mysql聚簇索引和非聚簇索引
聚簇索引
InnoDB使用的是聚簇索引
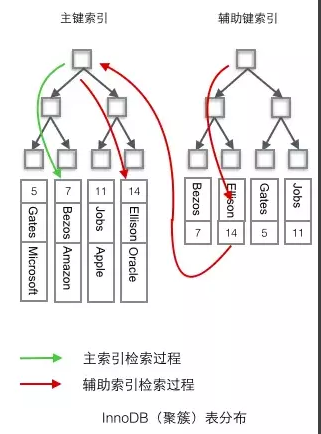
- 将数据与主键索引放在了一起,索引的叶子节点保存了行数据,找到了主键索引,即找到了行数据。
- 辅助索引记录了主键的位置,所以查询where name= xxx 时,先找辅助索引树,找到主键位置,然后找数据树,找到数据行
- 聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引时相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
- 聚簇索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是具体的物理地址。
非聚簇索引
MyISAM是非聚簇索引
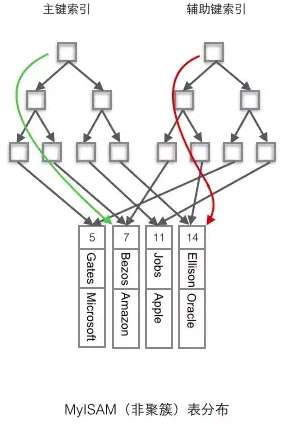
- B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的.
聚簇索引的优点
- 聚簇索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是具体的物理地址。
- 当你需要取出一定范围内的数据时,用聚簇索引也比用非聚簇索引好。
- 当一条查询语句符合覆盖索引条件时,只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率
聚簇索引的缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
- 使用辅助索引查询时需要查两次
- 采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距,聚簇索引遍历所有的叶子节点,非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有记录值,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
磁盘分块和内存分页
你要是觉得写的还不错,就点个关注,可以评论区留下足迹,以后方便查看.
你要是觉得写的很辣鸡,评论区欢迎来对线!
欢迎转载!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号