
为什么MySQL数据库要用B+树存储索引
A:为什么MySQL数据库要用B+树存储索引?
Hash的查找速度为O(1),而树的查找速度为O(log2n),为什么不用Hash作为数据库的存储索引呢?
树的话,无非就是前中后序遍历、二叉树、二叉搜索树、平衡二叉树,更高级一点的有红黑树、B树、B+树。
【红黑树】
红黑树也是平衡树中的一种,它复杂的定义以及繁琐的规则无非就是为了保证树的平衡性。一棵红黑树可以保证平衡性,保持平衡性的目的无非就是降低树的高度,提高搜索效率,Java中的TreeSet就是基于红黑树实现的

【B树】
B树就是多路搜索树,B树的每个节点都可以拥有多余两个孩子节点,比如一棵M路的B树最多可能拥有M个孩子节点。如下图,是一棵三路的B树,每个节点组多拥有三个孩子节点,同样是一棵搜索树。
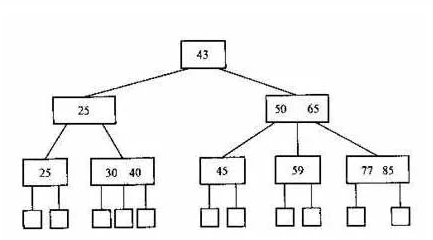
路数越多,树的高度越低,但是不能无限增加路数,那样B树会退化成有序数组。
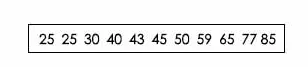
B树主要用在文件系统的索引上,为什么不用红黑树或者有序数组做文件系统的索引呢?要知道,文件系统和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中。
如果一棵树无法一次性加载到内存中的话,B树多路存储的能力就显现出来了,这时候可以每次加载树的一个节点,接着慢慢往下找。
比如下图的有序数组,如果内存每次只能加载两个数,这么长的数组是无法一次性加载到内存中的

如果把上图的有序数组转换成一棵三路的B树,这样每个节点最多能存储2个数
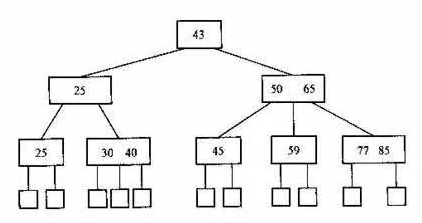
这样,查找的时候一次只需要加载一个节点进内存就可以了
B树在磁盘的操作上较红黑树更有优势,而在内存中,红黑树比B树效率更高
【B+树】
B+树是在B树的继承上进行改造,它的数据都存储在叶子节点上,同时叶子节点之间还加了指针形成链表。下图是一棵四路B+树,它的数据都存储在叶子节点上,并且有链表相连
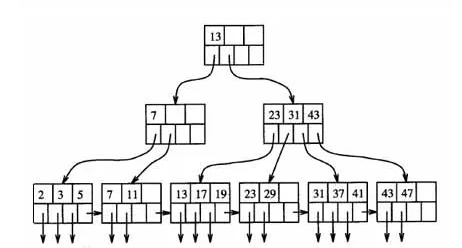
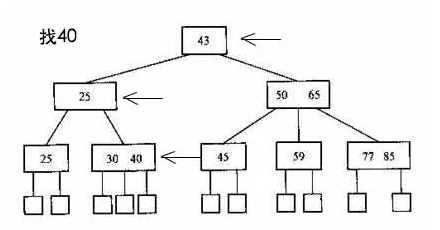
B+树的使用场景在数据库的索引上使用的比较多,这个也是跟业务系统有关的,使用数据库进行数据查找的时候,一般select查找的数据不止一条,有时候会有很多条检索结果,比如按照id排序后选10条。如果是多条的话,B树需要做局部的中序遍历,可能要跨层访问。而B+树由于所有数据都在叶子结点,不用跨层,同时由于有链表结构,只需要找到首尾,通过链表就能把所有数据取出来了。比如选出7和19,只需要在叶子节点中就能找到
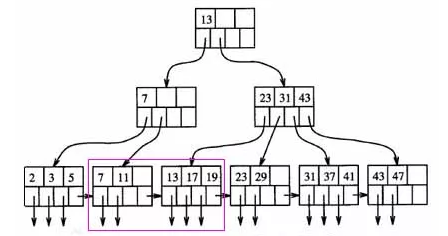
回到问题,为什么MySQL数据库要用B+树存储索引?
这和业务场景有关。如果只选一个数据,那确实是Hash更快。但是数据库中经常会选择多条,这时候由于B+树索引有序,并且又有链表相连,它的查询效率比Hash就快很多了。而且数据库中的索引一般是在磁盘上,数据量大的情况可能无法一次装入内存,B+树的设计可以允许数据分批加载,同时树的高度较低,提高查找效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号