
redis进阶
一、发布订阅
场景一:(实时性)
直播间中会话,进入直播间之前的消息你是接收不到的,只能接收到进入直播间之后的消息
订阅者只能接收到连接发布者之后发布者发布的消息
场景二:(历史性)
登陆微信之后可以查看历史聊天记录,数据库中肯定存放全量的数据
但是不能全部查库,n天之前的可以查库(请求量特别低),三天内的呢?
zset可以去实现,把时间作为记录的分值,把消息作为元素,按照时间去将数据从redis中删除
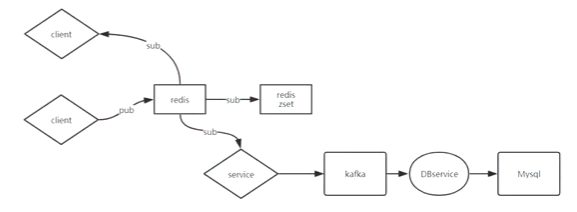
左边redis充当发布订阅,当消息来了后讲消息放到右侧redis的zset中。需要查询过往消息的时候从右侧redis读取
二、事务

watch为监听某些key的操作,mutli为开启事务标志
如上图,client1开启了watch监听k1,若client2发送的删除先执行了exec,watch1监听到k1发生了变化,此时client1之后的命令是不执行的
redis是单进程的,client1和client2两个客户端同时发送命令时,会将命令分组放到队列中,哪组命令先出现exec命令就先执行哪组命令,不论事务是否开启
三、布隆过滤器
作用:防止数据穿透
数据穿透了怎么办?在redis中新增一个key,value标记不存在,下次请求再来的时候redis直接返回不存在,避免再次穿透
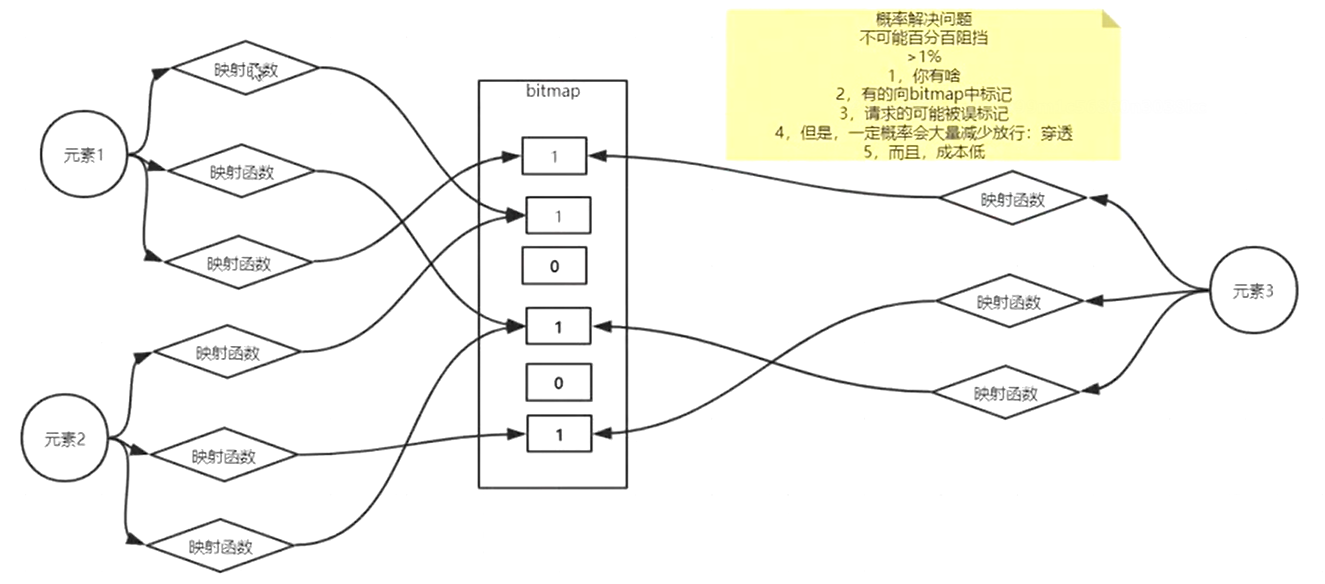
使用bitmap,如上图:
将数据库中现有的商品依次通过映射函数进行计算,在bitmap中将一些位置标记为1(具体哪些位置进行标记暂不研究)。所有映射函数计算完毕后,bitmap中相应位置都会被进行标记。
元素3为用户请求,当redis中没有该请求的时候使用布隆过滤器,通过映射函数进行计算,当所有计算结果在bitmap中都为1时,放行请求到数据库。
但是此时会有一个问题:请求计算后所有在bitmap中的数字可能都为1(如上图),但是这些被标记为1的bitmap对应的位置可能不是数据库中一个商品计算后修改为1的,这时也会请求到数据库。这种概率很小
四、redis作为缓存和作为数据库的区别
缓存不是全量数据,缓存应该随着访问变化,应该存放热数据
有时会对redis中某一key值设置过期时间,需要明确当查询这一key值时不会延长过期时间,当重新set这一key值时会剔除过期时间
五、管道
1、衔接前一个命令的输出作为后一个命令的输入
2、可以批量执行一组指令,一次性返回全部结果
六、RDB
1、时点性:redis中数据持久化会有一个时间
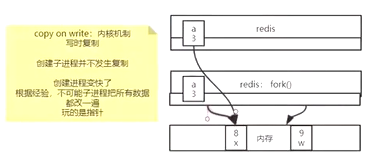
2、RDB会创建一个子进程,调用fork进行拷贝+copy on write
fork(系统调用)并不是真正的拷贝数据,仅仅是指针指向
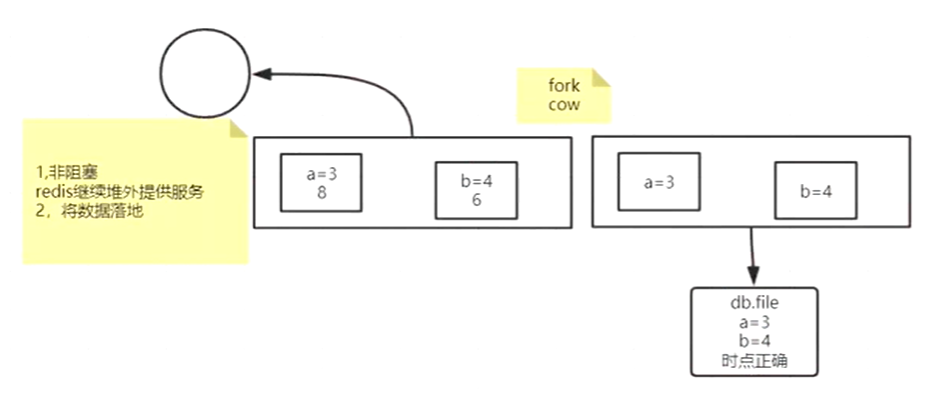
进行数据持久化时,父进程(上图fork左下)先通过fork创建一个子进程(上图fork右下),子进程将数据落地到磁盘,子进程创建的时间即为数据落地时间
父进程针对客户端进行操作,子进程进行数据落地
3、命令触发RDB
save触发前台阻塞,不允许对外提供服务,如读写(应用场景比如关机维护)
bgsave触发子进程fork
4、弊端:RDB都是快照文件,都是默认五分钟或更久的时间生成一次,这就意味着这次同步到下次同步中间五分钟的数据可能全部丢失
优点:数据写入磁盘,恢复数据速度更快
七、AOF
1、AOF:向文件追加,追加的内容为redis的写操作记录到文件中,类似于mysql中binlog
2、redis中可以同时开启AOF和RDB,如果开启了AOF,只会用AOF恢复
好处:很少丢失数据
弊端:体量无限变大,恢复慢
3、AOF在4.0以后将老的数据RDB到aof文件中,将增量的数据以指令的方式追加到AOF中
AOF是一个混合体,利用了RDB的快
4、redis是内存级别的数据库,写操作会触发IO,写操作有三种级别:
always:每次写入数据都会立即写入磁盘
everysec:redis每秒调一次flush向磁盘中写
no:当redis中数据在内核buffer中满了,会向磁盘中写入
八、AKF原理
1、单机、单节点、单实例的缺陷:
单点故障、容量有限、多线程打进来后压力大
2、AKF从x、y、z三个维度去解决问题
x:解决单点问题,x轴可以创建多个备机,进行数据备份
y:y轴可以将不同模块(按照业务区分模块)数据存放到不同redis中
z:z轴可以建立在同一模块的数据中按照id进行划分出多个redis
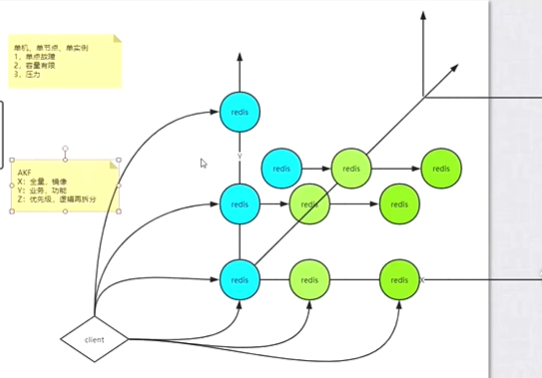
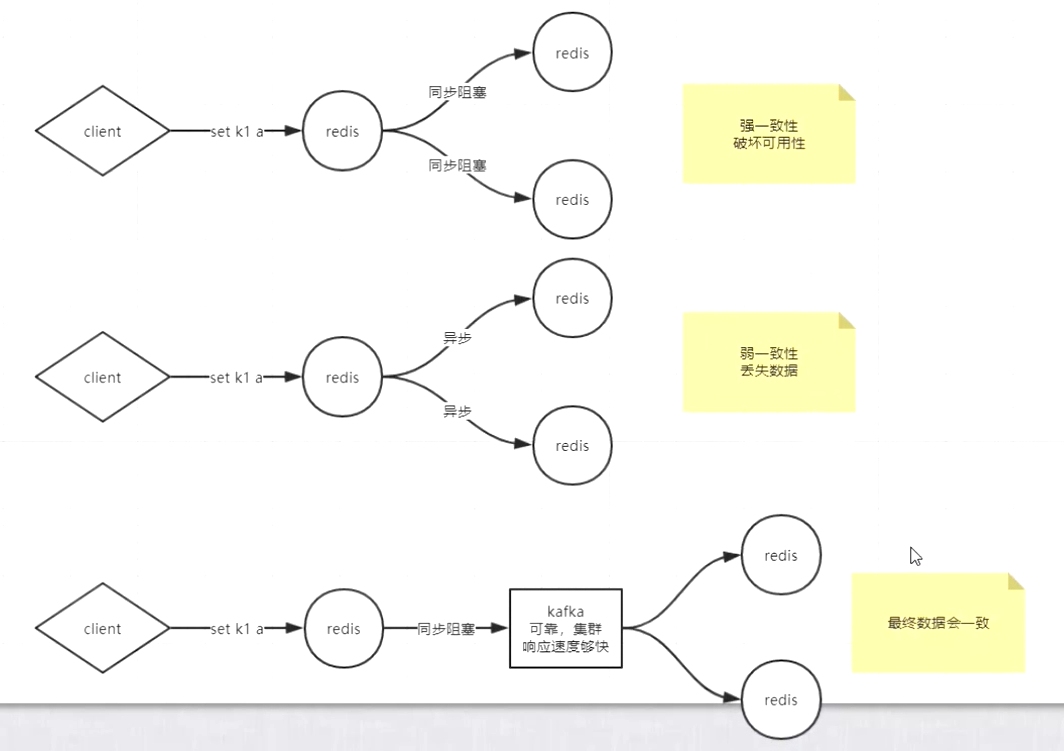
3、redis集群保证数据一致性的方案
4、redis一般用主从不用主备,用主从客户端可以访问主节点也可以访问从节点
主备的话客户端是不能访问备机
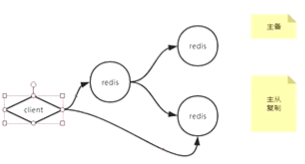
九、redis主从复制
redis主从复制为弱一致性,容易丢失数据,异步复制数据,可用性较高
十、哨兵
1、哨兵监听master判断是否可用,若不可用,重新选举master,之后让其他节点重新连接新的master
2、哨兵中会配置master的ip和端口号,master会往从节点同步数据,所以哨兵也知道从节点的端口号
3、哨兵之间彼此互相知道是通过发布订阅原理
4、哨兵的作用:监听、通知、自动转移故障
监听主节点是否可用
通知:哨兵监听的服务器出现问题时会通知其他哨兵
自动转移故障:在从机中重新选举master
十一、redis击穿
redis作为缓存,key过期,或redis中数据被当作冷数据删除,这时高并发过来请求穿过了redis到达数据库
1、解决方案
每一个请求首先get key发现没有,get失败的请求都去setnx,set成功的人去数据库操作,set失败的人睡眠
2、如果抢到setnx的线程在操作数据库的时候挂掉,导致其他线程一直阻塞无法获取value? 可以设置锁的过期时间
3、线程正在操作数据库,但是设置的超时时间过短,锁过期了,下一个线程到达数据库? 一个线程取db,一个线程监控是否取回来了,更新锁时间
十二、穿透
业务查询的是数据库中不存在的数据
使用布隆过滤器
十三、雪崩
短时间内大量的key同时失效,间接造成大量请求到达db
可以在业务层加判断进行延时,延时之后随机到达redis
十四、分布式锁
分布式锁一般使用zookeeper,虽然redis快,但是既然上锁了,就不会要求效率特别高。也就是说不要求速度快,要求一致性
1、redis:setnx+过期时间+多线程(守护线程)延长过期
首先setnx去设置key,如果redis中key不存在时,设置key值,否则设置失败(谁先抢到锁)
过期时间:①过期时间到了,活没干完
当线程setnx抢到锁后去进行后面的操作(比如往一个文件中写数据),操作还没执行完,分布式锁过期了,这时下一线程会抢到锁同样往一个文件中写数据,这时可能产生脏数据
②时间没到,线程挂了
增加守护线程:用于判断抢到锁的线程是否执行完业务逻辑,避免因设置的过期时间较短发生的错误
2、zookeeper做分布式锁
两个客户端去抢占锁,拿到锁之后才有资格去访问资源

1、抢占锁
2、获得锁的人出现问题:临时节点,session消失,临时节点消失
3、锁被释放别人怎么知道?
①客户端去轮询锁,看锁是否被释放。
轮询:发送心跳。弊端:有延迟、当有多个客户端一同向锁发送心跳会造成压力过大
watch:解决了延迟,但是若客户端过多,需要发送心跳的客户端也很多,压力过大
顺序节点+watch:每一个请求锁的客户端在父目录下创建顺序临时节点(有编号顺序),watch前一个顺序临时节点,解决了压力过大问题
作者:http://cnblogs.com/lyc-code/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号