
超标量处理器设计——第八章_发射
超标量处理器设计——第八章_发射
参考《超标量处理器》姚永斌著
8.1 简述
- 发射:将符合条件的指令从发射队列(Issue Queue)中选出来,送到FU中执行的过程。
- 重命名阶段的指令被写到ROB的同时,也会写到Issue Queue中
- 发射队列也称为保留站(Reservation Sation, RS)
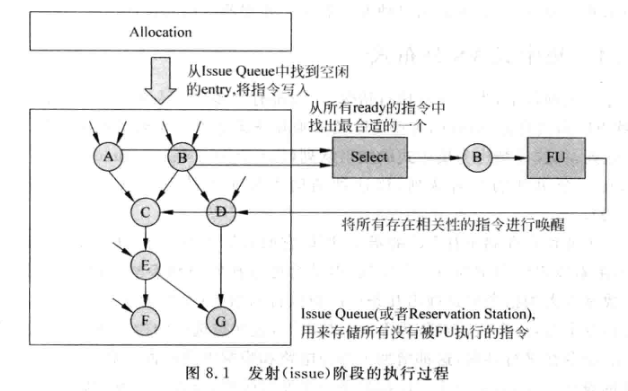
上图中的发射阶段涉及的硬件有:
- 发射队列(Issue queue)
- 分配电路(Allocation)
- 选择电路(Select)也叫仲裁(Arbiter)电路
- 唤醒电路(Wake-up)
后面会对这些电路一一进行介绍。
另外,发射阶段有很多实现方式,主要分为:
- 集中式(Centralized)和分布式(Distributed)
- 压缩式(Compressing)和非压缩式(Non-compressing)
- 数据捕捉式(Data-capture)和非数据捕捉式(Non-data-capture)
8.1.1 集中式 VS. 分布式
- 集中式:所有FU公用一个发射队列(Centralized Issue Queue, CIQ)
- 优势:容量大,利用效率高
- 劣势:选择和唤醒电路会变得复杂
- 分布式:每个FU都有一个单独的发射队列(Distributed Issue Queue, DIQ)
- 优势:容量小,选择电路简单(每个FU对应一个选择电路即可)
- 劣势:
- 指令分布较为分散,唤醒电路需要较多布线资源;
- 效率低,会有“木桶效应”,只要一个队列满,就不能写入新指令,需要将发射之前的流水线都暂停。
实际现代处理器会结合上述两个方法,有些FU公用一个发射队列。其他用各自的发射队列。
8.1.2 数据捕捉 VS. 非数据捕捉
-
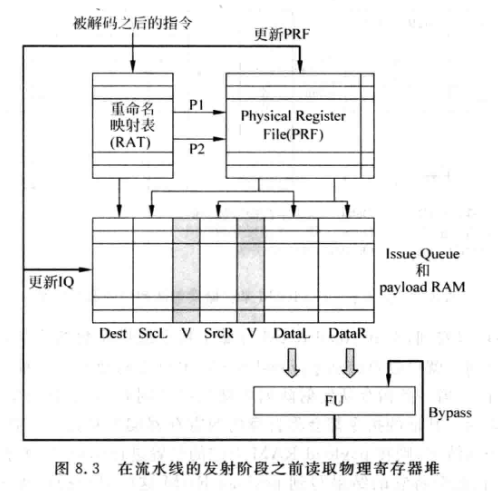
数据捕捉式:在流水线发射阶段之前读取寄存器。
-
寄存器重命名后的指令先读PRF,将读出值与指令一起写入IQ。
-
如果有寄存器的值还没计算出来,那就写入寄存器编号,供唤醒使用。且会标记为Non-available。
-
发射队列中存储指令操作数的地方是payload RAM:
-

-
payload RAM存储了指令的源操作数,当指令从IQ中被仲裁电路选中(grant),就会去payload RAM里取源操作数送到FU执行。
-
当指令被select时,会将自己的目的寄存器编号广播给IQ中的其他指令,有相等的话会在payload RAM中相应位置做标记,表示这些指令的源操作数会用到该指令的目的寄存器值。
-
当目的寄存器的值经过FU计算出来,就会经过bypass网络来更新payload RAM中做了标记的位置。
-
这种方式像是payload RAM在捕捉FU计算的结果,所以称为数据捕捉(data-capture)。注意从payload RAM中读取数据时指令还没离开发射队列。
-
工作流程:
-
-
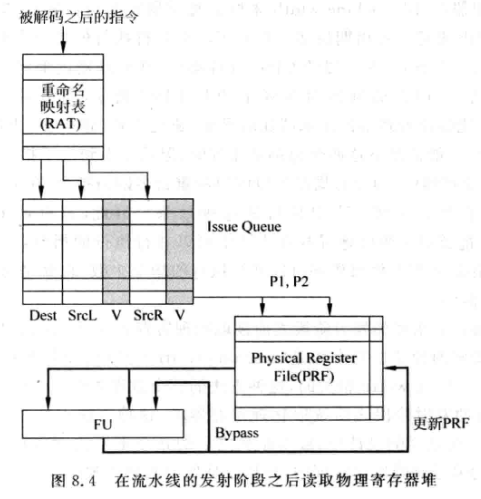
非数据捕捉式:在发射阶段之后读取物理寄存器。
-
重命名后的指令不读物理寄存器堆,而是直接将源寄存器编号一起送入IQ。
-
工作流程:
-
-
因为发射时才会读物理寄存器堆,所以寄存器堆的读端口个数是issue width*2, 一般会比较大, 相较于在发射阶段之前读取寄存器来说,这种方式读端口会更多
-
对比:
- 数据捕捉式需要的寄存器读端口较少,但是要在IQ中存储操作数,所以IQ面积会大些.
- 数据捕捉式的源操作数要经历两读一写, 需要从寄存器内读出来,写到IQ的payload RAM, 之后再从IQ读到FU, 因此功耗会大.
- 非数据捕捉式需要的寄存器读端口多,但IQ不用存操作数,所以IQ面积小,速度也快些, 且源操作数只要读一次,功耗也会低一些.
应用:
- 两种方式与寄存器重命名的实现方式直接相关.
- 如果用ROB进行寄存器重命名, 一般都会用数据捕捉式, 因为此时指令退休时会将结果从ROB搬运到ARF, 用数据捕捉方法不用关心目的寄存器位置的变化,因为指令结果会存到payload RAM中
- 用非数据捕捉式需要关注指令结果的位置变化.
8.1.3 压缩 VS. 非压缩
-
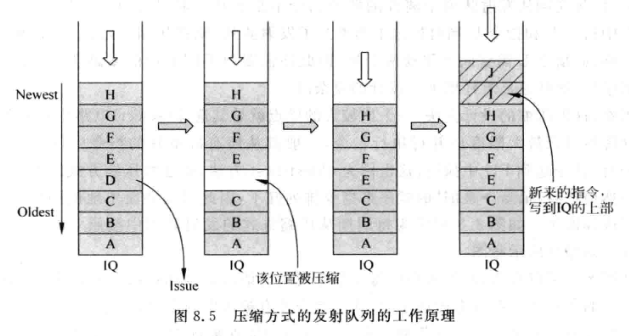
压缩式(Compressing Issue Queue)
-
给个图自行体会一下:
-
-
简单来说就是发射出去的指令空出来的位置会被后面的质量补上
-
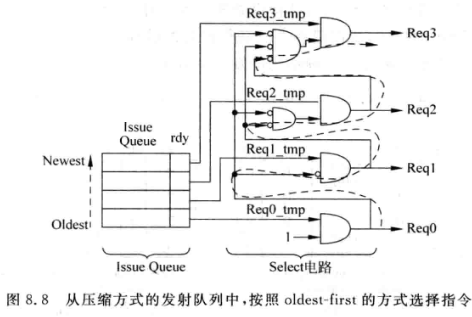
一种电路实现结构如下, 这种结构只能实现靠在一起的指令发生的压缩:
-

-
压缩的IQ选择电路比较简单
-
选择电路一般会从IQ中准备好的指令选择一条最旧的指令发射,称为oldest first方法.
-
压缩式的IQ天然地按照最新->最旧的顺序排列,因此只需要用优先级编码器就可以实现选择电路, 结构如下:
-
-
优点:
- 分配(Allocation)电路简单, 因为空闲空间总是处于上面,所以只需要用发射队列的写指针指向地一个空闲地址即可
- 选择电路简单, 上文已经提到了
-
缺点:
- 费面积, 当一次发射多条指令, 且发射的指令不靠在一起, 需要复杂的布线和MUX逻辑.
- 功耗大, 因为每个周期都要移动IQ的内容来进行压缩, 移动的项很多.
-
-
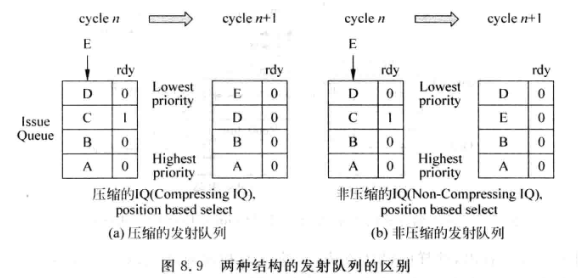
非压缩式(Non-Compressiong Issue Queue)
-
发射出指令后IQ中其他指令不移动,也就是不进行压缩
-
与压缩式的区别:
-
-
IQ中的指令不再有最新到最旧的顺序, 因为发射出指令后的空档可能被新指令填满, 此时从下到上就没有顺序关联了.
-
虽然也能让选择电路仍然按照从下到上取指令,但是因为没有oldest first, 所以对RAW相关性的指令就不能最大限度地释放.
-
优点:
-
- 功耗小,面积小
-
-
缺点:
-
- 要实现oldest-first需要更复杂的电路,延时更大.
-
- 分配电路比较复杂,需要扫描所有空闲空间
-
-
8.2 发射过程的流水线
8.2.1 非数据捕捉结构的流水线
进入到IQ中的指令要被FU执行,必须满足:
- 这条指令所有的源操作数都准备好了
- 能够从发射队列被选中(需要经过仲裁电路允许)
- 需要能够从寄存器、payload RAM或旁路网络中获得源操作数
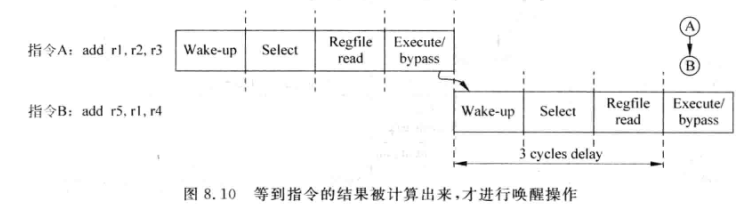
下面是一条指令从旁路网络获得源操作数的示意图:
-
上图的方法实际上在上世纪六七十年代就提出了,名字叫tomasulo算法。
-
但是这种方法效率不高,实际上具有RAW相关性的指令可以这样做:
-
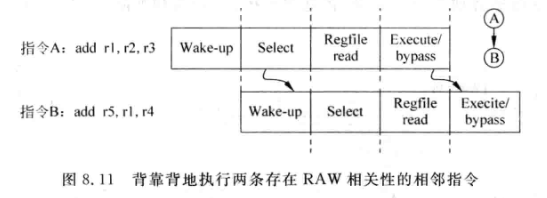
-
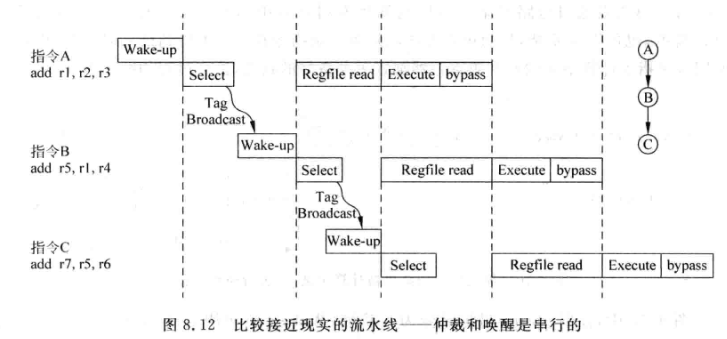
更接近显示的是下面的示意图:
-
-
仲裁(Select)负责从发射队列中找出一条合适的指令。
-
唤醒(Wake-up)负责将发射队列中相关寄存器置为准备好的状态。
-
为了使RAW相关的指令背靠背执行,需要保持仲裁和唤醒在一个周期内做完
-
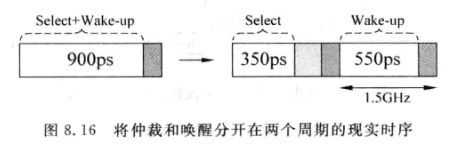
仲裁和唤醒电路相对比较复杂,一个周期做完会对频率有影响。如果将两步分两拍做,虽然能提升性能,但是会影响IPC:
-
-
上图中假设原始频率为1GHz, 每周期可执行两条指令,则IPC=2
-
当仲裁和唤醒拆分后,指令之间就不能背靠背执行,假设使IPC下降了15%,变成了2*0.85=1.7, 但是频率变为2GHz, 每秒指令数提升到.3.4G, 提升了85%
-
但是实际上拆分后延时不能均分,所以达不到2GHz, 可能就1.5GHz,这样速度提升就变为了27.5%
-
此外还会引入一些负面影响:
- 分支预测失败的惩罚加大
- cache访问周期数增加(因为周期变小了)
- 增加一级流水线,功耗增大
-
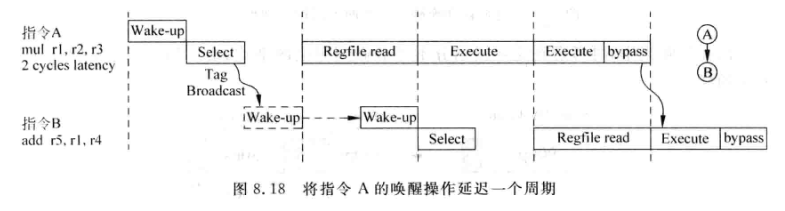
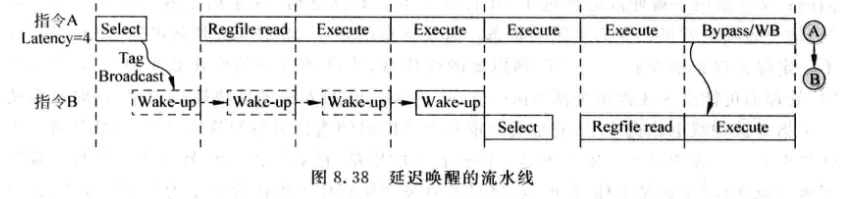
当FU需要多周期才能算完时,需要将唤醒延迟:
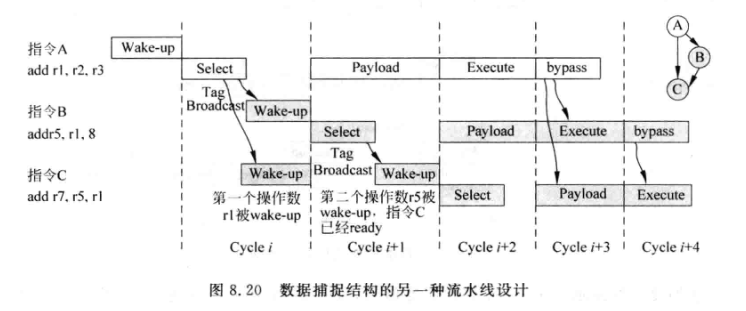
8.2.2 数据捕捉结构的流水线
- 与非数据捕捉型最大的区别是发射队列中采用了payload RAM存储所有指令的源操作数。而不需要读寄存器堆。
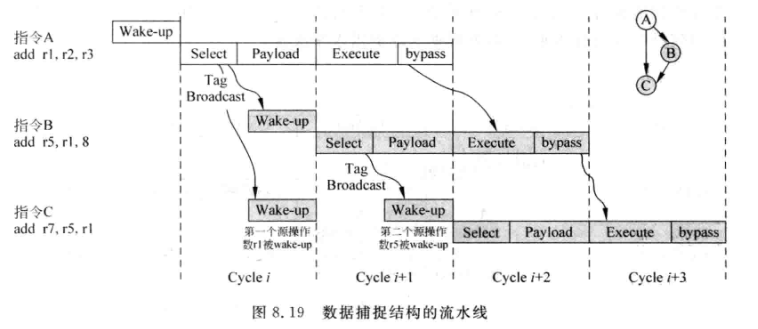
- 指令在被仲裁电路选中之后,同周期也会堆发射队列的其他指令进行唤醒;同时还会读取payload RAM; 两个操作是并行的
- 不一定所有指令都要从payload RAM读取操作数,也可以从旁路网络读取。
- 该流水线payload RAM在同一个周期既要被读又要被写,延时是比较大的,可以让他单独占一级流水线
8.3 分配
-
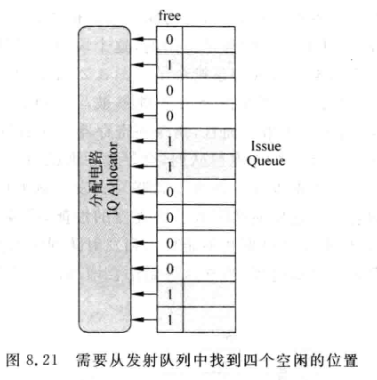
对于非压缩的发射队列,空闲的空间是没有规律的
-
分配电路需要从IQ中找出4条(4-way处理器)空闲的表项写入重命名后的指令
-
如下图所示,分配电路需要根据IQ的free bit位选择4个空位:
-
-
一次性处理所有的free bit对发射电路来说是较大的负担,可以采用分治的方法:
-

-
上面的分治方法弊端也很明显,如果某一组没有空闲位,可能会出现一条指令阻碍其他指令写入IQ
8.4 仲裁
8.4.1 1-of-M的仲裁电路
-
仲裁电路的一个主要工作就是落实oldest-first的仲裁效果。先执行旧的指令可以唤醒更多指令
-
对于非压缩的IQ, 由于指令在IQ中的年龄不一定跟位置直接相关,所以不能根据位置来选择。
-
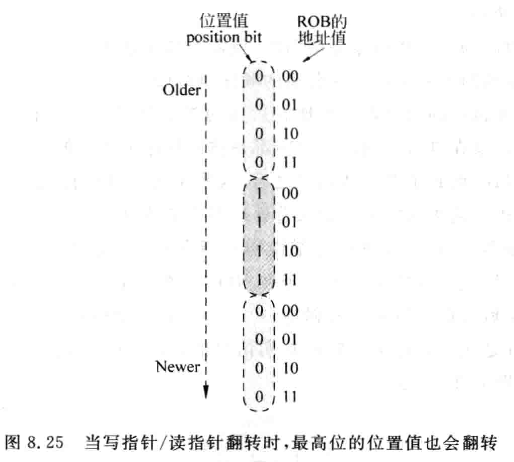
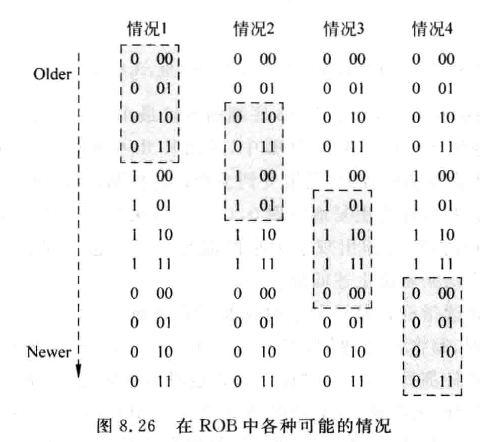
在ROB中保留了指令的顺序,因此可以使用每条指令在ROB中的位置作为该指令的年龄信息。但是由于ROB是一个FIFO,其读写指针地址会翻转,所以不能简单地根据地址来判断:
-
需要在ROB地址再加上一位,称为“位置位”
-
-
-
可以发现:
- 位置位相同时,ROB地址越小,指令越旧
- 位置位不同时,ROB地址越大,指令越旧
-
-
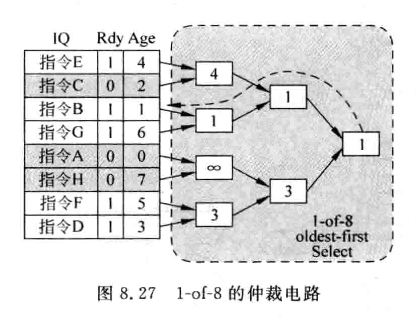
ROB中的年龄值需要写入IQ中,供仲裁电路使用,找出年龄最旧的指令。例如下面就是一个1-8的仲裁电路,采用二分的方式实现:
-
-
实际IQ中会存在没有准备好的指令,仲裁时需要加以屏蔽,可以为IQ的表项增加一个ready位,当两者ready位均为1时,才会比较选择年龄值小(对应最旧的);两个ready均为0时,会将输出级的ready置0;有一个ready为0时,选另外一个输出。
-
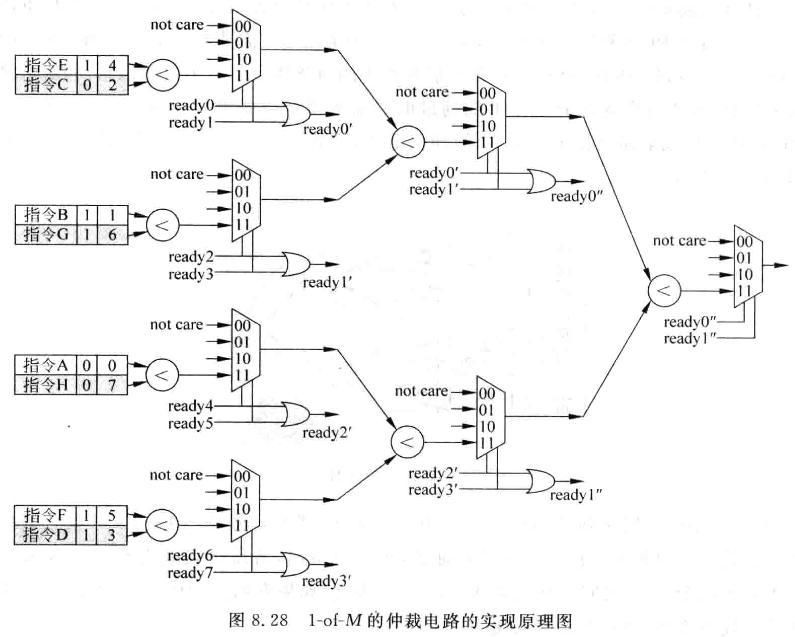
-
找到年龄最小的指令时,最好将该指令在IQ中的地址也跟随着送出:
-
-

8.4.2 N-of-M的仲裁电路
-
近似的N-M仲裁电路:
-
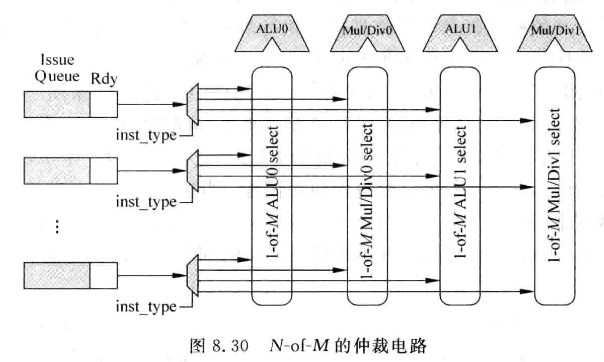
-
每个FU都有一个1-M仲裁器,IQ中的表项根据所属的指令类型选择送到那个FU的1-M仲裁器中。
-
这种方式的限制是,如果要实现5-M仲裁,但是只有4个FU时,最多只能实现4-M仲裁
-
例如下面的这种情况: IQ每次可以发射2条ALU指令, 如果只有一个ALU和1-4仲裁器,没法实现2发射,所以增加一个ALU. 并增加一个ALU分配位, 每次进IQ的指令都会带上这个分配位, 且分配位每周期都会翻转,从而实现轮换使用两个ALU的目的. 但是轮换的方式也有问题:
-
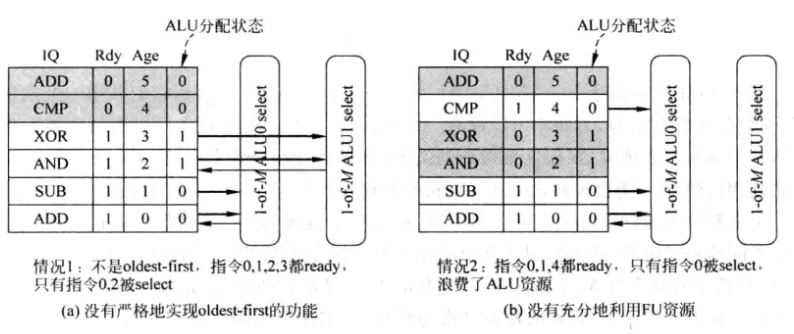
-
左图: ADD和SUB同一周期来, 分配状态=0,被送入第一个ALU;AND XOR下一周期来,状态=1, 送入第二个ALU. 经过select后, 可能ADD和AND最终被发射,但是实际上并没有满足严格的oldest-first, 因为SUB比AND跟旧
-
右图: 如果某次解码出3条ALU指令,同周期进入IQ, 那么他们都属于ALU0, 同时准备好, 此时ALU1就被闲置了.
-
8.5 唤醒
8.5.1 单周期指令唤醒
-
唤醒是指被仲裁电路选中的指令将其目的寄存器编号和IQ中所有源寄存器编号进行比较,并将结果想等的源寄存器进行标记的过程(标记为ready)
-
唤醒电路如下:
-
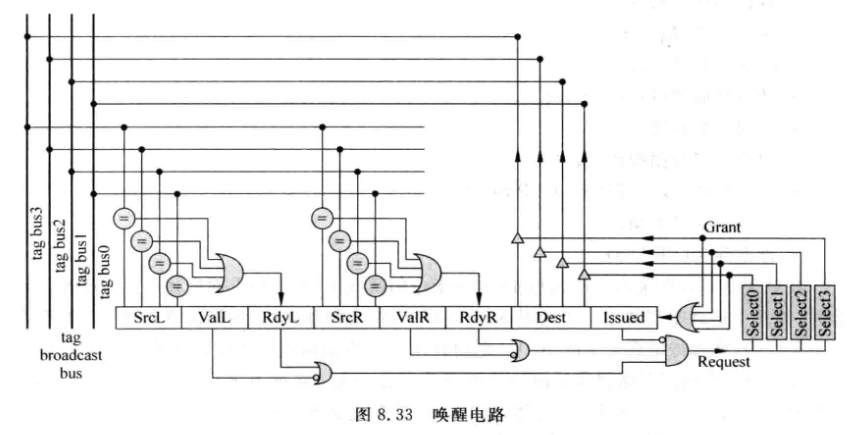
-
VAlL/R: 指令中是否有第一/二个源寄存器
-
RdyL/R: 指令中第一/二个源寄存器是否已经被唤醒
-
Issued: 指令被仲裁电路选中后,可能不会马上离开IQ, 用该位进行标记, 这样后续他将不会再向仲裁电路发出请求信号.
-
一条指令的源操作数都ready后,才会向仲裁器发出req, 仲裁器仲裁后给出结果grant. 上图中4个grant信号实际只会有一个有效.
-
Grant只要有效, 该指令就被标记为issued
-
被issued的指令会将自己的dest寄存器地址广播到tag bus上,用来唤醒其他指令的src
8.5.2 多周期指令的唤醒
- 单周期的唤醒中, 一条被仲裁器选中的指令能在本周期对IQ中其他源寄存器进行唤醒,前提是这条指令在一个周期内能被FU执行完.
- 当指令无法在单周期执行完, 需要将唤醒过程进行延迟
- 唤醒实际分两个步骤:
- 将被选中指令的目的寄存器编号送到总线
- 将总线上的值和发射队列所有源寄存器编号进行比较
- 两个步骤都可以延迟,衍生出两种方法:
- 延迟广播: 如果仲裁电路选中的指令执行周期大于1, 则在当前周期, 并不将该指令的目的寄存器编号送到总线, 而是根据执行周期数N, 延迟N-1个周期后送到总线.
-
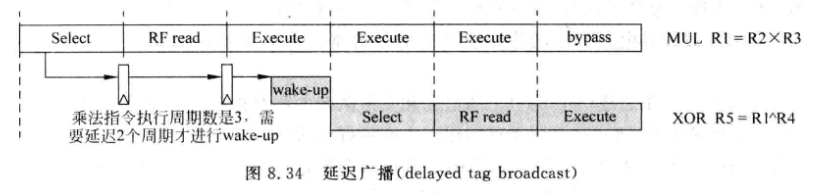
-
问题: 如果两条指令共用一个FU, 可能一条经过延迟唤醒后与下一条竞争总线:
-
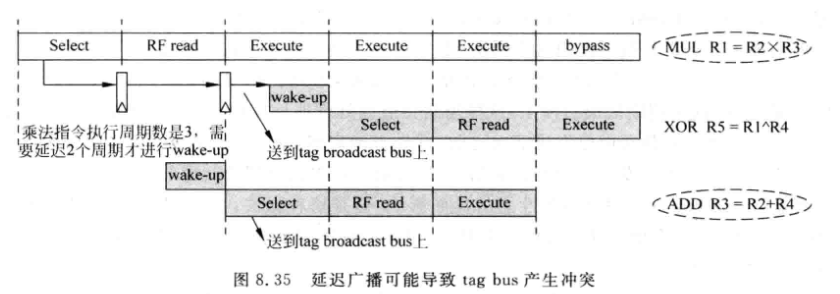
-
可以记录FU中执行指令所需的周期数, 后续仲裁电路选中时, 如果发现表格中之前记录的指令会跟当前指令冲突, 则本次仲裁不选中该指令. 等下个周期再次仲裁
-
- 延迟唤醒: 延迟N-1拍将ready置1
-
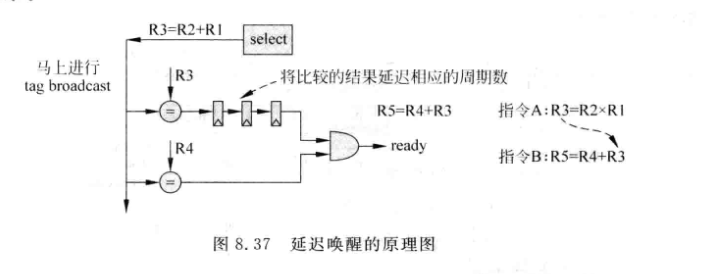
-
-
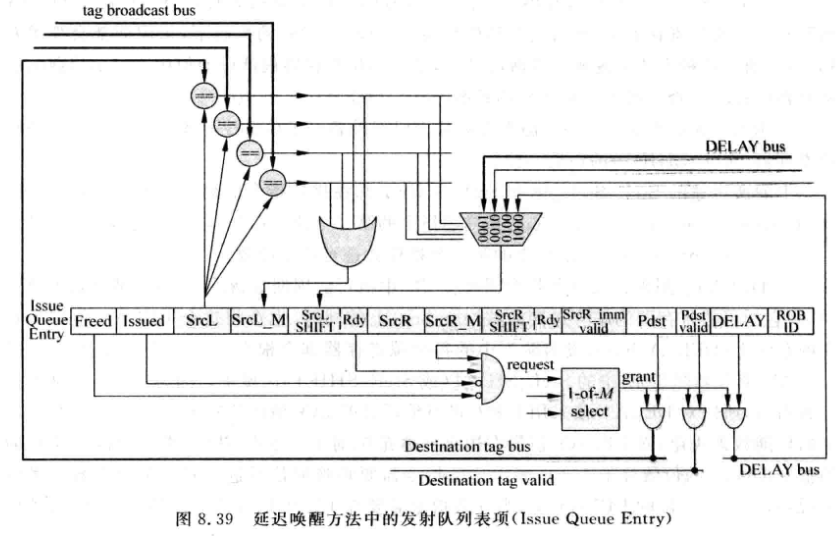
可以在ready状态位之前加入控制电路控制延迟的周期数,下面是一种实现方式:
-
-
其中:
- freed: 表示表项是否空闲, 当一条指令写入时,表项就不空闲了, 而当指令被仲裁电路选中时, 并确定没有问题, 可以离开发射队列,此时就可以变为空闲
- SrcL._M: 寄存器编号比较结果相等时, 该位会置1. 当仲裁电路给出响应信号, 清零. 他是移位寄存器SrcL_SHIFT的时能
- SrcL_SHIFT: 移位寄存器, 当寄存器编号想等时, 会将对应的Delay写到移位寄存器中, 然后在SrcL._M的控制下每周期算数右移一位, 其最低位等效为ready位
- ROBID: 该指令在ROB中的位置,也就是年龄信息
-
- 延迟广播: 如果仲裁电路选中的指令执行周期大于1, 则在当前周期, 并不将该指令的目的寄存器编号送到总线, 而是根据执行周期数N, 延迟N-1个周期后送到总线.
8.5.3 推测唤醒
-
DELAY值并不都是固定的:
-
Load指令: 周期数取决于D-Cache是否命中:
-
-
某些特殊情况, 允许FU结果提前得到(early out). 例如被乘数位数比较小时, 乘法结果可以提前得到
-
-
一种办法是等到指令执行完毕的到数据时, 才将目的寄存器编号送到总线上唤醒其他指令:
-
-
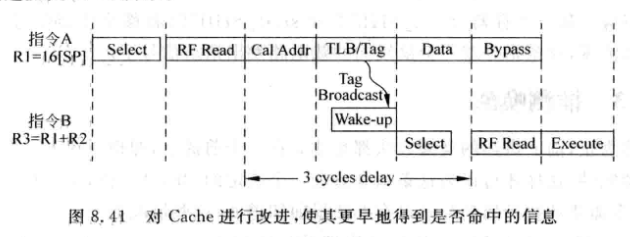
上图可以进行改进, 因为Cache是否命中是可以提前知道的, 所以可以将wake提前:
-
-
更为激进的方式是: 假设DCache总是命中, 也就是推测唤醒(speculative wake-up):
-
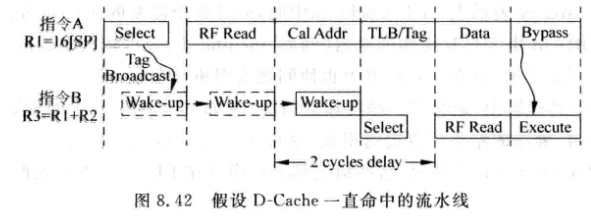
-

-
如果L1-Cache缺失:
-
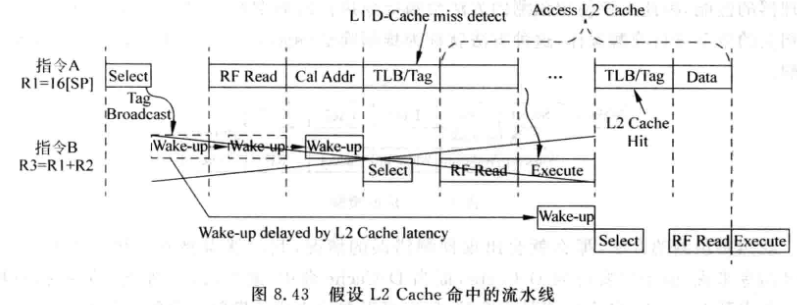
-
还需进行状态恢复, 将被load误唤醒的寄存器置为非ready, 如果一些指令离开了IQ,还需要将他们从流水线中抹除,重新放回IQ
-
-
Independent WIndow(IW) 和Speculative Window(SW):
-
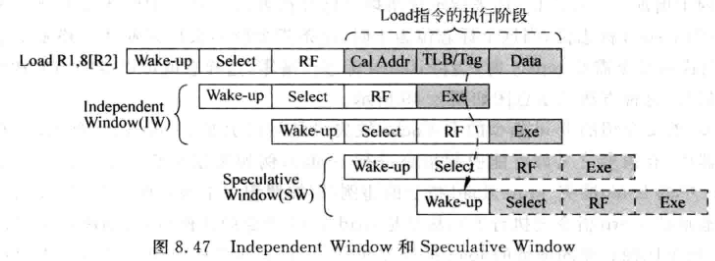
-
IW是load指令被仲裁器选中到执行间隔的时间. 在这个时间内可以放入一些跟本条load无关的指令.
-
SW是指load指令开始执行到它发现自身是否会DCache命中/缺失的周期数. 在该窗口可以放入一些跟load无关或相关的指令
-
-
当发现D-Cache缺失时, 和load指令有相关性的指令需要重新被放回发射队列等待唤醒, 就需要这些指令重新在发射队列中变为not ready的状态, 并重新向仲裁电路发出申请, 这个过程称为replay.

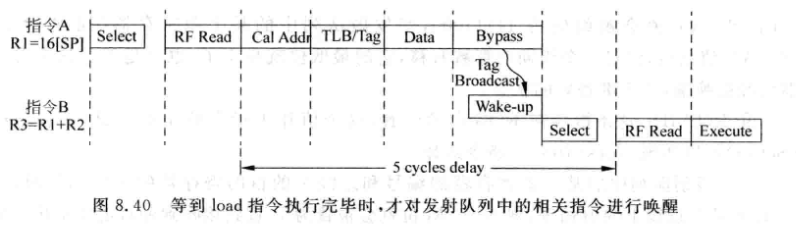
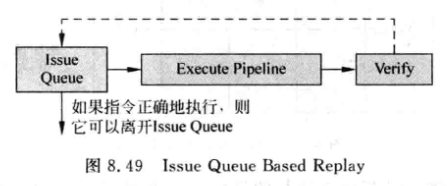
1. Issue Queue Based Replay
-
这种方式中, 指令被选中之后不会马上离开IQ, 而是将issued置为1.
-
issued =1的指令不会再向仲裁电路发出请求
-
当该指令需要replay时, 会将issued清除.
-
D-Cache缺失, 交叠结构D-Cache的bank冲突, store/load指令的违例, load/load的违例都可能引发replay
-
在完全乱序机中, 只有指令退休时指令才能离开IQ, 在顺序或部分乱序机中, SW中的指令才可能被replay
-
-
由于大部分指令都不会replay, 但是他们却仍然占着毛坑, 是及浪费了IQ的容量, 会降低性能
Non-Selective Replay
- 将load指令之后被仲裁电路选中的指令都重新放回发射队列
- 简单,但无差别地选择浪费了性能:
-
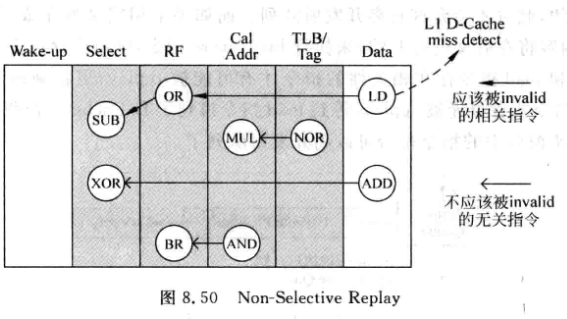
-
上图中,Data阶段LD指令发现D-Cache miss, 此时需要把图中所有指令都抹掉
-
但是实际上, 只有OR和SUB指令真的跟LD有相关性, 应该replay, 其他指令不应该被replay
-
改良: IW窗口中的指令, 肯定跟本LD无关, 不需要被replay, 也就是途中的MUL和NOR
-
Load-Vector
- replay时需要找出跟LD存在相关性的指令, 怎么找? 一种方法是Load-Vector:
-
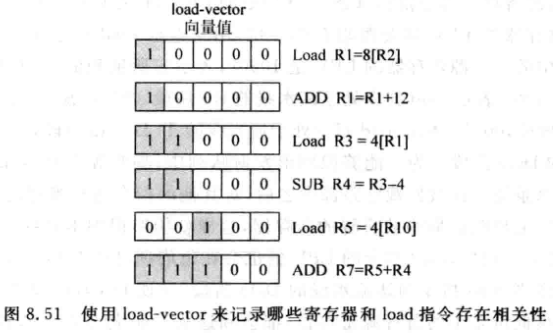
- 每个物理寄存器都有一个load-vector, 对于非load指令, 如果它有目的寄存器, 那么目的寄存器的向量值=两个源寄存器的向量相或
- 向量的宽度跟流水线深度相同
- 对于load指令的向量值, 除了来自于源寄存器, 还会占用向量的一个新位
- 实现方式是一个表格, 表项个数为物理寄存器个数, 指令在寄存器重命名后会访问该表, 或的源寄存器的向量, 并更新目的寄存器向量
- 当发现一条load产生了D-Cache miss, 就可以根据该load在向量值中对应的位来找到跟他相关的寄存器, 将他们置为not ready
- 流水线不深时, 这种方法是可以的, 但是流水线很深时, 向量值的宽度也会增加, 会导致更大的硬件资源消耗, 也会增大IQ的延迟
-
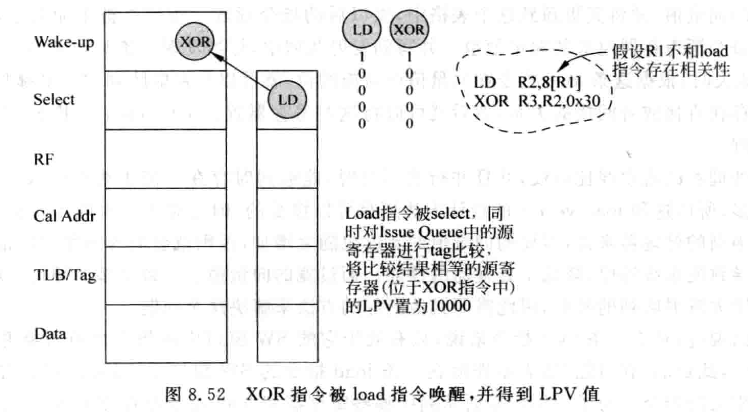
Load Position Vector(LPV)
- load-vector消耗的资源较多,LPV则试图借助延迟唤醒的操作,找到与load指令相关的指令。
- load指令使用一个5位的值,表示该load指令处于流水线的哪个位置(select,RF, Cal Addr, TLB/Tag, Data), 该值称为Load Position Vector (LPV)
- 每当一条load被仲裁电路选中, 会将他的LPV置为10000, 表示这条指令处于Select阶段。之后会将load放到总线上唤醒与IQ中所有源寄存器比较,如果结果相等,该源寄存器会获得该LPV
- 每个周期,IQ中所有源寄存器的移位寄存器会因为延迟唤醒而右移,同样,该寄存器捕获的LPV也会右移一位, 来追踪load在流水线中的状态。
- 为了检查间接相关性,每条指令在唤醒其他指令时,会将LPV传递给其他指令的源寄存器
- load指令的LPV也会不断右移,这样当load运行到data阶段发现D-Cache缺失, 就去IQ中寻找LPV最低位是1的所有源寄存器,这些寄存器就是与load存在直接或间接相关性的,需要置为not ready
- 下面几张图展示了LPV传递这一过程:
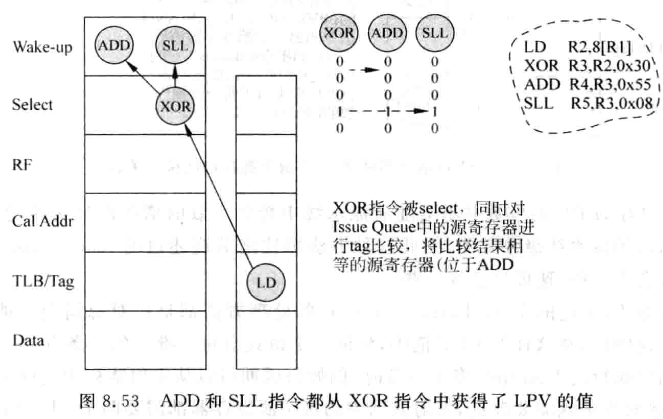
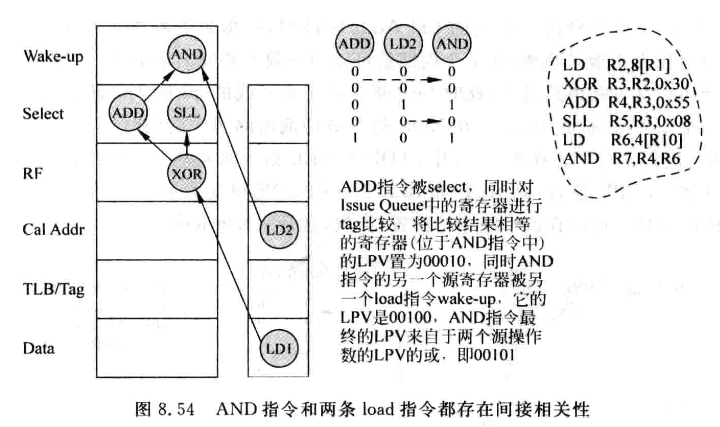
- LPV的位数不会随流水线中指令个数增多而显著增大,而是只跟load执行的流水线级数有关。会比load-vector资源少些,速度快些
- 如果每周期可以处理两条load指令,那么需要设置两个LPV值,分别记录两条load的位置。但是D-Cache的端口不会很多,所以每周期可执行的load不会很多
小结:
- Non-selective Replay实际是在load发现D-cache缺失时,将SW窗口中的指令从流水线中抹除,
- Selective Replay则结合LPV等方法选择性地将有关联的指令抹除
- 之后这些指令重新放回IQ,等待重新唤醒。
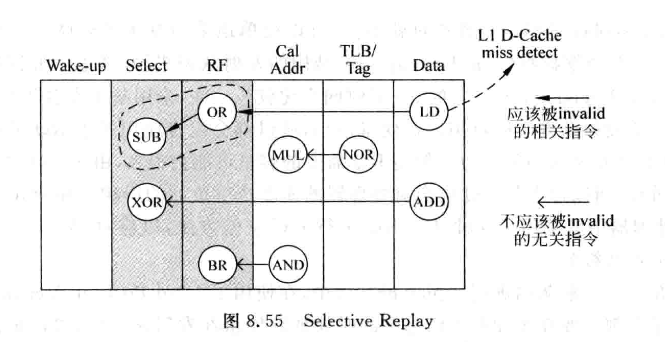
基于IQ进行replay方法的缺陷
- 基于IQ进行replay的方法中,很多指令在被仲裁电路选中后不能马上离开IQ, 会降低发射队列实际可用的容量,使得处理器无法最大限度寻找并行性
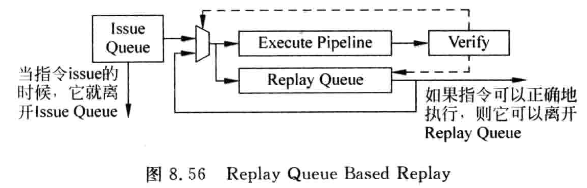
2. Replay Queue Based Replay
-
为了提高IQ的利用率, 这种方法中,指令被仲裁电路选中后,会马上离开发射队列,但不会消失,而是进入另一个部件Replay Queue(RQ)
-
-
当一条指令被验证执行正确,例如退休时,才能离开RQ
-
如果load发现D-Cache缺失,除了将相关指令从流水线抹除, 还要将这些指令在RQ中再次唤醒,并向仲裁电路发出请求,他们相比IQ中的指令有更高的优先级。
-
一般从流水线Select到Execute需要的周期越多,replay的指令也越多。对于数据捕捉结构的IQ,S-E时间短,所以可以用基于IQ的replay方法;而对于非数据捕捉结构,S-E时间会长一些,基于IQ的replay会造成IQ实际容量变小,所以可以配合使用基于RQ的replay方法。

