Tangram: Optimized Coarse-Grained Dataflow for Scalable NN Accelerators 阅读笔记
Tangram: Optimized Coarse-Grained Dataflow for Scalable NN Accelerators
@(论文笔记)
1.Abstract
- 针对层内并行性提出了buffer sharing dataflow。可以将分布式buffer组织为一种共享的buffer,避免了数据的复制与访存。
- 针对层间的pipline,设计了一种alternate layer loop ordering的方法,可以将暂存的数据以一种更加粗粒化的方式进行传播,减小了buffer的需求和pipline延迟。
- 针对复杂的有向无环结构(google net)做了优化。
2.Introduction
提出了两个问题:
- Parallelizing a single NN layer (intra-layer parallelism) leads to signifcant data duplication 层内的卷积并行化导致了很多数据的复制(从一个buffer复制到另一个buffer)
- pipeliningthe processing of multiple layers (inter-layer pipelining) results in substantial challenges in resource utilization and on-chip buffer requirements (在层间流水线设计时,对资源利用率以及片上buffer提出了很大挑战)
解决:
- Tangram. 一种分块加速器数据流,对粗粒度并行化进行了优化
- 对于层内的并行计算,提出了一种buffer sharing dataflow (BSD),消除了buffer之间数据复制的低效。使得原来分布的sram存储整合为靠近tile pe的共享buffer,
- 对于层间的流水线,alternate layer loop ordering (ALLO) dataflow,减少了对片上缓存的要求以及流水线的延迟。
- 对于有向无环的结构做了优化,最小化这些结构对片外存储的依赖。
3.Background
本文的NN engine与eyeriss相同:
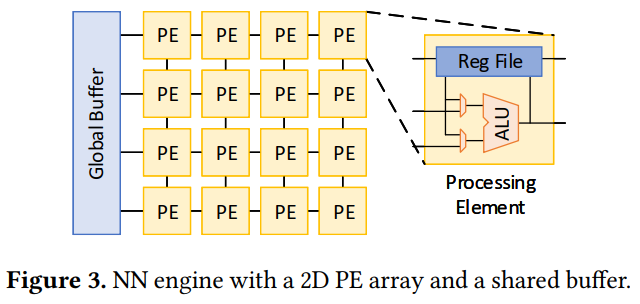
这种结构的问题:
- 简单增加PE数量并不高效。
- 小的网络层无法完全利用pe阵列。
- 再更换fmap时会有较高的延迟以及能耗
- 大的面积导致长的数据传播路径
- 单片PE阵列无法处理层间的pipline
采用的是scaling NN accelerators 可以解决这些问题:
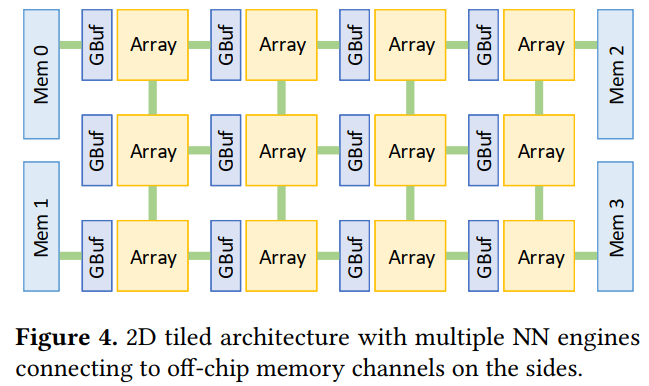
pe通过NoC与其他pe通信,并且可以直接与片外存储通信。而每个array内则是细粒化的并行结构。把类似SIMD的并行架构称作fine-grained parallelism细粒度并行,而多核作为coarse-grained parallelism粗粒度并行
主要有两种粗粒度并行方案:
- 层内的并行,包括batch、fmap、output和input的并行。
- 层间的pipline
其中,层间的pipline可以高效的利用硬件资源,尤其是在处理某些比较小的层(目前的趋势就是层数变多,大小变小)或者硬件资源富余时。另外在处理一些有向无环的结构时,可以利用NoC传播fmap减少了片外访存。
4.Baseline Architecture and Its Inefciencies
baseline 硬件结构:
- 16*16tiles
- Eyeriss-like NN engine that includes an 8 × 8 PE array and a 32 kB private SRAM
Baseline intra-layer dataflow:
- TETRIS
- ScaleDeep
主要问题:
- 数据浪费,每个engine的缓存都持有一份当前数据的拷贝。并且从表一可以发现,没有一种层内的并行可以完全将数据分割进不同的pe,多少会存在数据需要共享复制到另一个pe中的情况。
Baseline inter-layer pipelining:
当前的层间pipline结构都需要充足的硬件资源才能实现。
本文的层间pipline是通过:
- 将原先多层的网络分割为若干个segments
- 每次,只有一个segment的结构会被映射到pe上
- 每层占用的片上资源与其计算量成正比
- 只有第一层和最后一层才有片外访存的权限
此外,内部的大块GLB需要在外部存储于内部buffer之间搬运大部分数据,非常低效,尤其是当要缓存一个segment的数据时。
并且,整个数据流是顺序进行的,下一层的输入需要等待上一层的输出完全结束才能开始
还不支持有向无环的结构。
5.Tangram Parallel Dataflows
Intra-Layer Parallelism with Buffer Sharing
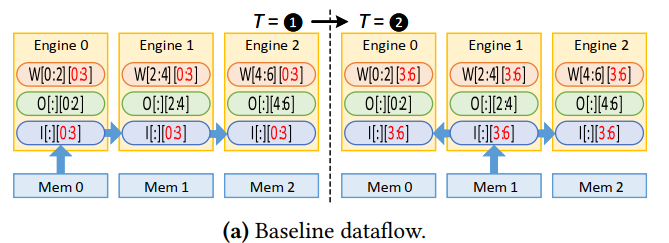
上面的图是传统的eyeriss的数据流,一份数据将会在pe之间复制若干份。这种方式浪费了片上buffer资源, 并没有充分利用数据复用。
Buffer sharing dataflow (BSD)

提出了改进的方案:BSD
第一个时间步时从外部mem内将不同的feature导入pe,在第二个时间步,pe之间通过NoC获得临近pe之间的data,直到ifmap将输出ofmap更新完。
更完整的数据流如下:
 首先将weight垂直调换,计算输出map后在进行水平的fmap循环。示意图如下
首先将weight垂直调换,计算输出map后在进行水平的fmap循环。示意图如下
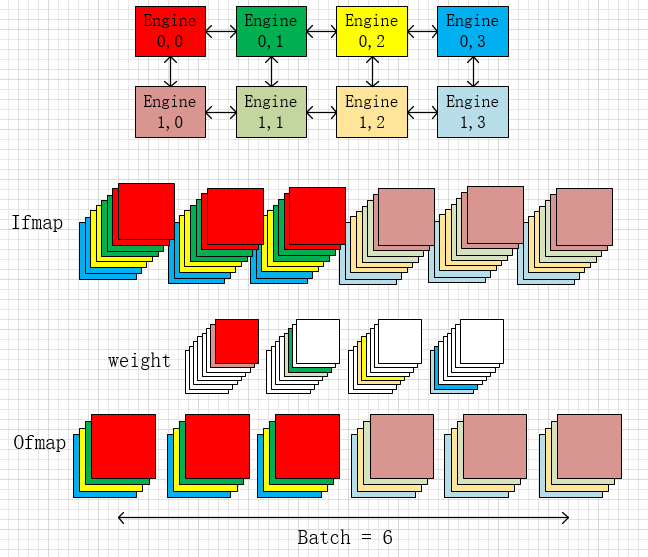
Loop transformation model for BSD
从代码循环来看:

ti,to,tb是分块系数(分成多少块),每个buffer存储1/t的数据,数据需要rotate的次数等于to,也就是输出map的分块数。
BSD benefts:
- 通过使用BSD, 可以发现,在数据读入阶段,之前的数据流一次只能读入一块ifmap,而现在的数据流可以一次读入Po块ifmap,从数据读取来看,每次从外部存储读数据的次数从ti次减少为ti/Po次。
- 此外,在转换层计算时,如果没有BSD, 每个计算单元需要将结果存入外部,在下一层计算时再从外部读入。而使用BSD可以直接将计算出的结果传入计算下一层的engine。
实际上,BSD等效于一种理想的足够大的片内存储,可以将所有数据存入而无需复制数据。通过将数据调取和循环结合起来,数据总是再内部buffer之内流动。
Inter-Layer Pipelining with ALLO
Alternate layer loop ordering (ALLO)
L-1处理0-2个batch的8输入通道的ifmap,输出0-3的ofmap。如果下一层L-2的输入是接收0-3的ofmap作为输入,则可以跟L-1的计算进行pipline,间隔一个fmap的计算时间。
限制:
- 如下图中的两个循环,第一个循环中,输出循环在输入循环之上,也就是说需要接收0-8的输入图片并计算才完成一次迭代,一次遍历输出一张完整的O输出图片。而由于下层的循环中,输入循环在输出循环之上,因此一张输入图片将更新6张输出图片,只有当4张输入完全遍历后输出图片 才是完整的卷积结果。因此,当上层(L-1)输出了一张完整的图片,下层(L-2)就可以立即接收并计算6张输出的部分卷积。
- 这种循环的组织方式可以将临近的两层pipline,但也只限于临近的两层。当考虑在L-2后再加入一层时,由于L-2卷积输出在当前batch的整个循环结束之前都是不完整的,因此无法继续组织这样的pipline,而是必须等待L-2层该batch的循环结束才能进行正常的卷积。因此这里的间隔时间将是一整个fmap。如下图中的L-3:
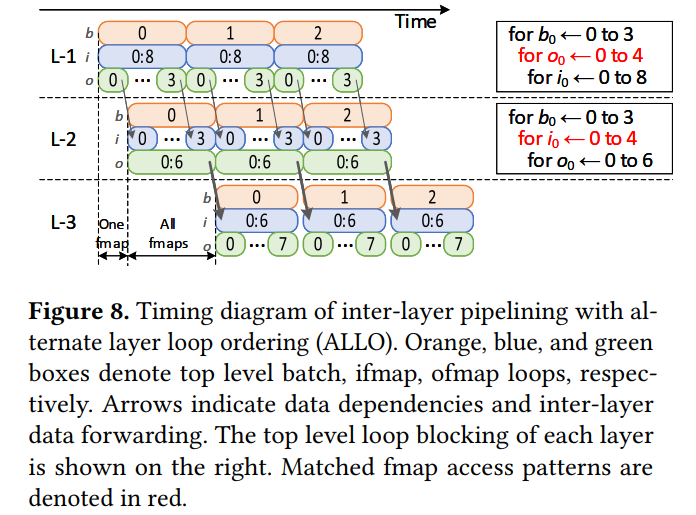
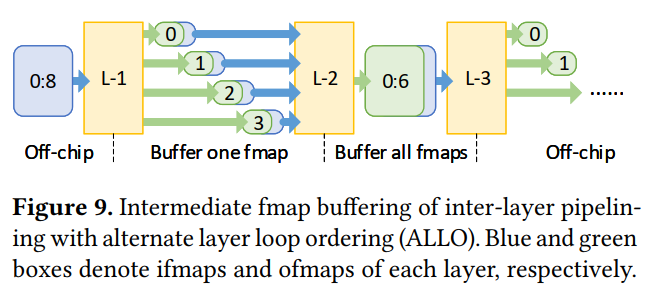
可见,两个相邻的层能pipline的条件是他们的输入输出分块参数t需要一致,也就是图中红色部分的循环。
ALLO benefts:
- 如果像上面提到的那样,临近的两层输入和输出的分块参数相同,都为t, 则ALLO可以减少t倍的流水线延时以及片内buffer存储。
- 但是ALLO只能将一个segment中l层中的一半进行高度pipline(原因上面也说明了)。也就是l层需要两两组合进行pipline(延迟是一张ofmap的计算时间),每个组合之间的pipline是batch层面的pipline(延时为一个batch的计算时间)。
Combining ALLO and BSD:
- 最大限度地节省了大量片内存储
Inter-Layer Pipelining for Complex NN DAGs
目前越来越多的网络出现了复杂的DAG类型(resnet, googlenet,LSTM等)的结构。因此本文针对这种复杂网络进行了分配策略的优化。
2D region allocation:
- ScaleDeep 中的设计时静态的1D的分配策略,也就是每层会分配一列或多列engines,fmap的数据时横向流动的。
- 而本文的分配策略是一种之字形的分配:
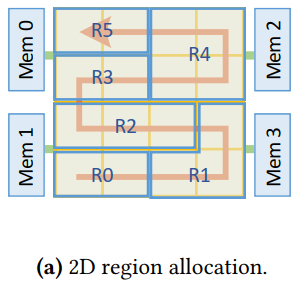
一行分配不下一层时,往上一行走。 好处:- 相比于1D(一整列为单位)的分配,这种分配更加细致
- 对于不临近的regions,比如R0和R3,在fmap data需要在他们之间传输(NAG结构会出现)时会有更短的路径。
Spatial layer mapping heuristics:
Segment selection:
- 只有当一个layer与其他segment中的layer有共享的数据时,才会被加入该segment
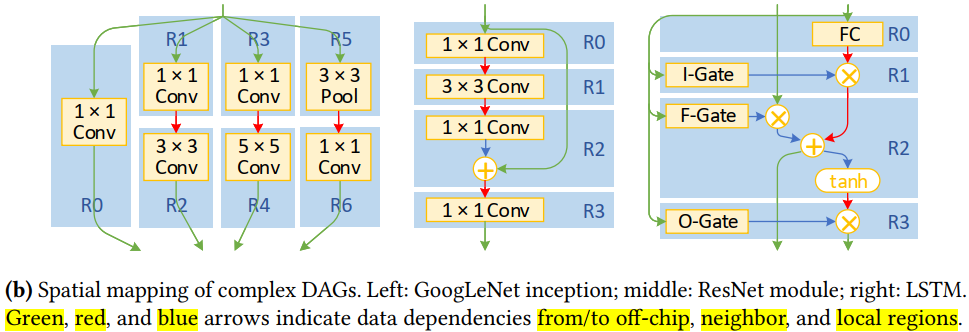
Region mapping:
- 将ACT,POOL 和element-wise 层都放进在他之前的卷积或全连接层。
- 在一个区域内(R)的层不允许接收多个临近区域的输入数据,只允许有一个。
Dataflow Optimizations for NN Training
由于在计算反向传播时,各个层的loss传播和gradient计算都依赖前向计算出来的激活值,因此反向网络也可以通过上面的方法映射到加速器上。
4. Tangram Implementation
包含两部分:
- (a) a search tool that identifes the optimized parallelization schemes for each NN
- (b) a compiler that produces the code for the selected schemes.
Hardware Support
- 之前的scaladeep 已经设计了一种支持有限数据在一层或多层间的计算模式,因此整个架构只需要按照complier生成的结构去运行即可,无需动态规划。
- 使用了scale deep中的MEMTRACK,监察在buffer中的数据是否已经被更新完等待读出,或者被读出完毕可以被重写。通过在buffer中设置一些缓冲行,可以防止死锁。
Dataflow Design Space Exploration
Code Generation
Result
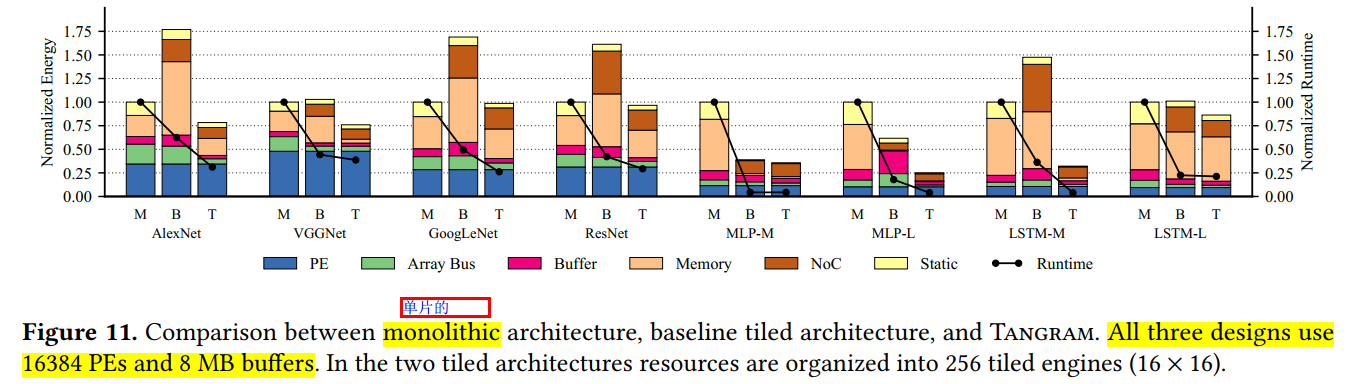
- monolithic:
- 耗费了大量(20%)能耗在array总线上,其性能受限于高的延迟以及数据广播机制
- 通过设定一个大的global buffer, 在层内的计算时较为高效的,避免了大量片外访存
- Baseline tile:
- 受制于数据复制,片内buffer缓存容量不足
- 有较高的片外访存以及NoC功耗,尤其是当fmap较大时
- Tangeram:
- BSD+ ALLO
- 支持Pipline的DAG结构
Parallel Dataflow Analysis
此外,还对比了层内(BSD)和层外优化(ALLO)的差异:
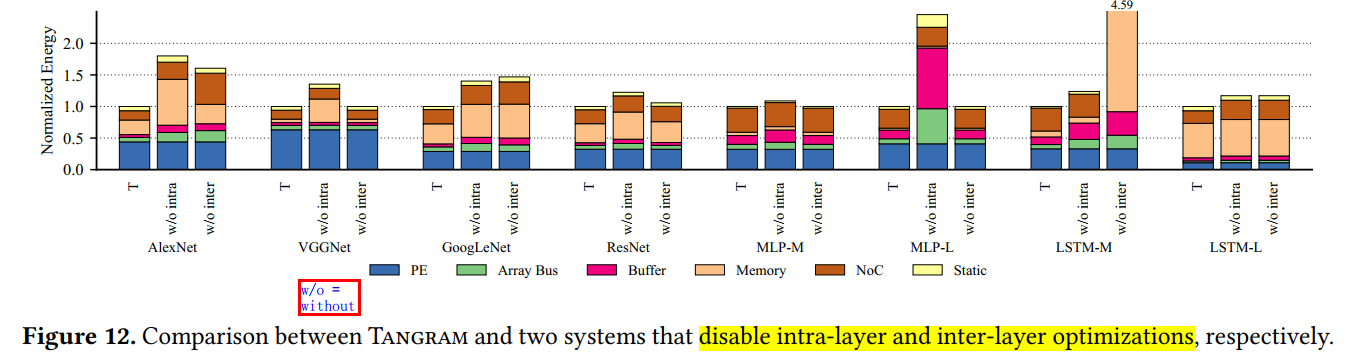
还对比了不同PE数量以及不同batch size 对这几种结构的影响:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号