java字符串常量池
字符串常量池是全局的,JVM 中独此一份,因此也称为全局字符串常量池。
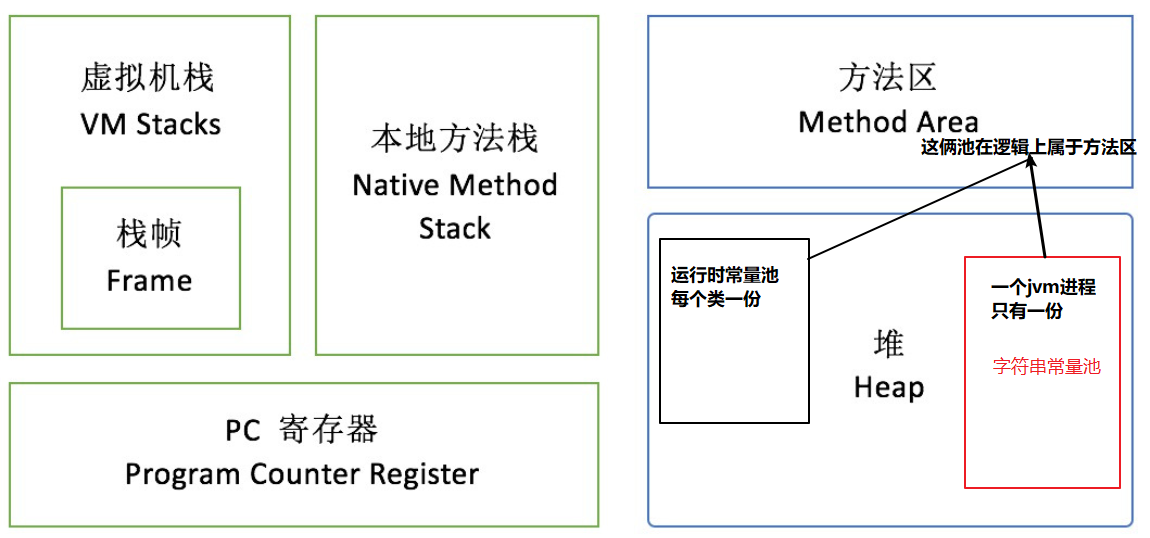
运行时常量池是方法区的一部分,是一块内存区域。Class 文件常量池将在类加载后进入方法区的运行时常量池中存放。一个类加载到 JVM 中后对应一个运行时常量池
运行时常量池
在JDK1.8中,使用元空间代替永久代来实现方法区,但是方法区并没有改变,方法区只是一个标准,永久代相当于一个实现方案,所谓"Your father will always be your father",变动的只是方法区中内容的物理存放位置。类型信息(元数据信息)等其他信息被移动到了元空间中,元空间存储类的元信息;但是运行时常量池和字符串常量池被移动到了堆中。但是不论它们物理上如何存放,逻辑上还是属于方法区的。
JDK1.8中字符串常量池和运行时常量池逻辑上属于方法区,但是实际存放在堆内存中,因此既可以说两者存放在堆中,也可以说两者存在于方法区中,这就是造成误解的地方。
- 是方法区的一部分,是一块内存区域,用于存放编译期生成的各种字面量和符号引用
- Class 文件常量池将在类加载后进入方法区的运行时常量池中存放。一个类加载到 JVM 中后对应一个运行时常量池
- 运行时常量池相对于 Class 文件常量池来说具备动态性,Class 文件常量只是一个静态存储结构,里面的引用都是符号引用。而运行时常量池可以在运行期间将符号引用解析为直接引用。可以说运行时常量池就是用来索引和查找字段和方法名称和描述符的。给定任意一个方法或字段的索引,通过这个索引最终可得到该方法或字段所属的类型信息和名称及描述符信息,这涉及到方法的调用和字段获取。
字符串常量池SCP
- jdk1.6是放在永久代(8中叫方法区或叫元空间)中;
- jdk1.8+中,
字符串常量池放入了堆中 - 字符串常量池中的元素是唯一的
- jdk1.8+为了节省内存,对象的真实数据实际上只会有一份,要么在scp中,要么在scp外的堆中,然后scp中引用堆中的地址
intern函数
- 查询字符串常量池中是否存在当前字符串;
- 如果字符串常量池中存在此字符串,返回常量池中的字符串的地址;如果常量池中不存在,在常量池中添加此字符串,并返回地址
创建字符串到字符串常量池
String s0 = "abc";这种方式创建的字符串直接存放到字符串常量池中- 通过new的方式创建的字符串,需要调用intern()方法,就可以存放到字符串常量池中
创建对象个数
可以通过字节码文件查看
String s2 = new String("abc");- 上面这行代码实际创建了2个对象,一个是字符串常量池外部的堆空间的abc,另一个是常量池中引用堆空间中abc的地址,s2本体是存放在scp外的堆中,常量池引用了这个地址
String s5 = new String("a") + new String("b") + new String("c");- 上面这行代码,字符串常量池中没有存放"abc",会单独存放"a","b","c";
- 变量之间使用+号,实际会创建一个
StringBuilder,然后调用append(),最后调用toString()方法
创建方式
使用字面量(引号)创建
String s1= "abc";
String s2= "abc";
- 当我们第一次执行String s1 =“abc”时,JVM将在常量池中创建一个新对象,s1将引用该对象,即“abc”。
- 当我们第二次执行String s2 =“abc”时,JVM将检查字符串常量池中是否存在任何值为“abc”的对象。截至现在是的,我们已经在“字符串常量”池中存在“abc”,因此它不会创建新对象,只是s2引用变量将指向现有的“abc”对象。
使用new关键字
String s2 = new String("abc");
- jvm会第一步检查常量池是否有"abc", 发现没有,创建一个新对象在常量池中.
- 然后因为有new关键词,所以会在堆中创建对象,然后将这个对象的地址引用返回
组合创建
String st1 ="abc";
String st2 = new String("abc");
- 当我们执行String st1 ="abc";时,JVM将在字符串常量池中创建一个对象
- 执行第二步的时候,JVM将检查字符串常量池中是否有任何可用的名称为“abc”的对象,现在是有,我们已经在字符串常量池中使用了“abc”,因此JVM不会在字符串常量池中创建任何对象。
- 因为有new关键词,它将在堆中创建一个对象,st2将指向该对象。
intern验证
以下代码运行环境为jdk1.8
情景一
String str = "aa";
String str2 = new String("aa");
System.out.println(str == str2); //false
String str3 = str2.intern();
System.out.println(str == str3); //true
String str = “aa”;在scp创建了一个对象"aa",- 而
String str2 = new String(“aa”);这里其实有两步 - 第一步java去scp找"aa",发现scp有"aa"
- 第二步,在堆中创建对象.所以两者地址不一样,str == str2 为false.
- 第二个,在经过
String str3 = str2.intern();后,intern发现scp已经有"aa"了, 所以直接将scp的地址返回给str3, 所以str == str3都是scp的地址,所以为true.
情景二
String s = new String("a") + new String("b");
String s1 = "ab" + "cd";
String s2 = s.intern();
String s3 = "ab";
System.out.println(s == s2); //true
System.out.println(s3 == s2);//true
- 这是因为第一行代码, 据上面所知,不管"a"和"b",只会在堆中创建"ab"对象
- 第二行代码,我们用两个声明字符串相加,可知jvm会优化,直接在scp中创建"abcd"
- 第三行代码,s调用intern方法,发现scp没有"ab",将s在堆中的引用地址给s2
- 第四行代码,java先去scp找"ab",发现有,直接将其地址返回给s3
- 所以s指向堆中的地址,s2也是这个地址,所以相同. s3==s2同理,相同
情景三
如果将String s3 = "ab"放到前面
String s = new String("a") + new String("b");
String s1 = "ab" + "cd";
String s3 = "ab";
String s2 = s.intern();
System.out.println(s == s2); //false
System.out.println(s3 == s2); //true
- 第一行代码和第二行代码如上
- 第三行代码,java发现scp没有"ab",在scp创建新对象,然后返回地址给s3
- 第四行代码,s调用intern方法,发现scp有"ab",将s在scp中的引用地址给s2
- 所以s是堆中的地址,s2和s3是scp的地址,所以结果是false和true
情景四
这次不调整代码顺序,而是将"ab" + “cd”,两个声明式相加,变成其中一个是变量
String s = new String("a") + new String("b");
String s1 = "ab" + s;
String s2 = s.intern();
String s3 = "ab";
System.out.println(s == s2); //false
System.out.println(s3 == s2); //true
- 因为s1不再是两个声明式相加,编译器无法得知结果,所以将String s1 = "ab" + s变成:
String var = "ab";String s1 = var + s; - 所以"ab"会在scp中,s2拿到的也会是var的地址,所以s == s2 为false
附录:
美团技术团队的解读
你要是觉得写的还不错,就点个关注,可以评论区留下足迹,以后方便查看.
你要是觉得写的很辣鸡,评论区欢迎来对线!
欢迎转载!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号