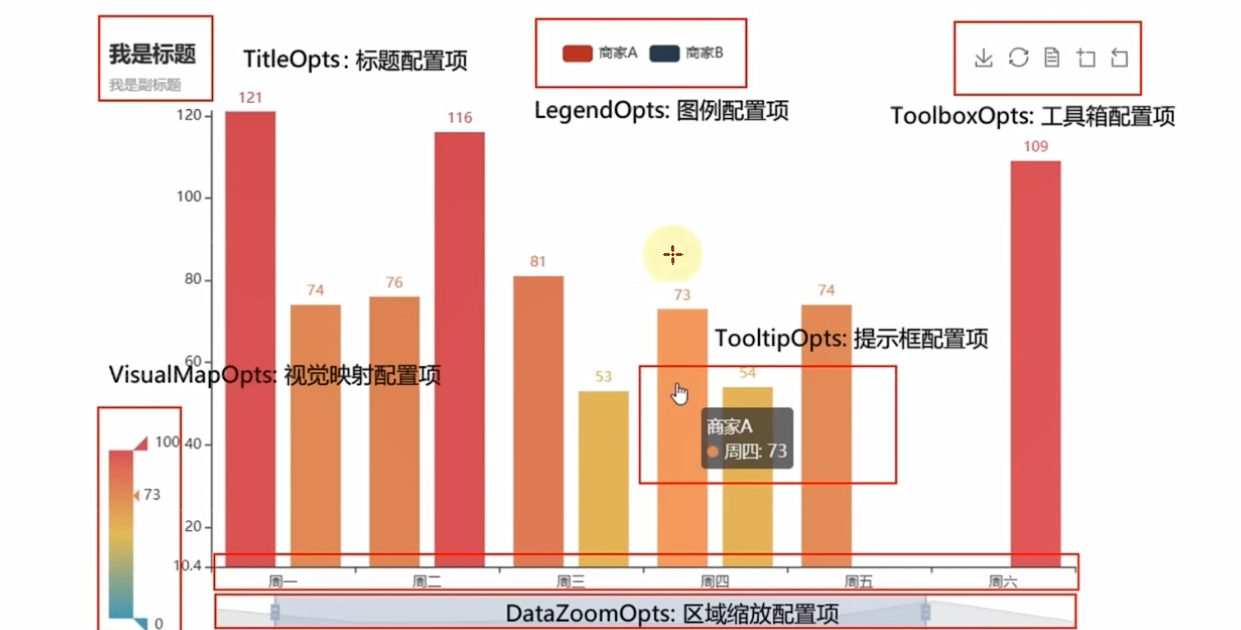
#导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts
#得到折线图
line = Line()
#添加x轴数据
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,20,10])
# 设置全局配置项set_global_opts来设置,
line.set_global_opts(
title_opts=TitleOpts(title = "GDP展示",pos_left="center",pos_bottom = "1%"),
lengend_opts = LegendOpts(is_show = True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts = VisualMapOpts(is_show = True)
)
#生成图标
line. Render()
