Mysql小知识
MySQL 事务属性
- 事务是由一组SQL语句组成的逻辑处理单元,事务具有ACID属性。
- 原子性(Atomicity):事务是一个原子操作单元。在当时原子是不可分割的最小元素,其对数据的修改,要么全部成功,要么全部都不成功。
- 一致性(Consistent):事务开始到结束的时间段内,数据都必须保持一致状态。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行。
- 持久性(Durable):事务完成后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
事务常见问题
-
更新丢失(Lost Update)
原因:当多个事务选择同一行操作,并且都是基于最初选定的值,由于每个事务都不知道其他事务的存在,就会发生更新覆盖的问题。类比github提交冲突。 -
脏读(Dirty Reads)
原因:事务A读取了事务B已经修改但尚未提交的数据。若事务B回滚数据,事务A的数据存在不一致性的问题。 -
不可重复读(Non-Repeatable Reads)
原因:事务A第一次读取最初数据,第二次读取事务B已经提交的修改或删除数据。导致两次读取数据不一致。不符合事务的隔离性。 -
幻读(Phantom Reads)
原因:事务A根据相同条件第二次查询到事务B提交的新增数据,两次数据结果集不一致。不符合事务的隔离性。 -
幻读和脏读有点类似
脏读是事务B里面修改了数据,
幻读是事务B里面新增了数据。
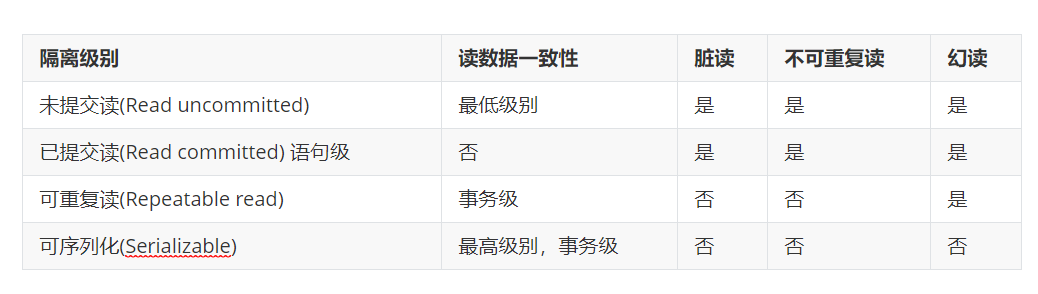
事务的隔离级别
数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大。这是因为事务隔离实质上是将事务在一定程度上"串行"进行,这显然与"并发"是矛盾的。根据自己的业务逻辑,权衡能接受的最大副作用。从而平衡了"隔离" 和 "并发"的问题。MySQL默认隔离级别是可重复读。
脏读,不可重复读,幻读,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。
数据库锁
- 间隙锁, 当我们用范围条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做"间隙(GAP)"。InnoDB也会对这个"间隙"加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。危害(坑):若执行的条件是范围过大,则InnoDB会将整个范围内所有的索引键值全部锁定,很容易对性能造成影响。
- 排他锁,也称写锁,独占锁,当前写操作没有完成前,它会阻断其他写锁和读锁。
- 共享锁,也称读锁,多用于判断数据是否存在,多个读操作可以同时进行而不会互相影响。当如果事务对读锁进行修改操作,很可能会造成死锁。
- 表锁的优势:开销小;加锁快;无死锁
表锁的劣势:锁粒度大,发生锁冲突的概率高,并发处理能力低
加锁的方式:自动加锁。查询操作(SELECT),会自动给涉及的所有表加读锁,更新操作(UPDATE、DELETE、INSERT),会自动给涉及的表加写锁。 - 也可以显式加锁:
- 共享读锁:lock table tableName read;
- 独占写锁:lock table tableName write;
- 批量解锁:unlock tables;
什么场景下用表锁
InnoDB默认采用行锁,锁是加在索引字段上的,并不是加在这行数据上,所以在未使用索引字段查询时升级为表锁。MySQL这样设计并不是给你挖坑。它有自己的设计目的。
即便你在条件中使用了索引字段,MySQL会根据自身的执行计划,考虑是否使用索引(所以explain命令中会有possible_key 和 key)。如果MySQL认为全表扫描效率更高,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
-
第一种情况:全表更新。事务需要更新大部分或全部数据,且表又比较大。若使用行锁,会导致事务执行效率低,从而可能造成其他事务长时间锁等待和更多的锁冲突。
-
第二种情况:多表级联。事务涉及多个表,比较复杂的关联查询,很可能引起死锁,造成大量事务回滚。这种情况若能一次性锁定事务涉及的表,从而可以避免死锁、减少数据库因事务回滚带来的开销。
表锁行锁小总结
-
InnoDB 支持表锁和行锁,使用索引作为检索条件修改数据时采用行锁,否则采用表锁。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁 -
InnoDB 自动给修改操作加锁,给查询操作不自动加锁
-
行锁可能因为未使用索引而升级为表锁,所以除了检查索引是否创建的同时,也需要通过explain执行计划查询索引是否被实际使用。
-
行锁相对于表锁来说,优势在于高并发场景下表现更突出,毕竟锁的粒度小。
-
当表的大部分数据需要被修改,或者是多表复杂关联查询时,建议使用表锁优于行锁。
-
为了保证数据的一致完整性,任何一个数据库都存在锁定机制。锁定机制的优劣直接影响到一个数据库的并发处理能力和性能。
-
表锁,读锁会阻塞写,不会阻塞读。而写锁则会把读写都阻塞
Group By 小知识
当select 的字段(除了聚合,例如sum()等)和group by 的字段不一致时,会导致语法错误,执行一下两个sql或者改数据库配置文件去掉ONLY_FULL_GROUP_BY,重新设置值。
set @@global.sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
set sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
SQL 执行顺序
FROM->WHERE->GROUP BY->HAVING->SELECT->distinct->ORDER BY->limit/offset
having 的作用是筛选满足条件的组,即在分组之后过滤数据。
SELECT seller_id,count(seller_id) FROM `offer_listing` where `country`='us' group by `seller_id` having count(seller_id)>10
# count 是统计出现的行数累计,sum是把满足条件的所有行中这个字段的值累加,先使用group by,然后用having
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
- FROM <表名> # 笛卡尔积
- ON <筛选条件> # 对笛卡尔积的虚表进行筛选
- JOIN <join, left join, right join...> <join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中
- WHERE <where条件> # 对上述虚表进行筛选
- GROUP BY <分组条件> # 分组 ,<SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
- HAVING <分组筛选> # 对分组后的结果进行聚合筛选
- SELECT <返回数据列表> # 返回的单列必须在group by子句中(参考上边的Group By 小知识可以任意字段),聚合函数除外
- DISTINCT # 数据除重
- ORDER BY <排序条件> # 排序
- LIMIT n,m<行数限制> # 跳过前n条数据,返回m条数据,注意,如果跳过40w行数,取几个数据,效率很低,因为要先扫描前40w行数,所以用于分页时要考虑其他方案,例如添加where条件
数据库很可能不按正常顺序执行查询(优化)
在实际当中,数据库不一定会按照 JOIN、WHERE、GROUP BY 的顺序来执行查询,因为它们会进行一系列优化,把执行顺序打乱,从而让查询执行得更快,只要不改变查询结果。
SELECT * FROM dept d LEFT JOIN student s ON d.student_id = s.id WHERE s.name = '嘿嘿';
如果只需要找出名字叫“嘿嘿”的学生信息,那就没必要对两张表的所有数据执行左连接,在连接之前先进行过滤,这样查询会快得多,而且对于这个查询来说,先执行过滤并不会改变查询结果。
JOIN
-
select * from A left join B on A.aID = B.bIDleft join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.
换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
B表记录不足的地方均为NULL. -
select * from A right join B on A.aID = B.bIDright join和left join的结果刚好相反,这次是以右表(B)为基础的,A表不足的地方用NULL填充. -
select * from A inner join B on A.aID = B.bIDinner join inner join并不以谁为基础,它只显示符合条件的记录. -
所以NOT IN 子查询 可以优化成left join 语句,例如:
-
not in :
select uid from signshould where mid=897 and uid not in(select uid from sign where mid=897 and thetype=0) and uid not in(select uid from leaves where mid=897) -
left join :
select a.* from signshould as a LEFT JOIN (select * from sign where mid=897 and thetype=0) as b ON a.uid=b.uid LEFT JOIN (select * from leaves where mid=897) as c ON a.uid=c.uid where a.mid=897 and b.uid is null and c.uid is null -
需要注意的地方
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户;
where条件是在临时表生成好后,再对临时表进行过滤的条件;
on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录,如果条件为假,则全部填充null,并且本条数据不去右表中查询
-
总结,过滤条件放在:
where后面:根据条件筛选临时表,生成最终结果
on后面:根据条件过滤筛选生成临时表
尽量用union all代替union
union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。
当然,union all的前提条件是两个结果集没有重复数据。
区分in和exists、not in和not exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
关于not in和not exists,推荐使用not exists,不仅仅是效率问题,not in可能存在逻辑问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号