超标量处理器设计——第二章_Cache
超标量处理器设计——第二章_Cache
参考《超标量处理器》姚永斌著
Cache的一般设计
- Cache缺失(miss)的3C定理:
- Compulsory , 第一次访问失效
- Capcity, 由于cache满引发的miss
- Conflict, 有多个数据映射到cache同一个位置
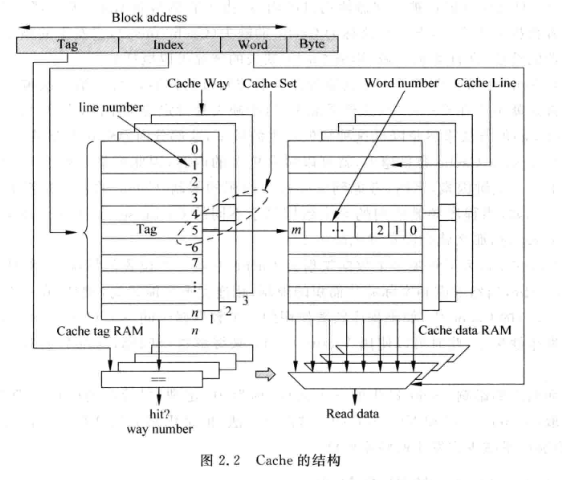
2.1.1 cache组成方式
-
直接映射:
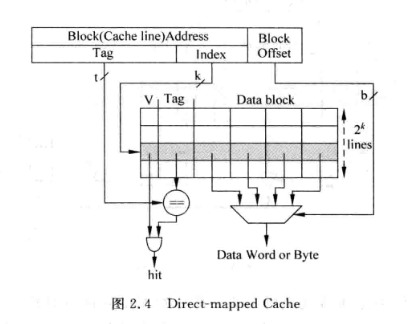
- 对所有index相同的存储地址, 会寻址到同一个cache line
-
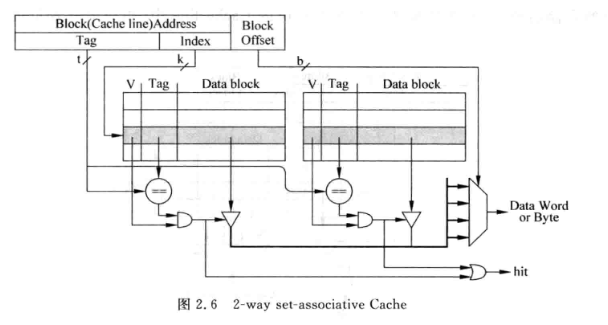
组相连:
-
对所有index相同的存储地址, 会寻址到多个cache line
-
n-way的组相连结构一个index对应n个line, 这些line称为一个cache set
-
可以显著降低cache miss
-
因为需要从set中比较得到一个line, 延迟较大
-
tag和data通常分成两个SRAM, 称为tag sram 和data sram
- 并行访问:
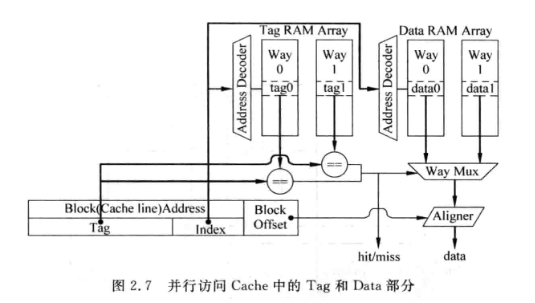
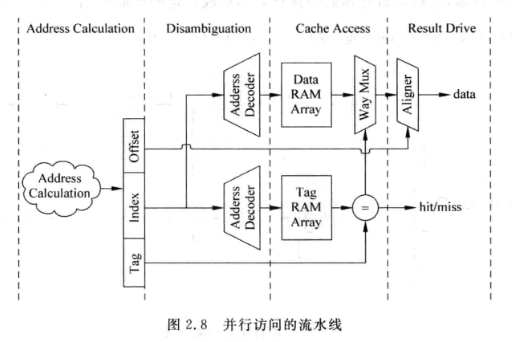
- 串行访问:
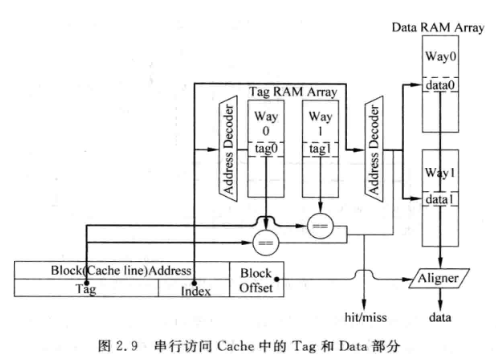
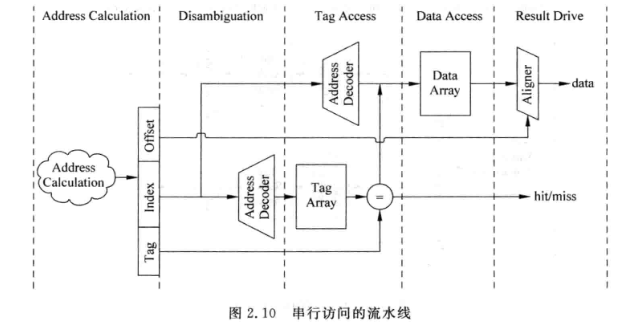
- 串行访问虽然增加了一拍延时, 但是省掉了way mux ,节省功耗, 可以提升流水频率
- 增加的一拍延时, 在乱序机中可以填充其他指令, 性能影响不大;但是对顺序机而言可能会降低性能
- 全相连
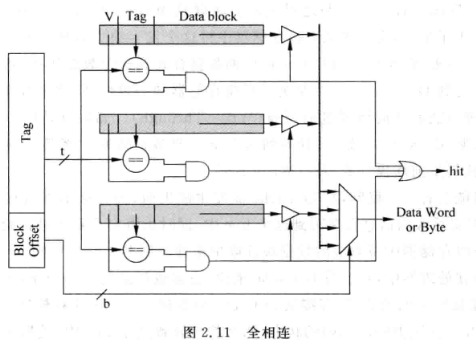
- 没有index, 一个地址的数据可以在cache的任意位置找到
- 将tag与所有cache line比较
- 相当与CAM 内容寻址存储器(Content Address Memory)
- 一般TLB采用这种结构
2.1.2 Cache的写入
-
一般I-Cache不会直接写入内容, 即使程序有self-modifying自修改的情况, 也是先把改写的指令写入D-Cache, 将D-cache内容写回下级存储器, 之后将I-cache所有内容置为无效, 这样处理器再次执行就会发生miss, 迫使I-cache从下级存储取指令
-
写D-cache的方式:
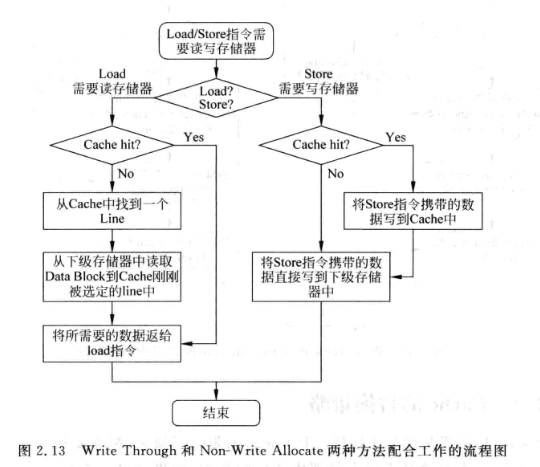
- 写通(Write-Through): 数据写到D-Cache的同时, 也写到下级存储器
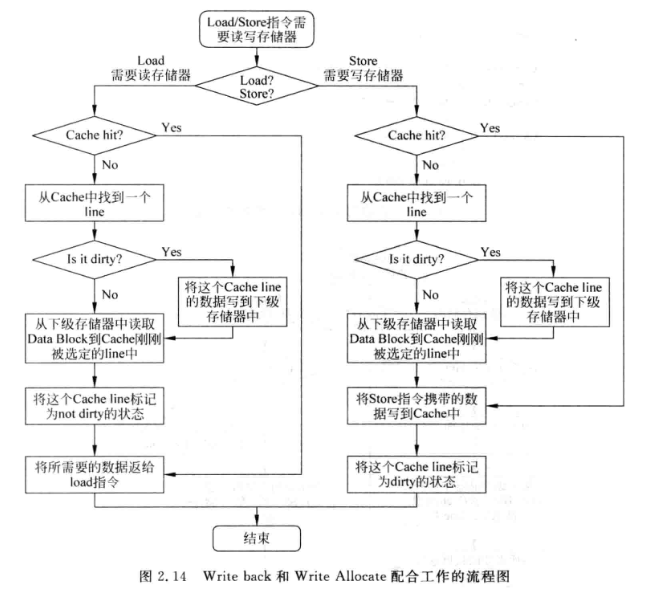
- 写回(Write-Back): 通过脏位标记D-cache中被修改的line, 当该line要被替换时才将其写到下级存储器
-
写D-Cache时发生写miss:
- Non-Write Allocate : 直接将要写的内容写到下级存储器, 不写到D-Cache中
- Write Allocate: 先从下级存储器中将发生缺失的地址对应的数据块取出, 与要写入到D-cache中的数据合并后再将该数据写入D-Cache
-
写通一般配合Non-Write Allocate; 写回则一般配合Write Allocate:
-
-
写回+Write Allocate的方法相对而言可以减少对下级存储器的访问频率
-
2.1.3 Cache的替换策略
- 替换发生在某个Cache set中所有的line都满了的情况
1. LRU (Least Recently Used)
-
为每个Cache line设置一个年龄部分, 每当way被访问, 年龄部分就会增加, 年龄最小的way就是要被替换的way
-
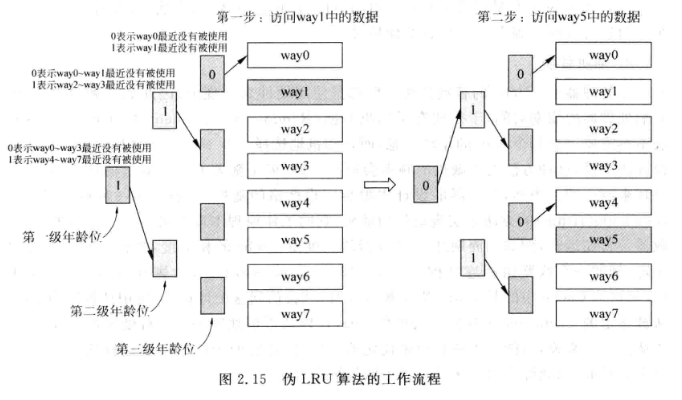
实际实现是通常采用PLRU(Pesudo Least Recently Used):
-
-
对于8个way的Cache, 需要三级年龄位, 每个年龄位为0表示标号小的那些way最近未被使用, 为1表示编号大的那一组最近未被使用
-
每次访问某个way都会更新三级年龄位
-
代码实例[[PLRU-伪LRU的一种优雅实现方式]]
2. 随机替换
- 一般采用时钟算法, 开一个计数器, 计数宽度等于Cache的相关度, 每个时钟周期加一, 需要替换时就用当前的计数值选择替换的way
2.2 提高Cache的性能
2.2.1 写缓存
- 起因: L2-Cache一般只有一个读写端口, 当D-Cache发生缺失, 需要从下级存储读取数据, 并写道Cache line中, 如果这个line是脏的, 需要先将其写回下级存储. 所以对L2-Cache的需要先写再读, 串行完成. 这样增加了从下级存储读入数据到Cache的延迟
- 解决: (写延迟策略) 增加一个write buffer, 当脏的line需要写回时先放到write buffer中, 等到下级存储有空的时候才会将write buffer中的数据写回夏季存储
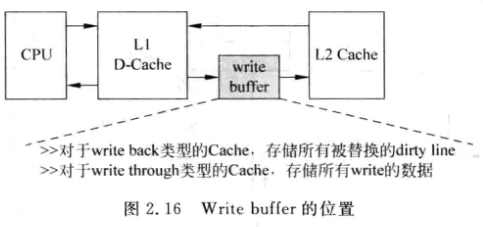
- 对于写通类型的缓存, 写下级存储的次数较多, 因此写缓存较为重要
- 缺陷: 会增加复杂度, 因为写缓存中也要加入地址比较CAM电路, D-Cache发生缺失时, 不仅要从下级存储器查找,还需要从写缓存中查找最新数据
PS. 写延迟的方法用处很多, 例如可以据此实现单端口SRAM的FIFO:
[[FIFO那些事儿——单端Sram实现的同步FIFO]]
2.2.2 写D-Cache流水线
- 对读Cache来说, 可以实现tag和data的读取并行
- 写Cache需要先比较tag, 通过之后才能写入data, 所以需要串行
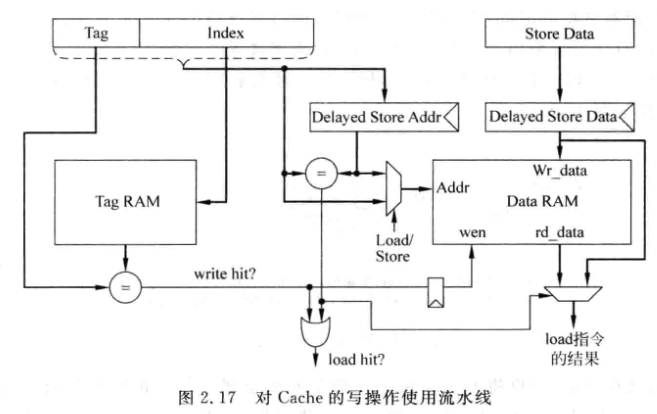
- 当sw后紧接着一条ld, 此时ld的地址可能正好在Delayed Store Data寄存器中, 因此上述流水线添加了一个旁路, 可以将load data直连到Delayed store data寄存器上
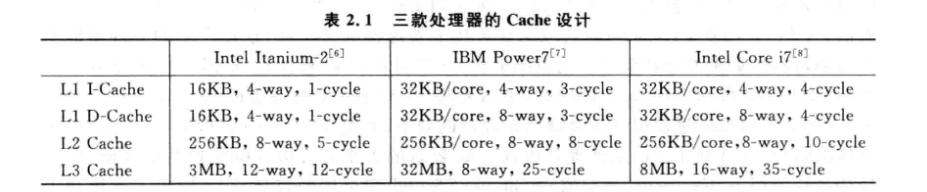
2.2.3 多级结构
-
一般L2 Cache会采用Write Back
-
对于多核处理器, L1 Cache采用Write Through可以简化流水线
-
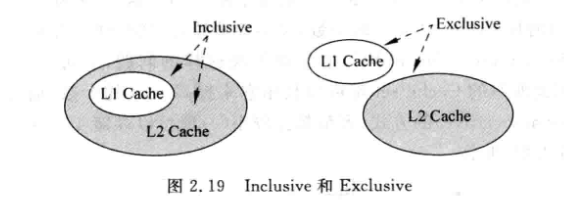
Inclusive和Exclusive:
-
-
Exclusive : 避免浪费, 可以获得更大的Cache可用容量, 提高处理器性能
-
Inclusive : 写数据时可以直接写入L1 Cache, 不需要再读下级存储出来合并后再写入, 且一致性管理更简单
2.2.4 Victim Cache
-
-
如果cache中被踢出的数据马上又要被用, 又不能增加cache的way数, 可以采用VC
-
VC用于保存最近被踢出的数据, 本质是相当与增加了way数:
-
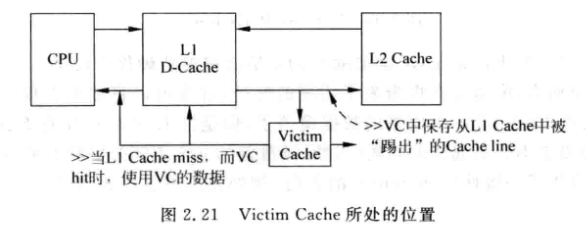
-
一般VC是全相连的, 容量较小(4-16)
-
VC相当于是L1-cache的一个Exclusive Cache
2.2.5 Filter Cache
-
VC是在L1 Cache之后, 而FC是在L1 Cache之前, 当一个数据第一次被使用, 不会放到L1 中,而是放到FC中, 再次被使用才会放入Cache
-
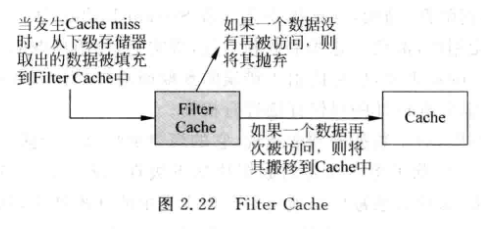
-
可以过滤一些偶然使用的数据
2.2.5 预取
- 硬件预取:
-
指令是很容易预取的(顺序特性), 通常可以将指令预取一部分到一个buffer
-
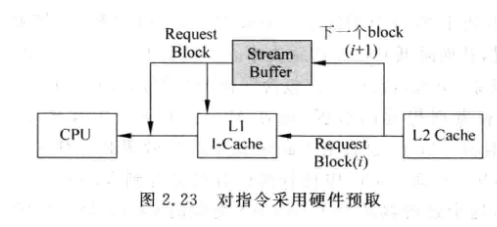
-
对于数据的预取, 通常是将要访问的数据的下一个数据快也预取出来
-
- 软件预取:
- 编译器知道程序的细节, 所以可以通过编译器控制程序进行预取
2.3 多端口Cache
- 超标量处理器一次可以取出多条指令, 因此需要多端口的Cache
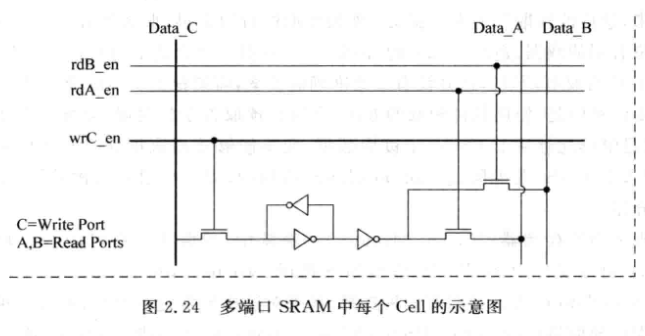
2.3.1 True Multi-port
-
SRAM中的每个Cell都需要支持两个读端口
-
-
面积, 延时, 功耗都会增大, 一般不会这么使用
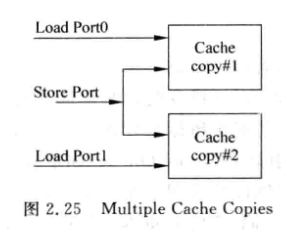
2.3.2 Multiple Cache Copies
- 直接复制一份, 相当于pingpong
- 面积和功耗浪费都更大
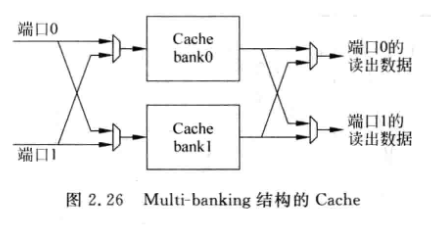
2.3.3 Multi-banking
-
将Cache分成多个bank, 每个bank都只有一个端口, 只要保证一个周期内Cache的访问地址们不在同一个bank中即可
-
-
可以增加bank数来减少bank冲突
2.3.4 AMD Opteron的多端口Cache
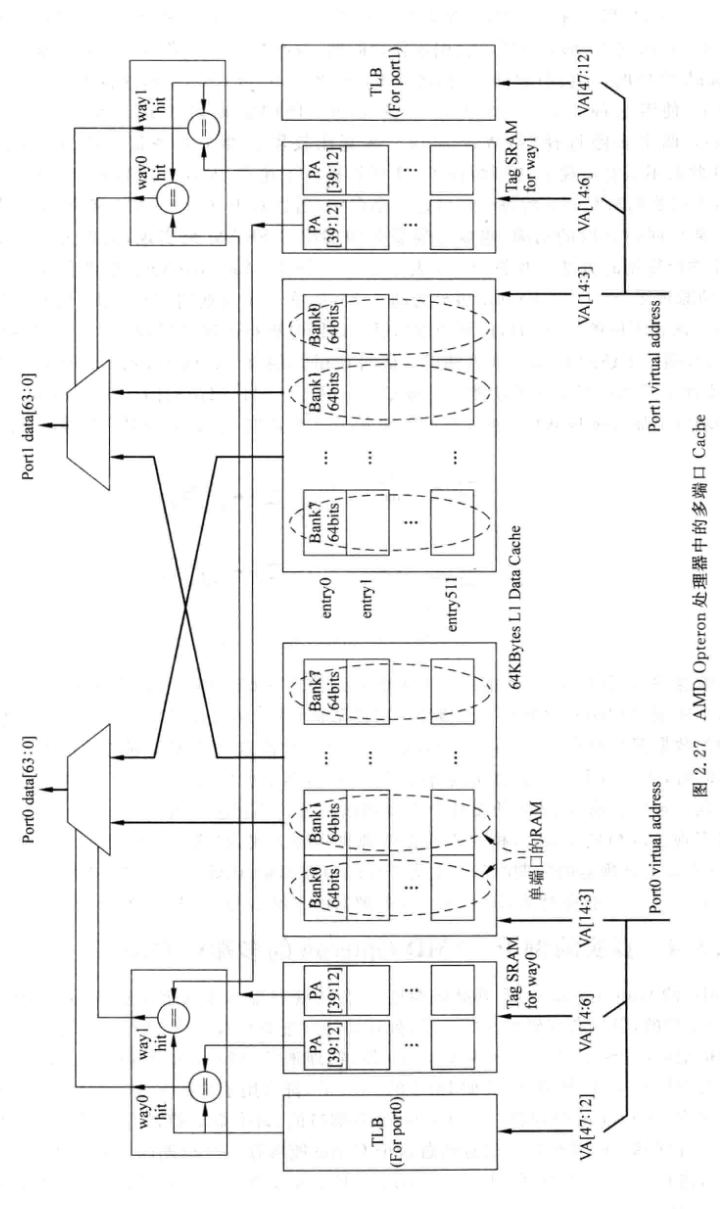
- 数据块分成8个bank
- 2-way, 两路的电路采用复制的方法
- Virtually-indexed, Physicaly-tagged, 直接使用VA寻址Cache
-
2.4 超标量处理器的取指令
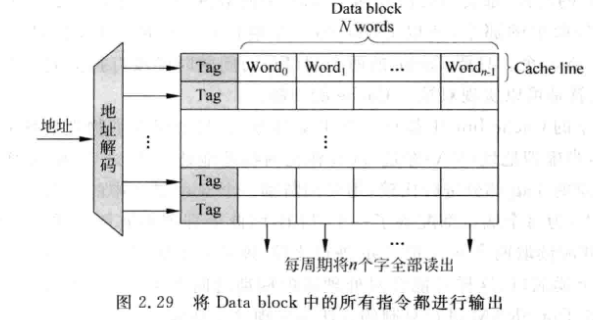
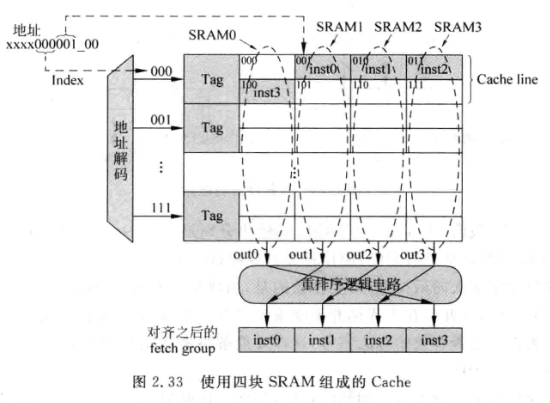
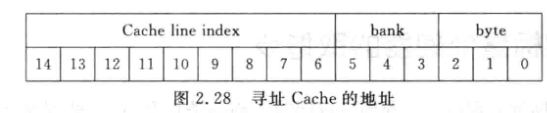
- 对于一个32位n-way的超标量处理器(一个周期可以取n条指令),如果取指令地址是n字对齐的, 那么就可以一个周期取出n条指令
- 实际情况是取指令很可能不是n个字对齐的,例如分支跳转到一个非n字对齐的地址。此时一次只能从cache line中读出一部分fetch group:
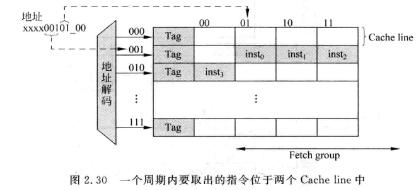
- 通常取指会将取出来的指令放到指令缓存(Instruction Buffer)中, 这样可以保证即使某一次没有取出一个完整fetch group的指令, 仍能保证后续流水线能被取到足够的指令
- 当第一条指令位于00位置, 一次可以取4条;当位于01, 一次可以取3条...可以推算出这种类型的cache每个周期可以取指的个数是1/4*4+1/4*3+1/4*2+1/4*1 = 2.5, 对于一个4-way的处理器来说就不太够了
- 当然上面的分析是基于四种情况都是等概率事件发生的,而实际上过于悲观, 因为某次不对齐取指后,下一次就是对齐的了;也就是说实际每周期取指个数>2.5
- 如何提升每周期取指个数?
- 一种方式是增加每个line的数据量,例如一个拥有8字的line的cache,它的每周期平均指令个数是3.25
- 仍然采用4个字的line, 但让每个tag管两行line,通过一个重排逻辑得到正确顺序的4条指令(处理跨行的情况):