RISCV-V-1.0向量扩展指令集学习
大部分内容翻译自 riscv-v-spec-1.0
部分参考:
【《RISC-V “V“ Vector Extension Version 1.0》阅读笔记】_LPL之芯的博客-CSDN博客
RISC-V "V"(向量)扩展规范v0.9+文档(2) - 知乎 (zhihu.com)
- 3. Vector Extension Programmer's Model
- 3.4 Vector type register, vtype
- 3.5 Vector Length Register, vl
- 3.6 Vector Byte Length, vlenb
- 3.7 Vector Start Index CSR, vstart
- 3.8. Vector Fixed-Point Rounding Mode Register , vxrm
- 3.9. Vector Fixed-Point Saturation Flag, vxsat
- 3.10. Vector Control and Status Register, vcsr
- 3.11. State of Vector Extension at Reset
- 4. Mapping of Vector Elements to Vector Register State
- 5. Vector Instruction Formats
- 6. Conguration-Setting Instructions (vsetvli/vsetivli/vsetvl)
- 7. Vector Loads and Stores
- 7.1. Vector Load/Store Instruction Encoding
- 7.2. Vector Load/Store Addressing Modes
- 7.3. Vector Load/Store Width Encoding
- 7.4. Vector Unit-Stride Instructions
- 7.5. Vector Strided Instructions
- 7.6. Vector Indexed Instructions
- 7.7. Unit-stride Fault-Only-First Loads
- 7.8. Vector Load/Store Segment Instructions
- 7.9. Vector Load/Store Whole Register Instructions
- 3. Vector Extension Programmer's Model
- 8. Vector Memory Alignment Constraints
- 9. Vector Memory Consistency Model
- 10. Vector Arithmetic Instruction Formats
- 11. Vector Integer Arithmetic Instructions
- 11.1. Vector Single-Width Integer Add and Subtract
- 11.2. Vector Widening Integer Add/Subtract
- 11.3. Vector Integer Extension
- 11.4. Vector Integer Add-with-Carry / Subtract-with-Borrow Instructions
- 11.5. Vector Bitwise Logical Instructions
- 11.6. Vector Single-Width Shift Instructions
- 11.7. Vector Narrowing Integer Right Shift Instructions
- 11.8. Vector Integer Compare Instructions
- 11.9. Vector Integer Min/Max Instructions
- 11.10. Vector Single-Width Integer Multiply Instructions
- 11.11. Vector Integer Divide Instructions
- 11.12. Vector Widening Integer Multiply Instructions
- 11.13. Vector Single-Width Integer Multiply-Add Instructions
- 11.14. Vector Widening Integer Multiply-Add Instructions
- 11.15. Vector Integer Merge Instructions
- 11.16. Vector Integer Move Instructions
- 12. Vector Fixed-Point Arithmetic Instructions
- 13. Vector Floating-Point Instructions
- 13.1. Vector Floating-Point Exception Flags
- 13.2. Vector Single-Width Floating-Point Add/Subtract Instructions
- 13.3. Vector Widening Floating-Point Add/Subtract Instructions
- 13.4. Vector Single-Width Floating-Point Multiply/Divide Instructions
- 13.5. Vector Widening Floating-Point Multiply
- 13.6. Vector Single-Width Floating-Point Fused Multiply-Add Instructions
- 13.7. Vector Widening Floating-Point Fused Multiply-Add Instructions
- 13.8. Vector Floating-Point Square-Root Instruction
- 13.9. Vector Floating-Point Reciprocal Square-Root Estimate Instruction
- 13.10. Vector Floating-Point Reciprocal Estimate Instruction
- 13.11. Vector Floating-Point MIN/MAX Instructions
- 13.12. Vector Floating-Point Sign-Injection Instructions
- 13.13. Vector Floating-Point Compare Instructions
- 13.14. Vector Floating-Point Classify Instruction
- 13.15. Vector Floating-Point Merge Instruction
- 13.16. Vector Floating-Point Move Instruction
- 13.17. Single-Width Floating-Point/Integer Type-Convert Instructions
- 13.18. Widening Floating-Point/Integer Type-Convert Instructions
- 13.19. Narrowing Floating-Point/Integer Type-Convert Instructions
- 14. Vector Reduction Operations
- 15. Vector Mask Instructions
- 15.1. Vector Mask-Register Logical Instructions
- 15.2. Vector count population in mask vcpop.m
- 15.3. vfirst find-first-set mask bit
- 15.4. vmsbf.m set-before-first mask bit
- 15.5. vmsif.m set-including-first mask bit
- 15.6. vmsof.m set-only-first mask bit
- 15.7. Example using vector mask instructions
- 15.8. Vector Iota Instruction
- 15.9. Vector Element Index Instruction
- 16. Vector Permutation Instructions
- 17. Exception Handling
- 18. Standard Vector Extensions
- 19. Vector Instruction Listing
- 完结,撒花~
3. Vector Extension Programmer's Model
- VLEN: 向量bit数, ELEN: 最大支持的元素bit数
- 增加了32个vector regs, 7个非特权CSRs :
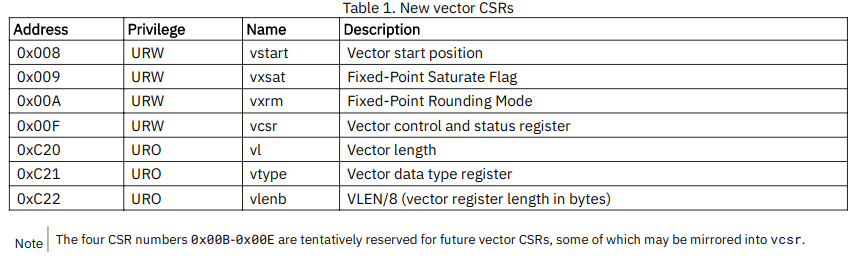
3.4 Vector type register, vtype
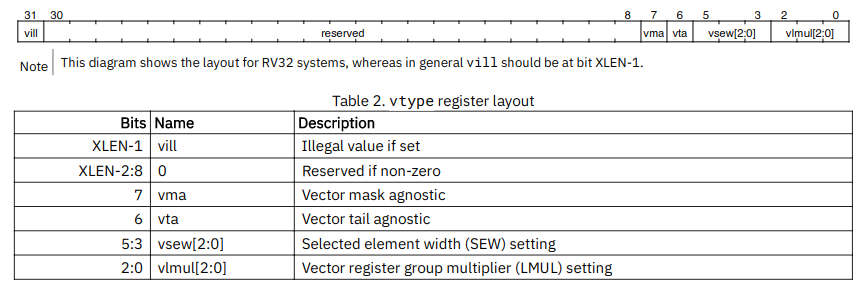
- vtype的初衷是为了使vector扩展指令集能适配32位编码空间
- 在执行一条vector指令之前,可以分别使用vset{i} vl{i}来设置vtype的field和vector length
3.4.1 Vector selected element width vsew[2:0]
-
这个field用来动态设置selected element width(SEW). 默认情况下,一个vector寄存器被分成VLEN/SEW 个元素.
-
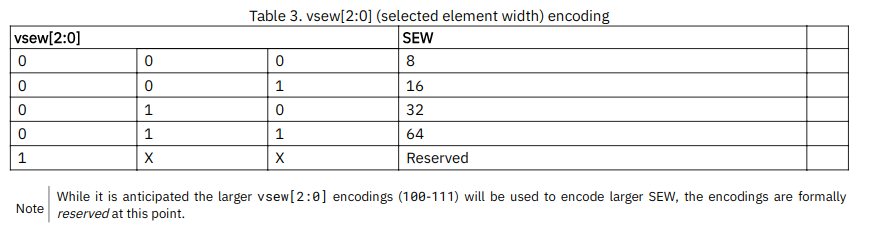
-

-
SEW越大, 一个v寄存器中的元素个数越少
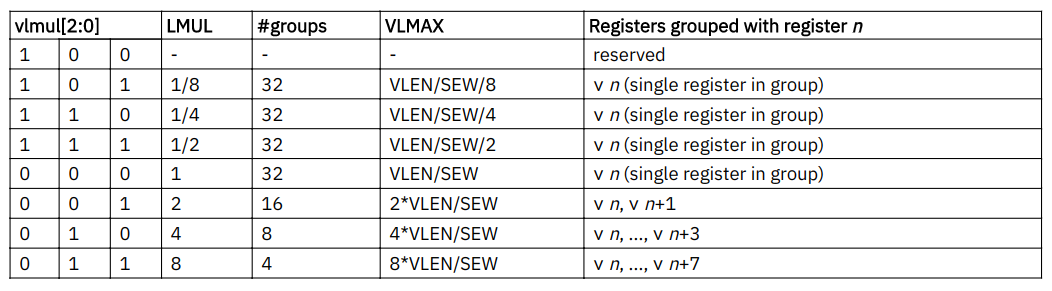
3.4.2 Vector Register Grouping (vlmul[2:0])
- 多个Vector寄存器可以被组成一个group。比如通用向量寄存器一共32个,设置LMUL为8,就可以将全部的通用寄存器分成4组,每组包含了8个连续的向量寄存器,这种分组的方式增加了向量寄存器组中元素的个数
- LMUL默认是1, 具体实现时必须支持LMUL=1,2,4,8
- vlmul是一个有符号数, \(LMUL = 2^{vlmul[2:0]}\)
- SEW和lmul配置错误时会置位vtype中的vill bit
- LMUL也可以是小数, 当存在混合长度的向量时, 小数LMUL可以增加vector寄存器的利用率. 具体来说当LMUL是小数时, 表示向量指令只操作一个向量的一部分. 例如VLEN=128, SEW=8, VLMAX表示一条向量指令所能操作的向量最大个数. 如果LMUL=1/8, 表示1/8个向量为一组, 则此时VLMAX=128/8/8 = 2, 也就是一条向量指令最多能操作一条向量的2个元素.
- LMUL为小数值时, 不是任意小数都能支持的, 最小支持\(SEW_{min}/ELEN\). 其中ELEN是最大支持的向量bit数, 需要保证LMUL乘上一个向量最大的元素个数大于等于1.
- 下表给出了不同LMUL对应的group个数, VLMAX以及所用到的vector寄存器个数:
VLEN=SLEN=128b
Byte F E D C B A 9 8 7 6 5 4 3 2 1 0
SEW=8b F E D C B A 9 8 7 6 5 4 3 2 1 0
SEW=16b 7 6 5 4 3 2 1 0
SEW=32b 3 2 1 0
SEW=64b 1 0
SEW=128b 0
Example, VLEN=SLEN=128b, LMUL=1/4
Byte F E D C B A 9 8 7 6 5 4 3 2 1 0
SEW=8b - - - - - - - - - - - - 3 2 1 0
SEW=16b - - - - - - 1 0
SEW=32b - - - 0
VLEN=SLEN=128b, SEW=32b, LMUL=4
Byte F E D C B A 9 8 7 6 5 4 3 2 1 0
v4*n 3 2 1 0
v4*n+1 7 6 5 4
v4*n+2 B A 9 8
v4*n+3 F E D C
3.4.3 Vector Tail Agnostic and Vector Mask Agnostic vta and vma
- 首先来看一下定义:
-
向量指令执行期间操作的元素索引可以分为四个不相交的子集。
- 预启动元素(The prestart elements): 是指索引小于
vstart寄存器初始值的元素。预启动元素不会引发异常,也不会更新目标向量寄存器。 - 活跃元素(The active elements): 指的是向量指令执行期间,在当前向量长度范围内的元素,并且在该元素位置启用了当前掩码。活动元素可以引发异常并更新目标向量寄存器组。
- 非活跃元素(The inactive elements): 指的是向量指令执行期间,在当前向量长度范围内的元素,但是在该元素位置禁用了当前掩码。 除非指定了masked agnostic(
vtype.vma = 1),否则非活跃元素不会引发异常,也不会更新任何目标向量寄存器组,在vtype.vma = 1这种情况下,非活跃元素可能会被1覆盖。 - 尾部元素(The tail elements): 是超出当前向量长度设置的元素。 尾部元素不会引发异常,并且只在指定了tail agnostic尾部不可知性(vtype.vta = 1)的情况下,才会更新目标向量寄存器组,在这种情况下,尾部元素可能会被1覆盖。 当LMUL <1时,尾部包含VLMAX之后的元素,这些元素保存在同一向量寄存器中。
- 主体部分(body): 用于表示活跃元素或非活跃元素的集合,即在预启动元素之后但在尾部元素之前。
- 预启动元素(The prestart elements): 是指索引小于
-
for element index x
prestart = (0 <= x < vstart)
mask(x) = unmasked || v0[x].LSB == 1
active(x) = (vstart <= x < vl) && mask(x)
inactive(x) = (vstart <= x < vl) && !mask(x)
body(x) = active(x) || inactive(x)
tail(x) = (vl <= x < max(VLMAX,VLEN/SEW))
下表给出了vta和vma的配置对应的处理方式:

-
对尾部元素的mask行为将被视为tail-agnostic, 无论vta如何配置.
-
当指定了agnostic时,对应的向量元素可以保持之前的值, 也可以被重写为全1. 并且对于同样的输入, 是保持undisturbed还是覆写为1,可以是不确定的.
-
agnostic策略实际上是为了兼容带有向量寄存器重命名的机器设计的. 如果只有undisturbed策略, 那么在寄存器重命名的时候就需要将旧的物理目的寄存器的内容复制到新的物理目的寄存器. 而设置为agnostic之后就可以忽略掉这部分无效的内容.
-
对于超标量的流水线,会采用寄存器重命名的方式,来避免WAW以及WAR这两类hazard。那程序的逻辑寄存器会映射到物理寄存器,映射后的对应关系会更新到重命名映射表中。那对于undisturbed策略,需要目的寄存器相应的元素保持原来的值。那么在用新的物理寄存器重命名时,还需要根据重命名映射表,查到原有的映射关系,再把这部分元素的值先读出来,写到重命名后的对应元素位置。这种方式对于压根儿不关心尾部元素集合或者被屏蔽元素集合的值的后续操作,就既降低了性能,又增加了不必要的功耗。
-
对于普通的in-order流水线,可以采用这种undisturbed的策略。对于超标量的流水线,使用agnostic策略就显得更加明智。
-
实际使用:
ta # Tail agnostic
tu # Tail undisturbed
ma # Mask agnostic
mu # Mask undisturbed
vsetvli t0, a0, e32, m4, ta, ma # Tail agnostic, mask agnostic
vsetvli t0, a0, e32, m4, tu, ma # Tail undisturbed, mask agnostic
vsetvli t0, a0, e32, m4, ta, mu # Tail agnostic, mask undisturbed
vsetvli t0, a0, e32, m4, tu, mu # Tail undisturbed, mask undisturbed
3.4.4. Vector Type Illegal vill
- 标志之前的一次vsetvli指令下发了一次不支持的值
- 当尝试执行一条vill位=1的指令时, 将会抛出非法指令异常
- vill=1时, vtype的其他部分需要被置为0
3.5 Vector Length Register, vl
- 只能通过vset{i}vl{i}指令赋值
- 定义了需一条向量指令更新的向量元素个数
3.6 Vector Byte Length, vlenb
- vlenb = VLEN/8
- 该寄存器是给一些需要将VLEN以byte计数的场景,否则还需要手动计算byte数
3.7 Vector Start Index CSR, vstart
- 定义了一条向量指令执行时的第一个元素在向量中的索引号
- 一条向量指令结束时会将vstart归零
- vstart之前的向量值将保持undisturbed
- 如果一条向量指令引发了非法异常,则不会修改vstart
- vstart可以被非特权等级的代码修改, 但是非0的vstart可能使得向量指令运行变慢,所以不应该被应用程序修改
3.8. Vector Fixed-Point Rounding Mode Register , vxrm
- vxrm[1:0]为可读可写寄存器,该寄存器不仅有独立的寄存器地址,并且在vcsr寄存器中也有对应的域。该寄存器控制定点舍入模式,一共四种模式,分别是round-to-nearest-up(rnu)、round-to-nearest-even(rne)、round-down(rdn)、round-to-odd(rod)。(问题:可否解释一下定点数在内存中的存放格式)
- vxrm[1:0]寄存器通过单条csrwi指令写入值。
- 假如源操作数是v,有低d bit数据要被截掉,那么做完rounding-mode之后的最终结果应该是(v>>d)+r,r就是根据不同的rounding mode得到的增量值。
rnu:向距离近的方向进行舍入,当距离与两边都相等时,向上舍入。
rne:向距离近的方向进行舍入,当距离与两边都相等时,向偶数方向舍入。
rdn:向下舍入,直接取移位后的值。
rod:舍入到奇数值方向。
其中,v[d-1]表示权重位。当v[d-1]=0,表示距离舍的方向更近;当v[d-1]=1且v[d-2:0]=0时,距离舍入两个方向距离均相等;当v[d-1]=1,且v[d-2:0] != 0时,表示距离入的方向更近。

3.9. Vector Fixed-Point Saturation Flag, vxsat
- vxsat为可读可写寄存器,该寄存器不仅有独立的寄存器地址,并且在vcsr寄存器中也有对应的域。该寄存器有效表示输出结果做了饱和截位以适应目的寄存器格式。比如当运算发生正溢出时,保留结果为能取到的最大正值;当运算发生负溢出时,保留结果为负数最小值。
3.10. Vector Control and Status Register, vcsr
- 实际上包含了vxrm和vxsat两个寄存器

3.11. State of Vector Extension at Reset
- 推荐的做法是在reset时, vtype.vill=1, 其余位为0, 且vl=0
- 大部分向量单元需要一个初始的vset{i}vl{i}, 来复位vstart. vxrm和vxsat也需要在使用前复位
4. Mapping of Vector Elements to Vector Register State
4.4. Mapping across Mixed-Width Operations
-
向量指令集可以支持元素混合位宽的操作。
-
通过动态修改vtype,应用程序可以操作多个精度不同的向量并且保持SEW/LMUL不变:
-
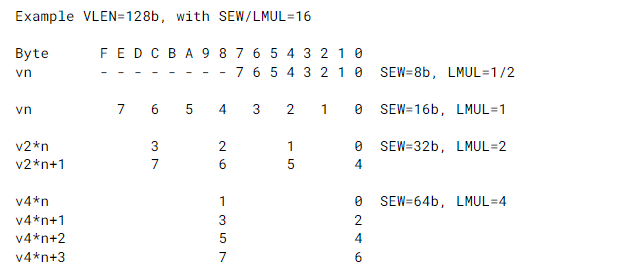
-
下表给出了一组关系:
-

-
如果要保持元素个数不变,只需要选定上面表格的一列,让LMUL随着SEW的变大成倍变大即可。
4.5. Mask Register Layout
- 向量的mask包括了整个vector reg,不管SEW和LMUL设置的是什么
- mask为每个element分配一个bit
5. Vector Instruction Formats
-
向量指令格式会单独扩展一个格式:OP-V
-
向量的load和store指令沿用LOAD-FP和STORE-FP:
-
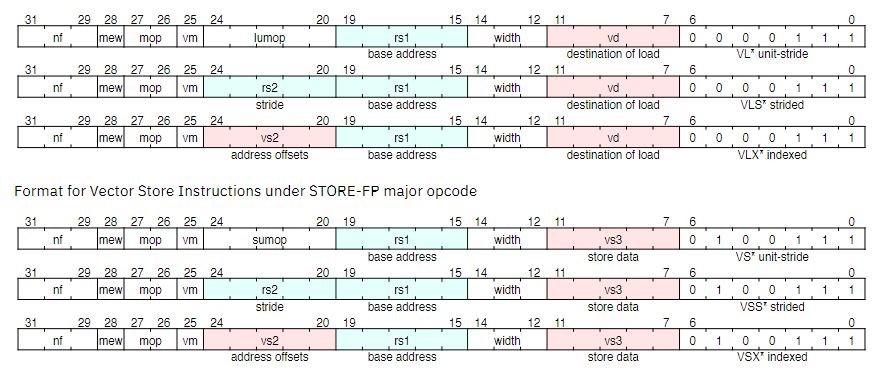
-
向量算数指令:
-
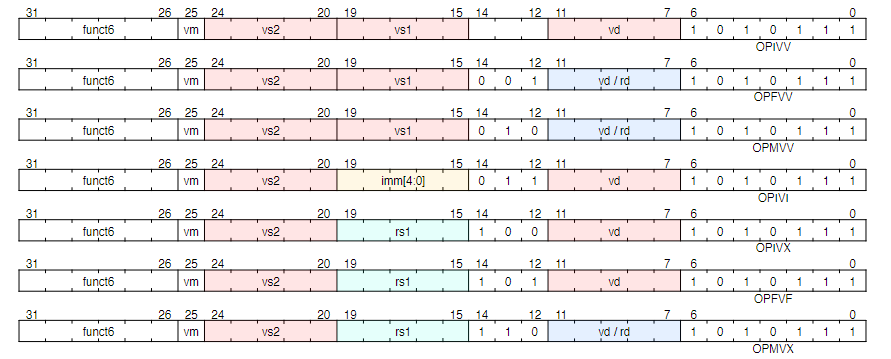
-
向量配置指令:
-

-

-
向量指令可以接收标量或者向量操作数,生成标量或者向量操作数
-
大多数向量指令可以通过mask实现条件或者非条件执行
5.1. Scalar Operands
- 标量操作数可以是立即数,整数寄存器(x),浮点寄存器(f)或者一个vector寄存器的第0个元素。
- 标量结果可以写入整数寄存器(x),浮点寄存器(f)或者一个vector寄存器的第0个元素。
5.2. Vector Operands
-
每个向量操作数都有一个effective element width (EEW), 一般情况下EEW=SEW.
-
每个向量操作数都有一个effectiveLMUL (EMUL), 一般情况下EMUL=LMUL.
-
某些向量指令的源和目的向量具有相同的元素个数,但是元素位宽不同。此时EEW和EMUL就不等于SEW和LMUL, 但是EEW/EMUL = SEW/LMUL,这样才能保证元素个数相同。例如:大部分拓宽的向量算数指令的源操作向量组EEW=SEW, EMUL=LMUL, 但是目的操作向量组的EEW=2*SEW, EMUL=2*LMUL
-
向量操作数或者结果操作数可能占用一个或多个向量寄存器(取决于EMUL), 如果占用多个,默认占用编号值较低的向量寄存器。
-
以下情况可以将目的向量寄存器组直接覆盖源向量寄存器组:
- 目的EEW=源EEW
- 目的EEW<源EEW, 并且发生覆盖的源向量是源向量寄存器组中的最低编号的向量寄存器。例如:LMUL=1, vnsrl.wi v0, v0, 3 is legal, but a destination of v1 is not
- 目的EEW>源EEW, 源EMUL至少是1, 并且发生覆盖的是目的向量寄存器组中的最高编号的向量寄存器。例如:LMUL=8, vzext.vf4 v0, v6 is legal, but a source of v0, v2, or v4 is not
-
向量指令最多可以用8个向量寄存器,也就是是说EMUL<=8. 如果一条向量指令需要超过8个向量寄存器,则会引发非法指令异常(实际上这种情况的指令编码空间是被保留的,目前不支持,可以被扩展)。 例如,当 LMUL = 8 时,尝试进行加宽操作产生加宽的向量寄存器组将引发非法指令异常,因为这意味着 EMUL = 16。
-
拓宽(Widened)标量值时,放在向量寄存器的第一个元素,EMUL=1.
5.3. Vector Masking
-
许多向量指令都支持掩码。 被掩码(非活跃)的元素操作不产生异常。 根据
vtype中的vma位的设置,用_掩码不受干扰或掩码不可知_(mask-undisturbed or mask-agnostic)这两种策略来处理与掩码元素相对应的目标向量寄存器元素。 -
在掩码向量指令中,由向量寄存器
v0保存用于控制掩码向量指令执行的掩码值。 -
以后的向量扩展可能会提供更长的指令编码,并为完整的掩码寄存器说明符提供空间。
-
只有当目标向量寄存器写入掩码值(如,comparisons)或归约的标量结果时,用于掩码向量指令的目标向量寄存器组才可以与源掩码寄存器( v0 )重叠。 否则,将引发非法指令异常。
-
其他向量寄存器可用于保存有效的掩码值,并且提供掩码向量逻辑运算以执行谓词计算。
-
当使用比较结果写入掩码时,当前向量长度结束后的目标掩码位将根据 vtype中的 vta 位设置的尾部策略( undisturbed or agnostic )处理。
5.3.1. Mask Encoding
-
掩码编码在指令( inst[25] )中的 vm 字段中,占一位。
-

-
向量掩码在汇编代码中表示为另一个向量操作数,用
.t表示当v0.mask[i]为1时是否发生操作。如果未指定掩码操作数,则假定为未掩码的向量执行(vm = 1)。 -
在较早版本中,
vm字段占2位,即vm [1:0],使用v0寄存器并编码标量运算,表示真值和掩码值。_ -
即使基本向量扩展中,仅支持一个向量掩码寄存器
v0,并且仅支持真实的谓词形式,汇编语法仍将其完全写出,以便与以后的扩展兼容,以后的扩展可能会添加掩码寄存器说明符并支持真值和掩码值。 掩码操作数上的.t后缀还有助于掩码编码的可视化。
6. Conguration-Setting Instructions (vsetvli/vsetivli/vsetvl)
- Application vector length (AVL)
- 应用程序可能会处理一个包含大量元素的vector, 硬件需要将其分为多个loop才能做完. 这里应用程序给出的真实的vector 元素个数就是AVL, 硬件每次处理的实际元素个数就是vl寄存器.
- vsetvli 指令根据其参数设置 vtype 和 vl CSRs,并将 vl 的新值写入 rd。

6.1 vtype encoding

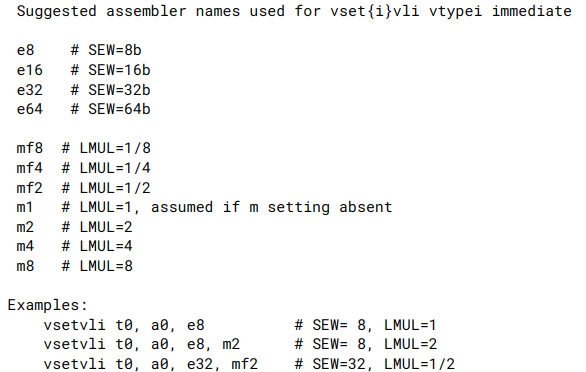
- vsetvl指令与vsetvli稍有不同, vsetvl从rs2寄存器拿到vtype值,而不是直接给出. 这可以用来进行上下文恢复.
6.2. AVL encoding
- 根据setivli指令的rd和rs寄存器的情况, 有以下三种模式:

- rs1不为x0时, AVL由rs1指定的x寄存器保存, 此时正常进行stripmine
- rs1=x0, rd!=x0时, 表示AVL是正整数最大值, 此时硬件需要采用最大支持的元素个数VLMAX, 并将vl和rd寄存器设置为VLMAX
- rs1=x0, rd=x0时, 将假设AVL就等于现在的向量长度vl. 此时vl不会再被写入rd. 这种情况只能使用在VLMAX和vl的值没有因为新的SEW/LMUL而改变的情况
- 这种情况下vtype寄存器可以变化,而vl保持不变,前提是_如果不减小 VLMAX 。如果 SEW / LMUL 比率更改导致 VLMAX 缩小,则可以通过此指令减小
vl值。选择该设计是为了确保vl始终是当前vtype设置的合法值。当前的vl值可以从vlCSR 读取。
- 这种情况下vtype寄存器可以变化,而vl保持不变,前提是_如果不减小 VLMAX 。如果 SEW / LMUL 比率更改导致 VLMAX 缩小,则可以通过此指令减小
- setivli指令格式中,rs1,也就是AVL变为一个5bit零扩展的立即数。
6.3. Constraints on Setting vl
vset{i}vl{i}指令首先根据 vtype 参数,设定 VLMAX ,然后设置vl服从以下约束:
- 如果
AVL ≤ VLMAX,则vl = AVL - 如果
AVL < (2 * VLMAX),则ceil(AVL / 2) ≤ vl ≤ VLMAX - 如果
AVL ≥ (2 * VLMAX),则vl = VLMAX - 如果输入相同的 AVL 和 VLMAX 值,则任何实现中,
v1都是确定的 - 满足之前提及的规则:
- 如果
AVL = 0,则vl = 0 - 如果
AVL > 0,vl > 0 vl ≤ VLMAXvl ≤ AVL- 从
vl中读取的值(用作vsetvl{i}的 AVL 参数时)会在vl中产生相同的值,前提是所得的 VLMAX 等于读取vl时的 VLMAX 值。
- 如果
vl的设置规则足够严格,可以在寄存器溢出和AVL ≤ VLMAX时上下文交换的情况下保护vl的行为,但又足够灵活,确保能够提高 AVL> VLMAX 时的向量通道利用率。- 当AVL介于VLMAX和VLMAX*2时, 可以保证vl=AVL的一半(向上取整),通过两次loop实现AVL.
6.4. Example of stripmining and changes to SEW
- 为了在混合宽度操作上提供高吞吐量,可以动态更改 SEW 和 LMUL 的设置。
-

7. Vector Loads and Stores
- 带mask的load不会更新非活跃的元素,除非被标记为不可知的(agnostic, vtype.vma=1)
7.1. Vector Load/Store Instruction Encoding
- 向量load/store复用标量浮点数的load/store(LOAD-FP/STORE-FP)
- 向量的加载和存储编码重新利用了标量浮点加载/存储12位立即数字段的一部分,以提供进一步的向量指令编码,其中位25保留了标准向量掩码位:
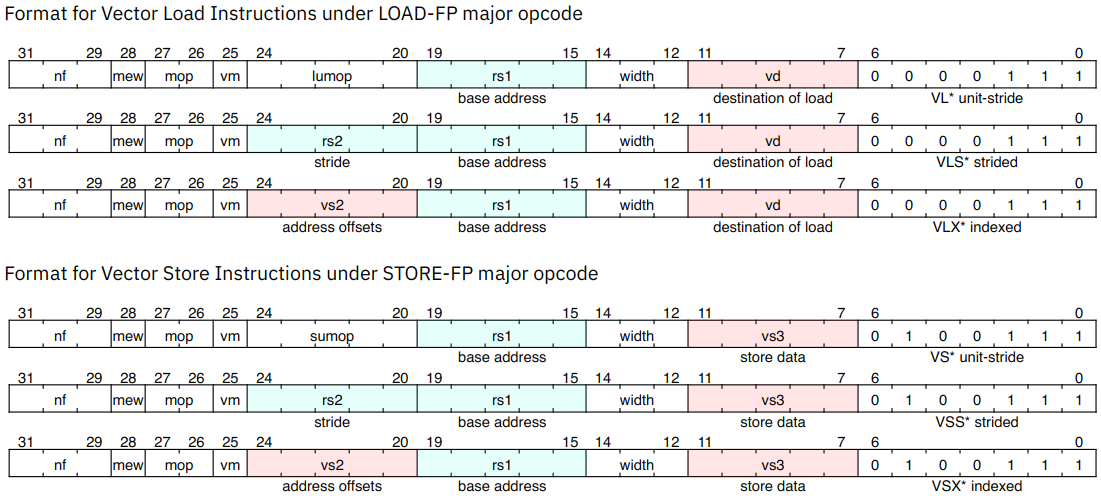
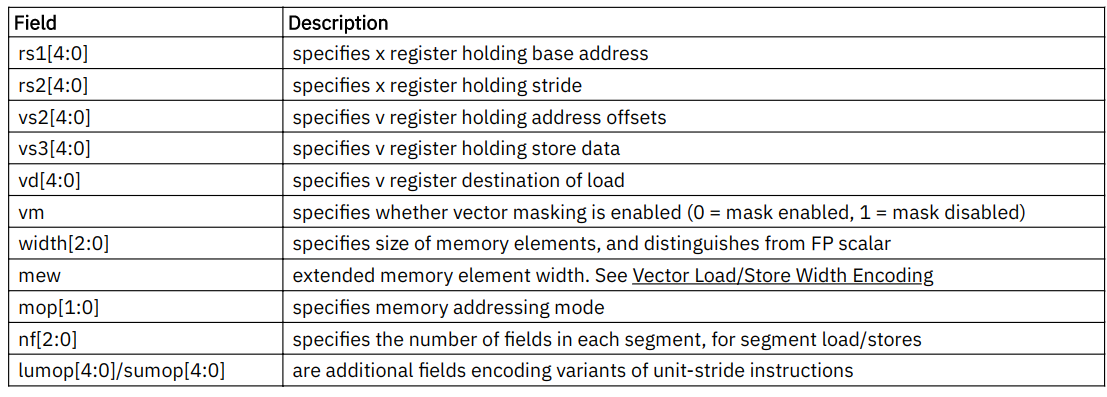
- 向量内存操作直接对指令中要静态传输的数据的 EEW 进行编码,从而减少混合宽度操作时,访问内存时
vtype的改变次数。 索引操作在指令中使用显式 EEW 编码来设置所使用索引的大小,并且用 SEW / LMUL 的值指定数据宽度。
7.2. Vector Load/Store Addressing Modes
-
基本向量扩展支持单位跨步(unit-stride),跨步(strided)和索引(indexed)寻址模式。向量加载/存储的基址寄存器和步幅取自GPR
x寄存器。- unit-stride就是向量元素在内存中的排布就是挨个的, 可以直接一个一个拿出来
- stride是为了按照一个固定间隔取向量元素的方式. 比如在进行两个矩阵相乘A*B, A的一行会跟B的一列做向量乘. A和B在内存中都是按行存储的. A做向量乘时,可以挨个拿出来放到向量寄存器, 而B, 需要按列取出, 所以需要每隔一行元素个数取一个元素, 放到向量寄存器, 才能取出B的一列. 此时就需要用到stride模式了.
- stride模式下, 每次取元素的步长是以byte为最小单位计数的. 步长值存储在rs2表示的寄存器中
- indexed模式是最精细的, 可以精确控制向量寄存器中的某个元素从哪里来. 在取每个元素时, 用vs2向量寄存器的值在mem中索引要取出的元素.
- indexed模式下, 存放元素的向量寄存器组的EEW= SEW, EMUL=LMUL.
- 存放index(offset)的向量寄存器组vs2对应的EEW在指令中进行了编码. 而EMUL则可以计算出来: EMUL=(EEW/SEW)*LMUL. 其实就是用数据向量的元素个数与index向量的EEW来计算组数.
-
向量偏移量操作数被视为字节地址偏移量的向量。如果向量偏移量小于 XLEN,则在将它们添加到基本有效地址之前,先将它们加零扩展到XLEN。如果向量偏移量大于 XLEN,则在地址计算中使用最低有效的 XLEN 位。
-
向量寻址模式使用2位
mop[1:0]字段进行编码: -
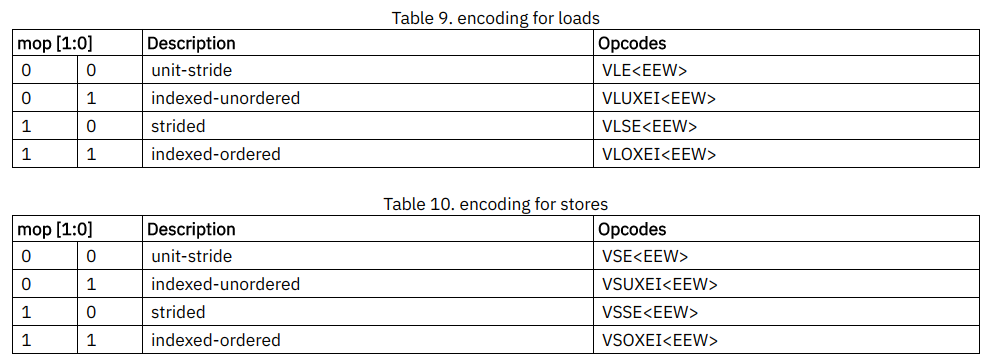
-
向量的索引操作具有两种形式,有序的和无序的。无序的索引(mop!=11)存储操作不保存元素顺序。
-
对于需要强访存顺序依赖的区域,例如IO, 需要使用ordered indexed 方式才能保证顺序
-
其他的 unit-stride 向量寻址模式在 unit-stride 加载和存储指令编码中分别使用5位
lumop和sumop字段编码。 -
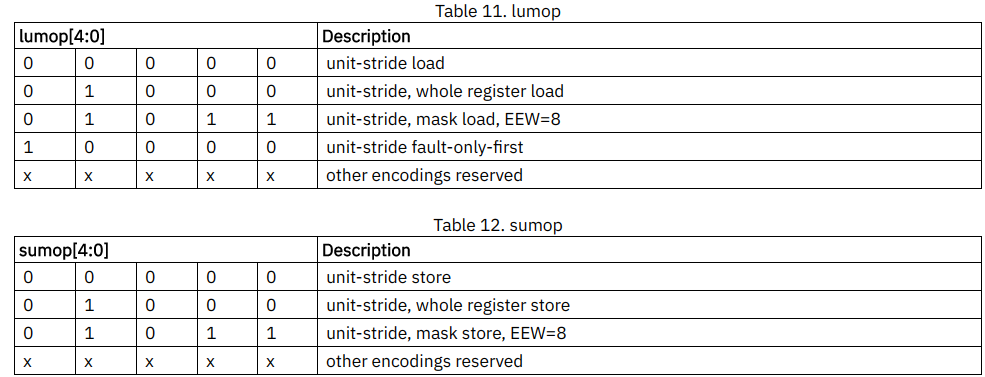
-
nf[2:0]字段编码每个段(segment)中的字段数。对于常规向量的加载和存储,nf= 0,表示在每个元素位置的向量寄存器组和内存之间移动单个值。nf字段中较大的值用于访问段中的多个连续字段(关于段的描述参见7.8节)。 -
**
nf字段替换了地址偏移量字段中的相同位。偏移量可以用单个标量整数计算代替,而段加载/存储添加了更强大的原语,可以将项目移入和移出内存。 -
nf[2:0]字段还对整个向量寄存器的数量进行编码,以针对整个向量寄存器的加载/存储指令进行传输。 -
后面会介绍nf的具体内容。
7.3. Vector Load/Store Width Encoding
- 向量的加载和存储直接将 EEW 编码在指令中。EMUL 的计算公式为:EMUL =(EEW / SEW)* LMUL 。如果 EMUL 超出范围( EMUL> 8 或 EMUL <1/8 ),则会触发非法指令异常。向量寄存器组必须存在能指明所选 EMUL 是否合法的寄存器,否则会触发非法指令异常。
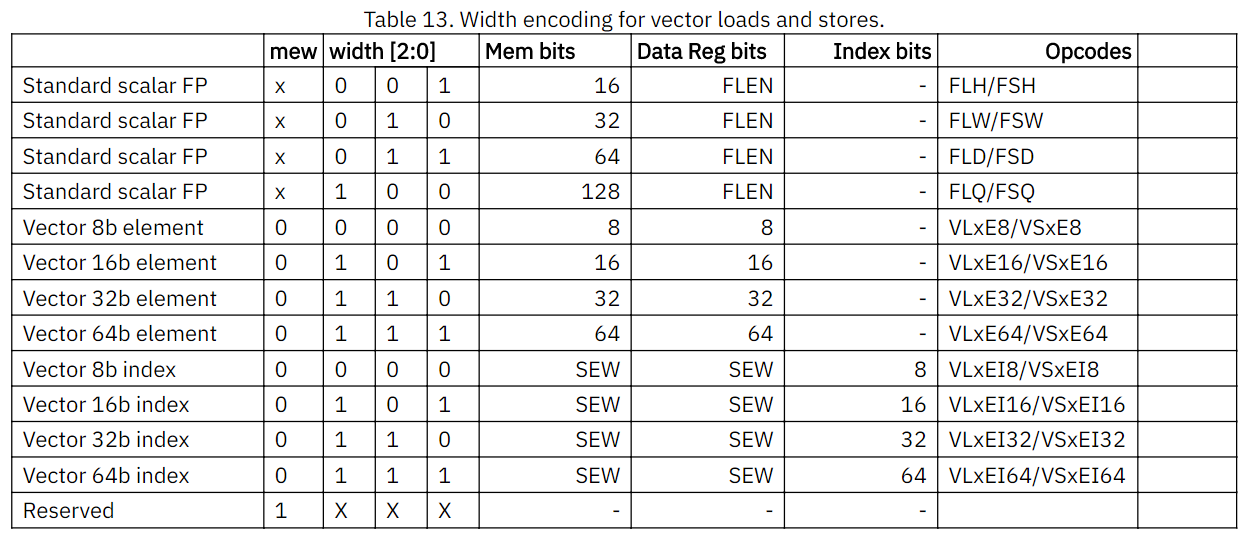
- Mem bits(内存位)是内存中访问的每个元素的大小。
- Reg bits(寄存器位)是寄存器中访问的每个元素的大小。
- index bits (索引位) 是索引向量中每个元素的大小。
mew位(inst[28])扩展了128位及超过128位的内存大小。
7.4. Vector Unit-Stride Instructions
-
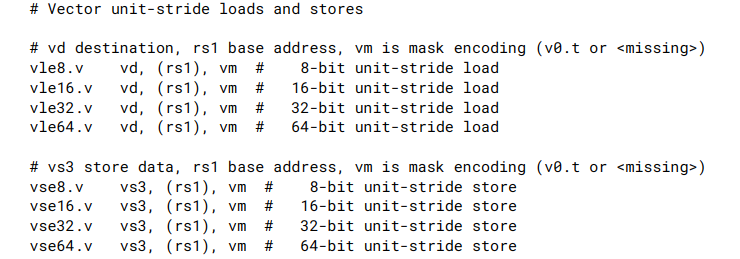
-
此外, 额外的unit-stride mask 访存指令需要被用来将mask值导入或导出。这个操作与unmasked byte load/store类似(EEW=8). 不同之处是等效向量长度evl=ceil(vl/8) , 也就是说没个bit管一个被masked元素. 目的向量寄存器中的剩余部分是tail-agnostic的
-
下面是mask load/store指令:
-

-
实际上vlm.v与width=0的vle8.v指令相同, 区别是lumop和sumop不同。
7.5. Vector Strided Instructions

- 支持负数stride和0-stride
- stride指令中元素的访问彼此之间无序
- 当rs2=x0时,允许但不要求实现执行比活动元素数量更少的内存操作,并且可以在同一静态指令的不同动态执行中执行不同数量的内存操作。
- 如果rs2!=x0, 但是rs2的值=0, 则每个active的元素都必须进行一次访问, 不过顺序可以不固定.
- 如果确定每个元素都执行内存访问,编译器必须注意当立即步长为0时,不要对rs2使用x0形式。
7.6. Vector Indexed Instructions
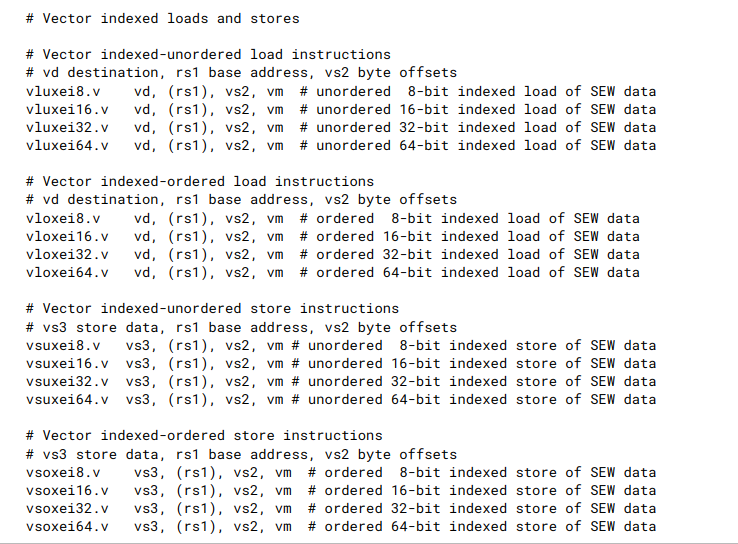
- 上述汇编中ei8,ei16等表示8,16都是表示index的位宽,而不是data的. data的位宽由SEW指定.
- 带u的就是unordered, 带o的是ordered.
7.7. Unit-stride Fault-Only-First Loads
-
Unit-stride Fault-Only-First Loads是用来对那些退出条件依赖数据的循环进行向量化(例如while循环)
-
一般情况下这些指令跟普通的unit访存指令相当, 但是会在向量的第一个元素触发了异常之后执行陷入操作
-
如果其他元素(非第一个元素)触发了异常,那么对应的陷入将不发生, 向量长度vl减少为这个元素的index大小。且不会更新向量寄存器中发生异常的元素及其之后的元素。
-

-

-
即使未引发异常,操作中也可以处理少于
vl个元素并相应地减少vl,但是如果vstart= 0和vl> 0,则必须处理至少一个元素。 -
当仅故障优先指令由于中断而发生陷阱时,实现不应减少 vl 而应设置 vstart 值。
-
注意当仅故障第一指令将在第一个之后触发元素上的调试数据观察点陷阱时,实现不应减少 vl 而是应触发调试陷阱,否则事件可能会丢失。
-
上面两点啥意思??
7.8. Vector Load/Store Segment Instructions
-
segment指令将多个连续内存区域与若干连续的向量寄存器进行数据搬运
-
“段”反映了移动的项目是具有同质元素的子数组。这些操作可用于在内存和寄存器之间转置数组,并且可以通过将结构中的每个字段解包到单独的向量寄存器中来支持对“结构数组”数据类型的操作。
-
nf是3bit的整数, 表示段中的Nfields-1.
-
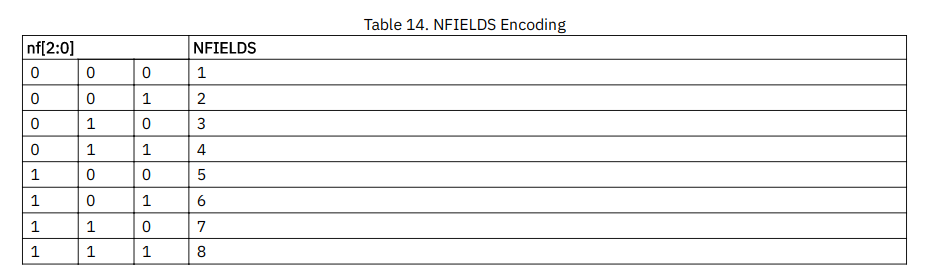
-
EMUL 设置必须使 EMUL * NFIELDS ≤ 8。
-
注意乘积 EMUL * NFIELDS 表示将被分段加载或存储指令触及的底层向量寄存器的数量。这个约束使得这个总数不大于架构寄存器文件的 1/4,并且与 EMUL=8 的常规操作相同。
-
每个字段将保存在连续编号的向量寄存器组中。当 EMUL>1 时,每个字段将占用多个连续编号的向量寄存器中保存的向量寄存器组,并且每个字段的向量寄存器组必须遵循通常的向量寄存器对齐约束(例如,当 EMUL=2 和 NFIELDS=4 时,每个域的向量寄存器组必须从偶数向量寄存器开始,但不必从 8 个向量寄存器号的倍数开始)。
-
如果段加载或存储访问的向量寄存器编号将增加超过 31,则保留指令编码。
-
注意此约束是为了帮助实现与未来可能更长的指令编码的前向兼容性,该指令编码具有更多可寻址向量寄存器。
-
vl 寄存器给出要移动的段数,它等于传送到每个向量寄存器组的元素数。mask也应用于整个段的级别。 对于段加载和存储,用于访问每个段内的字段的各个内存访问相对于彼此是无序的,即使对于有序索引段加载和存储也是如此。
-
vstart 值以整个段为单位。如果在访问段期间发生陷阱,则在采取陷阱之前是否执行故障段的访问子集是由实现定义的。
7.8.1. Vector Unit-Stride Segment Loads and Stores
-
Unit-Stride Segment Loads and Stores将打包的连续段移动到多个目标向量寄存器组中。
-
可以用于一些结构体: RGB, complex数据等的向量存取
-
注意在段包含具有不同大小字段的结构的情况下,软件稍后可以在段加载将数据带入向量寄存器后使用附加指令解压缩单个结构字段。
-
vlseg/vsseg 分别用于单位跨度段的加载和存储。
-

-
对于加载( loads),vd 寄存器将保存从段加载的第一个字段。对于存储,读取 vs3 寄存器以提供要存储到每个段的第一个字段。
-
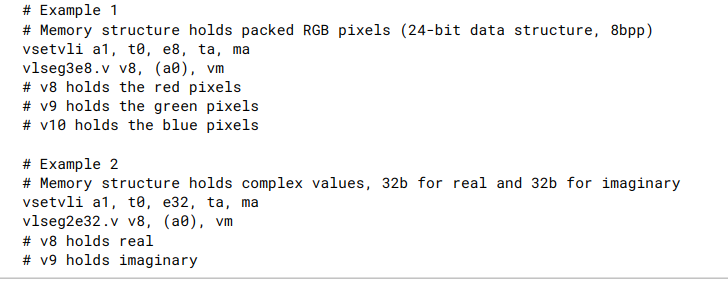
-
上图中, 第一个是加载RGB三个像素点组成的segment到向量寄存器的例子. 其中nfields=3, eew=8.
-
也有单元步长指令的仅故障优先版本:
-

-
对于仅故障的第一个段加载,如果在访问段的过程中检测到异常,则无论元素索引是否为零,是否加载段的子集都是实现定义的。
-
这些指令可能会在报告陷阱的点或修剪向量长度的点之后覆盖目标向量寄存器组元素。
7.8.2. Vector Strided Segment Loads and Stores
-
每个segment之间间隔byte-stride时用这种指令
-

-
例如上面第一个例子, x5是基地址, x6就是stride. 因为有3个seg, 所以会占用3个vector group. 这里需要注意的是, 3个segment实际上在内存中应该是一个结构体, 所以每个segment在内存上是连续的, 所以这里三个seg的address是连续的, 但是会放在三个不同的vector reg group
-
对一个segment中的fields的访问顺序是随意的.
7.8.3. Vector Indexed Segment Loads and Stores
- indexed访存指令的segment版本.
- 同样包含ordered和unordered. 但是即使是ordered, 对一个segment中的不同field的访问也是无序的
- 同样的, indexed访存指令中, 显式给出的是index的EEW, 例如ei32, 表示index是32bit. data向量的EEW=SEW, EMUL = LMUL
-

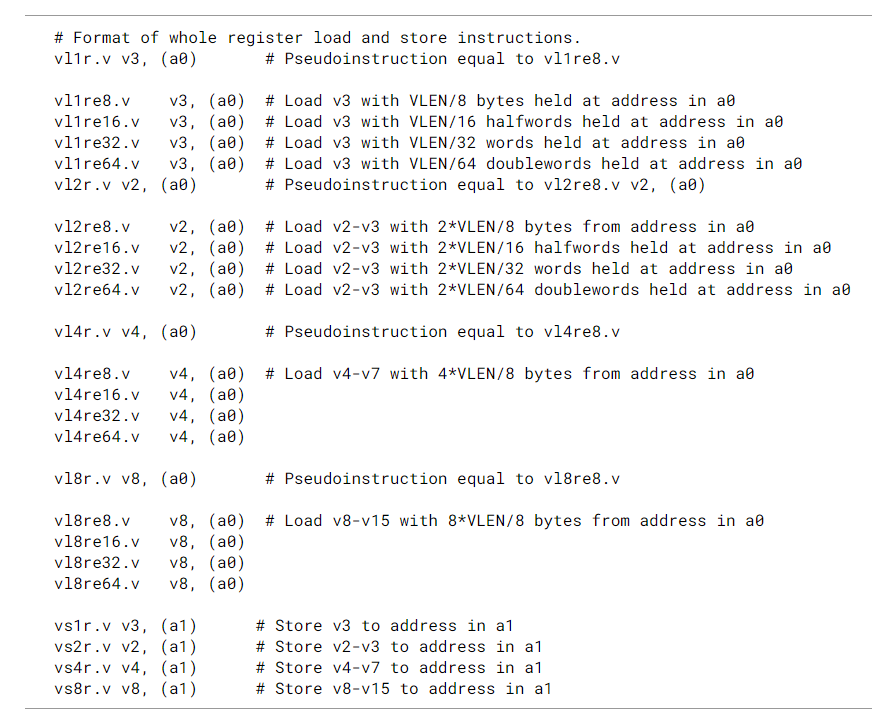
7.9. Vector Load/Store Whole Register Instructions

-
这类load/store指令会操作全部的向量寄存器组
-
这类指令可以在向量寄存器当前内容的长度未知时使用, 或者某些修改vl和vtype代价较高的场景。例如:
- compiler register spills(当寄存器使用超出物理寄存器个数,会将一部分寄存器搬到主存中,为新变量腾出寄存器空间)
- 用向量寄存器传值的向量函数
- 中断处理
- 操作系统的上下文切换
-
load执行包含mew字段,表示EEW, width字段的含义与[[#7.3. Vector Load/Store Width Encoding]] 中所述相同。
-
注意 因为寄存器中字节布局与内存中字节布局相同,所以无论EEW如何,相同的数据都会写入目标寄存器组。因此,仅提供 EEW=8 变体就足够了。提供了完整的 EEW 变体集,以便编码的 EEW 可用作指示目标寄存器组接下来将使用此 EEW 访问的提示,这有助于在内部重新排列数据的实现。
-
向量整个寄存器存储指令的编码类似于 EEW=8 的元素的未屏蔽单元步长存储。
-
nf 字段使用 NFIELDS 编码对要加载和存储的向量寄存器数量进行编码(图 NFIELDS 编码)。
-
寄存器的编码数量必须是 2 的幂,并且向量寄存器数量必须与向量寄存器组对齐,否则保留指令编码。 NFIELDS 表示要传输的向量寄存器的数量,在基数之后依次编号。仅支持 NFIELDS 值 1、2、4、8,保留其他值。当传输多个寄存器时,编号最小的向量寄存器保存在编号最小的内存地址中,并且连续的向量寄存器编号连续放置在内存中。
-
无论 vtype 和 vl 中的当前设置如何,指令都以有效向量长度 evl=NFIELDS*VLEN/EEW 运行。如果 vstart ≥ vl , 则还是可能会写入元素(之前的指令中如果vstart≥ vl ,不会写入任何元素)。相反,如果 vstart ≥ evl 则不写入任何元素。
-
这些指令的操作类似于未屏蔽的单位步长加载和存储指令,基地址在由 rs1 指定的标量 x 寄存器中传递。
-
如果基地址未自然对齐到以字节为单位的编码 EEW 的大小 (EEW/8) 或以字节为单位的实现的最小支持 SEW 大小(SEWmin/8)中的较大者,则允许实现在整个寄存器加载和存储时引发未对齐的地址异常 。
-
注意 允许基于与编码的 EEW 不对齐而引发未对齐异常可简化这些指令的实现。一些子集实现可能不支持较小的 SEW 宽度,因此即使大于编码的 EEW,也允许报告支持的最小 SEW 的未对齐异常。例如,一个极端的非标准实现可能有 SEWmin>XLEN。软件环境可以强制要求最低对齐要求来支持 ABI。
-
下面是实际的伪代码示例:
- 注意 对于不支持的 EEW 值,实现应该在 vl<nf>r指令上引发非法指令异常。
- 注意我们已经考虑添加一个完整的寄存器掩码加载指令(vl1rm.v),但决定从初始扩展中省略。主要目的是通知微架构数据将用作掩码。使用以下代码序列可以达到相同的效果,其成本最多为四条指令。其中,第一个可能会被删除,因为 vl 通常已经在一个标量寄存器中,如果后面的向量指令需要一个新的 SEW/LMUL,最后一个可能已经存在。因此,在最好的情况下,只需要两条指令(其中只有一条执行向量运算)来合成专用指令的效果:
-

8. Vector Memory Alignment Constraints
- 如果向量内存指令访问的元素与元素的大小不自然对齐,则该元素被成功传输或在该元素上引发地址未对齐异常。
- 对未对齐的向量内存访问的支持与对未对齐的标量内存访问的支持在一个具体实现中是独立开来的。
- 注意 一个实现可能没有、有一个或两个标量和向量内存访问支持硬件中的部分或全部未对齐访问。应定义一个单独的 PMA 以确定相关地址范围内是否支持向量未对齐访问。
- 矢量未对齐内存访问遵循与标量未对齐内存访问相同的原子性规则。
9. Vector Memory Consistency Model
- 向量内存指令在本地 hart 上按程序顺序执行。
- 向量存储器指令在指令级遵循 RVWMO。
- 除了vector indexed-ordered loads and stores,,指令中的元素操作是无序的。
- Vector indexed-ordered 分别按元素顺序从/向内存加载和存储读取和写入元素。
- 受向量长度寄存器 vl 影响的指令对 vl 具有控制依赖性,而不是数据依赖性。类似地,mask向量指令对源mask寄存器具有控制依赖性,而不是数据依赖性。
- 注意 将向量长度和掩码视为控制而不是数据通常与相应标量代码的语义相匹配,其中通常会使用分支指令。将掩码视为控制允许掩码向量加载指令在知道掩码值之前访问内存,而无需错误推测恢复机制。
- 注意目前未定义提议的 RVTSO 内存模型(Ztso 扩展)下的向量内存指令的行为。
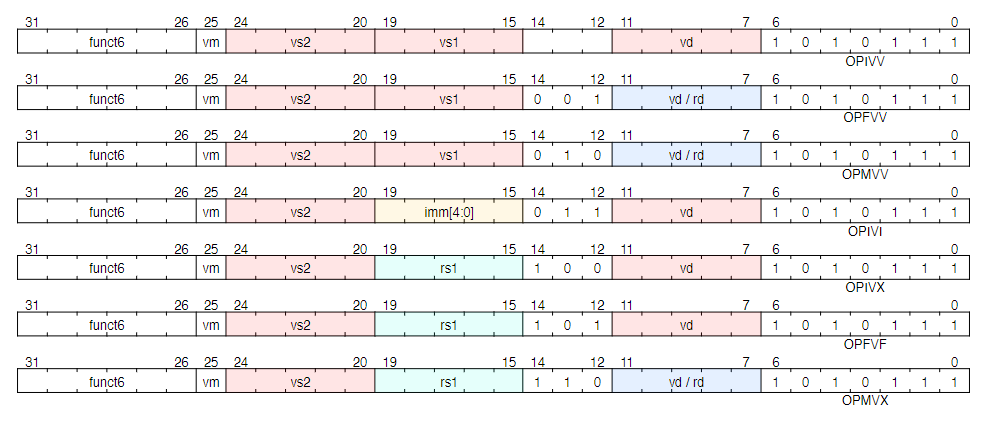
10. Vector Arithmetic Instruction Formats
- 矢量算术指令使用与 OP-FP 相邻的新主操作码 (OP-V = 10101112)。三位 funct3 字段用于定义向量指令的子类别。
- OP-V 主要操作码下向量算术指令的格式:
-
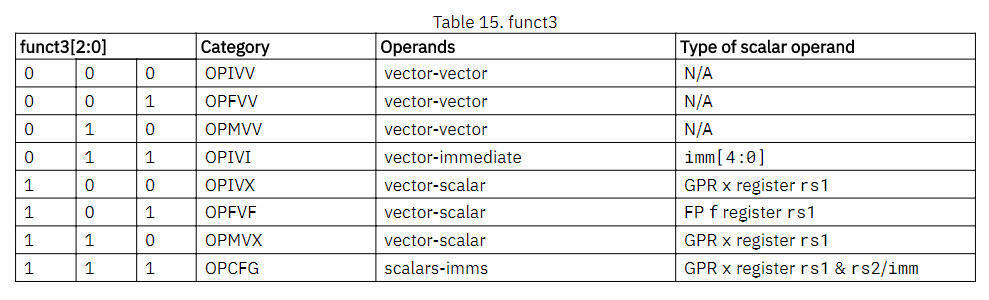
10.1. Vector Arithmetic Instruction encoding
-
funct3编码了操作类型和源地址
-
-
根据操作码,使用无符号或二进制补码有符号整数算术执行整数运算。
-
注意在本讨论中,定点运算被认为是整数运算。
-
所有标准向量浮点算术运算都遵循 IEEE-754/2008 标准。所有向量浮点运算都使用 frm 寄存器中的动态舍入模式。当任何向量浮点指令使用 包含无效的舍入模式的frm 字段时,即使它是不依赖于舍入模式的指令,或者其vl=0 时,又或者此时vstart ≥ vl 时,都是非法的。
-
注意 所有向量浮点代码都依赖于 frm 中的有效值。当舍入模式无效时,具体实现可以使所有向量 FP 指令报告异常,以简化控制逻辑。
-
vector-vector运算从分别由 vs2 和 vs1 指定的向量寄存器组中获取两个操作数向量。
-
vector-scalar 运算可以有三种可能的形式。在所有三种形式中,向量寄存器组操作数由 vs2 指定。第二个标量源操作数来自三个备选源之一:
- 对于整数运算,标量可以是 5 位立即数 imm[4:0],编码在 rs1 字段中。除非另有说明,否则该值符号扩展到 SEW 位。
- 对于整数运算,可以从 rs1 指定的标量 x 寄存器中获取标量。如果 XLEN>SEW,除非另有说明,否则使用 x 寄存器的最低 SEW 位。如果 XLEN < SEW, 则要将x寄存器的值有符号扩展到SEW。
- 对于浮点运算,可以从标量 f 寄存器中获取标量。如果 FLEN > SEW,则检查 f 寄存器中的值是否为有效的 NaN-boxed([[NaN-Boxing]])值,在这种情况下,使用 f 寄存器的最低有效 SEW 位,否则使用规范的 NaN 值。保留任何浮点向量操作数的 EEW 不是受支持的浮点类型宽度(包括 FLEN < SEW 时)的向量指令。
-
注意 一些指令对 5 位立即数进行零扩展,并通过在汇编语法中命名立即数 uimm 来表示这一点。
-
注意 当向 Zfinx/Zdinx/Zhinx 扩展添加向量扩展时,浮点标量参数取自 x 寄存器。这些扩展不支持 NaN-boxed,因此向量浮点标量值使用与整数标量操作数相同的规则生成(即,当 XLEN > SEW 使用最低 SEW 位时,当 XLEN < SEW 使用符号扩展值)。
-
矢量算术指令在 vm 字段的控制下进行mask操作:
-

-
注意 在编码中,vs2 是第一个操作数,而 rs1/imm 是第二个操作数。这与标准标量排序相反。这种安排保留了现有的编码约定,即只读取一个标量寄存器的指令,从 rs1 读取它,并且 5 位立即数来自 rs1 字段。
-
向量三元算术指令的汇编语法模式(乘加):
-

-
注意 对于三元乘加运算,汇编语法总是将目标向量寄存器放在最前面,然后是 rs1 或 vs1,然后是 vs2。这种排序为这些三元运算提供了更自然的汇编程序读取,因为乘法操作数总是彼此相邻。
10.2. Widening Vector Arithmetic Instructions
-
一些向量算术指令被定义为widening(加宽)操作,其中目标向量寄存器组具有 EEW=2*SEW 和 EMUL=2*LMUL。这些通常在操作码上被赋予 vw* 前缀,或者为向量浮点指令赋予 vfw*。
-
第一个向量寄存器组操作数可以是单宽或双宽:
-

-
注意 最初,w 后缀用于操作码,但这可能与使用 w 后缀表示双字整数中的字长操作混淆,因此 w 被移至前缀。
-
注意 浮点加宽操作已从 vwf* 更改为 vfw*,以便与将写入 fw* 的任何标量扩展浮点操作更加一致。
10.3. Narrowing Vector Arithmetic Instructions
- 提供了一些指令来将双宽度源向量转换为单宽度目标向量。这些指令将 EEW/EMUL=2*SEW/2*LMUL 由 vs2 指定的向量寄存器组转换为具有当前 SEW/LMUL 设置的向量寄存器组。如果有第二个源向量寄存器组(由 vs1 指定),则它与结果的宽度相同(更窄),即vs1的 EEW=SEW。
- 注意 另一种设计决策是将 SEW/LMUL 视为定义源向量寄存器组的大小。这里的选择是基于这样一种信念,即所选择的方法将需要更少的 vtype 更改。
- 注意设置掩码寄存器的比较操作也隐含地属于归约操作。
- 操作码上的 vn* 前缀用于区分汇编程序中的这些指令,或 vfn* 前缀用于归约的浮点操作码。双宽度源向量寄存器组由源操作数后缀中的 w 表示(例如,vnsra.wv)
-

11. Vector Integer Arithmetic Instructions
- 提供了一组向量整数算术指令。除非另有说明,否则整数运算会在溢出时wrap( 相当于不对溢出做特殊处理)。
11.1. Vector Single-Width Integer Add and Subtract
-
提供向量整数加减法。还为向量标量形式提供了反向减法指令。
-

-
可以使用带有 x0 标量操作数的反向减法指令对整数值向量求反。提供了汇编伪指令 vneg.v vd,vs = vrsub.vx vd,vs,x0。
11.2. Vector Widening Integer Add/Subtract
-
加宽加/减指令在有符号和无符号变体中都提供,两者的区别在于较窄的源操作数在形成双宽度的和之前是进行符号扩展还是零扩展。
-

-
注意 使用标量操作数为 x0 的加宽加法指令可以将整数值的宽度加倍。提供汇编伪指令 vwcvt.x.x.v vd,vs,vm = vwadd.vx vd,vs,x0,vm 和 vwcvtu.x.x.v vd,vs,vm = vwaddu.vx vd,vs,x0,vm。
11.3. Vector Integer Extension
-
这类指令将零或符号扩展 EEW 小于 SEW 的源向量整数操作数,以填充目标中 SEW 大小的元素。源的 EEW 是 SEW 的 1/2、1/4 或 1/8,而源的 EMUL 是 (EEW/SEW)*LMUL。目的元素的 EEW 等于 SEW,EMUL 等于 LMUL。
-

-
如果源 EEW 不是支持的宽度,或者源 EMUL 低于最小合法 LMUL,则保留指令编码。
-
注意 标准向量加载指令访问与目标寄存器元素大小相同的内存值。一些应用程序代码需要对更宽元素中的一系列操作数宽度进行操作,例如,从内存中加载一个字节并添加到一个八字节元素。为了避免必须提供向量加载指令的数量与数据类型(字节、字、半字以及有符号/无符号变体)的数量的叉积,我们改为添加显式扩展指令,如果合适,可以使用加宽算术指令不可用。
11.4. Vector Integer Add-with-Carry / Subtract-with-Borrow Instructions
-
为了支持多字整数运算,提供了对进位操作的指令。对于每个操作(加法或减法),提供两条指令:
- 一条是提供结果(SEW宽度)
- 另一条是产生进位输出(编码为一个mask布尔值)。
-
进位输入和输出使用掩码寄存器来表示,由于编码限制,进位输入必须来自隐式的v0寄存器,但是进位输出可以写到任何遵循源/目的重叠限制的向量寄存器。
-
vadc和vsbc对源操作数和进位或借位进行加减,并将结果写入向量寄存器vd。这些指令被编码为带mask的指令(vm=0),但是它们对所有的主体元素进行操作并写回。
-
vmadc和vmsbc对源操作数进行加减运算,如果是包含mask的指令形式(vm=0),则还会加上进位或减去借位,并将进位结果写回vd的mask寄存器。如果没有包含mask形式(vm=1),则没有进位或借入。这些指令对所有的主体元素进行操作和回写,即使是被masked的。因为这些指令产生了一个mask值,所以它们总是以tail-agnostic,即尾部不可知的策略进行操作。
-
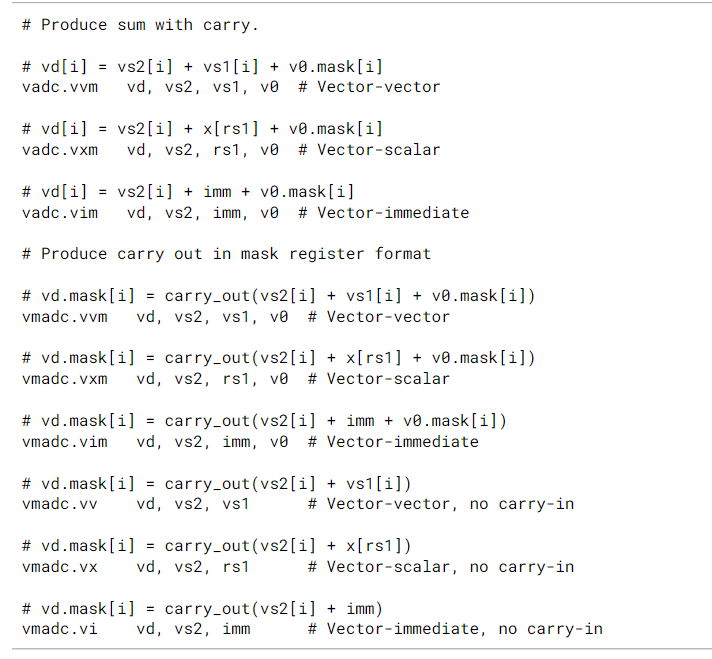
-
一条带进位传播的加减法需要两条使用相同输入的指令:
-

-
下面是带借位的向量减法,向量减法没有减立即数的指令:
-

-
对于vmsbc,如果截断前的差值为负数,则借位被定义为1。
-
对于vadc和vsbc,如果目的向量寄存器是v0,指令编码被保留。
11.5. Vector Bitwise Logical Instructions

11.6. Vector Single-Width Shift Instructions

11.7. Vector Narrowing Integer Right Shift Instructions

- 使用标量操作数为x0的缩小整数移位指令,一个整数值的宽度可以减半。提供了一个汇编伪指令 vncvt.x.x.w vd,vs,vm = vnsrl.wx vd,vs,x0,vm。
11.8. Vector Integer Compare Instructions
- 以下的整数比较指令,如果比较结果为真,则将1写入目的掩码寄存器元素。目的屏蔽向量总是保存在一个单一的向量寄存器中,目标屏蔽向量寄存器可以与源向量屏蔽寄存器(v0)相同。
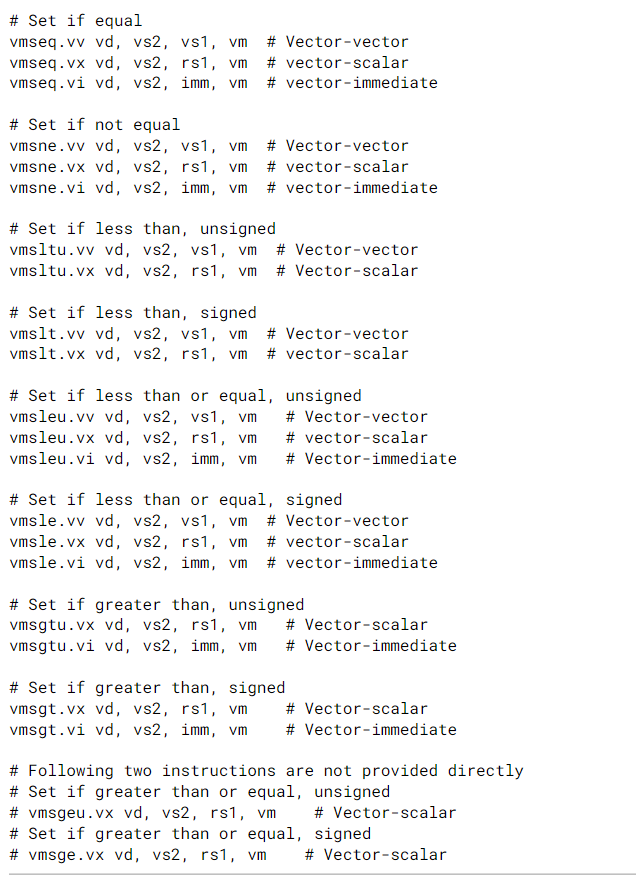
- 不提供vmslt{u}.vi的即时形式,因为即时值可以减少1,并使用vmsle{u}.vi的变体来代替。vmsle.vi的范围是-16到15,导致vmslt.vi的有效范围是-15到16。vmsleu.vi的范围是0到15,导致有效的vmsltu.vi范围是1到16(注意,vmsltu.vi的即时0没有用,因为它总是假的)。
- 因为5位向量的即时值总是带符号的,当simm5即时值的高位被设置时,vmsleu.vi也支持2SEW-16到2SEW-1范围内的无符号即时值,允许相应的vmsltu.vi对2SEW-15到2SEW范围内的无符号即时值进行比较。注意,带有2SEW即时值的vmsltu.vi是没有用的,因为它始终是真的。

-
同样,没有提供vmsge{u}.vi,比较是用vmsgt{u}.vi实现的,即时值减一。由此产生的有效vmsge.vi范围是-15到16,由此产生的有效vmsgeu.vi范围是1到16(注意,立即为0的vmsgeu.vi没有用,因为它总是真的)。
-
寄存器标量和即时值的vmsgt形式的提供是为了让一条比较指令提供正确的mask值的极性,而不需要使用额外的屏蔽逻辑指令。
-
为了减少编码空间,没有直接提供vmsge{u}.vx形式,因此va≥x的情况需要特殊处理。
-
vmsge{u}.vx操作可以通过将x的值减少1并使用vmsgt{u}.vx指令来合成,前提是这样做不会使x中的表示值溢出:
-

-
上述序列通常是最有效的实现,但在x的范围未知的情况下,可以提供汇编伪指令(>=可以通过小于的结果取反得到):
-

-
可以利用v0来快速地实现比较表达式的相与操作:
-

11.9. Vector Integer Min/Max Instructions
- 支持有符号和无符号整数的最小和最大指令。
-

11.10. Vector Single-Width Integer Multiply Instructions
- 单宽乘法指令执行SEW位*SEW位的乘法,产生2*SEW位的乘积,然后在SEW位宽的目的寄存器中返回乘积的一半。mul版本将乘积的低字写到目标寄存器,而mulh版本将乘积的高字写到目标寄存器。
-

11.11. Vector Integer Divide Instructions
-
除法和余数指令等同于RISC-V标准标量整数乘法:
-

-
没有标量除以向量的指令形式。
11.12. Vector Widening Integer Multiply Instructions
- 加宽的整数乘法指令从SEW位*SEW位的乘法中返回完整的2*SEW位乘积。
-

11.13. Vector Single-Width Integer Multiply-Add Instructions
-
整数乘加指令是具有破坏性的(会修改源操作寄存器的值),有两种形式,一种是覆盖加数或减数(vmacc, vnmsac),一种是覆盖第一个乘数(vmadd, vnmsub)。
-

-
乘积的低半部分与第三个操作数相加或相减。
11.14. Vector Widening Integer Multiply-Add Instructions
- 加宽的整数乘加指令将SEW-位*SEW-位乘法的全部2*SEW-位乘积加到2*SEW-位值,并产生2*SEW-位结果。支持有符号和无符号乘法操作数的所有组合。
-

11.15. Vector Integer Merge Instructions
- 矢量整数合并指令根据一个mask合并两个源操作数。与普通的算术指令不同,合并指令对所有的主体元素(即从vstart到vl中的当前矢量长度的元素集)进行操作。
- vmerge指令被编码为带mask的指令(vm=0)。该指令将两个来源结合起来,具体如下:在mask值为0时,第一个操作数被复制到目的元素上,否则第二个操作数被复制到目的元素上。第一个操作数总是一个由vs2指定的向量寄存器组。第二个操作数是由vs1指定的向量寄存器组或由rs1指定的标量x寄存器或一个5位符号扩展的立即数:
-

11.16. Vector Integer Move Instructions

- 矢量整数移动指令复制一个源操作数到一个矢量寄存器组。vmv.v.v变体复制了一个向量寄存器组,而vmv.v.x和vmv.v.i变体将一个标量寄存器或立即数复制到目标向量寄存器组的所有有效元素。这些指令被编码为无mask指令(vm=1)。第一个操作数(vs2)必须包含v0,vs2中的任何其他矢量寄存器编号都是保留的。
- mask可以用一个序列vmv.v.i vd, 0; vmerge.vim vd, vd, 1, v0来拓宽成SEW宽度的元素。
- 矢量整数移动指令与矢量合并指令共享编码,但移动指令的vm=1,vs2=v0。
- vmv.v.v vd, vd的形式,使主体元素保持不变,可以用来表示寄存器的下一次使用将是EEW等于SEW。
12. Vector Fixed-Point Arithmetic Instructions
- 将整数运算指令扩展即可支持定点运算指令
12.1. Vector Single-Width Saturating Add and Subtract

- 与整数加减的区别是多了s 标记,表示saturate
12.2. Vector Single-Width Averaging Add and Subtract
- 均值加法和均值减法会将加法或者减法的结果右移一位并根据vxrm的设置进行舍入
-

12.3. Vector Single-Width Fractional Multiply with Rounding and Saturation
- 有符号分数乘法指令计算两个SEW位的输入, 输出2*SEW位宽的输出,然后将结果右移SEW-1位,这些右移的位据vxrm舍入,之后进行饱和截位到SEW位。如果结果导致饱和,则需要设置vxsat位。
-

12.4. Vector Single-Width Scaling Shift Instructions
- 这些指令将右移输入,根据vxrm将右移的位进行舍入。右移填充的位可以无符号扩展(vssrl)也可以有符号扩展sign-extending (vssra)。vs2是需要移位的寄存器组, vs1是移位量寄存器组,标量整数寄存器rs1或zero-extended的5bit立即数也可以用来作为移位量。对于移位量, 只有低log2(SEW) bit是有效的。
-

12.5. Vector Narrowing Fixed-Point Clip Instructions
-
vnclip指令用于将一个定点数归约到一个目的向量中. 该指令支持rounding, scaling和饱和.
-
vs2指定了源数据, vs1指定了scale的shift amount
-

-
具体的round模式由vxrm CSR寄存器指定. round在目的寄存器的低位进行, 先于饱和操作
-
如果目的元素存在饱和的情况, 则vxsat的对应bit会拉高.
13. Vector Floating-Point Instructions
- 目前支持32和64bit的满足IEEE-754/2008标准的floating-point
- 如果浮点单元状态位mstatus.FS被关闭了, 则任意执行向量浮点指令的尝试都会抛出指令异常. 同理, 任意改变了浮点状态寄存器的向量浮点指令都需要将mstatus.FS设置为dirty
- 如果实现了hypervisor扩展且V=1, 则vsstatus.FS位也需要考虑进来, 即mstatus.FS或vsstatus.FS位被关闭, 则任意执行向量浮点指令的尝试都会抛出指令异常. 同理, 任意改变了浮点状态寄存器的向量浮点指令都需要将mstatus.FS和vsstatus.FS设置为dirty
13.1. Vector Floating-Point Exception Flags
- 向量中活跃的浮点元素会设置标准FP扩展标记位: fflags.
- 非活跃的元素不会修改fflags对应位
13.2. Vector Single-Width Floating-Point Add/Subtract Instructions

13.3. Vector Widening Floating-Point Add/Subtract Instructions

13.4. Vector Single-Width Floating-Point Multiply/Divide Instructions

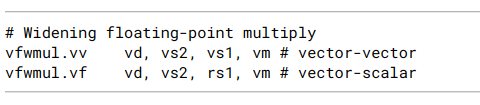
13.5. Vector Widening Floating-Point Multiply
13.6. Vector Single-Width Floating-Point Fused Multiply-Add Instructions

13.7. Vector Widening Floating-Point Fused Multiply-Add Instructions
- 乘数的位宽是SEW, 加数和结果的位宽是2SEW

13.8. Vector Floating-Point Square-Root Instruction

13.9. Vector Floating-Point Reciprocal Square-Root Estimate Instruction

-
该指令返回1/sqrt(x)结果的7bit估计值
-
下表给出了该指令的输出情况:
-

-
sqrt是采用查找表实现的.
-
浮点相关基础知识: [[浮点数F]] CSAPP复习笔记03:Floating Point - 知乎
-
规格化后的浮点数的exp的0bit和significand的高6bit(不包括最高位的1)将组合起来寻址下面的查找表. 查找表的输出为结果的significand的高7位(不包括最高位的1)



- 例子:SEW=32, vfrsqrt7(0x00718abc ( ≈ 1.043e-38) ??怎么赶紧不太对) = 0x5f080000 ( ≈ 9.800e18), and vfrsqrt7(0x7f765432 ( ≈ 3.274e38)) = 0x1f820000 (≈ 5.506e-20).
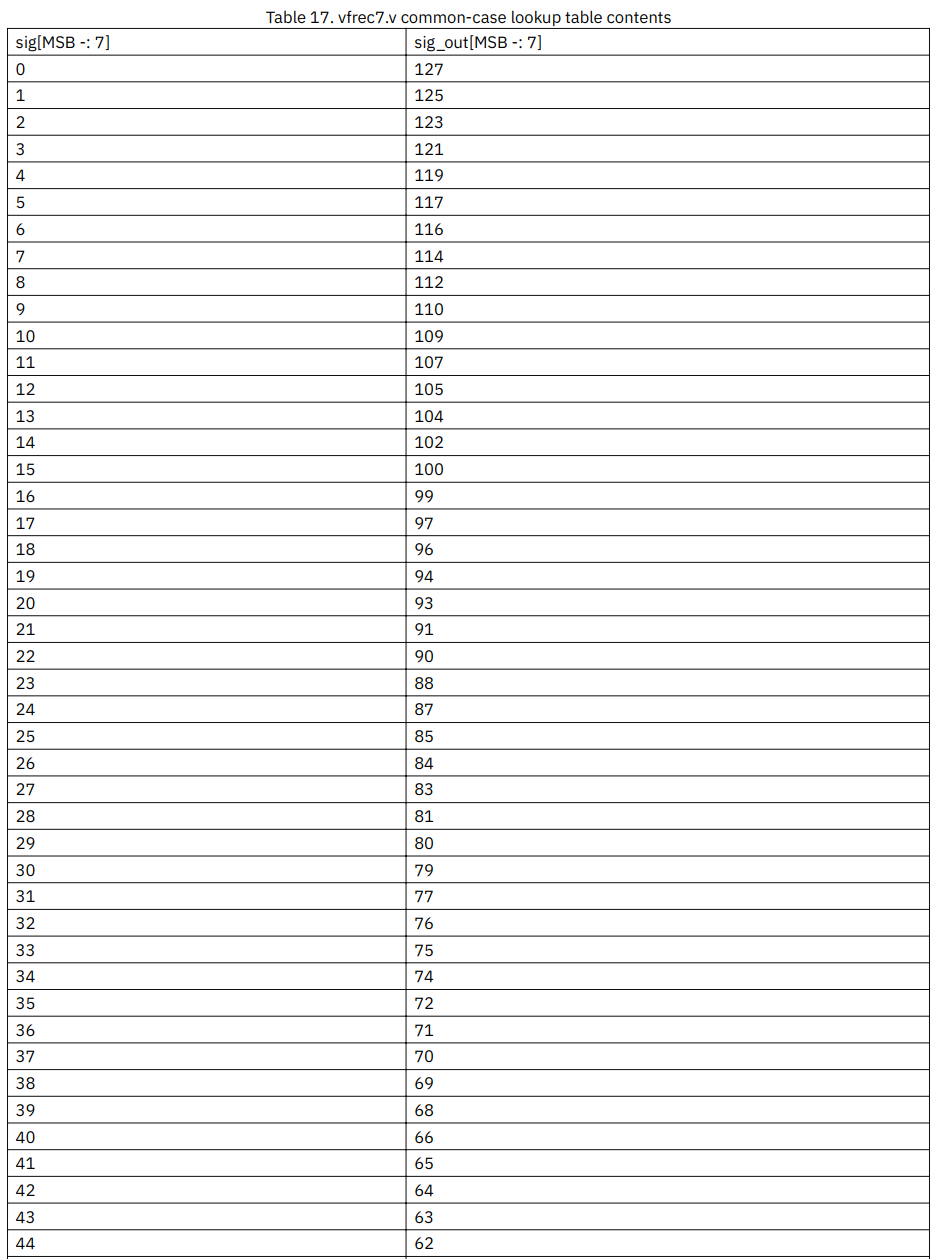
13.10. Vector Floating-Point Reciprocal Estimate Instruction
-
返回1/x的7bit估计值:
-

-
下表是所有可能的输出值:
-
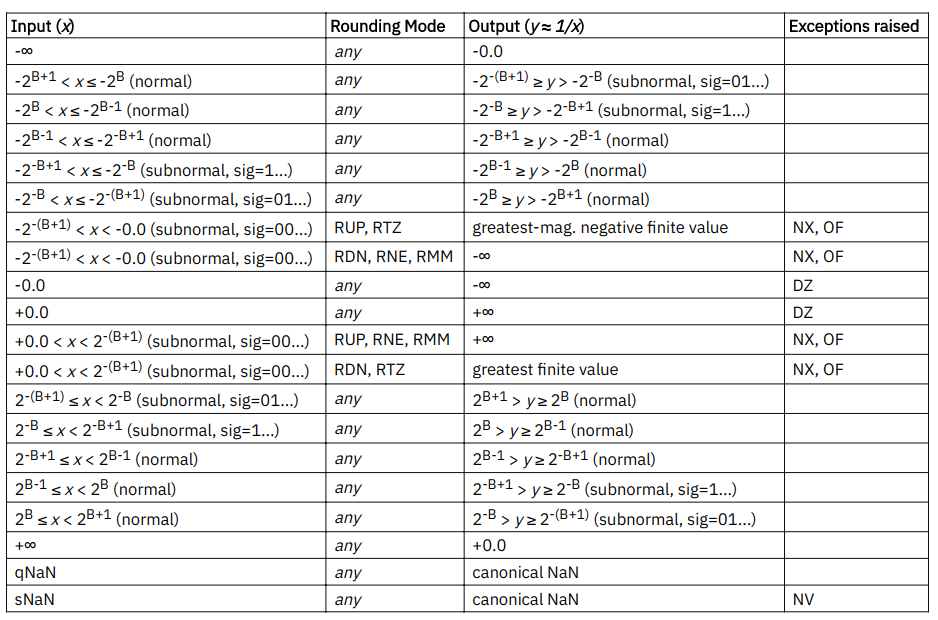
-
significand的高7bit(不包括最开始的1)索引查找表, 获得7bit的输出值:
-
-

-
13.11. Vector Floating-Point MIN/MAX Instructions

13.12. Vector Floating-Point Sign-Injection Instructions

- 该指令可以将vs1的符号与vs2的非符号部分进行组合
- 可以实现取相反数:vfneg.v vd,vs = vfsgnjn.vv vd,vs,vs.
- 可以实现取绝对值: vfabs.v vd,vs = vfsgnjx.vv vd,vs,vs.
13.13. Vector Floating-Point Compare Instructions



13.14. Vector Floating-Point Classify Instruction

- 该指令与标量classify操作相同
- 产生的10bit mask只占用结果元素的低位, 高SEW-10位为0
- 该指令只对SEW=16b以上的位宽有效
13.15. Vector Floating-Point Merge Instruction

- 是一条masked指令, 根据mask选择数据
13.16. Vector Floating-Point Move Instruction

- 将rs1对应的浮点数拷贝到vd
- 该指令等同于: vfmerge.vfm, but with vm=1 and vs2=v0.
13.17. Single-Width Floating-Point/Integer Type-Convert Instructions
- 将SEW宽度的浮点数转换成同宽度的整数(或者反过来)

- 转换时根据frm寄存器动态rounding
13.18. Widening Floating-Point/Integer Type-Convert Instructions

- 单宽度向双宽度的浮点-整数转换
13.19. Narrowing Floating-Point/Integer Type-Convert Instructions

-
- 双宽度向单宽度的浮点-整数转换
14. Vector Reduction Operations
- 归约指令接收一个向量寄存器组的元素,和一个放在向量寄存器元素0位置的标量, 通过某种归约操作得到一个标量值, 该标量值也放在一个向量寄存器的元素0位置.
- 归约操作中的标量都是放在一个向量寄存器中, 而不是响亮寄存器组.
- 之所以不把结果放在标量寄存器, 是为了与标量core 去耦
- 源向量寄存器组中的非活跃元素将不参与归约操作.
- 目的向量寄存器中, 除了元素0的部分都是tail, 遵循当前的尾部不可知或不变(tail agnostic/undisturbed)的原则.
14.1. Vector Single-Width Integer Reduction Instructions

- 溢出时, wrap around
14.2. Vector Widening Integer Reduction Instructions

- 在归约操作之前对向量元素位宽进行扩展, 从SEW-2*SEW
- 溢出时, wrap around
14.3. Vector Single-Width Floating-Point Reduction Instructions

14.3.1. Vector Ordered Single-Width Floating-Point Sum Reduction
-
ordered的指令必须按顺序对元素进行归约:
-

-
非活跃的元素不参与
14.3.2. Vector Unordered Single-Width Floating-Point Sum Reduction
- 指令汇编: vfredusum
- 无序指令需要实现与归约树等价的计算过程
- 每个节点接受两个操作数生成一个结果, 在计算时, 每个节点都是精确的(浮点的指数和小数部分都有无限精度), 得到精确的浮点结果后再规格化为SEW位的标准浮点数
- 每个节点的浮点数范围和精度可能都不同
- 实现时可以给最后的结果加上一个加法标志
- 当向下舍入(接近-∞)时,加法标识为0.0,或者对于所有其他舍入模式,加法标识为-0.0。
- 对于vtype和vl中的给定值,归约树结构必须是确定的。
14.3.3. Vector Single-Width Floating-Point Max and Min Reductions
- 浮点最大最小归约指令无论操作的顺序如何, 都应该返回相同的结果和相同的异常
- 如果没有活跃元素, 则vs1[0]会被复制到目的寄存器, 不会规格化NaN值, 也不会设置异常标志
14.4. Vector Widening Floating-Point Reduction Instructions

- 加宽的归约指令, vs2在进入归约操作时会加宽到2*SEW 位
15. Vector Mask Instructions
15.1. Vector Mask-Register Logical Instructions
-
这类指令是针对单个向量寄存器的(不是组), 因此会忽略vlmul的值
-
索引小于vstart的元素将保持不变. 执行指令后vstart会复位为0
-
mask logical指令都是unmasked的, 所以不存在非活跃元素, 并且总是遵循尾部不可知原则
-

-
一些伪指令:
-

-
上述8种逻辑操作可以产生16种任意的逻辑操作:

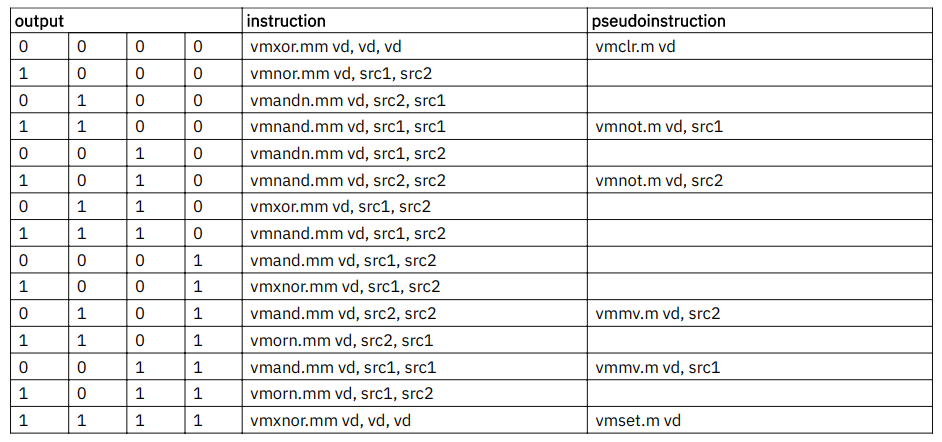
15.2. Vector count population in mask vcpop.m

- 该指令的源操作数vs2是一个包含mask值的响亮寄存器
- popcount, 该指令对vs2中活跃元素进行计数
- 可以在一个mask的指导下进行:
-

15.3. vfirst find-first-set mask bit

- 找到作为source mask的vs2中活跃元素的首个1, 并将其索引写入通用寄存器GPR。 如果vs2没有活跃元素, 写入-1到GPR
15.4. vmsbf.m set-before-first mask bit

- vmsbf.m指令接收一个mask向量寄存器作为输入, 将结果写入另一个向量寄存器
- 规则是: 首先将目的向量的所有元素写为1; 之后看源向量, 源向量的第一个为1的活跃元素的位置及其之后将目的向量元素都写成0
- 类似于leading one det
- 目的寄存器不能与源寄存器重合, 如果使用mask(vm=0), 目的寄存器也不能与v0重合。
15.5. vmsif.m set-including-first mask bit
- 与set-before-first 类似, 区别是第一个1的位置也要置1.

15.6. vmsof.m set-only-first mask bit
- 与set-before-first 类似, 区别是只有第一个1的位置要置1.

15.7. Example using vector mask instructions
- 下面是一个data-dependent exit loop向量化的例子:

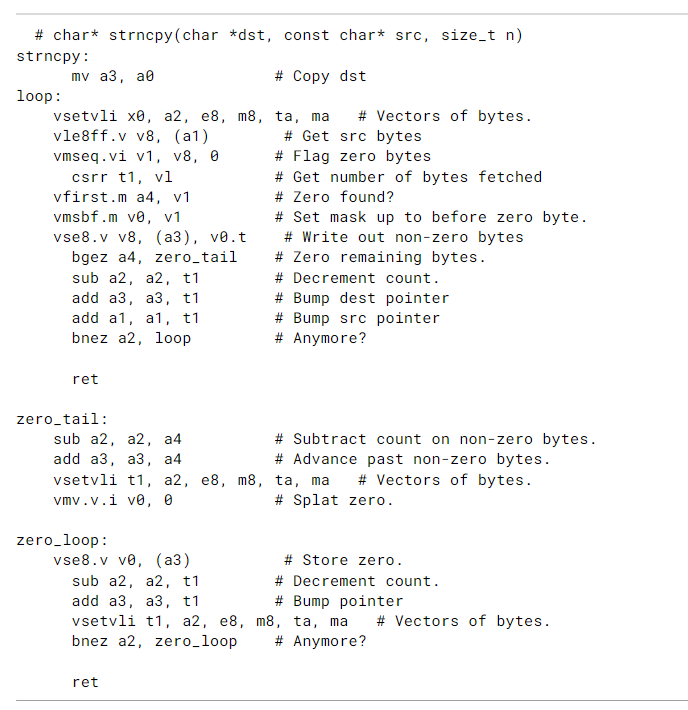
15.8. Vector Iota Instruction
- viota.m 指令读取源向量mask寄存器, 并向目的寄存器中依次写入元素。
- 写入的规则是: 索引值小于该元素的所有元素之和
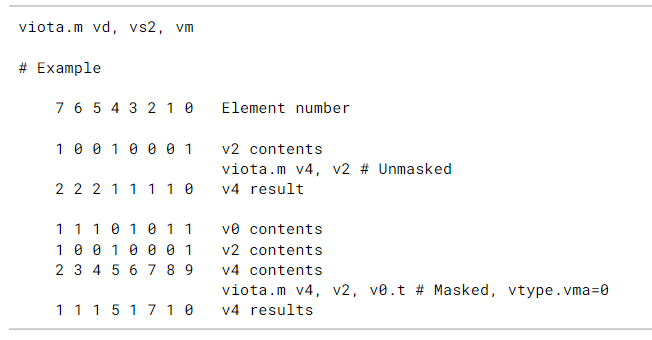
- viota.m指令可以与memory scatter指令组合以实现向量压缩方法:

15.9. Vector Element Index Instruction
- 将每个元素的index写到目的寄存器组

- vid.v可以用viota.m实现
16. Vector Permutation Instructions
16.1. Integer Scalar Move Instructions
- 该指令向vs2寄存器的第0个元素传入一个标量值

- 如果SEW>XLEN, 则只传输XLEN bit, SEW-XLEN个高位将被忽略;如果SEW< XLEN,则将有符号扩展到XLEN位
16.2. Floating-Point Scalar Move Instructions
- 与上一条指令类似, 只是换成了浮点寄存器:
-

16.3. Vector Slide Instructions
- slide操作比寄存器聚集指令更高效(gather)
- 2的幂次的slide会比较快
16.3.1. Vector Slideup Instructions

- offset可以由rs1指定, 也可以由立即数产生
- 从offset到vl的元素会被覆盖:
-

16.3.2. Vector Slidedown Instructions


16.3.3. Vector Slide1up


- 该指令要求目的向量寄存器组不能和源向量寄存器组有交叠
16.3.4. Vector Slide1down Instruction


16.4. Vector Register Gather Instructions

- vrgatherei16.vv form uses SEW/LMUL for the data in vs2 but EEW=16 and EMUL = (16/SEW)*LMUL for the indices in vs1.
- 当SEW=8时,每个vs1的元素只能索引256个数据。可能是不够的。所以增加了vrgatherei16指令,使用EEW=16, 可以索引64K的元素。另外,当SEW>16时,可能也是浪费的(没有那么多向量元素来给你索引),此时使用EEW=16也节省了向量寄存器空间
- 支持标量和立即数形式的gather指令:

- 此时只会从源寄存器读出一个元素
16.5. Vector Compress Instruction
- vs1是一个mask寄存器,可以使用vs1中=1的部分选择vs2的元素连续地放入vd
- vd中余下的元素遵循尾部不可知原则。


- vstart=0时, 该指令会上报陷入。vstart不为0时, 该指令会出发非法指令异常
16.5.1. Synthesizing vdecompress
- 该指令将一个压缩的向量按照mask还原

16.6. Whole Vector Register Move
- vmv<nr>r.v 指令可以拷贝整个向量寄存器或向量寄存器组到目的寄存器。
- nr值表示向量寄存器的个数
-

17. Exception Handling
- 在一条向量指令执行时发生了陷入(可以是异常或者中断触发的),则*epc CSR寄存器会被指向陷入发生的那条向量寄存器的指针所覆盖。此时vstart CSR的内容就是陷入发生时的那个元素的索引
- vstart CSR是用来允许恢复部分执行的向量指令,以减少中断延迟的。这类似于IBM 3090向量工具中的方案。如果没有vstart CSR,则实现必须保证整个向量指令总是可以在原子上完成,而不产生陷阱。所以vstart实际上允许向量指令在执行期间发生陷入,陷入处理结束后再从新的vstart处继续执行。这是因为很难保证在有stride load/store,scatter/gather操作以及按需分页的虚拟存储器的前提下保证向量指令的原子性。
17.1. Precise vector traps
- 精确的向量陷阱需要:
- 在陷入发生前的向量指令都需要已经提交了结果
- 比陷入向量指令更加新的指令不能改变架构状态
- 陷入向量指令中影响vstart之前的结果元素的任何操作都提交了它们的结果
- 陷入向量指令中影响vstart处或之后元素的任何操作都不会改变架构状态,除非重新启动和完成受影响的向量指令,否则这些指令不能正确更新架构状态
- 此处我们稍微放宽一些最后一条原则,修改为允许vstart之后的元素在陷入发生后被修改,因为实际上当陷入处理结束,重新从vstart处执行该向量指令时,这些元素就会被覆盖,所以问题不大
17.2. Imprecise vector traps
- 非精确的异常
- 新于*epc的指令可以提交结果,旧于*epc的指令可以未完成执行
- 不精确陷阱主要用于报告错误和终止执行是适当响应的情况。
- 专家可能会指定中断是精确的,而其他陷阱是不精确的。我们假设许多嵌入式实现只会为在致命(fatal)错误上的向量指令生成不精确的陷阱,因为它们不需要可恢复的陷阱。
- 在当前的标准扩展中,不支持使用不精确的陷阱。
17.3. Selectable precise/imprecise traps
- 一些专家可能会选择提供一个特权模式位来在精确和不精确的向量陷阱之间进行选择。不精确模式会在高性能下运行,但可能会使其无法识别错误的原因,而精确模式会运行得更慢,但支持错误的调试,尽管有可能不会经历与不精确模式相同的错误。
- 在当前的标准扩展中,不支持这种模式。
17.4. Swappable traps
- 另一种陷阱模式可以支持矢量单元中的可交换状态,在陷阱上,特殊指令可以保存和恢复矢量单元的微体系结构状态,以允许在不精确的陷阱周围继续正确执行。
-
- 在当前的标准扩展中,不支持这种模式。
18. Standard Vector Extensions
- 一组用于嵌入式使用的较小扩展用“Zve”命名。而为应用程序处理器设计的一个更大的向量扩展被命名为单字母V扩展。还提供了一个向量长度扩展,名为“Zvl”
18.1. Zvl*: Minimum Vector Length Standard Extensions
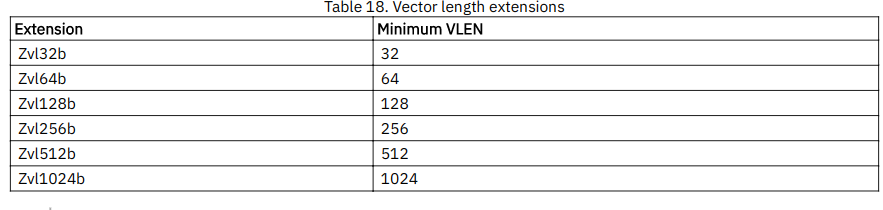
- 具有更长VLEN的扩展都向下兼容更小VLEN的扩展
18.2. Zve*: Vector Extensions for Embedded Processors
- 针对嵌入式领域:
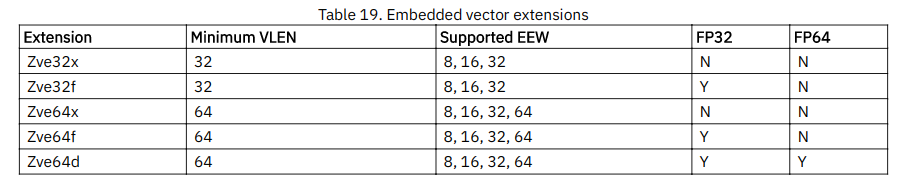
- 具有精确的陷阱
- 支持所有的向量load/store指令
- 支持所以向量整数运算
- 支持所有向量定点运算
- 支持所以向量整数单宽度和加宽/归约指令
- 支持所有mask指令
- 支持所有序列指令
- Zve32f和64f需要标量core支持F扩展或Zfinx扩展
- Zve64d需要标量core支持D扩展或Zdinx扩展
18.3. V: Vector Extension for Application Processors
- 单字一个V是应用级处理器的向量扩展
- misa.v 会被支持misa和vector的实现置位
- 具有精确的陷阱
- 需要Zvl128b
- 支持EEW=8,16,32,64
- 支持vset{i}vl{i}指令
- 支持所有的向量load/store指令
- 支持所以向量整数运算
- 支持所有向量定点运算
- 支持所以向量整数单宽度和加宽/归约指令
- 支持所有mask指令
- 支持所有序列指令
- 需要标量core支持F扩展和D扩展。并实现EEW=32/64的所有浮点向量指令及浮点归约和加宽指令。
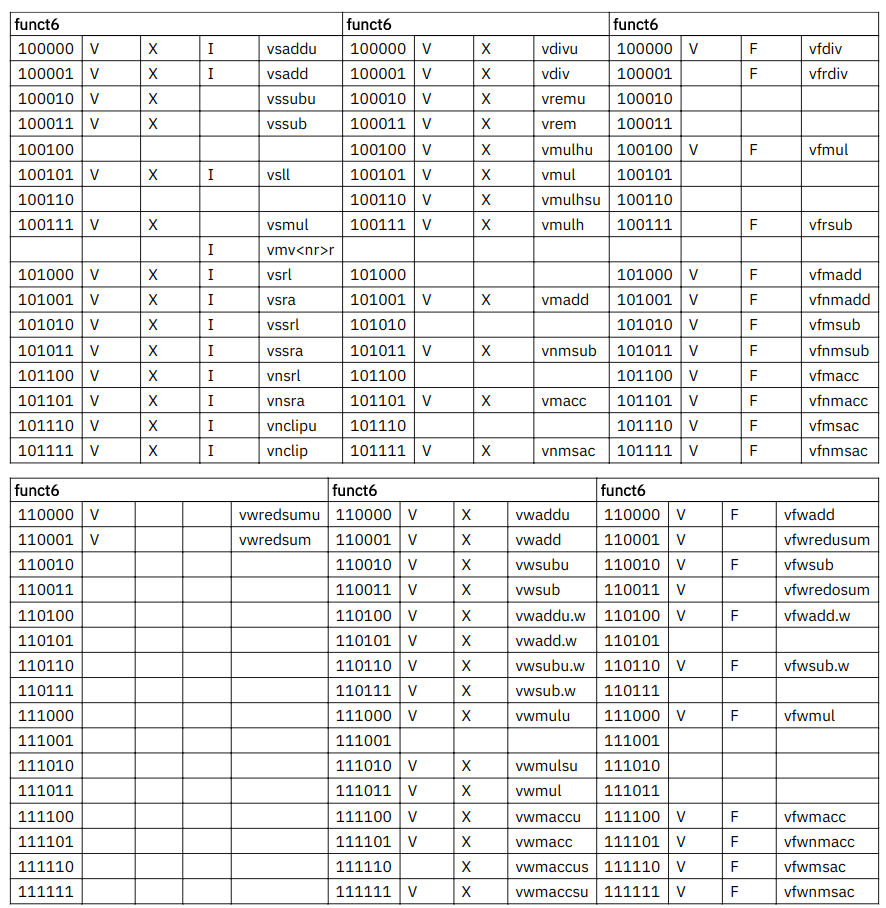
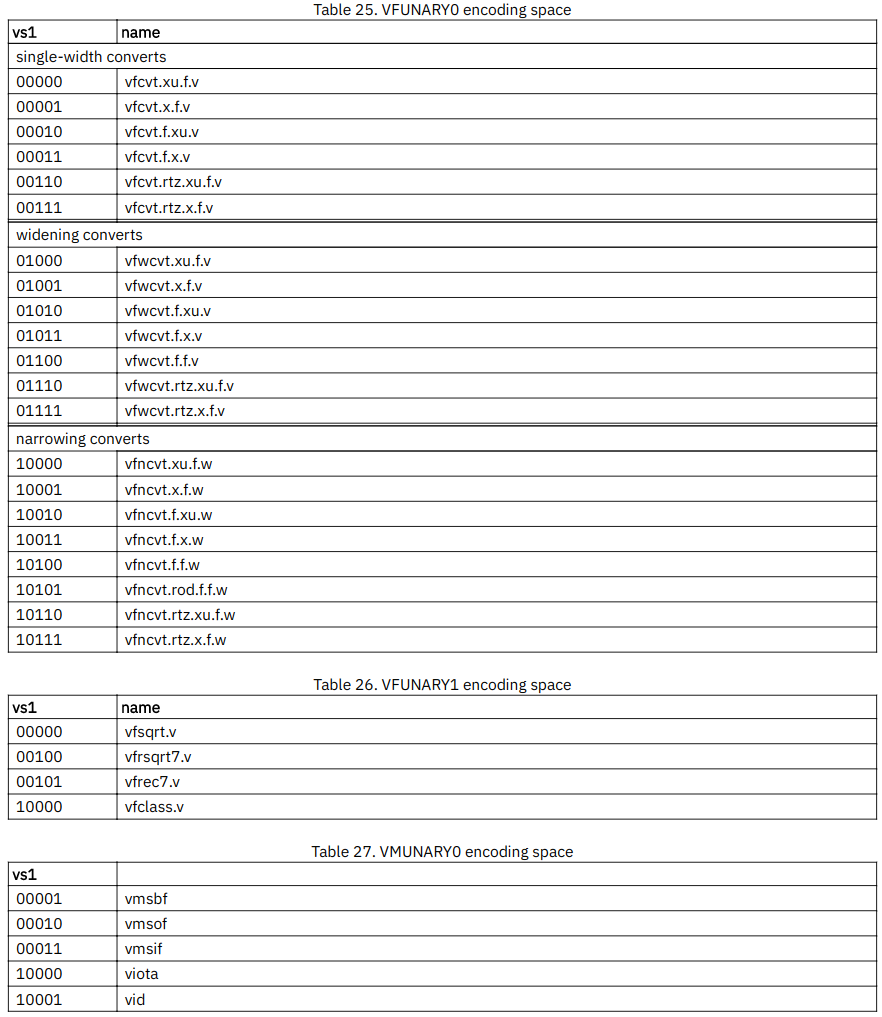
19. Vector Instruction Listing
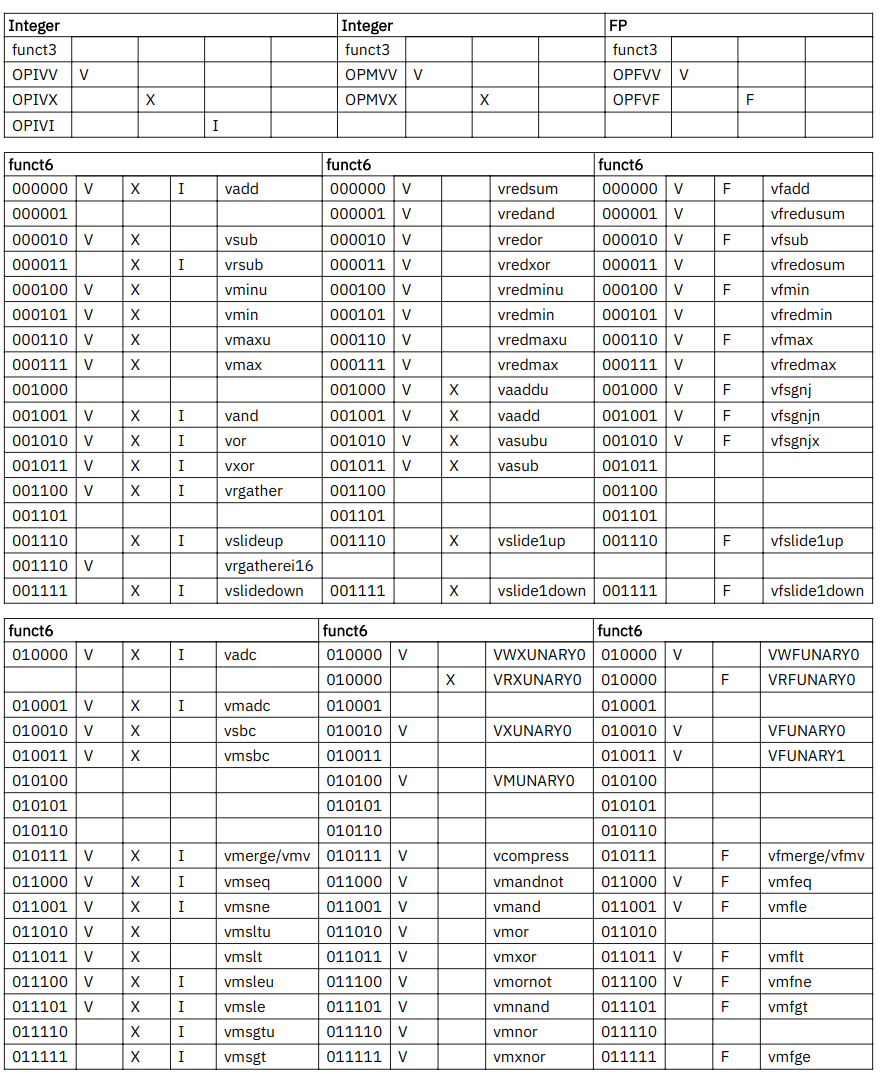

完结,撒花~
知乎:flappylyc - 知乎 (zhihu.com)
博客园: love小酒窝 - 博客园 (cnblogs.com)
CSDN:love小酒窝的CSDN博客-IC领域博主
公众号已开,了解更多相关内容可以扫一扫下方二维码~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号