
VIM插件 -- 自动生成verilog module的testbench
VIM插件 -- 自动生成verilog module的testbench
@(VIM)
1. 动机
软件语言都有各自好用的IDE,各种自动补全,高亮,语法检查。而苦逼的ICer大多还操着远古时期的VIM写着verilog。也是,硬件语言本身就小众,即使是xilinx, altera等大厂的vivado, quartus等大牌软件,自带的代码编辑器也不是很友好。好在号称编辑器之神的VIM提供了丰富的定制化功能,vimscript可以实现诸多媲美成熟IDE的功能。此外,vimscript还配备了很多语言的编程接口,perl,python的脚本都可以在vimscript里运行,这也使得开发插件的门槛降低了不少。
在某次写verilog的testbench时,觉得从写完一个模块,到验证其功能的路上花了大量时间在一些重复的coding上,testbench中大部分内容都是重复模块的端口定义,完全可以让脚本去干,于是花了半天尝试着用python写了一套自动生成verilog modual 的testbench的脚本,嵌入到vim中,通过简单的命令就可以实现繁琐的testbench的模板生成。顺便,,,也巩固一下python的正则表达式写法。话不多说,直接上代码。
2. 代码
"-------------------------------------------------------------------
" auto testbench (python)
"-------------------------------------------------------------------
:nnoremap <leader>tb :call Autotb()<cr>
function! Autotb()
python << EOF
import vim,re
# 清除所有注释内容
def clear_commonts(lines):
block_comment_index = [] # record block comment index
# remove // comment
for i in range(len(lines)):
lines[i] = re.sub('//.*$','',lines[i])
all_pairs = re.findall('/\*',lines[i])
if(all_pairs != []):
next_index = 0
new_line = lines[i]
for j in range(len(all_pairs)):
# print(new_line)
find_index = re.search('/\*',new_line).span()
next_index = find_index[1]
new_line = new_line[next_index:]
block_comment_index.append(i)
if(re.search('\*/',new_line)!=None): # find paired */
block_comment_index.append(i)
else:
if(re.search('\*/',lines[i])!=None): # find paired */
block_comment_index.append(i)
# print(block_comment_index)
if(len(block_comment_index)%2!=0):
raise('ERROR: /* and */ not paired')
else:
for i in range(int(len(block_comment_index)/2)):
left_index = block_comment_index[i*2]
right_index = block_comment_index[i*2+1]
if(left_index==right_index): # inline /* */
lines[left_index] = re.sub('/\*.*\*/','',lines[left_index])
else:
for j in range(left_index+1,right_index): # delet comment in block /* */
lines[j] = ''
lines[left_index] = re.sub('/\*.*$','',lines[left_index])
lines[right_index] = re.sub('^.*\*/','',lines[right_index])
return lines
# 找到模块名
def find_inst_name(line):
pattern = re.compile('(module)\s+(\w+)')
if(pattern.search(line)!=None):
return pattern.search(line).group(2)
else:
return ''
# 文本行转换为字符串
def lines2string(lines):
string = ''
for l in lines:
string += l
return string
# 获取输入输出端口名以及位宽,符号
def find_port_and_width(s):
signed_flag = 0
l_tmp = re.sub('(input)|(output)|(inout)','',s,1) # count=1 will not sub these word in signal name
l_tmp = re.sub('(wire)|(reg)','',l_tmp,1)
if(re.search('\sunsigned[\s\[]',l_tmp)!=None):
signed_flag = 'unsigned'
elif(re.search('\ssigned[\s\[]',l_tmp)!=None):
signed_flag = 'signed'
else:
signed_flag = ' '
l_tmp = re.sub('(signed)|(unsigned)','',l_tmp,1)
l_tmp = re.sub('\s','',l_tmp)
if(re.search('\[.+\]',l_tmp)!=None):
width = re.search('\[.+\]',l_tmp).group(0)
l_tmp = re.sub('\[.+\]','',l_tmp)
else:
width = '1'
#print(l_tmp)
if(re.search('\w+(?=[;,\s\)])',l_tmp)!=None):
port_name = re.search('\w+(?=[;,\s\)])',l_tmp).group(0)
else:
raise('Port name lost!')
print(width,port_name,signed_flag)
return width,port_name,signed_flag
# 寻找模块例化中定义段parameter变量
def find_parameter(s):
l_tmp = re.sub('\s','',s)
name_search = re.search('\w+(?=\=)',l_tmp)
val_search = re.search('(?<=\=)[\w\+\-\*/\%\$\'`]+',l_tmp)
if(name_search!=None):
name = name_search.group(0)
else:
name = ''
if(val_search!=None):
val = val_search.group(0)
else:
val = ''
return name,val
# 寻找模块的输入输出
def find_input_output(lines):
inst_dict = {'name':'','input':[],'output':[],'inout':[],'para':[]}
string = lines2string(lines)
inst_dict['name'] = find_inst_name(string)
if inst_dict['name'] == '':
raise('Inst name lost!')
output_pattern = re.compile('\Woutput[\[\s][\w\s\[\]:\+\-\*/\(\)%\{\}\'`]*[,;]') # include 0-9 a-z A-Z [:] \n
input_pattern = re.compile('\Winput[\[\s][\w\s\[\]:\+\-\*/\(\)%\{\}\'`]*[,;]') # include 0-9 a-z A-Z [:] \n
inout_pattern = re.compile('\Winout[\[\s][\w\s\[\]:\+\-\*/\(\)%\{\}\'`]*[,;]') # include 0-9 a-z A-Z [:] \n
input_list = input_pattern.findall(string)
output_list = output_pattern.findall(string)
inout_list = inout_pattern.findall(string)
para_search_end_index = input_pattern.search(string).span()[0]
# print (string[:para_search_end_index])
para_pattern = re.compile('\Wparameter\s+[\s\w\[\]:\+\-\*/\(\)%\{\}\=,\'`]*')
para_search = para_pattern.search(string[:para_search_end_index])
if(para_search!=None):
para_string = para_search.group(0)
#print(para_string)
para_string = ' '+para_string
para_string = re.sub('\sparameter\s','',para_string)
para_list = para_string.split(',')
# print(para_list)
for l in para_list:
inst_dict['para'].append(find_parameter(l))
else:
inst_dict['para'] = []
for l in input_list:
inst_dict['input'].append(find_port_and_width(l))
for l in output_list:
inst_dict['output'].append(find_port_and_width(l))
for l in inout_list:
inst_dict['inout'].append(find_port_and_width(l))
return inst_dict
def max_len(ll,mode=0):
max_len = 1
for l in ll:
if(len(l[mode])>max_len):
max_len = len(l[mode])
return max_len
def build_input_port_tb(in_list,mode='input'):
max_in_len_width = max_len(in_list,0)
max_in_len_signed = max_len(in_list,2)
string = ''
net_type = {'input':'reg','output':'wire','inout':'wire'}
for in_port in in_list:
in_name = in_port[1]
width = in_port[0] if in_port[0]!='1' else ''
signed_type = in_port[2]
added_len_signed = max_in_len_signed - len(signed_type)
added_len_width = max_in_len_width - len(width)
s = '%s %s '%(net_type[mode],signed_type) + added_len_signed*' '
s += '%s'%(width) + added_len_width*' ' + ' %s;\n'%(in_name)
#print(max_in_len_width)
#print(max_in_len_signed)
string += s
return string
def build_para_tb(in_list):
max_in_len = max_len(in_list,0)
string = ''
for in_port in in_list:
in_name = in_port[0]
number = in_port[1]
added_len = max_in_len - len(in_name)
s = 'parameter %s '%(in_name) + added_len*' '+'= %s;\n'%(number)
string += s
return string
# 寻找模块中的clk和rst
def find_clk_and_rst(in_list):
clk = ''
rst = ''
for l in in_list:
name = l[1]
if(re.search('clk',name,re.I)!=None):
clk = name
break
for l in in_list:
name = l[1]
if(re.search('rst',name,re.I)!=None):
rst = name
break
return clk,rst
def input_initial_tb(in_list,rst):
string = 'initial begin\n'
for l in in_list:
if(l[1]!=rst):
s = ' %s = 0;\n'%l[1]
string += s
rst_kind = re.search('(?<=rst)_?n',rst,re.I)==None #1:rst, 0:rst_n
string += ' %s = %d;\n #4 %s = %d; #2 %s = %d;\n'%(rst,1-rst_kind,rst,rst_kind,rst,1-rst_kind)
string += 'end\n'
return string
# 生成模块例化代码
def build_inst(inst_dict):
inst_name = inst_dict['name']
name_len = len(inst_name)
string = inst_name
if(inst_dict['para']==[]):
para_string = ' '
else:
para_string = ' #('
para_max_in_len = max_len(inst_dict['para'],0)
for i,para_port in enumerate(inst_dict['para']):
para_name = para_port[0]
number = para_port[1]
added_len = para_max_in_len - len(para_name)
s = (i!=0)*(name_len+3)*' '+' .%s '%(para_name) + added_len*' '+'( '+ para_name +added_len*' '+' )'+(i!=len(inst_dict['para'])-1)*','+(i==len(inst_dict['para'])-1)*')'+'\n'
para_string += s
string += para_string
string += 'U_'+ inst_name.upper()+'_0\n'
# port inst
port_list = inst_dict['input']+inst_dict['output']+inst_dict['inout']
port_max_in_len = max_len(port_list,1)
port_string = '('
for i,port in enumerate(port_list):
port_name = port[1]
added_len = port_max_in_len - len(port_name)
# print(port_list)
s = (i!=0)*' '+' .%s '%(port_name) + added_len*' '+'( '+ port_name + added_len*' '+' )'+(i!=len(port_list)-1)*','+(i==len(port_list)-1)*');'+'\n'
port_string += s
string += port_string
return string
# 增加dumpvar相关命令,vcs+verdi调试需要
def add_dumpvars():
string = '\ninitial begin\n $fsdbDumpvars();\n $fsdbDumpMDA();\n $dumpvars();\n #1000 $finish;\nend'
return string
# 增加头部信息
def add_head(name,author='Yicheng Lu'):
import time
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
year = now_time[0:4]
string = "// -----------------------------------------------------------------\n// Copyright (c) %s .\n// ALL RIGHTS RESERVED\n// -----------------------------------------------------------------\n// Filename : %s.v\n// Author : %s\n// Created On : %s\n// Last Modified :\n// -----------------------------------------------------------------\n// Description:\n//\n// -----------------------------------------------------------------\n"%(year,name,author,now_time)
return string
# 生成tb
def build_tb(inst_dict):
string = add_head(name=inst_dict['name']+'_tb')
string += '\n`timescale 1ns/1ps\n\n'
string += 'module %s();\n\n'%(inst_dict['name']+'_tb')
string += build_para_tb(inst_dict['para'])
string += '\n'
string += build_input_port_tb(inst_dict['input'],'input')
string += '\n'
string += build_input_port_tb(inst_dict['output'],'output')
string += '\n'
string += build_input_port_tb(inst_dict['inout'],'inout')
clk,rst = find_clk_and_rst(inst_dict['input'])
string += '\nalways #1 %s = ~%s;\n'%(clk,clk)
string += input_initial_tb(inst_dict['input'],rst)
string += '\n'
string += build_inst(inst_dict)
string += '\n'
string += add_dumpvars()
string += '\n'
string += '\nendmodule\n'
return string
lines = []
for l in vim.current.buffer[:]:
lines.append(l+'\n') # string in buffer do not contain '\n'
clear_lines = clear_commonts(lines)
inst_dict = find_input_output(clear_lines)
tb_string = build_tb(inst_dict)
# 调用vim的python接口,生成一个新的窗口,在新窗口构建tb
vim.command("badd %s"%(inst_dict['name']+'_tb.v'))
buffer_num = len(vim.buffers)
print(buffer_num)
vim.command("tabnew")
vim.command("b"+str(buffer_num))
vim.current.buffer[:] = tb_string.split('\n')
#vim.command('NERDTree')
EOF
endfunction
3. 使用方法
以上脚本需要复制粘贴到vim的配置文件.vimrc中即可生效。需要系统装有python,如果系统装的python是python3,需要修改
:nnoremap <leader>tb :call Autotb()<cr>
function! Autotb()
python << EOF
为
:nnoremap <leader>tb :call Autotb()<cr>
function! Autotb()
python3 << EOF
使用时,用vim打开某个.v,按\(\color{red}{\tb}\)即可生成当前verilog的testbench模板。
4. 效果
需要生成testbench的verilog文件:

按下\(\color{red}{\tb}\)后:
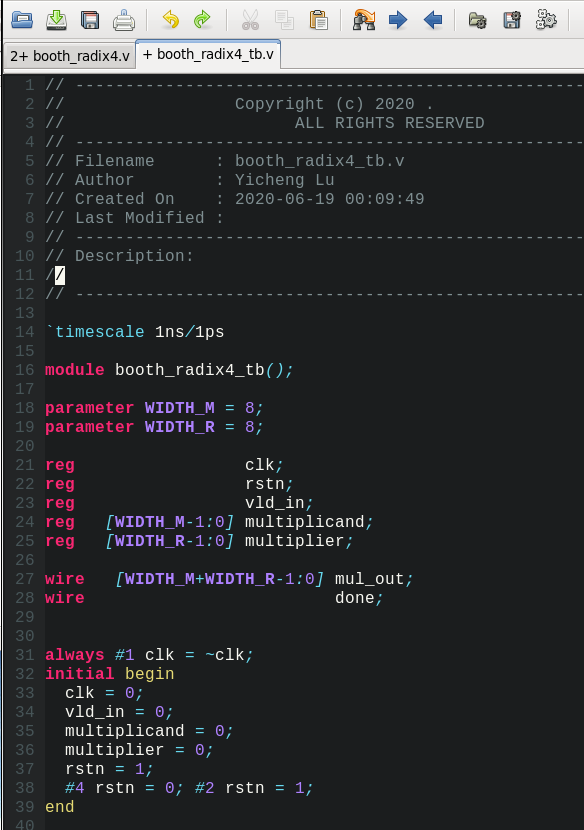
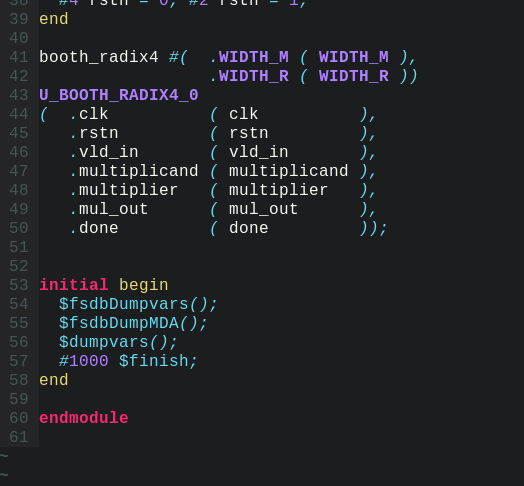
后面只需要添加特定的激励即可,初始化和例化都已经自动生成了。
5. 说明
由于只是自己一时兴起而写,虽然用到现在没出过错,但不排除某些特殊情况会出错。此外,对verilog 1995标准的写法支持仍不够完善,实测module中带有参数的1995标准写法在run该脚本时会有问题,其他情况暂时没发现问题。对于2001标准的写法应该是没有太大问题(如果有发现问题欢迎留言,以便改进)。如果有自己的testbench的风格,可以直接修改代码中tb生成部分的代码。

