
超标量处理器设计——第七章_寄存器重命名
超标量处理器设计——第七章_寄存器重命名
参考《超标量处理器》姚永斌著
7.1 简述
程序中存在很多相关性。可以分为:
-
数据相关性:

-
存储器数据相关性:
- load/store的相关,也可以分为WAW,WAR和RAW三种类型。
-
控制相关性:
- 分支指令引起的相关性,可以用分支预测解决。
-
结构相关性:
- 指令必须等到某些部件空闲时才能使用。例如发射队列和重排序缓存,或者功能单元FU为空闲时才能继续执行。
只有RAW是真相关性。WAW是先写再写,可以通过重命名让两条指令先写到不同的寄存器;WAR是先读后写,可以通过重命名让写指令写到另一个寄存器,就不会对读产生干扰。而先写后读,读指令必须读到新写进去的值,所以只有RAW才是真的数据相关。
例子:
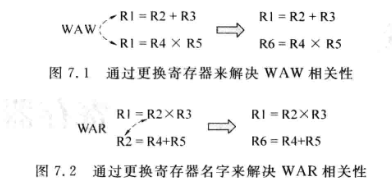
之所以会有上述相关性,主要原因还是:
- 寄存器个数有限。
- 程序中循环体会重复像同一个变量赋值
- 代码重用。某些函数在一段时间被频繁调用。
解决办法:寄存器重命名(Register Renaming)
- 指令集定义的寄存器为逻辑寄存器(Logical Register 或 Architecture Register)。
- 处理器内部实际存在的寄存器为物理寄存器(Physical Register)。
- 将逻辑寄存器映射到物理寄存器:重命名映射表(Register Renaming Table) ,Intel也将其称为Register Alias Table, RAT
7.2 寄存器重命名方式
三种方式:
- 将逻辑寄存器(Architechure Register File, ARF)扩展来实现重命名。
- 使用统一的物理寄存器(PRF)来实现重命名。
- 使用ROB来实现重命名。
实现时,需要考虑:
- 何时占用一个物理寄存器,这个物理寄存器来自哪里?
- 何时释放这个物理寄存器,这个物理寄存器去往哪里?
- 发生分支预测失败时,如何处理?
- 发生异常时,如何处理?
7.2.1 用ROB进行寄存器重命名
在超标量处理器中,每条指令都会将自身的信息按照程序中原始的顺序存储到ROB中,当一条指令将结果计算出来之后,会将其写到ROB中,但是由于分支预测失败(mis-prediction)和异常(exception)等原因,这些结果未必就是正确的,它们的状态被称为推测的(speculative). 在一条指令离开流水线之前(也就是退休之前),它都会一直待在ROB中,只有当指令变为流水线中最旧的指令,并且被验证为正确的时候,才会离开ROB,并使用它的结果对处理器的状态进行更新,例如将结果写到ARF中。
下面展示了ROB进行寄存器重命名的过程:

指令被写到ROB中的一个表项时,该表项在ROB中的编号就是指令的目的寄存器对应的物理寄存器号。这样相当于将逻辑寄存器对应到了物理寄存器。
- 指令离开流水线后(退休)会将结果从ROB中更新到ARF中。
- ARF和ROB中存储了两份逻辑寄存器的值。某条指令还在流水线中,那么该指令所用的逻辑寄存器的值还在ROB中,ARF的存储内容就不是这个逻辑寄存器的最新值。
- 需要一个重命名映射表来指示每个逻辑寄存器的值是在ROB还是ARF,如下图所示。图中的重命名寄存器表里每个表项表示了该逻辑寄存器是在哪里,以及对应的ROB地址。
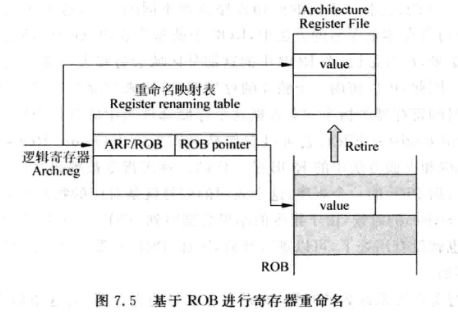
- 指令退休后,结果会从ROB中搬移到ARF中,这个信息也需要更新到重命名映射表中。
该方法的缺点:
- 不是所有指令都有目的寄存器,但是ROB中都会统一为每个表项分配物理寄存器的字段。
- 对于一条指令,既可以从ROB中取源操作数,也可以从ARF中取。ROB和ARF都需要支持最坏的情况。比如对4路超标量处理器来说,如果一条指令的源寄存器有两个,那就要支持8个读端口。
该方法的优点:
- 容易实现,复杂度不高,性能不错。
7.2.2 扩展ARF进行寄存器重命名
对ROB方案进行升级,既然有些指令没有目的寄存器,那就只保存那些有目的寄存器的指令。
可以使用一个独立的存储部件,用来存储流水线中所有指令的结果, 只有那些存在目的寄存器的指令才会占据这个存储部件当中的存储空间,这个存储部件称为PRF(Physical Register File)。可以看作ARF(Architecture Register File)的扩展。
PRF 可以通过FIFO来实现。
下面是该方法的实现图:

可以发现,仍然需要将逻辑寄存器的值存放在两个地方。
但是好处是相比于使用ROB,该方法不再需要为每条指令都开辟一个物理寄存器的字段。
7.2.3 使用统一的PRF进行寄存器重命名
该方法相当于将ARF和PRF合并。合并后称为统一的PRF。

在该PRF中,没有和指令产生映射关系的寄存器都处于空闲状态。有一个空闲列表来记录哪些寄存器是空闲的。
- Free List用FIFO实现。
- 对于一个4-way的超标量处理器,需要每周期从FIFO读4个物理寄存器编号出来。
- 每周期最多可以退休4条指令,所以最多有4个空闲物理寄存器编号会写入FIFO。
- 当空闲列表被读空,表示物理寄存器全部占用,流水线重命名及其之前的阶段就要被暂停。直到有指令退休释放物理寄存器为止。
- 当外部查看处理器状态时,很多物理寄存器还是推测的,因为相应的指令还没有退休,所以这些处于推测状态的寄存器不应该被外部可见。因此需要开辟另一个重命名映射表(RAT),用于存储所有退休状态的指令(逻辑寄存器)和物理寄存器的对应关系。
新的问题:一个物理寄存器被占用后,何时再次变为空闲?
-
理论上来说,只要最后一条使用该物理寄存器的指令退休即可。
-
实际上这个条件在硬件中并不好判断。处理器采用的是一种简单保守的方法:
-

-
当一条指令和后面的某条指令写到同一个目的寄存器时,后面的指令退休时,前面的指令对应的物理寄存器就没用了。此时该物理寄存器就可以变为空闲。上图中,b指令退休时,逻辑寄存器的值就被覆写了,所以在此之前使用了r1对应的物理寄存器的指令都应该完成了,就可以释放b指令之前r1的重命名寄存器了。
-
因此在ROB中除了记录逻辑寄存器当前对应的物理寄存器之外,还需要存储它之前对应的物理寄存器,便于该指令退休时释放旧的映射关系。
使用统一的PRF进行寄存器重命名的缺点:
- 控制逻辑复杂,难度更大。
- 需要更多的电路:Free List存储空闲物理寄存器编号,两个重命名映射表(RAT)配合。
优点:
- 寄存器的值只要被写入一次,就不需要进行移动。其他两种方法都是先写入ROB或PRF,之后再写回ARF。两次写入带来两倍的功耗。
- 一条指令的源寄存器的值值会存在一个地方,即PRF中。其他两个方法中值可能会在两个地方,即ARF和ROB(PRF)中。存在两个地方有一个坏处,就是当物理寄存器值写回ARF中时,需要将该信息通知流水线中所有用了这个寄存器作为操作数的指令,增加了连线数量和功耗。
7.3 重命名映射表(RAT)
重命名映射表提供了逻辑寄存器到物理寄存器的映射关系。因此RAT的地址就是逻辑寄存器编号,内容是物理寄存器编号。这个表格在实现上有两种方式:
- 基于SRAM(SRAM-Based RAT, sRAT)
- 基于CAM(CAM-Based RAT, cRAT)
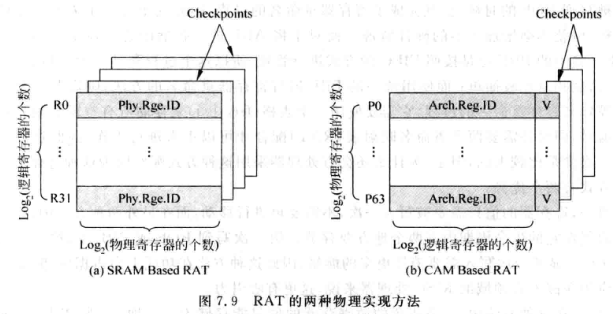
sRAT:
- 表项的个数为逻辑寄存器的个数
- 单张表的容量=逻辑寄存器个数*物理寄存器编号位宽,例如32*6=192bits
- 速度要快于CAM
cRAT:
- 也用逻辑寄存器编号寻址,但是寻址时是基于内容比较(CAM)。也就是用逻辑寄存器编号与存储的表项一一比较,相同且V有效则返回对应的地址(物理寄存器编号)。
- 单张表的容量= 物理寄存器个数*逻辑寄存器位宽,例如64*5=320bits
- 因为要比较内容,速度慢
比较:
- 物理寄存器个数越多,单张表而言sRAT要比cRAT小很多,且此时sRAT功耗更低,速度也更快。
- 分支预测时需要保存checkpoint,当流水线很深时checkpoint个数很多,此时快照有多少个sRAT就需要复制多少份。但是对cRAT而言,只需要为每个快照保存一列V即可。所以这种情况下cRAT由于sRAT。
7.3.1基于SRAM的重命名映射表
新写入sRAT的值会覆盖掉就的对应关系,比如两条指令先后写入同一个目的寄存器,那么sRAT中该目的寄存器对应的表项就会被覆盖。这样做可以吗?
答案是不行,原因有二:
- 前面也说了被覆盖的旧对应关系在释放物理寄存器时也是需要的,因此旧的对应关系需要记录下来。这样在第二条指令写同一个目的寄存器时,旧的对应关系中的物理寄存器就可以释放了。这个旧的对应关系实际被记录在ROB中。
- 当一条指令之前存在异常或分支预测失败的指令时,该指令需要从流水线中抹除。同时该指令对RAT的修改也需要被恢复,此时就可以利用之前保存的旧映射关系了。
限制:
- 流水线中分支指令越多,就要使用越多的checkpoint。此时就会时重命名映射表复制多份。
解决办法:
- 使用预测方法,对分支指令的正确度进行预测,对那些预测正确率很高的指令,就不对他们使用checkpoint。虽然这些指令发生错误时需要用很慢的方法对RAT进行恢复,但是好在这种错误发生概率很低,所以对性能影响不大。
7.3.2 基于CAM的重命名映射表
CAM重命名映射表中,每个表项表示一个目标寄存器对应的逻辑寄存器。多条指令可能有相同的目标寄存器,因此重命名映射表中可能会有若干个地址中的内容是相同的,但是这几个地址中应该只有最后一个是有效的,因为之前的映射会被后面的映射覆盖,所以需要一个有效位V来标志最后一次映射。

cRAT实际结构如下图:
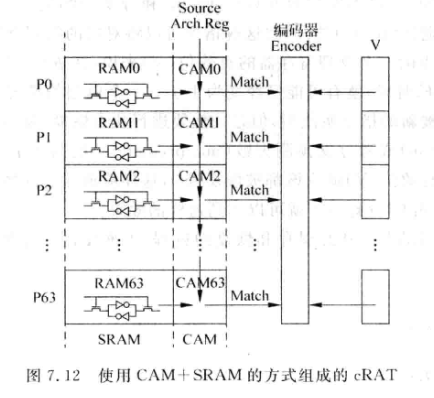
SRAM的部分用来存储逻辑寄存器编号,CAM部分用来进行内容比较,最后汇总到编码器。V也会送入编码器,最终得到物理寄存器编号。
- cRAT中,并不是V为0就表示这个物理寄存器是空闲的。可能只是这个映射关系刚被覆盖而已。
- 如果物理寄存器是空闲的,那么它在cRAT中对应的有效位一定是0。
- 在进行checkpoint保存时,只需要保存一份V向量就可以了。
下面是一个示例:

在执行到指令D时,会将V保存一份Checkpoint:
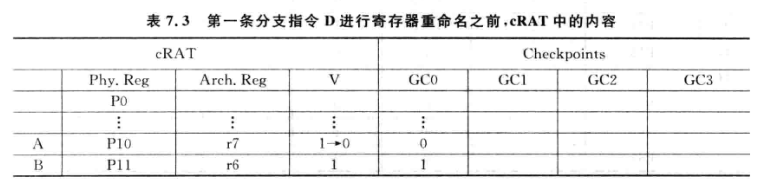
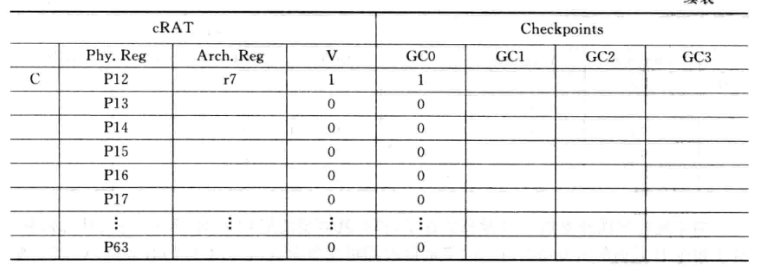
同理,执行到G的寄存器重命名阶段,假设D还没得到结果,则又会保存一份checkpoint:

如果指令执行完后发现D预测出错,就会使用GC0对cRAT进行状态恢复,D之后的指令对应的有效位都会被置为0,还要对空闲列表free list进行恢复。最后还要清空所有GC。因为后面的GC都在GC0的预测失败路径上。
7.4 超标量处理器的寄存器重命名
对于Dest=Srcl 0P Src2这样的指令来说,寄存器重命名的过程如下:
-
从RAT中找到Src1和Src2对应的物理寄存器Psrc1和Psrc2。
-
-
从Free List中找到一个空闲的物理寄存器Pdest,作为目的寄存器Dest对应的物理寄存器。
-
-
将映射关系写到RAT中:
-
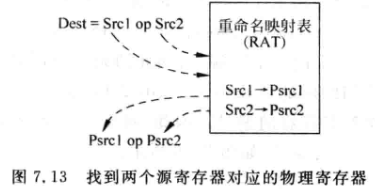
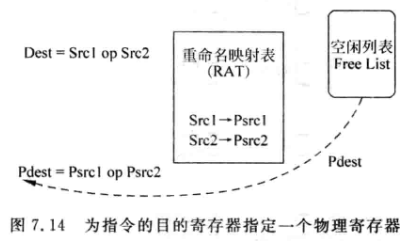
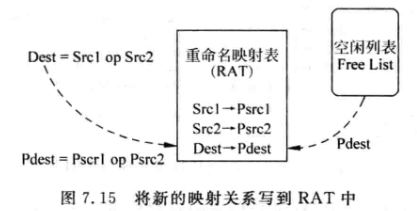
可见,RAT需要支持:
- 三个读端口,两个用来读取两个源寄存器;另一个用来读取每条指令的目的寄存器之前对应的映射关系(用来释放物理寄存器)。
- 一个写端口,用来写目的寄存器的映射关系。
对于一个4-way的超标量处理器来说,每周期又四条指令进行寄存器重命名,因此需要:12个读端口,4个写端口。如下图所示:

在每周期进行重命名时各指令之间存在各种相关性:

WAW相关性的处理:
- 写入RAT时,只需要将逻辑寄存器的最新映射关系写道RAT中。如果一个周期内多条指令的有同一个目的寄存器,执行需要写入最新的那条指令的映射关系。
- 将每条指令的旧映射关系写入ROB时,若一个周期内多条指令使用一个目的寄存器,则写入ROB的旧映射关系不再是来自RAT读取的值,而是来自和它有WAW相关性的指令。
WAR相关性的处理:寄存器重命名可直接消除。
7.4.1 解决RAW相关性
在4-way的超标量处理器中,一次可以对四条指令进行寄存器重命名,过程如下:

上图中R1,R2被映射到P10,P11,目的寄存器R1,R3,R5,R8分别映射为P31, P40, P8, P5(从Free List中选取)。
当存在RAW相关性时:
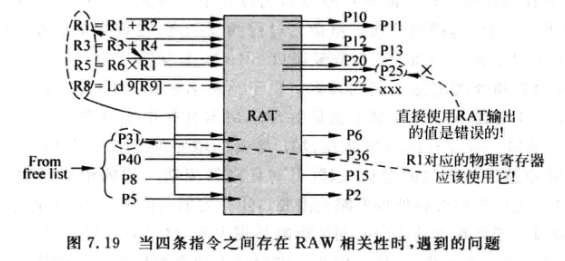
R1寄存器存在RAW,因此第三条指令中的R1应该使用映射后的寄存器,也就是P31。
此时,需要一种组内相关性检查机制,对一个周期内进行重命名的所有指令进行RAW检查。需要将每条指令的源寄存器编号与前面所有指令的目的寄存器编号进行比较,如果相等,源寄存器的物理寄存器就应该来自Free List的输出,而不是RAT的输出。
- 下面是组内相关性检查的一个电路示意图:

- 其中的相关性检查电路如下图:
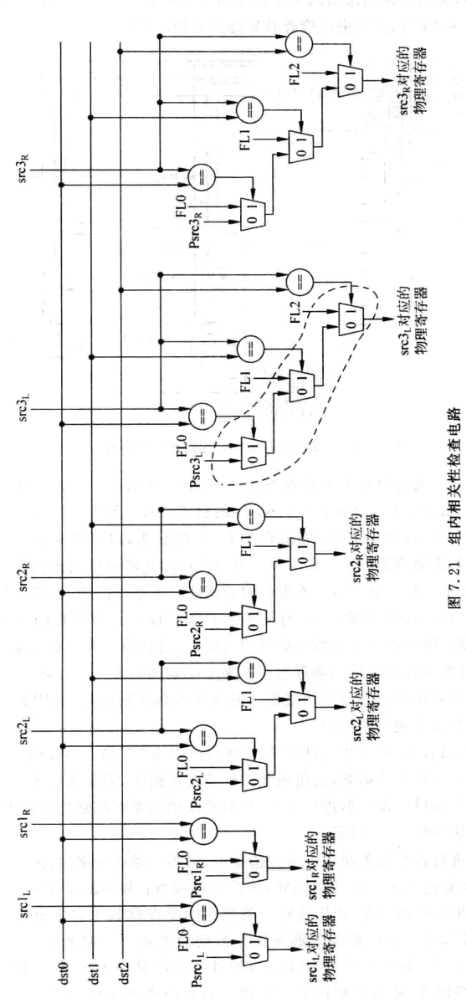
7.4.2 解决WAW相关性
-
对RAT进行检查:
- 多条指令的目的寄存器相等时,只有最新的那条指令的映射关系会被写入RAT中。
- 相应的电路结构:

-
对ROB进行检查:
- 为了释放物理寄存器,每条指令需要从RAT中读出它之前对应的物理寄存器,写回到ROB中。
- 若一个周期进行重命名的几条指令中有两条指令目的寄存器相同,则较新的指令对应的旧的物理寄存器就直接来自于旧的那条指令(Free List),而不是RAT的输出。

相应的电路图如下:

- 若读取RAT的源寄存器和写入RAT的目的寄存器是同一个,会遇到同周期读写同一个地址的问题。
- 应该采用读优先的策略,也就是先读出旧值,再向该地址写入新值。
7.5 寄存器重命名过程的恢复
分支预测失败或者异常会导致指令从流水线中抹除,此时需要将被这条指令占用的资源进行恢复。除了要恢复ROB和发射队列,还要对RAT也进行恢复。
对RAT的恢复主要有3种方法:
- Checkpoint
- WALK
- Architecture State
7.5.1 Checkpoint
- 所谓checkpoint就是对某些部件在某个时刻原封不动保存一份。相当于某个时间对处理器状态拍了一个快照。

- 一般将Checkpoint简写为GC(Global Checkpoint)。
- 若状态恢复时,可以从任意一个GC中读取,那这种方式就是随机访问的GC (Random Access GC, RAGC);
- 若在状态保存时,只有一个GC与状态寄存器直接相连,其他GC要逐级移位才能放到指定GC中,就称为串行访问的GC (Sequential Access GC, SAGC)

PS. 串行访问的GC能减少对主存储部件的驱动能力的要求,但是相应的,需要较长时间才能进行状态恢复。因此RAGC更适合做Checkpoint。
RAGC在电路上是如何实现的呢?
- RAT实际上本质是多端口的SRAM或寄存器堆。实现Checkpoint时,需要在SRAM的每个Main Bit Cell(MBC)旁边加入一个Checkpoint Bit Cell(CBC)。
- MBC的内容可以复制到CBC,称为Allocate
- CBC内容复制到MBC, 称为Restore
- 电路结构如下图:

7.5.2 使用WALK
背景:
- Checkpoint电路会增大硬件开销
- 由于硬件限制,checkpoint没法做很多
另辟蹊径:使用ROB对RAT进行恢复。
- ROB中存储了一条指令之前对应的物理寄存器。
- 从ROB底端最新的指令开始,逐条将每条指令之前对应的映射关系写道RAT中。
- 对于4-way的处理器,RAT支持4路写端口,可以每周期从ROB中WALK四条指令。
缺陷:
- 速度较慢,需要对流水线中的指令有选择的抹除
- 还要逐个地对指令进行恢复
优势:
- 消耗资源少
7.5.3 使用Architecture State
背景:
- 在统一的PRF进行寄存器重命名的方法中,所有逻辑寄存器都混在物理寄存器中了。当要从处理器外部访问逻辑寄存器,直接用寄存器重命名阶段的RAT是很难实现的,因为它是推测的(speculative)。因此一般都会在流水线的提交阶段也用一个RAT。
例如下面的一组指令:
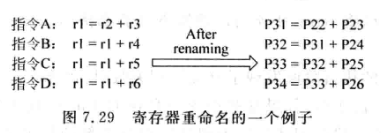
当A离开流水线时,r1的值存储在P31内。如果在D完成重命名的时刻,处理器外部访问逻辑寄存器r1,如果直接用重命名阶段的RAT,那只能得到P34这个映射结果,而该映射是推测的,可能被分支预测失败或异常而抹除。所以不应该被外界看到这个映射。
解决方案:
-
所有正确离开流水线的指令都会更新这个RAT。称之为aRAT(architectrue RAT)
-
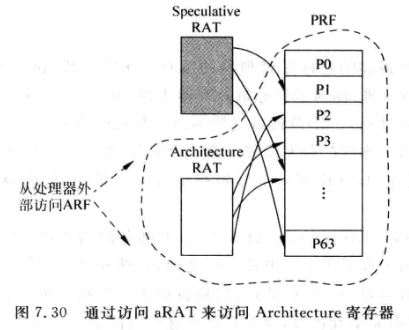
-
aRAT的状态肯定是正确的。其中的逻辑寄存器到物理寄存器的映射关系也是正确的而非推测的。
RAT状态恢复:
- 分支预测失败时,不马上进行RAT状态恢复,而是让处理器继续执行。
- 当该分支指令变为最旧的指令,aRAT中就表示了分支指令所对应的正确状态的RAT。因为分支指令前的指令都正确离开了流水线。
- 此时可以将aRAT的内容复制到重命名阶段的Speculative RAT,就完成了RAT的状态恢复。
- 这种恢复可以在RAT中的bit cell中建立连接(类似checkpoint)
7.6 分发
流水线的分发(Dispatch)就是将重命名后的指令写道发射队列(Issue Queue)和重排序缓存ROB的过程。指令到达发射队列后,就可以乱序执行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号