
超标量处理器设计——第四章_分支预测
超标量处理器设计——第四章_分支预测
参考《超标量处理器》姚永斌著
4.1 简述
- 分支预测主要与预测两个内容, 一个是分支方向, 还有一个是跳转的目标地址
- 首先需要识别出取出的指令是否是分支指令, 如果是需要送入方向和地址预测模块:
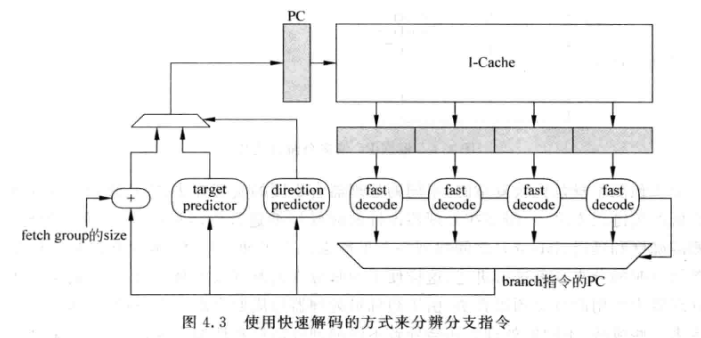
- 分支预测最好的时机就是当前周期取到指令地址的时候, 就进行预测, 这样就可以在下个周期根据预测结果取指
- 进行分支预测的PC实际是虚拟地址, 在一个进程内PC值对应唯一一条指令, 只不过在进程切换后需要将分支预测器的内容清空, 才能保证不同进程互不干扰.
4.2 分支指令的方向预测
4.2.1 基于两位饱和计数器的分支预测
-
最广泛使用的预测技术就是两位饱和计数器的分支预测器
-
有四个状态,如下图:
-

-
状态机在饱和时需要连续两次预测失败才会改变预测结果
-
相当于一个去抖电路
-
可以使用格雷码减少翻转降低功耗
-
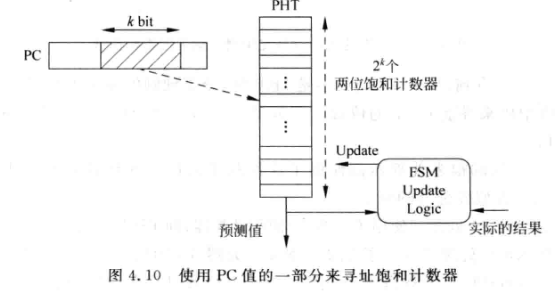
每一个PC都会对应一个两位饱和计数器, 但是这样对于32位的PC长度来说, 全部分配一个显然是不现实的, 因此通常用PHT, 如下图:
-
-
PHT (Pattern History Table)是一个表, 存放PC值的一部分对应的两位饱和计数器的值.
-
PHT只用PC的k位来寻址, 以降低表项个数
-
PC值的k部分相同的两条指令会对应PHT的同一个表项, 这种情况称为别名(aliasing)
-
别名问题会导致分支预测的状态有可能错误跳转(因为会两条指令会相互干扰)
-
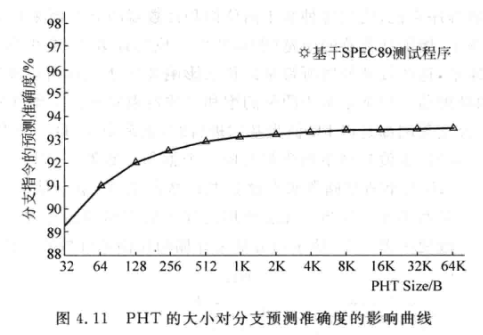
PHT越大, 别名问题就越不显著(因为k位相同的可能性降低了):
-
-
避免别名的方法: 哈希(Hash) , 对PC值进行处理后再寻址PHT:
-

-
哈希算法能够将32位PC压缩为固定长度的较小值, 这样保证了不同PC尽量不会寻址同一个PHT地址.
-
更新PHT的状态机有三个时机:
- 在取指令阶段, 进行分支预测时用预测结果更新PHT
- 在执行阶段, 当分支方向计算出来时根据结果更新PHT
- 在提交阶段, 分支指令要离开流水线时更新PHT
-
上面三种方法准确度依次提升. 方法1是最不可靠的, 因为预测结果可能是错的, 方法二也不能保证计算的分支结果是对的, 因为这条指令之前可能也有分支指令, 而该指令可能处于之前分支指令的预测错误路径上. 所以只有第三种方法才是万无一失的.
4.2.2 基于局部历史的分支预测
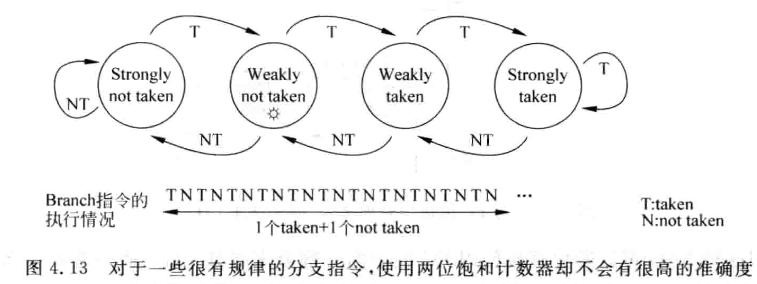
- 对于很有规律的分支指令, 两位饱和计数器的准确率可能很糟糕, 例如下图的情况, 初始在weakly not taken , 则对于TNTNTN...这样的序列, 预测将一次都不对:
解决办法:
-
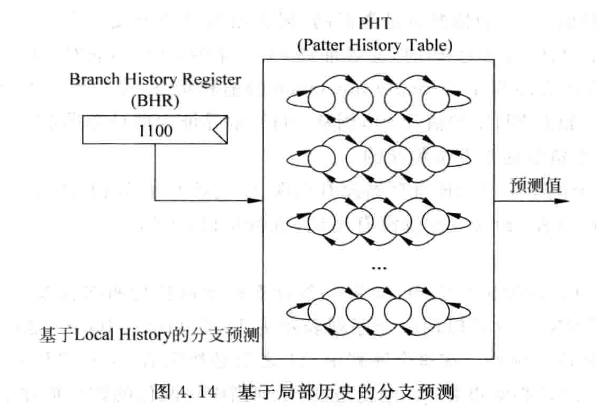
BHR (Branch History Register) , 也称为自适应的两级分支预测(Adaptive Two-level Predictror)
-
将一条分支指令每次的结果都写入BHR寄存器, 就能记录该指令的历史状态
-
-
BHR位宽为n, PHT地址宽度与之对应. 用BHR来寻址PHT
-
PHT中实际不是每个表项都是一个饱和计数器, 实际只是存储了一个计数器的值. 每次更新表项需要先读出计数器值, 然后放到统一的饱和计数状态机里获得下一个状态的值再写回.
-
例子:
- 假设BHR位宽为2, 对应一个4个表项的PHT, 假设分支序列是T -> NT -> T -> NT -> T ...
- BHR是一个移位寄存器, 所以相当于2位的寄存器在一个101010...的序列上滑动, 寄存器的值要么是10, 要么是01
- 当BHR是10时,下一次进来的一定是1,也就是一定是跳转,10寻址PHT的第三个表项,当分支结果计算出来之后会更新这个表项,则之后再遇到BHR是10的情况,去PHT中获取历史预测结果就可以得到预测为跳转的结果了。 同理BHR是01是处理过程也是类似的。
-
一般性规律:
- 如果一个序列中连续相同的数最多有p位, 那么循环周期就是p,例如对于序列11000_11000_11000, p=3;
- 只要BHR宽度大于等于某一个循环周期为p的分支序列,就可以用BHR对其进行完美预测
-
每个PC都需要一个BHR和一个PHT(与BHR的宽度呈指数关系)
-
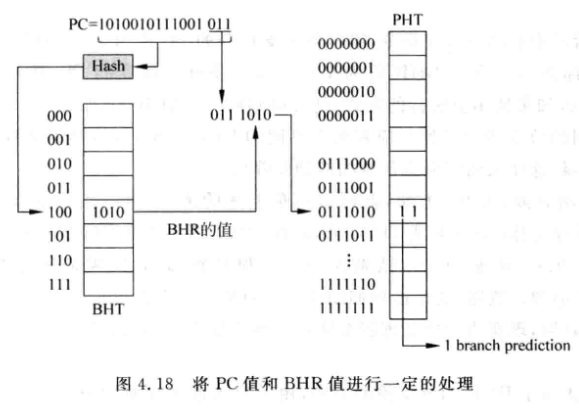
BHT (Branch History Register Table), 将所有BHR组织为一个分支历史寄存器表, 用PC的一部分寻址这个表:
-

-
PC的k位寻址BHT, t位寻址PHT.
-
PHTs 如果为每个PC都分配一个PHT, 那PHTs表就会很大, 一种极端的方法是只放一个PHT:
-

-
BHR实际只会用到PHT的少部分内容, 所有多BHR就可以使用PHT中的不同部分.
-
但是会有重名问题, 因为所有PC都共用一个PHT. 具体表现为:
- 两个PC的k位相同, 对应到了同一个BHR, 自然也会对应同一个PHT地址
- 两个PC的k位不同, 对应到不同BHR, 但是两个BHR对应到同一个PHT地址
-
一种解决办法:
-
-
另一种方法(比上一种可能更好些, 别名问题更少):
-

4.2.3 基于全局历史的分支预测
- 基于局部历史的分支预测技术只针对一条分支指令自身的历史信息
- 基于全局历史的分支预测会考虑该指令之前的分支指令的执行结果
- 例如下面的代码中, b3分支可以观察b1和b2分支的结果:
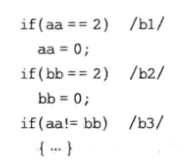
-
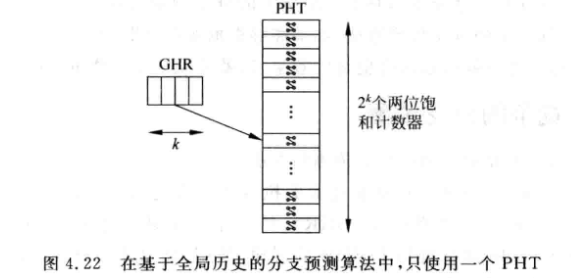
GHR (Global History Register) 全局历史寄存器, 记录所有分支指令过去的执行情况
-
GHR也是一个移位寄存器, 一条分支指令的结果会插入GHR寄存器的最右边, 并将最左边的值移出寄存器
-
分支指令进行预测时, 还要用GHR寄存器来索引PHT, 用饱和计数器捕捉GHR寄存器的规律.
-

-
同样, 为了减少PHTs的大小, 可以采用下面的结构:
-
-
为了解决别名问题, 同样可以采用位拼接或XOR:
-

-
GHR和BHR的本质区别是GHR是所有分支指令共用一个GHR. 而BHR是每条分支指令对应一个BHR
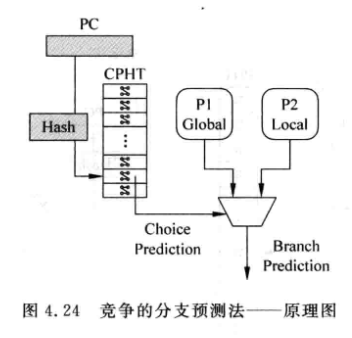
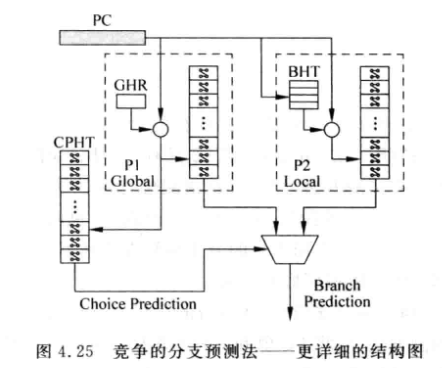
4.2.4 竞争的分支预测
-
结合局部和全局的分支预测方法:
-
-
-
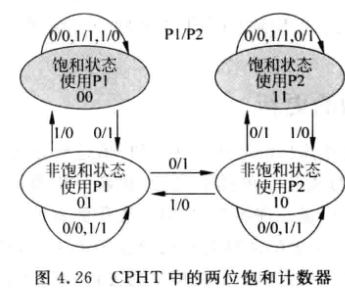
CPHT (Choice PHT) 由分支指令的PC值寻址的一个表格, 内部也是两位饱和计数器
-
当P1或P2预测失败时, 会使状态机跳转:
-
-
CPHT相当于是对选择局部和全局预测器进行预测
4.2.5 分支预测的更新
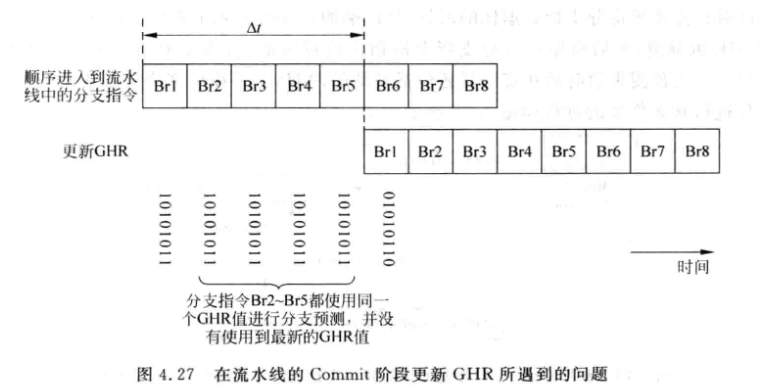
对GHR的更新
-
在分支指令退休的时候更新GHR虽然稳妥但是有如下问题:
-
-
从分支指令被预测到退休中间可能还会进入很多分支指令, 这些分支指令都无法使用最新的GHR
-
对GHR的更新, 实际上可以在取指的阶段进行:
-
一是可以让后续指令都用到最新的GHR
-
二是即使该指令预测错误, 也不要紧, 因为后续的指令都在分支预测的错误路径上, 会被抹掉
-
唯一需要考虑的问题是, 如果预测失败, 如何恢复GHR到被更新之前的值?
- 可以在提交阶段进行修复. 指令退休时将结果更新到retired GHR , 发现与前端使用的speculative GHR不匹配时说明预测出错, 就可以用这个GHR对前端的GHR进行修复.
- Checkpoint修复. 在取指阶段更新GHR时, 可以将旧的GHR存起来, 当分支的结果计算出来时就可以用checkpoint GHR对其进行修复(比如执行阶段)
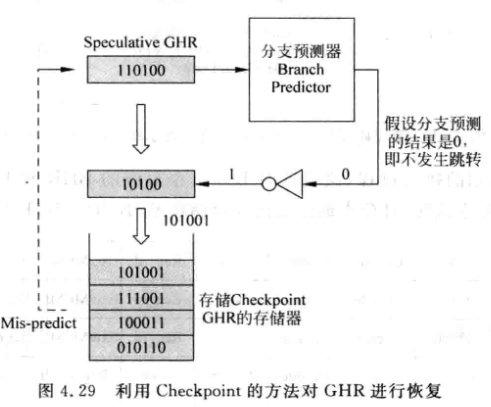
- 实际上, 在执行阶段得到的分支结果也不一定是正确的, 因为它可能处在分支预测失败的路径上, 所以还是要设置retired GHR
-
对BHR的更新
-
对BHR的更新也可以基于推测和不推测(取指阶段或退休时更新)
-
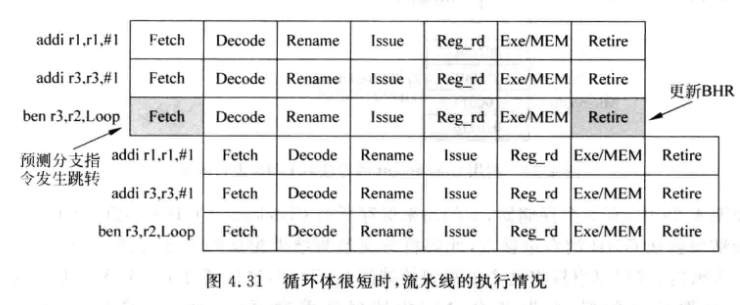
有一种特殊情况, 循环体很短的时候一条分支指令可能在流水线中存在多次:
-

-
-
这种情况下在退休时更新BHR就来不及了, 流水线中后续的相同的分支指令用不到更新的结果. 但是实际上这种方法对性能并不会有太大影响, 因为经过一段训练时间, 分支预测器会判断该分支是跳转的, 即使第一次出错, 后面的预测都是正确的.
总结:
- GHR在取指阶段更新比较合适
- BHR在退休的时候更新比较合适, 可以简化设计, 也不会造成太大的性能损失.
- 通常都是在退休的时候更新PHT中的饱和计数器
4.3 分支指令的目标地址预测
主要分为:
- 直接跳转, 目标地址以立即数形式在指令中, 是固定的
- 间接跳转, 目标地址来自通用寄存器
程序中大部分间接跳转是用来处理子程序调用的CALL和Return指令, 这两种指令的目标地址是有规律的, 可以进行预测
4.3.1 直接跳转类型的分支预测
直接跳转的分支目标地址有两种:
- 当不发生跳转时: 目标地址 = PC + Sizeof(fetch group)
- 发生跳转时: 目标地址 = PC + Sign_extend(offset)
-
用一个表格记录每条直接跳转的分支指令对应的目标地址
-
分支预测基于PC, 为了节省空间一般是几个PC对应一个表项
-
BTB (Branch Target Buffer): cache形式, PC的一部分寻址(index), PC的其他部分作为Tag. BTB中的数据段为分支的目标地址, 称为 BTA (Branch Target Address)
-
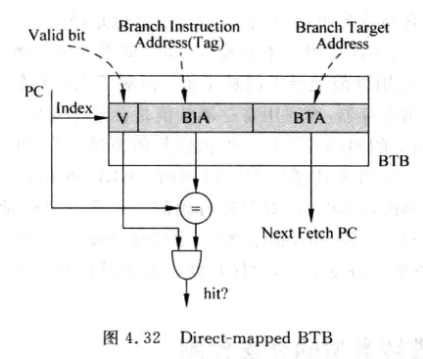
-
可以采用组相连结构减少不同的PC索引到同一个cache data的情况:
-

-
BTB不能用太多的组
-
Partial-tag BTB : 为了节省面积, 可以减少tag的空间, 只使用PC的一小部分做tag:
-
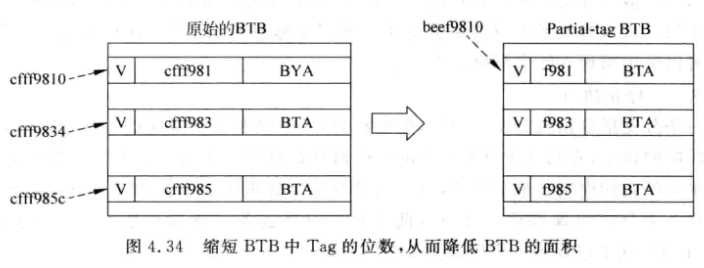
-
除了直接截取小位宽的tag, 还可以使用hash:
-
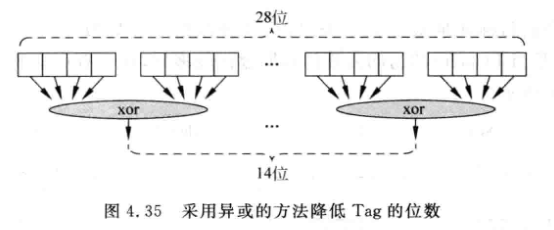
-
直接跳转类分支使用BTB预测分支目标地址是较为准确的, 但间接跳转不行
发生BTB缺失时:
- 停止执行. 暂停取指, 直到分支的目标地址被计算出来为止.
-
-
会产生Bubble:
-

-
不适用于间接跳转, 因为寄存器值被计算出来至少要在执行阶段, 引入过多bubble
-
- 继续执行.
- 发生BTB缺失时, 默认分支不发生, 用顺序的PC值取指令
- 如果解码后发现计算出的地址和顺序执行的PC不一样(大部分时候都如此), 就把分支指令之后进入流水线的指令抹掉
- 虽然会浪费功耗, 但是还是存在正确的可能性
4.3.2 间接跳转类型的分支预测
-
CALL/Return的分支预测
-
CALL调用子程序, 一般目标地址也是固定的, 可以用BTB进行预测:
-

-
但是Return的地址却会变化:
-

-
return的目标地址, 是CALL指令地址相反的顺序, 是一个后进先出的队列(栈)
-
RAS (Return Address Stack), 返回地址堆栈, 用于存储Return的目标地址:
-
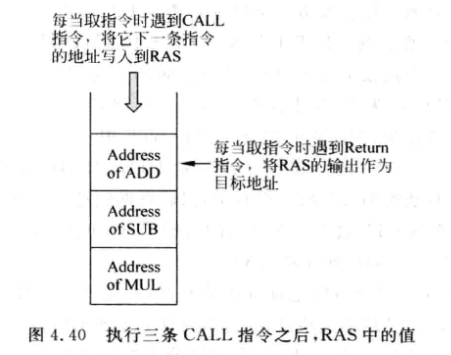
-
因此, 使用BTB对CALL地址预测, 使用RAS对Return地址进行预测:
-

-
存在的问题: 如何识别分支指令类型?
- 到解码阶段才能识别到CALL指令, 随后将PC+4放到RAS中. 但是在到达解码的时间内, 又有很多指令进入了流水线(访问I-cache取指需要几个周期), 如果里面有Return, 这些Return就无法从RAS获得目标地址
- Return指令的目标地址需要能切换到RAS的输出, 而不是BTB的输出, 所以也需要在分支预测阶段就知道指令类型.
-
解决: BTB中保持了所有发生跳转的分支指令. 在BTB中增加一项, 表示分支指令的类型, 记录是CALL, Return还是其他. 之后取指时就可以通过BTB检查当前PC是不是CALL
-
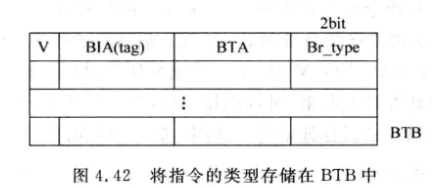
-
新的问题: RAS满了如何处理?
-

-
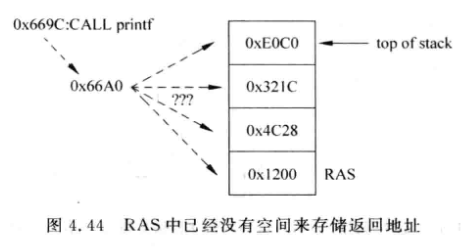
-
解决方法:
- 不对新的CALL处理, 让新的Return预测失败(不推荐)
- 继续写RAS, 覆盖旧的数据:
-
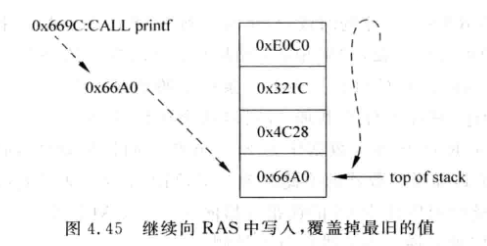
-
此时Return1将不可避免地预测失败
-
但是该方法存在正确的可能, 例如递归调用, 自己调用自己, 此时RAS中每项的值都是一样的, 所以覆盖也没事
-
-
-
其他分支类型的预测
-
对既不是CALL也不是Return的间接跳转指令, 通常其目标地址只有固定几个, 例如Case语句
-
可以用BHR对其进行预测:
-
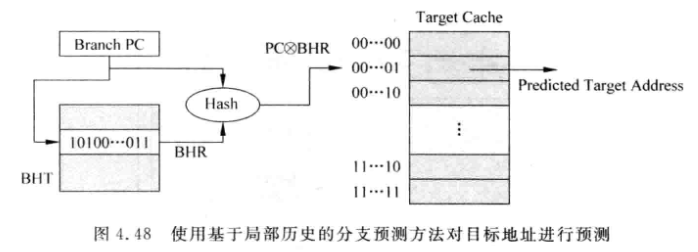
-
用PC和BHR的值来hash索引Target Cache
-
Target Cache内存储间接跳转分支指令的目标地址
-
4.3.3 小结
- Decoupled BTB : 分支指令的方向预测独立于BTB的做法
- 下面给出一个完整的分支预测结构:
-
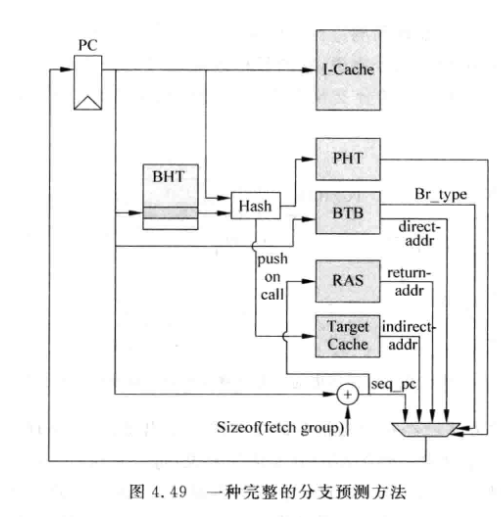
4.4 分支预测失败时的恢复
- 解码阶段: 可以对直接跳转的分支指令进行正确性检查
- 读取物理寄存器阶段: 可以对间接跳转的分支指令进行检查
- 执行阶段: 任意类型的分支都可以在此时检查正确性, 但是失败惩罚最大.
在某个阶段发现预测失败时, 需要将这个阶段之前进入流水线的指令都抹除
-
在执行阶段发现预测失败时, 可以等到该指令成为ROB中最旧的指令之后才抹除流水线中的指令. 避免影响分支指令之前的指令
-
也可以采用checkpoint方法, 消耗更多的硬件资源, 保存分支之前的处理器状态, 在预测失败时立即恢复, 并抹除分支指令之后的指令. 但是此时, 流水线中还有其他指令, 他们不能被抹除, 如何区分?
-
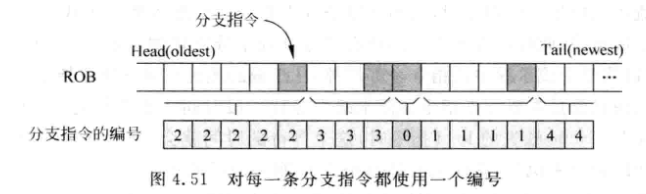
-
可以像上图这样, 为每条分支指令都添加一个编号. 所有在在分支指令之后的指令都会获得这个编号, 直到下一个分支指令为止
-
编号列表(tag list) 组织为一个FIFO, 其容量为处理器最多支持的分支指令个数
-
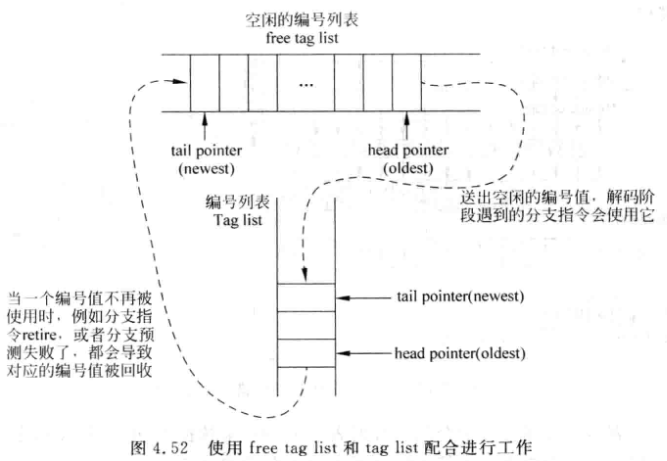
可以再开一个空闲的编号列表(free list), 每次解码时发现一条分支指令, 就从中送出一个编号, 写道tag list中, 之后所有解码的指令都会带上这个编号, 直到遇到下一条分支指令
-
当一条分支指令离开流水线, 或者分支预测错误, 就会释放编号
-
-
-
如何抹除错误路径上的指令呢?
- 在发射阶段之前的指令都需要被抹除, 因为发射之前是in order的, 所以执行阶段发现分支预测失败时, 发射阶段之前的指令都在错误路径上, 一个周期就可以抹除
- 在发射阶段之后, 是按照 out-of-order执行的, 需要根据编号列表的编号找出错误路径的指令. 一个周期可能无法完成, 过程如下:
-
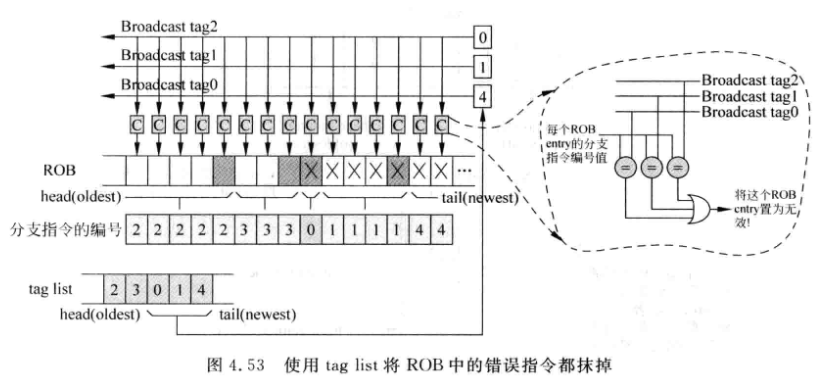
-
广播tag list的值, ROB中的指令每个都需要进行比较, 如果相等就把ROB中该entry置为无效
-
对发射队列的处理也可以用上图这种结构
-
实际上并不要求一个周期就抹除所有错误路径上的指令, 因为新的指令要经过好几个阶段才能到发射阶段, 所以只需要在这之前清楚所有错误指令即可
-
可以每个周期只从tag list中广播一个或几个编号, 几个周期就能将这些错误路径上的指令抹除, 消耗的布线和组合逻辑资源就不会那么多了
-
-
在解码阶段为每条指令分配编号是最合适的
-
N-way的超标处理器没周期可能处理多条分支指令, 需要多端口的tag list, 消耗太大, 因此处理器内部可以做一个折中约定: 解码阶段每周期最多处理一条分支指令
-
在流水线的后续(执行阶段), 需要检查分支预测正确性, 那如何获得取指阶段就进行的分支预测结果呢?
-
可以在解码阶段, 将分支预测结果写入一个缓存: PTAB (Prediction Target Address Buffer)
-
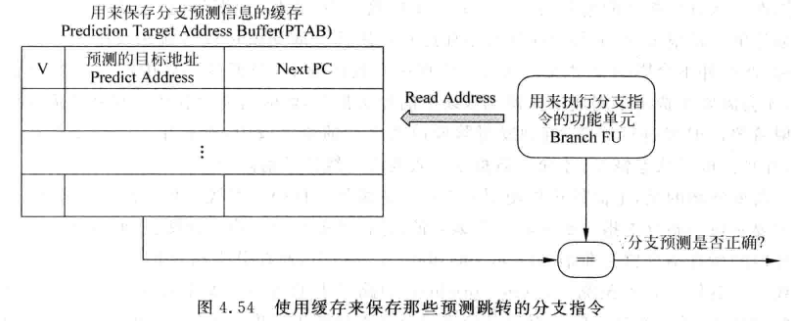
-
分支指令在PTAB中的地址会随着指令在流水线的位置而改变
-
PTAB只需要保存预测为跳转的分支指令
-
执行阶段检查分支预测正确性时, 有四种情况:
- 实际不跳转, PTAB中也没有相应内容 -> 预测正确
- 实际不跳转, PTAB中有对应内容 -> 预测错误, 用next pc作为目标地址
- 实际跳转, PTAB中没有对应内容 -> 预测错误, 需要用实际计算出来的地址
- 实际跳转, PTAB中有对应内容 -> 看计算出来的目标地址是否跟表中一致
-
4.5 超标量处理器中的分支预测
-
超标量处理器中每次取出一个指令组(fetch group), 每次送到I-cache中的实际只是指令组的第一条指令地址
-
如果仍然使用取指时的地址进行分支预测, 相当于只对第一条指令进行了分支预测
-
好在大多数情况下一个组内只有一条分支指令, 所以只需要家一个分支指令的组内偏移即可, 并记录在BTB中
-
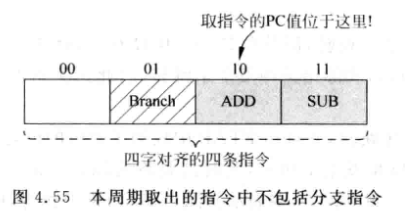
-
当然, 如果fetch group中有多条分支指令, 就需要对所有分支都进行预测:
-


