Verilog -- SPI协议
Verilog -- SPI协议
简介
SPI是一种全双工通信,并且是一种同步传输方式(slave的接收clk需要master给出)
SPI总线是一种4线总线,因其硬件功能很强,所以与SPI有关的软件就相当简单,使中央处理器(Central Processing Unit,CPU)有更多的时间处理其他事务。正是因为这种简单易用的特性,越来越多的芯片集成了这种通信协议,比如AT91RM9200。SPI是一种高速、高效率的串行接口技术。通常由一个主模块和一个或多个从模块组成,主模块选择一个从模块进行同步通信,从而完成数据的交换。SPI是一个环形结构,通信时需要至少4根线(事实上在单向传输时3根线也可以)。
SPI的通信原理很简单,它以主从方式工作,这种模式通常有一个主设备和一个或多个从设备,需要至少4根线,事实上3根也可以(单向传输时)。也是所有基于SPI的设备共有的,它们是MISO(主设备数据输入)、MOSI(主设备数据输出)、SCLK(时钟)、CS(片选)。
(1)MISO– Master Input Slave Output,主设备数据输入,从设备数据输出;
(2)MOSI– Master Output Slave Input,主设备数据输出,从设备数据输入;
(3)SCLK – Serial Clock,时钟信号,由主设备产生;
(4)CS – Chip Select,从设备使能信号,由主设备控制。
其中,CS是从芯片是否被主芯片选中的控制信号,也就是说只有片选信号为预先规定的使能信号时(高电位或低电位),主芯片对此从芯片的操作才有效。这就使在同一条总线上连接多个SPI设备成为可能。
(以上来自百度百科)

SPI最大传输速率
SPI是一种事实标准,由Motorola开发,并没有一个官方标准。已知的有的器件SPI已达到50Mbps。具体到产品中SPI的速率主要看主从器件SPI控制器的性能限制。
受以下几个条件影响:
SPI的最大时钟频率
CPU处理SPI数据的能力
输出端驱动能力(PCB所允许的最大信号传输速率)
SPI的最大时钟频率
一般情况下,SPI模块的最大时钟频率为系统时钟频率的1/2。虽然SPI的传输速率主要受限于CPU处理SPI数据的能力,但在同另一个非常高速率的SPI设备通讯时,SPI的最大时钟频率将有可能制约其传输速率。
CPU处理SPI数据的能力
通常情况下,考虑到系统中CPU有可能需要处理其他任务,以及对所接收SPI数据的具体运算处理方法,CPU处理SPI数据的能力将影响到整体的传输速率。
下面是verilog代码:
module spi_master
(
input I_clk , // 全局时钟50MHz
input I_rst_n , // 复位信号,低电平有效
input I_en , // en信号
input [7:0] I_data_in , // 要发送的数据
output reg [7:0] O_data_out , // 接收到的数据
output reg O_tx_done , // 发送一个字节完毕标志位
output reg O_rx_done , // 接收一个字节完毕标志位
// 四线标准SPI信号定义
input I_spi_miso , // SPI串行输入,用来接收从机的数据
output reg O_spi_sck , // SPI时钟
output reg O_spi_cs , // SPI片选信号
output reg O_spi_mosi // SPI输出,用来给从机发送数据
);
reg [3:0] R_state ;
always @(posedge I_clk or negedge I_rst_n)
begin
if(!I_rst_n)
begin
R_state <= 4'd0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_data_out <= 8'd0 ;
end
else if(I_en) // en信号打开的情况下
begin
O_spi_cs <= 1'b0 ; // 把片选CS拉低
R_state <= R_state + 1'b1 ;
case(R_state)
// 发送
4'd0: // 发送第7位
begin
O_spi_mosi <= I_data_in[7] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd2: // 发送第6位
begin
O_spi_mosi <= I_data_in[6] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd4: // 发送第5位
begin
O_spi_mosi <= I_data_in[5] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd6: // 发送第4位
begin
O_spi_mosi <= I_data_in[4] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd8: // 发送第3位
begin
O_spi_mosi <= I_data_in[3] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd10: // 发送第2位
begin
O_spi_mosi <= I_data_in[2] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd12: // 发送第1位
begin
O_spi_mosi <= I_data_in[1] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b0 ;
end
4'd14: // 发送第0位
begin
O_spi_mosi <= I_data_in[0] ;
O_spi_sck <= 1'b0 ;
O_tx_done <= 1'b1 ;
end
// 接收
4'd1: // 接收第7位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[7] <= I_spi_miso ;
end
4'd3: // 接收第6位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[6] <= I_spi_miso ;
end
4'd5: // 接收第5位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[5] <= I_spi_miso ;
end
4'd7: // 接收第4位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[4] <= I_spi_miso ;
end
4'd9: // 接收第3位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[3] <= I_spi_miso ;
end
4'd11: // 接收第2位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[2] <= I_spi_miso ;
end
4'd13: // 接收第1位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[1] <= I_spi_miso ;
end
4'd15: // 接收第0位
begin
O_spi_sck <= 1'b1 ;
O_rx_done <= 1'b1 ;
O_data_out[0] <= I_spi_miso ;
end
default:R_state <= 4'd0 ;
endcase
end
else
begin
R_state <= 4'd0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_data_out <= 8'd0 ;
end
end
endmodule
testbench:
`timescale 1ns/1ps
module spi_master_tb();
reg I_clk;
reg I_rst_n;
reg I_en;
reg [7:0]I_data_in;
wire [7:0]O_data_out;
wire O_tx_done;
wire O_rx_done;
wire I_spi_miso;
wire O_spi_sck;
wire O_spi_cs;
wire O_spi_mosi;
always #1 I_clk = ~ I_clk;
assign I_spi_miso = O_spi_mosi;
integer i;
initial begin
I_clk = 1;
I_en = 0;
I_data_in = 0;
I_rst_n = 1; #2 I_rst_n = 0; #2 I_rst_n = 1;
#20;
@(posedge I_clk) begin
I_en <= 1;
I_data_in <= 0;
end
for(i=1;i<20;i=i+1) begin
@(negedge O_tx_done) begin
I_data_in <= i;
end
end
I_en <= 0;
end
spi_master U_SPI_MASTER_0(
.I_clk ( I_clk ),
.I_rst_n ( I_rst_n ),
.I_en ( I_en ),
.I_data_in ( I_data_in ),
.O_data_out ( O_data_out ),
.O_tx_done ( O_tx_done ),
.O_rx_done ( O_rx_done ),
.I_spi_miso ( I_spi_miso ),
.O_spi_sck ( O_spi_sck ),
.O_spi_cs ( O_spi_cs ),
.O_spi_mosi ( O_spi_mosi )
);
initial begin
$fsdbDumpvars();
$fsdbDumpMDA();
$dumpvars();
#1000 $finish;
end
endmodule
仿真波形:
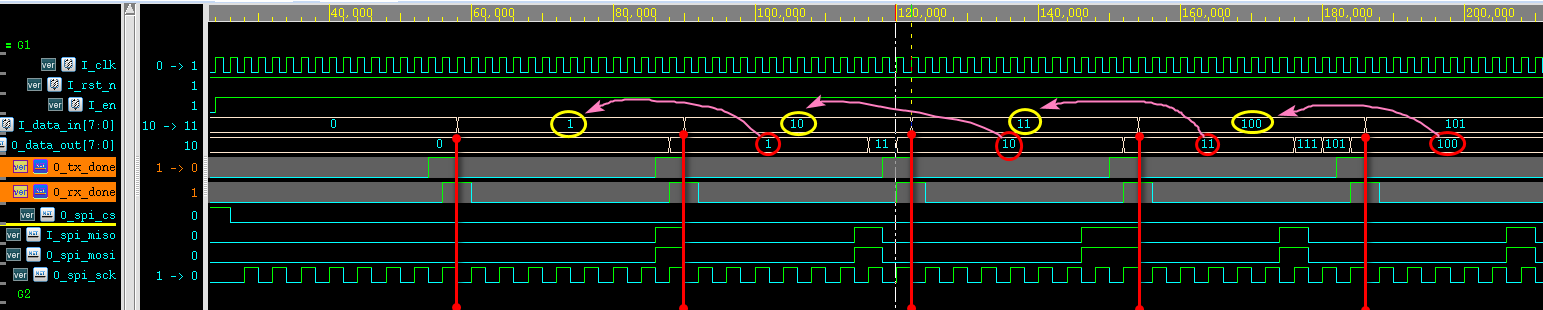
测试程序中将MOSI和MISO短接了,所以spi发送的数据被自己接收,从波形图中可以看到,发送和接收的逻辑正确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号