ES的查询上下文、评分、元数据
一、元数据
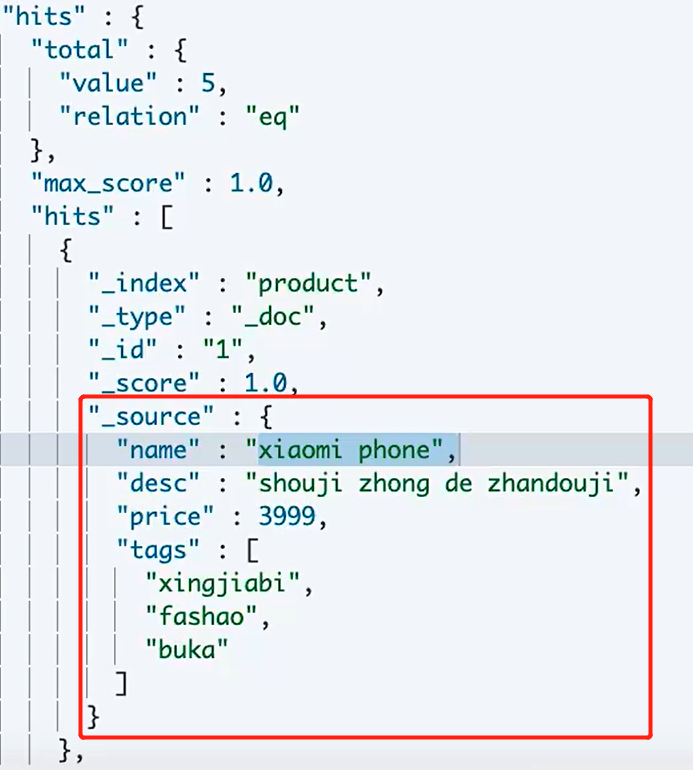
1、从索引中查询出的结果可以称之为元数据,如下图
2、可以禁止元数据的展示(一般不使用)
使用如下代码查询后,元数据将不再展示
1 GET product/_search 2 { 3 "_source": false, 4 "query": { 5 "match_all": {} 6 } 7 }
好处:节省存储开销
坏处:不支持update、update_by_query、reindex API
3、数据源过滤器
第一种:使用下图这种形式设置索引mapping,查询结果中只会包含name和price,不会包含desc和tags
1 PUT product1 2 { 3 "mappings": { 4 "_source": { 5 "includes": [ 6 "name", 7 "price" 8 ], 9 "excludes": [ 10 "desc", 11 "tags" 12 ] 13 } 14 } 15 }
第二种:在查询时指定include和exclude字段
1 GET product/_search 2 { 3 "_source": { 4 "includes": [ 5 "name" 6 ], 7 "excludes": [ 8 "age" 9 ] 10 }, 11 "query": { 12 "match_all": {} 13 } 14 }
二、全文检索
1、match:根据字段进行匹配。select * from table where name = '';
2、match_all:无条件匹配。select * from table;
3、multi_match:从指定“字段中匹配。select * from table where name=shouji and age=shouji;
1 GET product/_search 2 { 3 "query": { 4 "multi_match": { 5 "query": "shouji", 6 "fields": ["name","age"] 7 } 8 } 9 }
4、match_phrase:会被分词
被检索字段必须包含match_phrase中的所有词项并且顺序必须相同
被检索字段包含的match_phrase中的词项之间不能有其他问题
1 GET product/_search 2 { 3 "query": { 4 "match_phrase": { 5 "name": "my name" 6 } 7 } 8 }
如上代码:查询的name字段必须为my name,不能为my xx name、name my
三、精准查询
term:搜索词不会被分词
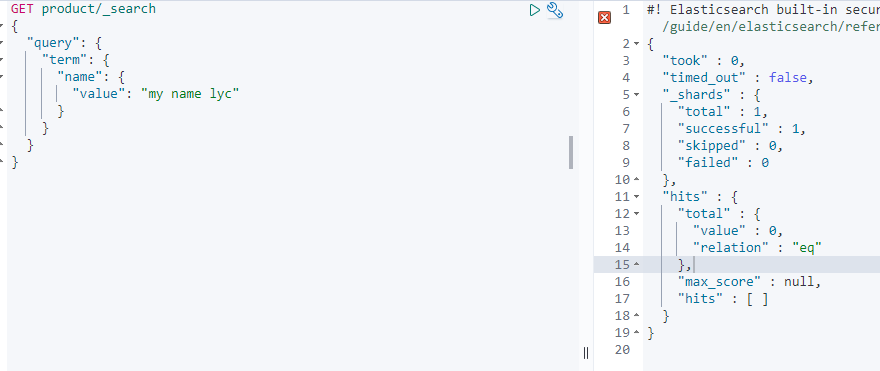
1、如下图查询没有结果是因为:搜索词没有被分词,所以my name lyc被当成一个整体。但是索引中my name lyc被分成了my、name、lyc。所有没有匹配记录
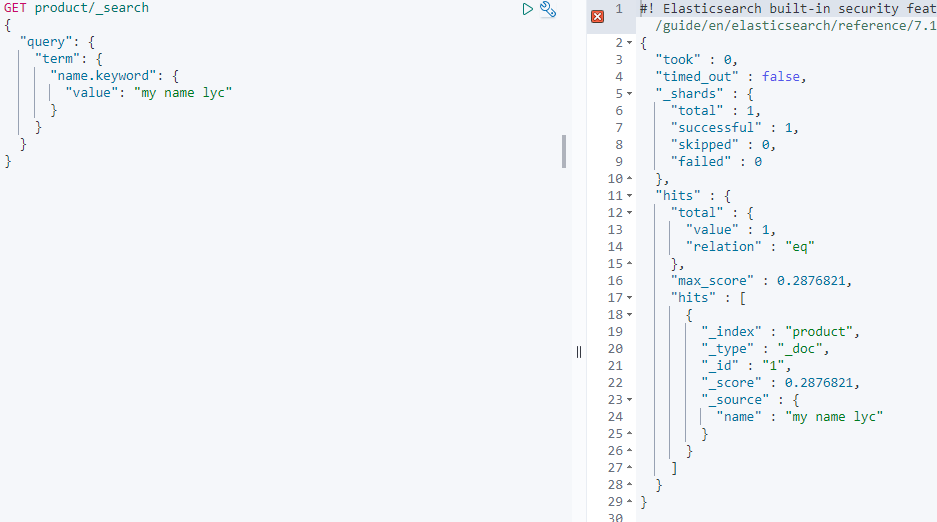
2、如下图就有结果,因为搜索词没有被分词,而索引中name字段取了keyword,也不会被分词。所以有匹配结果
3、terms
1 GET product/_search 2 { 3 "query": { 4 "terms": { 5 "tags": [ 6 "lowbee", 7 "gongjiaoka" 8 ] 9 } 10 } 11 }
4、range:范围查询
1 GET product/_search 2 { 3 "query": { 4 "range": { 5 "price": { 6 "gte": 10, 7 "lte": 20 8 } 9 } 10 } 11 }
四、过滤器
作用:筛选数据,不会计算相关度评分,提高效率
而query则是会计算相关度评分的
若数据量非常大的时候使用filter会降低性能开销
五、组合查询(bool query)
1、must:所有条件都必须符合相当于sql中的and
使用下面代码查询出的结果有相关度评分
1 GET product/_search 2 { 3 "query": { 4 "bool": { 5 "must": [ 6 { 7 "match": { 8 "name": "lyc" 9 } 10 } 11 ] 12 } 13 } 14 }
2、filter:将上图中must替换为filter。替换后查出的结果相关度评分为0。
3、must_not:所有条件都不符合的结果
4、should:或者,相当于sql中的or
5、must与filter组合使用
下面代码为must与filter组合使用,若样本很多时,可以先使用filter进行过滤(filter不计算相关度分数,节省了性能消耗),之后再使用match计算相关度评分。
1 GET product/_search 2 { 3 "query": { 4 "bool": { 5 "must": [ 6 { 7 "match": { 8 "name": "lyc" 9 } 10 } 11 ], 12 "filter": [ 13 { 14 "range": { 15 "age": { 16 "gte": 10 17 } 18 } 19 } 20 ] 21 } 22 } 23 }
6、should与filter或must组合使用时
minimum_should_match:若没有这个参数,should条件可以被忽略(不匹配)。后面的数字表示需要有几个should满足条件(若组合查询有must或者filter时该参数默认为0;若只有should,该参数默认为1;若需要满足其他场景,该参数需要手动设置)
1 GET product/_search 2 { 3 "query": { 4 "bool": { 5 "filter": [ 6 { 7 "range": { 8 "age": { 9 "gte": 10 10 } 11 } 12 } 13 ], 14 "should": [ 15 { 16 "match_phrase": { 17 "name": "my name" 18 } 19 } 20 ], 21 "minimum_should_match": 1 22 } 23 } 24 }
作者:http://cnblogs.com/lyc-code/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号