
redis使用
redis为单线程模式,采用非阻塞异步处理机制
一、基础
1、连接客户端命令:redis-cli
2、退出客户端命令:exit
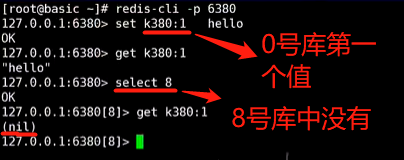
3、redis中有16个库,0库和1库是不能修改的,各个库之间是隔离的
4、查看所有key值keys *
二、String类型
1、set k1 hello
get k1
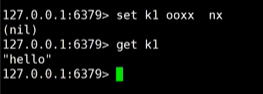
2、nx:当k1不存在时可以进行设置,k1存在时会返回nil
set k1 ooxx nx,下图中k1已经存在
使用场景:分布式锁
多线程下去单线程redis中抢占某一key值,给key1设置成功,就抢到了锁
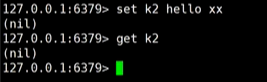
3、xx:当k2存在时可以进行设置,k2不存在时返回nil
set k2 hello xx,下图中k2不存在,返回nil
注意:nx只能新建,xx只能更新
4、多key设置:mset k3 a k4 b
将k3value设置为a,k4设置为b
5、redis中有正向索引和逆向索引

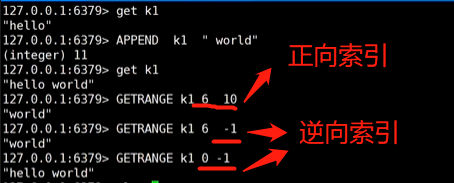
上图为append追加、getrange截取
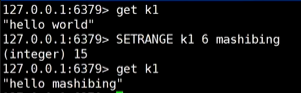
上图为根据偏移量替换
6、获取value长度:STRLEN k1
7、获取key对应value类型:type k1
8、INCR加一、INCRBY加固定值、DECR减一、DECRBY减固定值
对数值的操作可以应用到秒杀场景下,如果操作mysql会涉及到事务。使用redis在内存中就可以完成操作

9、GETSET k1 mashibing
将k1的值变为mashibing并且返回原先k1的值
GETSET与一次get一次set的区别
一次get、一次set相当于在通信上发送了两个包
而GETSET相当于一次只发送了一个包完成了等同于一次get一次set的操作,减少了一次io
10、MSETNX批量set伴随nx

11、二进制安全:redis中存得是字节
redis中存的是字节,而redis本身在存储字节的时候没有进行任何操作。换言之只要双方有相同的编解码,数据就不会被破坏。因为任何的编解码针对字节得到的结果是一样的(每种语言对数据类型的理解不一样,可能导致解码之后溢出等问题)
三、list类型
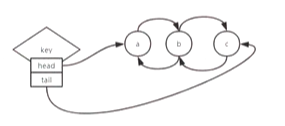
key中有头信息和尾信息,分别指向双向链表的头和尾
1、lpush k1 a b c d e f
从左向list中存(推)数据,放入的数据顺序为f e d c b a,最终顺序为f e d c b a
2、rpush k1 a b c d e f
从右向list中推数据
3、lpop k1
从最左面弹数据
4、rpop k1
从最右面弹数据
5、lrange k1 0 -1 取出list中规定范围的值
6、lindex k1 2 取出list中规定下标的值

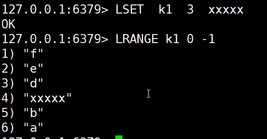
7、lset 将规定下标的值替换成目标值
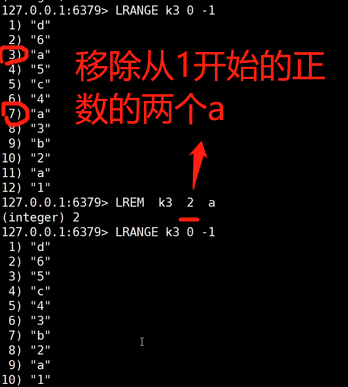
8、lrem k3 2 a
k3:key值 2:移除个数 a:移除的元素
9、linsert k3 before/after 6 a
k3:key值 bafore:在元素前 after:在元素后 6:value中的值 a:要插入的元素
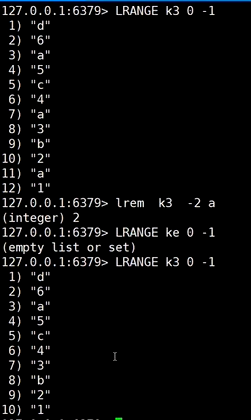
10、ltrim k4 0 -1
k4:key值 0:开始范围 -1:结束范围
ltrim删除0到-1之外的元素
11、使用场景
消息队列的有序性
四、Hsah
value中按照key-value的形式存值
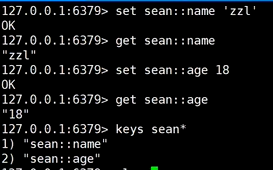
1、基础操作
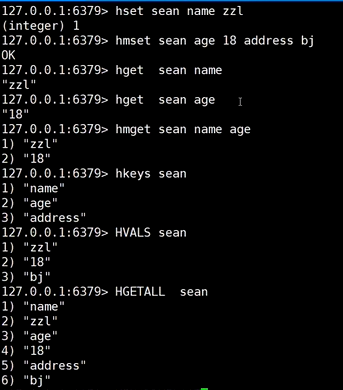
使用场景:使用redis查询一个人的全部属性,减少了查询mysql
五、Set
set会进行去重,无序
1、新增元素:sadd k1 21 1 2 3 4 5 1
2、查询元素:smembers k1
结果:21 1 2 3 4 5
3、移除元素:srem k1 2 3
2 3是value中元素
4、可以做交集、并集、差集等运算。 k2:1、2、3、4、5 k3:4、5、6、7、8
交集:
5、srandmember key count
正数:取出一个去重的结果集(不能超过已有集)
负数:取出一个可重复的结果集,一定满足你要的数量
0:不返回
应用场景一:粉丝送福利(粉丝足够),set中存放粉丝的名单,送三个礼物
srandmember key 3:抽出三个粉丝不重复
srandmember key -3:粉丝可能重复
应用场景二:奖品足够,粉丝数少。value中存放粉丝信息
srandmember key -20:负数足够大就可以(粉丝有重复)
应用场景三:公司年会抽奖,进门发一个带有数字的卡片,这时一个数字不能重复出现
spop k1:每次会从已抽到过剩下的卡片中随机抽取
六、ZSet
在给数据排序时需要有一个分值维度,如果不给出分值我们就不知道按照什么分值进行排序。如果分值都为1时,按照字典序进行排序
1、要给每个元素分配分值

在去除所有这个命令中是按照分数左小右大的顺序从上到下进行展示的
应用场景:歌曲排行榜,刚上线的时候歌曲的分值默认都是1,当点击量或者下载量上升以后,可以使用zset对分值进行相应的加减操作
2、排序是如何实现的,增删改查的速度?
skip list结构:跳跃表 牺牲存储空间来获取查询效率,随机造层
保证每一层是上一层节点数的一半
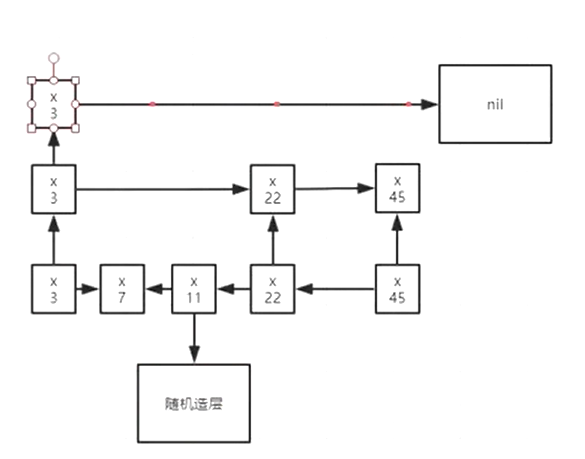
从最高层开始,逐层进行对比。在最终插入后修改指针
平均值相对最优
作者:http://cnblogs.com/lyc-code/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号