《Java I/O 从0到1》 - 第Ⅱ滴血 “流”
前言
《Java I/O 从0到1》系列上一章节,介绍了File 类,这一章节介绍的是IO的核心 输入输出。I/O类库常使用流这个抽象概念。代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象。
流 屏蔽了实际的I/0设备中处理数据的细节。Java类库中的I/O类库分为输入输出两部分。InputStram或Reader 派生而来的类都含有 read() 基本方法,用于 读 取单个字节或者字节数组。同样,任何自OutputStream或Writer 派生而来的类都含有名为write()基本方法,用于 写 单个字节或者字节数组。但是,我们通常不会用到这些方法,他们之所以存在是因为别的类可以使用它们,以便提供更有用的接口。因此,很少使用单一的类来创建流对象,而是通过叠合多个对象来提供所期望的功能。摘自《Java 编程思想第四版》
下面呢,提供一个整理的IO思维导图(查看图片,点击图片右键 选择 新标签页中打开):
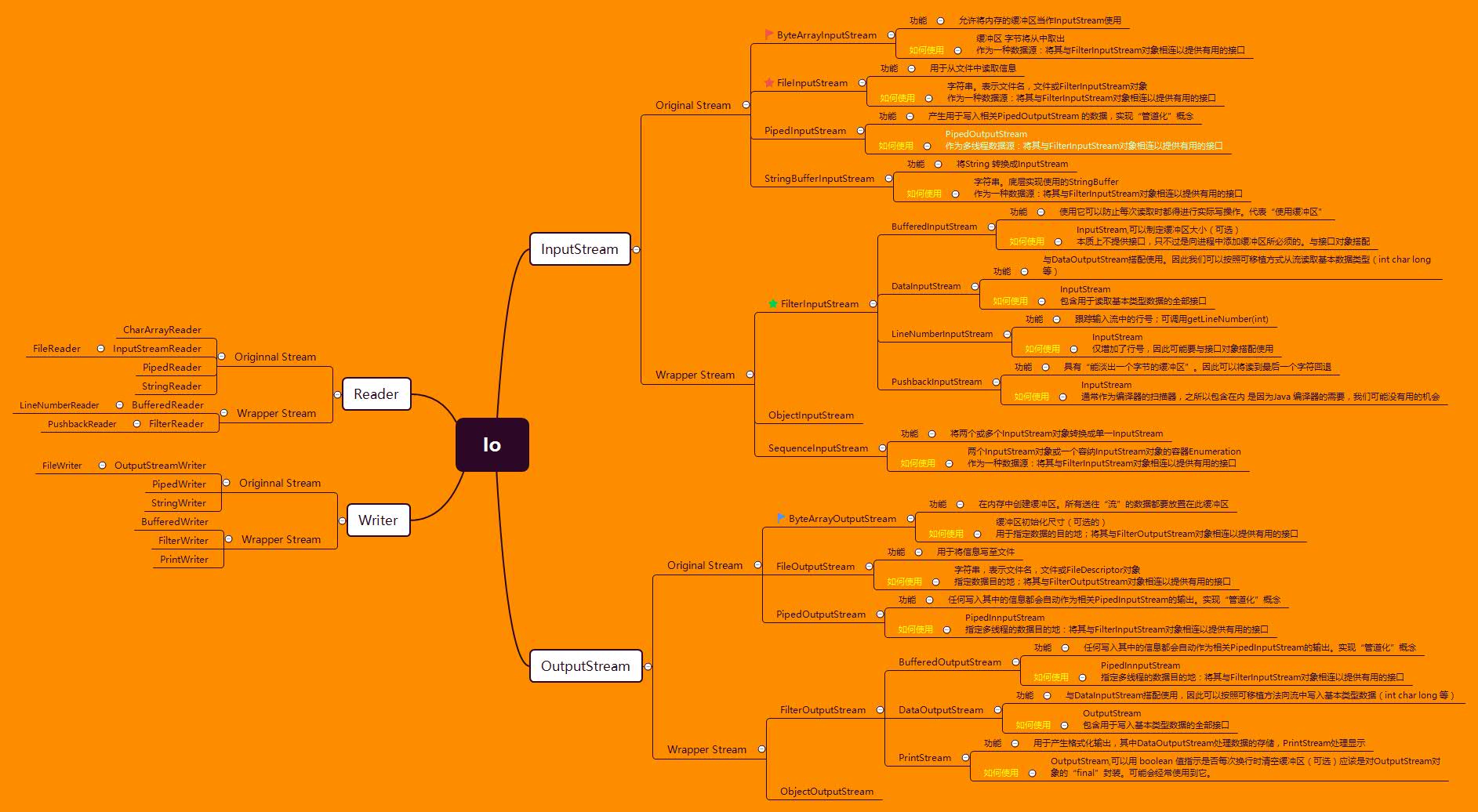
Xmind下载链接:http://pan.baidu.com/s/1gfrLcf5
InputStream:用来表示从不同数据源产生输入的类。数据源包括:字节数组,String对象,文件,“管道”等 。引用《Java 编程思想第四版》中图片。
OutputStream:决定了输出所要去往的目标。
字节流
字节流对应的类是InputStream和OutputStream,而在实际开发过程中,需要根据不同的类型选用相应的子类来处理。
a. 先根据需求进行判定,读 则使用 InputStream 类型; 写 则使用 OutputStream 类型
b. 在判定媒介对象什么类型,然后使用对应的实现类。 eg: 媒介对象是 文件 则使用FileInputStream FileOutputStream 进行操作。
方法
1. int read(byte[] b) 从此输入流中读取一个数据字节。
2. int read(byte[] b, int off, int len) 从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
3. void write(byte[] b) 将 b.length 个字节写入此输出流。
4. void write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。


1 /** 2 * 3 * Title: writeByteToFile 4 * Description: 字节流写文件 5 * @author yacong_liu Email:2682505646@qq.com 6 * @date 2017年9月20日下午5:34:41 7 */ 8 private static void writeByteToFile() { 9 String str = new String("Hello Everyone!,My name is IO"); 10 byte[] bytes = str.getBytes(); 11 File file = new File("D:" + File.separator + "tmp" + File.separator + "hello.txt"); 12 OutputStream os = null; 13 try { 14 os = new FileOutputStream(file); 15 os.write(bytes); 16 System.out.println("write success"); 17 } catch (FileNotFoundException e) { 18 e.printStackTrace(); 19 } catch (IOException e) { 20 e.printStackTrace(); 21 } finally { 22 try { 23 os.close(); 24 } catch (IOException e) { 25 e.printStackTrace(); 26 } 27 } 28 }
1 /** 2 * 3 * Title: readByByteFromFile Description: 字节流读文件 4 * 5 * @author yacong_liu Email:2682505646@qq.com 6 * @date 2017年9月20日下午5:47:35 7 */ 8 public static void readByByteFromFile() { 9 File file = new File("D:" + File.separator + "tmp" + File.separator + "hello.txt"); 10 byte[] byteArr = new byte[(int) file.length()]; 11 try { 12 InputStream is = new FileInputStream(file); 13 is.read(byteArr); 14 15 System.out.println(new String(byteArr) + "\n"); 16 17 is.close(); 18 } catch (FileNotFoundException e) { 19 e.printStackTrace(); 20 } catch (IOException e) { 21 e.printStackTrace(); 22 } 23 24 /** 25 * Console: 26 * Hello Everyone!,My name is IO 27 */ 28 }
字符流
字符流对应的类似 Reader 和 Writer。
1 public static void writeCharToFile() { 2 String str = new String("Hello Everyone!,My name is IOs"); 3 File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java"); 4 try { 5 Writer os = new FileWriter(file); 6 7 os.write(str); 8 9 os.close(); 10 } catch (IOException e) { 11 e.printStackTrace(); 12 } 13 }
1 public static void readCharFromFile() { 2 File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java"); 3 try { 4 Reader reader = new FileReader(file); 5 char[] byteArr = new char[(int) file.length()]; 6 reader.read(byteArr); 7 8 System.out.println("文件内容: " + new String(byteArr)); 9 reader.close(); 10 } catch (FileNotFoundException e) { 11 e.printStackTrace(); 12 } catch (IOException e) { 13 e.printStackTrace(); 14 } 15 16 /** 17 * Console: 18 * 文件内容: Hello Everyone!,My name is IOs 19 */ 20 }
字节字符流组合
IO流之间可以组合,但不是所有的流都能组合。组合(或者称为嵌套)的好处就是把多种类型的特性融合到一起以实现更多的功能。
1 public static void composeByteAndChar() { 2 File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java"); 3 InputStream is; 4 5 try { 6 is = new FileInputStream(file); 7 Reader reader = new InputStreamReader(is); 8 char[] byteArr = new char[(int) file.length()]; 9 reader.read(byteArr); 10 11 System.out.println("文件内容: " + new String(byteArr)); 12 13 is.close(); 14 reader.close(); 15 } catch (Exception e) { 16 e.printStackTrace(); 17 } 18 }
缓冲流
缓冲就是对流进行读写操作时提供一个缓冲管道buffer来提高IO效率。(且由我说成为管道吧,其实原理都一样的嘛,前面是小管道,后面套一个大管道,然后就可以大批量的往后输送了嘛)。
原始的字节流对数据的读取都是一个字节一个字节的操作,而Buffer缓冲流在内部提供了一个buffer,读取数据时可以一次读取一大块数据到buffer中,效率要提高很多。对于磁盘IO以及大量数据来讲,使用缓冲最合适不过。
使用方面,其实很简单,只要在字节流的外面组合一层缓冲流即可。
1 public static void readBufferFromByte(){ 2 File file = new File("D:" + File.separator + "tmp" + File.separator + "helloChar.java"); 3 byte[] byteArr = new byte[(int) file.length()]; 4 try { 5 // 制定缓冲流 buffer 大小 6 InputStream is = new BufferedInputStream(new FileInputStream(file),2*1024); 7 8 is.read(byteArr); 9 10 System.out.println("文件内容: " + new String(byteArr)); 11 12 is.close(); 13 14 } catch (FileNotFoundException e) { 15 e.printStackTrace(); 16 } catch (IOException e) { 17 e.printStackTrace(); 18 } 19 }
上面的示例中,我们制定了buffer 的大小,那么这个大小范围如何确定呢?这可不是瞎编的哦。buffer的大小应该是硬件状况来确定。对于磁盘IO来说,如果硬盘每次读取4KB大小的文件块,那么我们最好设置成这个大小的整数倍。因为磁盘对于顺序读的效率是特别高的,所以如果buffer再设置的大写可能会带来更好的效率,比如设置成4*4KB或8*4KB。
还需要注意的就是磁盘本身就会有缓存,在这种情况下,BufferedInputStream会一次读取磁盘缓存大小的数据,而不是分多次的去读。所以要想得到一个最优的buffer值,我们必须得知道磁盘每次读的块大小和其缓存大小,然后根据多次试验的结果来得到最佳的buffer大小。(引用自Heaven-Wang 博客 java io 概述)。
那么,至此呢,本章节 “流”的内容就已经基本介绍完毕了,更多的内容还是需要常查看API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号