聊聊关于mysql 主从 同步 问题
总结:稍微有些规模的网站,基本上都会配置mysql主从复制,一方面用mysql的主从做数据库的读写分离,另一方面mysql本身的单机备份不是很强,一般采用主从架构,在从上进行数据备份。
在MySQL主从复制过程中或多或少出现一些主从不同步的情况,本文将对数据主从不同步的情况进行简单的总结,请注意本文主要从数据库层面上探讨数据库的主从不一致的情况。






1.网络的延迟
由于mysql主从复制是基于binlog的一种异步复制,通过网络传送binlog文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计。
2.主从两台机器的负载不一致
由于mysql主从复制是主数据库上面启动1个io线程,而从上面启动1个sql线程和1个io线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况。
3.max_allowed_packet设置不一致
主数据库上面设置的max_allowed_packet比从数据库大,当一个大的sql语句,能在主数据库上面执行完毕,从数据库上面设置过小,无法执行,导致的主从不一致。
4.key自增键开始的键值跟自增步长设置不一致引起的主从不一致。
5.mysql异常宕机情况下,如果未设置sync_binlog=1或者innodb_flush_log_at_trx_commit=1很有可能出现binlog或者relaylog文件出现损坏,导致主从不一致。
6.mysql本身的bug引起的主从不同步。
7.版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面不支持该功能。
以上就是常见的一些主从不同步的情况。或许还有其他的一些不同步的情况,请说出你所遇到的主从不一致的情况。
基于以上情况,先保证max_allowed_packet、自增键开始点和增长点设置一致,再者牺牲部分性能在主上面开启sync_binlog,对于采用innodb的库,推荐配置下面的内容
1、innodb_flush_logs_at_trx_commit = 1
2、innodb-support_xa = 1 # Mysql 5.0 以上
3、innodb_safe_binlog # Mysql 4.0
同时在从数据库上面推荐加入下面两个参数
1、skip_slave_start
2、read_only
今天继续讨论,MySQL主从复制什么原因会造成不一致,如何预防及解决?
1.人为原因导致从库与主库数据不一致(从库写入)
2.主从复制过程中,主库异常宕机
3.设置了ignore/do/rewrite等replication等规则
4.binlog非row格式
5.异步复制本身不保证,半同步存在提交读的问题,增强半同步起来比较完美。 但对于异常重启(Replication Crash Safe),从库写数据(GTID)的防范,还需要策略来保证。
6.从库中断很久,binlog应用不连续,监控并及时修复主从
7.从库启用了诸如存储过程,从库禁用存储过程等
8.数据库大小版本/分支版本导致数据不一致?,主从版本统一
9.备份的时候没有指定参数 例如mysqldump --master-data=2 等
10.主从sql_mode 不一致
11.一主二从环境,二从的server id一致。
12.MySQL自增列 主从不一致
13.主从信息保存在文件里面,文件本身的刷新是非事务的,导致从库重启后开始执行点大于实际执行点
预防措施:
1.master:innodb_flush_log_at_trx_commit=1&sync_binlog=1
2.slave:master_info_repository="TABLE"&relay_log_info_repository="TABLE"&relay_log_recovery=1
3.设置从库库为只读模式
4.可以使用5.7增强半同步避免数据丢失等
5.binlog row格式
6.必须引定期的数据校验机制
7.mysql 版本一致
如何每次都能 读到最新的数据:(一般大多数业务都是可以容忍 短暂数据 不一致问题)
1.部分接口 强制走 主库
2.每次修改 写缓存 隔几秒 就过期
3.开启 半同步机制
4.pxc
PXC-mysql运维手册
PXC-mysql,全名Percona XtraDB Cluster,是一种强大的MySQL开源集群方案。

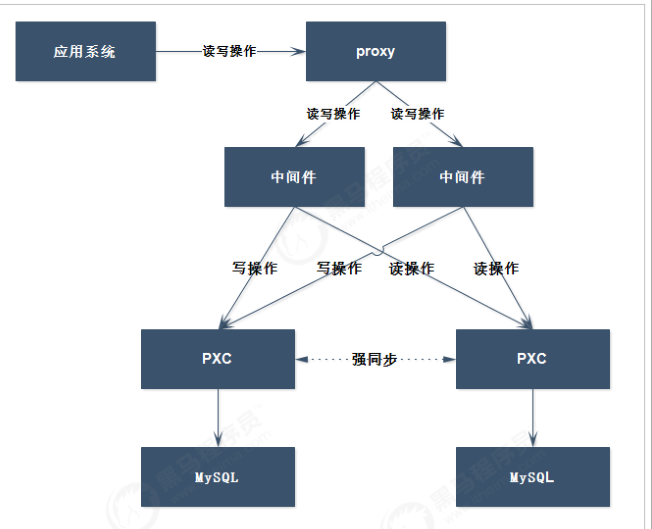
1. 特点
-
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的。
-
同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失。
-
并发复制:从节点在APPLY数据时,支持并行执行,有更好的性能表现。
-
故障切换:在出现数据库故障时,因为支持多点写入,切的非常容易。
-
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小。
-
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,PXC会自动拉取在线节点数据,最终集群会变为一致。
以上几点,足以说明PXC是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案。
2. 缺点
-
配置新节点的开销。添加新节点时,必须从现有节点中的一个复制完整数据集。如果是100GB,则复制100GB。
-
这不能用作有效的写入缩放解决方案。当您将写入流量运行到2个节点,而将所有流量运行到1个节点时,写入吞吐量可能会有所改善,但您不能期望太多。所有写入仍然必须在所有节点上进行。
-
重复的数据,3个节点就会有3个重复的数据。
参考链接:
https://blog.csdn.net/hardworking0323/article/details/81046408
https://www.jianshu.com/p/3bfb0bfb8b34
https://mp.weixin.qq.com/s?src=11×tamp=1566467774&ver=1806&signature=ERFDjZkBC3qO5*mPXNyybcs41xF*RRiAL*2-NCtpYxwNVdUbJ8HFikBVbbHXGkCIfZtWk7-T7pWHFHUFgtmCHJTcy33eeKA5Q-YxIyGr0sNNq7CtziDMxaMUVkuLRTsg&new=1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号