结对第二次—文献摘要热词统计及进阶需求
课程名称:软件工程实践
作业要求:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600428 | 221600438
Github项目地址:基本需求 | 进阶需求
Github的代码签入记录:
分工如下:
- 221600438 郑厚楚
- 主要代码编写
- 需求分析
- 单元测试
- 221600428 林煜
- 博客撰写
- 需求分析
- 单元测试
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 1300 | 1540 |
| Development | 开发 | 1140 | 1420 |
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 120 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design Review | • 设计复审 | 60 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| • Design | • 具体设计 | 200 | 240 |
| • Coding | • 具体编码 | 500 | 660 |
| • Code Review | • 代码复审 | 100 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 160 | 120 |
| • Test Report | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 100 | 60 |
| 合计 | 1300 | 1540 |
解题思路描述
拿到题目后,我们花了大量的时间对任务进行需求分析,然后针对基本需求分别构建对字符数、单词数、有效行数以及词频的统计函数用以实现各项功能,然后根据进阶需求完善程序,并对各项功能进行优化。
- 基本需求
- 输入文件名以命令行参数传入。
- 统计文件的字符数
- 统计文件的单词总数
- 统计文件的有效行数
- 统计文件中各单词的出现次数,最终只输出频率最高的10个
- 按照字典序输出到文件result.txt
- 进阶需求
- 使用工具爬取论文信息
- 自定义输入输出文件
- 加入权重的词频统计
- 新增词组词频统计功能,统计文件夹中指定长度的词组的词频
- 自定义词频统计输出
- 多参数的混合使用
实现过程
设计过程
-
基本需求
- 项目需求
221600428&221600438 - src
- Main.java
- lib.java
函数与流程:
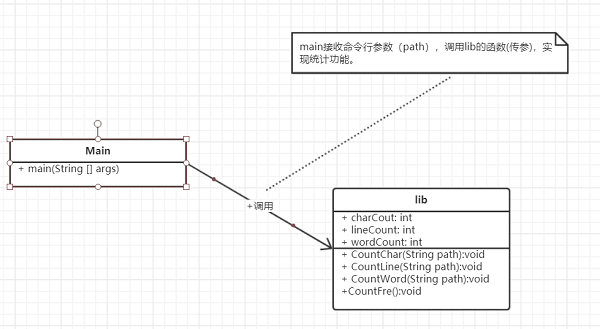
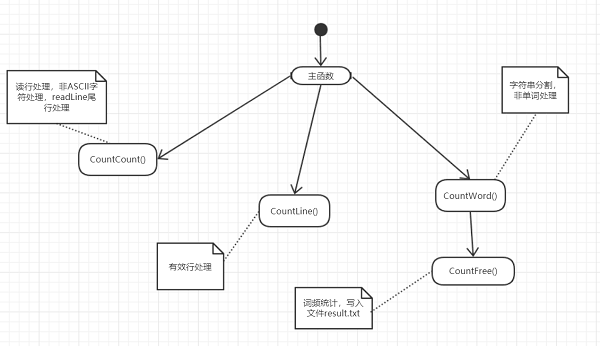
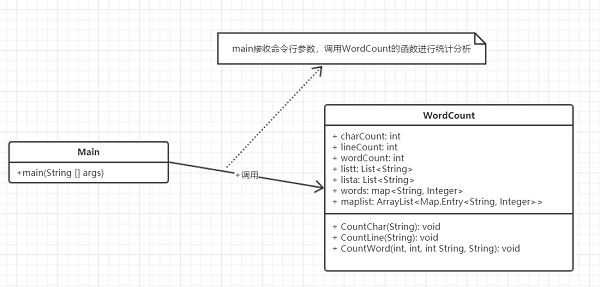
主要有两个类 Main.java 和 Lib.java 为了方便维护和修改 函数拆成四个 主要函数countChar,countWord,countLine,countMostWord,分别为计算字符数,单词数,行数,和输出词频,通过主函数依次调用countChar,countWord,countLine,countMostWord去进行计算并输出.
类图:
![]()
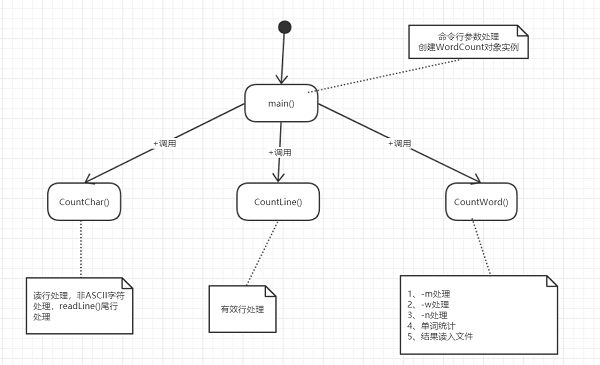
流程图:
![]()
- 项目需求
-
进阶需求
在基本需求的基础上,对词频统计函数进行完善。
类图:
![]()
流程图:
![]()
-
爬虫:
- 对http://openaccess.thecvf.com/CVPR2018.py的网页信息导入输入InputStream中,
- 对缓冲流中的数据进行读行处理,用正则表达式筛选有ptitle的有效行
- 对有效行进行split字符分割处理,得到title和论文Abstract的链接
- 爬取Abstract链接的网页信息
- 对信息做读行处理(含有Abstract的行为有效行)再读一行做split处理得到Abstract的内容
改进思路
- 基础:
- 对于字符统计的部分,一开始的思路是用read()读出的字符先存在一个字符串里面,然后进行\r\n的处理,再行统计字符数,结果发现这种方法的性能极差,没办法统计出1M以上的文件级的字符数。改进方法:使用 readLine() 读文件,用一个int (记为len)变量标记 readLine() 的结果长度,将读出的字符串字符逐个分析(非ASCII码字符不做统计),累加。最后若是len不等于0,则chatCount做减1处理(即做readLine()尾行读处理))。。
- 对于单词统计部分,一开始是用自定义的函数做判断是否是单词的处理。改进方法:采用正则表达式 .matches("[a-z]{4}[a-z0-9]*") 做判断是否为单词。
- 进阶:
- 读字符处理过程跟基础需求的处理过程差不多,但多了一个识别Title:行和Abstract:行的处理。另外的功能处理也只是添加的功能处理部分的代码,并无太大的改变。
- 另外词组的统计没有包含字符,因为看不出来这个需求,助教的博客没有及时去更新看,所以时间已经来不及了。
代码说明
基础部分
字符统计
用readLine()进行读行处理,用一个整型变量len标记字符串的长度,然后对字符串做逐个的字符分析处理(非ASCII字符不做统计)。每读完一行加上一个换行符。最后若(len != 0),字符数量减1。
public void CountChar(String path)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(path));
BufferedReader br = new BufferedReader(r);
int a=0;
int len=0;
String str=null;
while((str=br.readLine()) != null)
{
//str = str +(char)a;
a=str.length()-1;
len=a+1;
while(a>=0)
{
char o=str.charAt(a);
if(o>=0 && o<=127)
{
charCount++;
}
a--;
}
charCount++;
}
if(len != 0) charCount--;
//str=str.replaceAll("\\r\\n+", "a");
//charCount=str.length();
r.close();
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
}
有效行数统计
有效行的分析处理后统计行数。
public void CountLine(String path)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(path));
BufferedReader br = new BufferedReader(r);
String s= br.readLine();
while(s != null)
{
//charCount+=s.length();
//System.out.println(s);
if(!s.trim().equals(""))
{
lineCount++;
}
s=br.readLine();
}
r.close();
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
}
单词统计
readLine()读行,字符串做字符分割处理,然后对分割后的字符串数组做是否为单词的判断,若是单词则统计单词量并list.add;若不是则不作处理。
public void CountWord(String path)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(path));
BufferedReader br = new BufferedReader(r);
String s= br.readLine();
while(s != null)
{
s=s.toLowerCase();
String wordstr[] = s.split("[^a-zA-Z0-9]");
int x = wordstr.length;
for(int i=0; i<x; i++)
{
/*if(wordstr[i].length() >= 4)
{
//System.out.println(wordstr[i]+" "+wordstr[i].length()+" ");
String st = wordstr[i].substring(0, 4);
//System.out.print(st.matches("[a-zA-Z]+"));
if(st.matches("[a-zA-Z]+"))
{
++wordCount;
list.add(wordstr[i]);
}
}*/
if(wordstr[i].matches("[a-z]{4}[a-z0-9]*"))
{
++wordCount;
list.add(wordstr[i]);
}
}
s=br.readLine();
}
r.close();
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
}
词频统计
用一个Map做list的单词词频统计并做降序处理,输出前10词频的单词,并将结果写入result.txt文件里面。
public void CountFre()
{
for(String li: list)
{
if(words.get(li) != null)
{
words.put(li, words.get(li)+1);
}
else words.put(li, 1);
}
maplist = new ArrayList<Map.Entry<String, Integer>>(words.entrySet());
Collections.sort(maplist, new Comparator<Map.Entry<String, Integer>>(){
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
// TODO Auto-generated method stub
return o2.getValue() - o1.getValue(); //降序
}
});
try
{
File file = new File("result.txt");
BufferedWriter br = new BufferedWriter(new FileWriter(file));
br.write("characters: "+charCount+"\r\n");
br.write("words: "+wordCount+"\r\n");
br.write("lines: "+lineCount+"\r\n");
for(int i=0; i<maplist.size(); i++)
{
if(i>=10) break;
br.write("<"+maplist.get(i).getKey()+">: "+maplist.get(i).getValue()+"\r\n");
}
br.close();
}
catch(Exception e)
{
System.out.println("文件读取出错!");
}
for(int i=0; i<maplist.size(); i++)
{
if(i>=10) break;
System.out.println("<"+maplist.get(i).getKey()+">: "+maplist.get(i).getValue());
}
}
进阶部分
字符统计
用readLine()进行读行处理,做正则表达式匹配(“Title: “ “Abstract: “),判断字符串是属于Title还是Abstract;然后对字符串做.length长度统计,用一个整型变量len标记字符串的长度,对字符串每个字符做分析(非ASCII字符不做统计)。每读完一行加上一个换行符,若属于Title行则减7,若属于Abstract行则减10。
public void CountChar(String inpath)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(inpath));
BufferedReader br = new BufferedReader(r);
//int a=0;
//int cnt=0;
//int csnt=0;
String str=null;
Pattern psa = Pattern.compile("Title");
Pattern psb = Pattern.compile("Abstract");
//int lines=0;
while((str=br.readLine()) != null)
{
Matcher msa = psa.matcher(str);
Matcher msb = psb.matcher(str);
if(msa.find())
{
int index=str.length()-1;
//System.out.println(str.charAt(10));
while(index >= 0)
{
char o = str.charAt(index);
if(o>=0 || o <=127 )
{
charCount++;
}
index--;
}
charCount-=7; //减去“Title: ”
charCount++; //加上换行符
//charCount += str.length()-7;
}
else if(msb.find())
{
//charCount+=str.length()-10;
int index=str.length()-1;
while(index >= 0)
{
char o = str.charAt(index);
if(o>=0 || o <=127 )
{
charCount++;
//System.out.println(o);
}
index--;
}
charCount-=10; //减去“Abstract: ”
charCount++;
}
}
//if(a != 0) charCount--;
//charCount = charCount - (csnt/2)*17;//有效行减去"\r\n", "Title: ", "Abstract: "
//System.out.println(csnt);
r.close();
System.out.println("characters: "+charCount);
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
}
有效行数统计
做有效行处理(属于“Title”和属于“Abstract”的行)
public void CountLine(String inpath)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(inpath));
BufferedReader br = new BufferedReader(r);
String s= br.readLine();
int cnt=0;
while(s != null)
{
//charCount+=s.length();
//System.out.println(s);
if(cnt%5 != 0 && !s.trim().equals(""))
{
lineCount++;
}
cnt++;
s=br.readLine();
}
r.close();
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
}
单词与词频统计
xx表示-w的参数,yy表示-m的参数,zz表示-n的参数,inpath表示-i的参数,outpath表示-o的参数。
对文件做读行得到字符串s;对s做字符分割成字符串数组wordstr,x记录wordstr的长度,
先用一个循环 做-m的词组统计,这里我只考率了单词词组,没有考虑特殊字符的处理。
在用两个List
再用一个循环 统计-m没有统计到的单词,即wordstr[(x-xx+1)~(x)] 的字符串处理。
用一个Map做词频处理
在输出前yy个词频的词组(一个单词或是单个单词都可以)
public void CountWord(int xx, int yy, int zz, String inpath, String outpath)
{
try
{
InputStreamReader r = new InputStreamReader(new FileInputStream(inpath));
BufferedReader br = new BufferedReader(r);
String s= br.readLine();
while(s != null)
{
s=s.toLowerCase();
String wordstr[] = s.split("[^a-zA-Z0-9]");
int x = wordstr.length;
if(x>=yy)
{
for(int i=1; i<(x-yy+1); i++)
{
if(wordstr[i].matches("[a-z]{4}[a-z0-9]*"))
{
++wordCount;
//System.out.println(wordstr[0]);
String phrase = "";
if(wordstr[0].equals("title"))
{
//System.out.println("Title--");
int j=0;
for(j=0; j<yy; j++)
{
if(!wordstr[i+j].matches("[a-z]{4}[a-z0-9]*")) break;
else{
phrase += (wordstr[i+j]+" ");
}
}
phrase = phrase.substring(0, phrase.length()-1);
if(j == yy) listt.add(phrase);
}
else
{
//System.out.println("Abstract--");
int j=0;
for(j=0; j<yy; j++)
{
if(!wordstr[i+j].matches("[a-z]{4}[a-z0-9]*")) break;
else{
phrase += (wordstr[i+j]+" ");
}
}
phrase = phrase.substring(0, phrase.length()-1);
if(j == yy) lista.add(phrase);
}
}
}
for(int k=(x-yy+1); k<x; k++)
{
if(wordstr[k].matches("[a-z]{4}[a-z0-9]*"))
{
++wordCount;
}
}
}
else
{
for(int k=1; k<x; k++)
{
if(wordstr[k].matches("[a-z]{4}[a-z0-9]*"))
{
++wordCount;
}
}
}
s=br.readLine();
}
r.close();
System.out.println("words: "+wordCount);
System.out.println("lines: "+lineCount);
}
catch(IOException e)
{
System.out.println("文件读取出错!");
}
if(xx == 0)
{
for(String li: listt)
{
if(words.get(li) != null)
{
words.put(li, words.get(li)+1);
}
else words.put(li, 1);
}
}
else
{
for(String li: listt)
{
if(words.get(li) != null)
{
words.put(li, words.get(li)+10);
}
else words.put(li, 10);
}
}
for(String li: lista)
{
if(words.get(li) != null)
{
words.put(li, words.get(li)+1);
}
else words.put(li, 1);
}
maplist = new ArrayList<Map.Entry<String, Integer>>(words.entrySet());
Collections.sort(maplist, new Comparator<Map.Entry<String, Integer>>(){
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
// TODO Auto-generated method stub
return o2.getValue() - o1.getValue(); //降序
}
});
//打印前十结果
for(int i=0; i<maplist.size(); i++)
{
if(i>=zz) break;
System.out.println("<"+maplist.get(i).getKey()+">: "+maplist.get(i).getValue());
}
//将词频统计输入result.txt文件中
try
{
File file = new File(outpath);
BufferedWriter br = new BufferedWriter(new FileWriter(file));
br.write("characters: "+charCount+"\r\n");
br.write("words: "+wordCount+"\r\n");
br.write("lines: "+lineCount+"\r\n");
for(int i=0; i<maplist.size(); i++)
{
if(i>=10) break;
br.write("<"+maplist.get(i).getKey()+">: "+maplist.get(i).getValue()+"\r\n");
}
br.close();
}
catch(Exception e)
{
System.out.println("文件读取出错!");
}
}
main
xx表示-w的参数,yy表示-m的参数,zz表示-n的参数,inpath表示-i的参数,outpath表示-o的参数。
public class Main {
public static void main(String[] args)
{
//long startTime = System.currentTimeMillis();
//爬虫部分 去掉注释可用
/*
lib count = new lib();
count.GetInfo();
*/
WordCount words = new WordCount();
//CountPhrase cp = new CountPhrase();
String inpath = null; //-i
String outpath = null; //-o
int xx = 0; //-w
int yy = 1; //-m
int zz = 10; //-n
for(int i=0; i<args.length;i+=2)
{
//if(args[i].equals("-i")) ;
//else if(args[i].equals("-o")) ;
if(args[i].equals("-i"))
{
inpath = args[i+1];
}
if(args[i].equals("-o"))
{
outpath = args[i+1];
}
if(args[i].equals("-w")){
xx = Integer.parseInt(args[i+1]);
}
if(args[i].equals("-m"))
{
yy = Integer.parseInt(args[i+1]);
}
if(args[i].equals("-n"))
{
zz = Integer.parseInt(args[i+1]);
}
}
words.CountChar(inpath);
words.CountLine(inpath);
words.CountWord(xx, yy, zz, inpath, outpath);
//long endTime = System.currentTimeMillis();
//System.out.println("程序运行时间:"+(endTime-startTime)+"ms");
}
}
部分测试代码
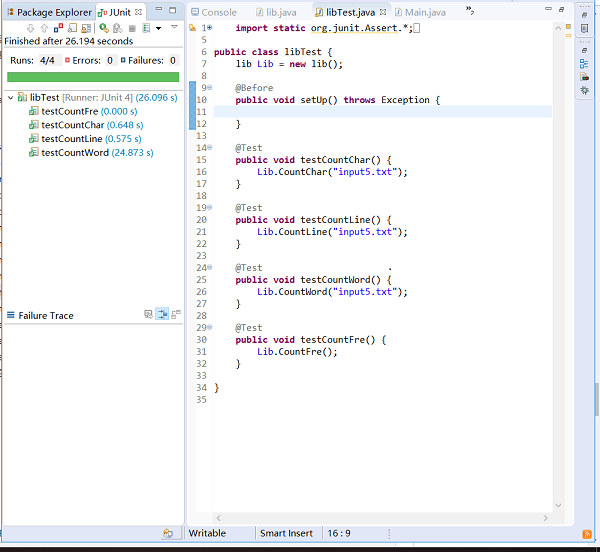
基础需求单元测试如下:分别对四个函数(CountChar(),CountLine(), CountWord(), CountFre() )进行大小为110M左右的文件测试(由测试结果可知:CountWord()所耗时间最多):
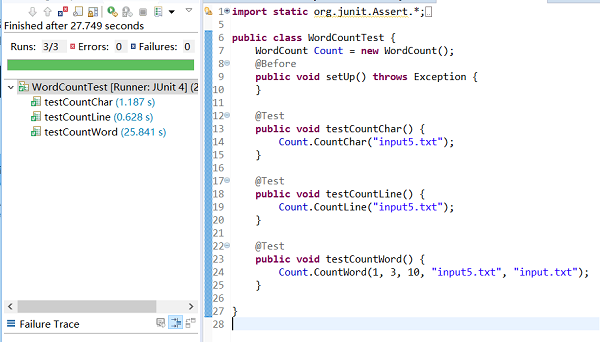
进阶需求单元测试如下:分别对三个函数(CountChar(),CountLine(), CountWord())进行大小为110M左右的文件测试(由测试结果可知:CountWord()所耗时间最多)
部分测试结果如下:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
\t\n

!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
软件工程
软件工程\t\n软件工程

abcdefghijklmnopqrstuvwxyz
1234567890
,./;'[]\<>?:"{}|`-=~!@#$%^&*()_+

e
a
d
软工
dhoisahdio
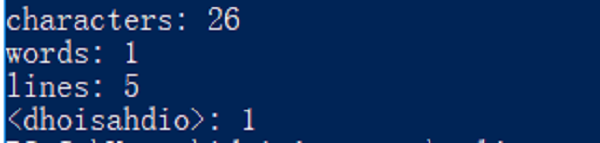
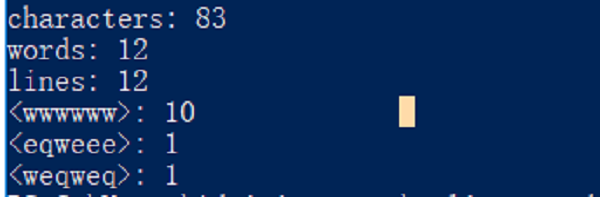
e
a
d
s
dhoisahdio

weqweq
eqweee
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
wwwwww
困难与解决
对爬虫不够熟悉,编程能力较弱。最后通过上网查资料阅读有关知识才得以完成任务。
- 队友评价
- 221600428被评价:队友思维活跃,积极参与,两人分工明确,合作较为愉快。
- 221600438被评价:队友认真细心,富有耐心,动手能力强,代码能力强,是我应该学习的对象。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号