Flink:DWD-DIM层 测试广播流
一、服务集群版本
| hadoop | 2.8.1 |
| hbase | 2.0.5 |
| hive | 3.1.2 |
| java | 1.8.0 |
| kafka | 2.11.0 |
| maxwell | 1.25.0 |
| nginx | 1.12.2 |
| phoenix | 5.0.0 |
| zookeeper | 3.4.10 |
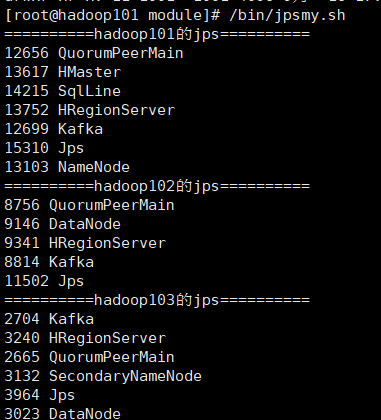
二、启动服务节点
三、在navicat中建库表
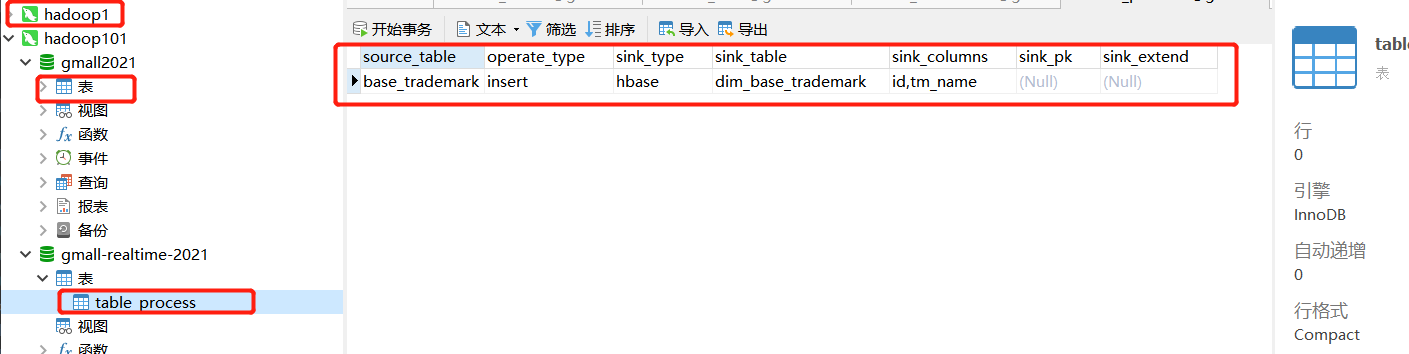
CREATE TABLE `table_process` ( `source_table` varchar(200) NOT NULL COMMENT '来源表', `operate_type` varchar(200) NOT NULL COMMENT '操作类型insert,update,delete', `sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型hbasekafka', `sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)', `sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段', `sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段', `sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展', PRIMARY KEY (`source_table`,`operate_type`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
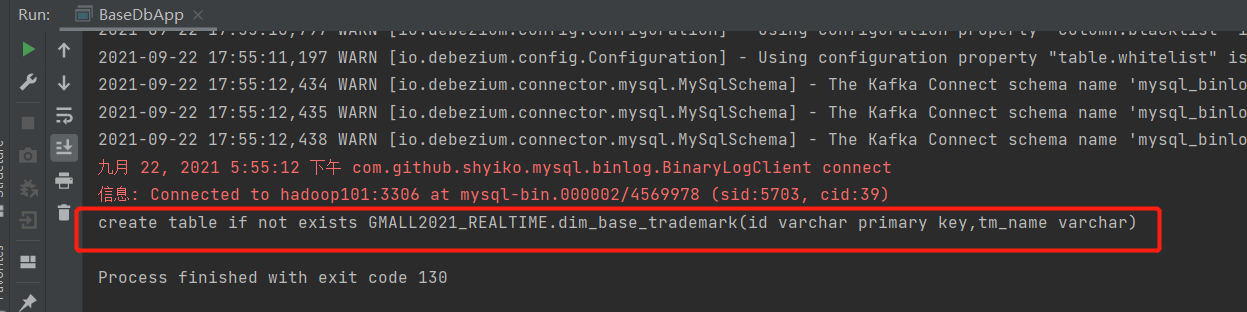
四、启动主程序
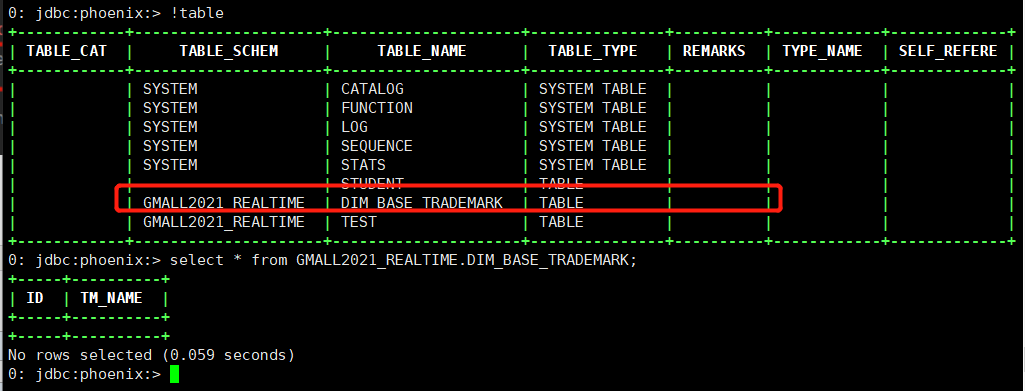
五、查看Phoenxi是否建表成功
六、源码架构图
1.pom文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>lxz0909</artifactId> <groupId>com.lexue</groupId> <version>0.0.1-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>gmall-realtime</artifactId> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <java.version>1.8</java.version> <maven.compiler.source>${java.version}</maven.compiler.source> <maven.compiler.target>${java.version}</maven.compiler.target> <flink.version>1.12.0</flink.version> <scala.version>2.12</scala.version> <hadoop.version>3.1.3</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-cep_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.68</version> </dependency> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <version>1.2.0</version> </dependency> <!--如果保存检查点到hdfs上,需要引入此依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!--Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <!--lomback插件依赖--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.14</version> <scope>provided</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-spark</artifactId> <version>5.0.0-HBase-2.0</version> <exclusions> <exclusion> <groupId>org.glassfish</groupId> <artifactId>javax.el</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
2.resources
log4j.properties
log4j.rootLogger=warn,stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
hbase-site.xml(需要根据自己实际的HBase配置文件写)
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name> hbase.master.port</name> <!-- hbasemaster的端口 --> <value>16000</value> </property> <property> <name>hbase.tmp.dir</name> <!-- hbase 临时存储 --> <value>/opt/module/hbase-2.0.5/tmp</value> </property> <property> <name>hbase.master.maxclockskew</name> <!-- 时间同步允许的时间差 单位毫秒 --> <value>180000</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop101:9000/hbase</value> <!-- hbase共享目录,持久化hbase数据 存放在对应的HDFS上 --> </property> <property> <name>hbase.cluster.distributed</name> <!-- 是否分布式运行,false即为单机 --> <value>true</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <!-- zookeeper端口 --> <value>2181</value> </property> <property> <name>hbase.zookeeper.quorum</name> <!-- zookeeper地址 --> <value>hadoop101,hadoop102,hadoop103</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <!-- zookeeper配置信息快照的位置 --> <value>/opt/module/hbase-2.0.5/tmp/zookeeper</value> </property> <!-- Phoenix配置 --> <!-- 要用单独的Schema,所以在程序中加入 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <property> <name>phoenix.schema.mapSystemTablesToNamespace</name> <value>true</value> </property> <!-- hbase二级索引配置 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> </configuration>
3.utils
MyKafkaUtil
package utils; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.functions.sink.SinkFunction; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.kafka.clients.consumer.ConsumerConfig; import java.util.Properties; public class MyKafkaUtil { private static String KAFKA_SERVER = "hadoop101:9092,hadoop102:9092,hadoop103:9092"; private static Properties properties = new Properties(); static { properties.setProperty("bootstrap.servers",KAFKA_SERVER); } // 封装Kafka消费者 public static FlinkKafkaConsumer<String> getKafkaSource(String topic,String groupId){ // 给配置信息对象添加配置项 properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,groupId); // 获取KafkaSource return new FlinkKafkaConsumer<String>(topic,new SimpleStringSchema(),properties); } // 封装Kafka生产者 public static FlinkKafkaProducer<String> getKafkaSink(String topic){ return new FlinkKafkaProducer<String>(topic,new SimpleStringSchema(),properties); } }
4.common
GmallConfig
package common; public class GmallConfig { //Phoenix库名 public static final String HBASE_SCHEMA = "GMALL2021_REALTIME"; //Phoenix驱动 public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver"; //Phoenix连接参数 public static final String PHOENIX_SERVER = "jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181"; }
5.bean
TableProcess
package bean; import lombok.Data; @Data public class TableProcess { //动态分流Sink常量 public static final String SINK_TYPE_HBASE = "hbase"; public static final String SINK_TYPE_KAFKA = "kafka"; public static final String SINK_TYPE_CK = "clickhouse"; //来源表 String sourceTable; //操作类型 insert,update,delete String operateType; //输出类型 hbase kafka String sinkType; //输出表(主题) String sinkTable; //输出字段 String sinkColumns; //主键字段 String sinkPk; //建表扩展 String sinkExtend; }
6.ods
Flink_CDCWithCustomerSchema
package app.ods; import com.alibaba.fastjson.JSONObject; import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource; import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions; import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema; import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction; import io.debezium.data.Envelope; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import org.apache.kafka.connect.data.Field; import org.apache.kafka.connect.data.Schema; import org.apache.kafka.connect.data.Struct; import org.apache.kafka.connect.source.SourceRecord; import utils.MyKafkaUtil; public class Flink_CDCWithCustomerSchema { public static void main(String[] args) throws Exception { // 1.创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.设置并行度,最好和Kafka分区数保持一致 env.setParallelism(1); //3. 创建Flink-MySQL-CDC的Source DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder() .hostname("hadoop101") .port(3306) .username("root") .password("000000") .databaseList("gmall2021") .startupOptions(StartupOptions.latest()) .deserializer(new DebeziumDeserializationSchema<String>() { // 自定义数据解析器 @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { // 获取主题信息,包含着数据库和表名 mysql_binlog_source.gmall-flink.z_user_info String topic = sourceRecord.topic(); String[] arr = topic.split("\\."); String db = arr[1]; String tableName = arr[2]; // 获取操作类型 READ DELETE UPDATE CREATE Envelope.Operation operation = Envelope.operationFor(sourceRecord); // 获取值信息并转换为Struct类型 Struct value = (Struct) sourceRecord.value(); // 获取变化后的数据 Struct after = value.getStruct("after"); // 创建JSON对象用于存储数据信息 JSONObject data = new JSONObject(); if (after != null) { Schema schema = after.schema(); for (Field field : schema.fields()) { data.put(field.name(), after.get(field.name())); } } // 创建JSON对象用于封装最终返回值数据信息 JSONObject result = new JSONObject(); // result.put("operation", operation.toString().toLowerCase()); result.put("database", db); result.put("table", tableName); result.put("data", data); result.put("after-data", after); String type = operation.toString().toLowerCase(); if ("create".equals(type)) { type = "insert"; } result.put("type", type); // 发送数据至下游 collector.collect(result.toJSONString()); } @Override public TypeInformation<String> getProducedType() { return TypeInformation.of(String.class); } }) .build(); // 3. 使用CDC Source从MySQL读取数据 DataStreamSource<String> mysqlDS = env.addSource(mysqlSource); // 4.打印数据 mysqlDS.addSink(MyKafkaUtil.getKafkaSink("ods_base_log")); // 5.执行任务 env.execute(); } }
7.func
TableProcessFunction
package app.func; import bean.TableProcess; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import common.GmallConfig; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> { // 定义Phoenix连接 private Connection connection; // 定义侧输出流标签 private OutputTag<JSONObject> objectOutputTag; // 定义Map状态表述器 private MapStateDescriptor<String,TableProcess> mapStateDescriptor; public TableProcessFunction() { } public TableProcessFunction(OutputTag<JSONObject> objectOutputTag, MapStateDescriptor<String,TableProcess> mapStateDescriptor) { this.objectOutputTag = objectOutputTag; this.mapStateDescriptor = mapStateDescriptor; } @Override public void open(Configuration parameters) throws Exception { Class.forName(GmallConfig.PHOENIX_DRIVER); connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER); } // 处理广播数据 @Override public void processBroadcastElement(String value, Context ctx, Collector<JSONObject> out) throws Exception { // 1.将数据转换为JavaBean value:{"database":"gmall-","table":"table_process","type":"insert" // ,"data":{"":""},"before-data":{"":""}} JSONObject jsonObject = JSON.parseObject(value); JSONObject data = jsonObject.getJSONObject("data"); TableProcess tableProcess = JSON.parseObject(data.toJSONString(), TableProcess.class); // 2.检验表是否存在。如果不存在,则创建Phoenix表 if (tableProcess != null) { if (TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())) { checkTable(tableProcess.getSinkTable(), tableProcess.getSinkColumns(), tableProcess.getSinkPk(), tableProcess.getSinkExtend()); } } // 3.将数据写入状态广播处理 BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor); String key = tableProcess.getSourceTable() + ":" + tableProcess.getOperateType(); broadcastState.put(key,tableProcess); } // 处理主流数据 @Override public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<JSONObject> out) throws Exception { out.collect(value); } private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend) { // 处理主键以及扩展字段 if (sinkPk == null || sinkPk.equals("")) { sinkPk = "id"; } if (sinkExtend == null) { sinkExtend = ""; } // 创建 建表SQL // create table if not exists xx.xx (id int,name varchar(10)); StringBuilder createTableSQL = new StringBuilder("create table if not exists ") .append(GmallConfig.HBASE_SCHEMA) .append(".") .append(sinkTable) .append("("); // 将建表字段拆分开 String[] columns = sinkColumns.split(","); for (int i = 0; i < columns.length; i++) { // 需要考虑的事情,1-是否是主键,2-是否是最后一个字段 String column = columns[i]; // 如果当前字段是主键 if (sinkPk.equals(column)) { createTableSQL.append(column).append(" varchar").append(" primary key"); // 此处的建表语句,需要有空格 } else { createTableSQL.append(column).append(" varchar"); } // 如果当前字段不是最后一个字段 if (i < columns.length - 1) { createTableSQL.append(","); } } // 拼接扩展字段 createTableSQL.append(")").append(sinkExtend); // 打印sql String sql = createTableSQL.toString(); System.out.println(sql); PreparedStatement preparedStatement = null; // 执行sql建表 try { preparedStatement = connection.prepareStatement(sql); preparedStatement.execute(); } catch (SQLException e) { throw new RuntimeException("Phoenix建表失败!"); } finally { if (preparedStatement != null) { try { preparedStatement.close(); } catch (SQLException e) { e.printStackTrace(); } } } } }
MyDeserializerFunc
package app.func; import com.alibaba.fastjson.JSONObject; import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema; import io.debezium.data.Envelope; import org.apache.flink.api.common.typeinfo.BasicTypeInfo; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.util.Collector; import org.apache.kafka.connect.data.Field; import org.apache.kafka.connect.data.Struct; import org.apache.kafka.connect.source.SourceRecord; public class MyDeserializerFunc implements DebeziumDeserializationSchema<String> { /** * { * "data":"{"id":11,"tm_name":"sasa"}", * "db":"", * "tableName":"", * "op":"c u d", * "ts":"" * } */ @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { //获取主题信息,提取数据库和表名 String topic = sourceRecord.topic(); String[] fields = topic.split("\\."); String db = fields[1]; String tableName = fields[2]; //获取Value信息,提取数据本身 Struct value = (Struct) sourceRecord.value(); Struct after = value.getStruct("after"); JSONObject jsonObject = new JSONObject(); if (after != null) { for (Field field : after.schema().fields()) { Object o = after.get(field); jsonObject.put(field.name(), o); } } //获取Value信息,提取删除或者修改的数据本身 Struct before = value.getStruct("before"); JSONObject beforeJson = new JSONObject(); if (before != null) { for (Field field : before.schema().fields()) { Object o = before.get(field); beforeJson.put(field.name(), o); } } //获取操作类型 Envelope.Operation operation = Envelope.operationFor(sourceRecord); //创建结果JSON JSONObject result = new JSONObject(); result.put("database", db); result.put("table", tableName); result.put("data", jsonObject); result.put("before-data", beforeJson); String type = operation.toString().toLowerCase(); if ("create".equals(type)) { type = "insert"; } result.put("type", type); //输出数据 collector.collect(result.toJSONString()); } @Override public TypeInformation<String> getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; } }
8.dwd
BaseLogApp
package app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.restartstrategy.RestartStrategies; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import utils.MyKafkaUtil; // 数据流 Web、App -> Nginx -> SpringBoot -> Kafka -> Flink -> Kafka // 进程 Mock -> Nginx -> Logger.sh -> Kafka(ZK) -> BaseLogApp -> Kafka public class BaseLogApp { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度 最好和Kafka分区保持一致 env.setParallelism(1); // 1.1 开启CK // env.enableCheckpointing(5000L); // env.getCheckpointConfig().setCheckpointTimeout(10000L); // env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // // 正常Cancel任务时,保留最后一次CK // env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // // 重启策略 // env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L)); // // 状态后端 // env.setStateBackend(new FsStateBackend("hdfs://hadoop1:8020/gamll-flink-2021/ck")); // // 设置访问HDFS的用户名 // System.setProperty("HADOOP_USER_NAME","root"); // 2.读取Kafka ods_base_log主题数据 String topic = "ods_base_log"; String groupId = "ods_dwd_base_log_app"; FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId); DataStreamSource<String> kafkaDS = env.addSource(kafkaSource); // 3.将每行数据转换为JSONObject // 为了下面ctx.output异常抛出 OutputTag<String> dirty = new OutputTag<String>("DirtyData") { }; SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() { @Override public void processElement(String value, Context ctx, Collector<JSONObject> out) throws Exception { try { JSONObject jsonObject = JSON.parseObject(value); out.collect(jsonObject); } catch (Exception e) { ctx.output(dirty, value); } } }); // 4.按照Mid分组 SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlag = jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid")) .process(new KeyedProcessFunction<String, JSONObject, JSONObject>() { // 定义状态 private ValueState<String> isNewState; // 初始化状态 @Override public void open(Configuration parameters) throws Exception { isNewState = getRuntimeContext().getState(new ValueStateDescriptor<String>("isNew-state", String.class)); } @Override public void processElement(JSONObject jsonObject, Context ctx, Collector<JSONObject> out) throws Exception { // 取出数据中”is_new“字段 String isNew = jsonObject.getJSONObject("common").getString("is_new"); // 如果isNew为1,则需要继续校验 if ("1".equals(isNew)) { // 取出状态中的数据,并判断是否为null if (isNewState.value() != null) { // 说明当前mid不是新用户,修改is_new的值 jsonObject.getJSONObject("common").put("is_new", "0"); } else { // 说明为真正的新用户 isNewState.update("0"); } } // 输出数据 out.collect(jsonObject); } }); // .执行任务测试 // jsonObjWithNewFlag.print(">>>>>>>>>>>>>>>>>"); // 5.使用侧输出流将 启动、曝光、页面数据分流 OutputTag<String> startoutputTag = new OutputTag<String>("start"){ }; OutputTag<String> displayoutputTag = new OutputTag<String>("display") { }; SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlag.process(new ProcessFunction<JSONObject, String>() { @Override public void processElement(JSONObject jsonObject, Context ctx, Collector<String> out) throws Exception { // 获取启动数据 String start = jsonObject.getString("start"); if (start != null && start.length() > 0) { // 为启动数据 ctx.output(startoutputTag, jsonObject.toJSONString()); } else { // 不是启动数据,则一定为页面数据 out.collect(jsonObject.toJSONString()); // 获取曝光数据 JSONArray displays = jsonObject.getJSONArray("displays"); // 取出公共字段、页面信息、时间戳 JSONObject common = jsonObject.getJSONObject("common"); JSONObject page = jsonObject.getJSONObject("page"); Long ts = jsonObject.getLong("ts"); // 判断曝光数据是否存在 if (displays != null && displays.size() > 0) { JSONObject displayObj = new JSONObject(); displayObj.put("common", common); displayObj.put("page", page); displayObj.put("ts", ts); // 遍历每一个曝光信息 for (Object display : displays) { displayObj.put("display", display); // 输出到侧输出流 ctx.output(displayoutputTag, displayObj.toJSONString()); } } } } }); // 6.将三个流的数据写入Kafka jsonObjDS.getSideOutput(dirty).print("Dirty>>>>>>>>>>>>"); pageDS.print("page>>>>>>>>>"); pageDS.getSideOutput(startoutputTag).print("Start>>>>>>>>>>>"); pageDS.getSideOutput(displayoutputTag).print("Dirty>>>>>>>>>>"); // 创建Kakfa主题 String pageSinkTopic = "dwd_page_log"; String startSinkTopic = "dwd_start_log"; String displaySinkTopic = "dwd_display_log"; pageDS.addSink(MyKafkaUtil.getKafkaSink(pageSinkTopic)); pageDS.getSideOutput(startoutputTag).addSink(MyKafkaUtil.getKafkaSink(startSinkTopic)); pageDS.getSideOutput(displayoutputTag).addSink(MyKafkaUtil.getKafkaSink(displaySinkTopic)); env.execute(); } }
BaseBdApp(本次测试启动的主程序,仅启动它即可)
package app.dwd; import app.func.MyDeserializerFunc; import app.func.TableProcessFunction; import bean.TableProcess; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource; import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions; import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.OutputTag; import utils.MyKafkaUtil; public class BaseDbApp { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 1.1 开启CK // env.enableCheckpointing(5000L); // env.getCheckpointConfig().setCheckpointTimeout(10000L); // env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // // 正常Cancel任务时,保留最后一次CK // env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // // 重启策略 // env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,5000L)); // // 状态后端 // env.setStateBackend(new FsStateBackend("hdfs://hadoop1:8020/gamll-flink-2021/ck")); // // 设置访问HDFS的用户名 // System.setProperty("HADOOP_USER_NAME","root"); // TODO 2.读取Kafka ods_base_db 主题的数据 String sourceTopic = "ods_base_db"; String groupId = "base_db_app_group"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaSource(sourceTopic, groupId)); // TODO 3.将每行数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(line -> { return JSON.parseObject(line); }); // TODO 4.过滤空值 SingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.filter(jsonObj -> { String data = jsonObj.getString("data"); return data != null && data.length() > 0; }); // TODO 5.使用FlinkCDC读取配置表并创建广播流 DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder() .hostname("hadoop101") .port(3306) .username("root") .password("000000") .databaseList("gmall-realtime-2021") .startupOptions(StartupOptions.initial()) .deserializer(new MyDeserializerFunc()) .build(); DataStreamSource<String> tableProcessDS = env.addSource(sourceFunction); MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("bc-state", String.class, TableProcess.class); BroadcastStream<String> broadcastStream = tableProcessDS.broadcast(mapStateDescriptor); // TODO 6.连接主流和广播流 BroadcastConnectedStream<JSONObject, String> connectedStream = filterDS.connect(broadcastStream); // TODO 7.处理广播流数据,发送至主流,主流根据广播流的数据进行处理自身数据(分流) OutputTag<JSONObject> hbaseOutputTag = new OutputTag<JSONObject>("hbase") { }; SingleOutputStreamOperator<JSONObject> process = connectedStream.process(new TableProcessFunction(hbaseOutputTag, mapStateDescriptor)); process.print(); // TODO 8.将HBase流写入HBase // TODO 9.将Kafka流写入Kafka // TODO 10.启动 env.execute(); } }
七、遇到的问题
1.在TableProcessFunction中的建表语句,一定要注意空格的使用,不可忽略!
2.注意服务jar包版本的依赖关系要和Pom文件中的版本保持一致,不然会报错。
不要为了追逐,而忘记当初的样子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号