
Trie前缀树原理、FST的构建过程
一、前缀树原理
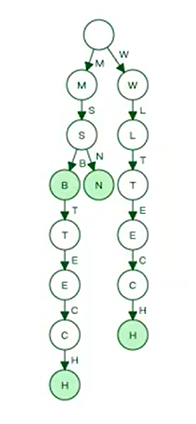
依次输入:msb、msn、msbtech、wltech会产生如上图数据结构
1、如果出现可以公用的元素,则另开分支将不可以公用的部分进行存储,最后一个节点标记为绿色
2、在查找时按照从头到尾的顺序进行查找,只有每个节点都符合并且最后一个字母为绿色final节点时代表查询成功
3、若没有可以公用的部分,则单独开分支进行存储,如wltech
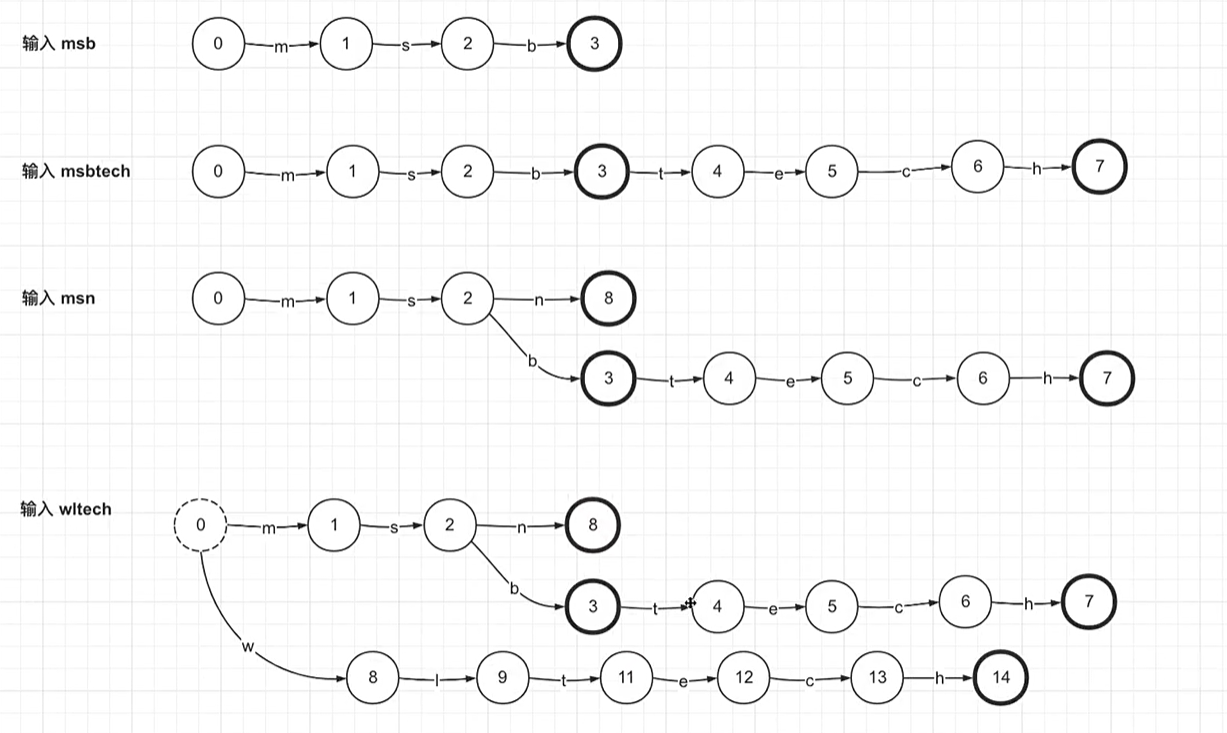
但是此时有一问题,msbtech和wltech在前缀上没有可以公用的部分,但是tech可以公用,此时是否还可以进行优化呢?
二、FSA
接着上图前缀树与红色字体问题,提出当输入wltech时,tech可以复用,得出FSA将tech直接复用减少存储空间
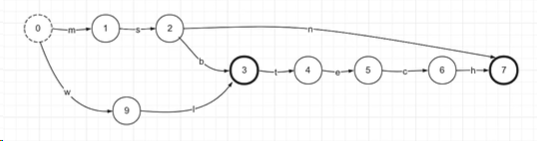
注意:当输入msn时,如果是前缀树,n节点会单独新增一个节点表示final节点。在使用FSA之后n节点直接指向最后的final节点
但是这里又会产生一个问题:wl是否存在呢?因为wl的下一个节点为final节点,中止节点,按理说是应该存在的,但是结果是不存在的
三、FST
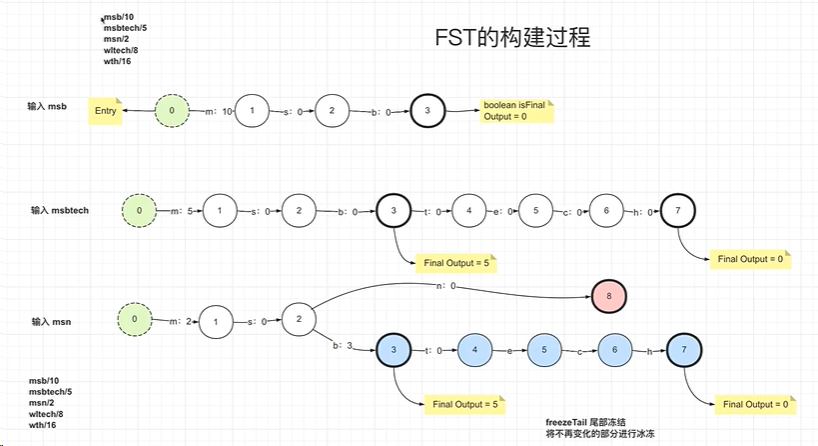
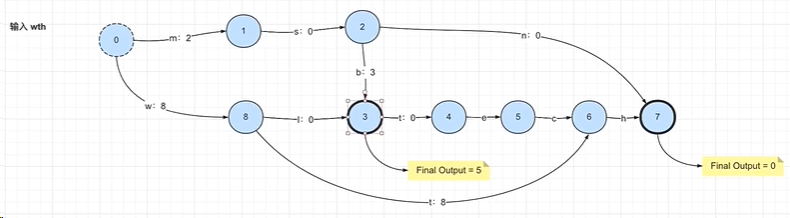
FST会在final节点中新增Final Output数值,当查找某一字符串的时候,会根据当前字符串的路径相加每个节点中的value得到最终值与初始value对应判断是否一致
作者:http://cnblogs.com/lyc-code/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号