Flink StreamExecutionEnvironment API
Flink流式处理API流程图

# 创建流式处理任务环境
StreamExecutionEnvironment env = StreamExceptionEnvironment.getExceptionEnvironment();
创建一个执行环境,表示当前执行程序的上下文,类似于SparkContext.
如果程序是独立调用的,则此方法返回本地执行环境.;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境.
案例:读取摄氏度
Source:从集合和元素读取数据
public class SensorReading { private String id; private Long ts; private Double temperature; public SensorReading(){ } public SensorReading(String id,Long ts,Double temperature){ this.id = id; this.ts = ts; this.temperature = temperature; } public String getId(){ } public void setId(String id){ this.id = id; } }
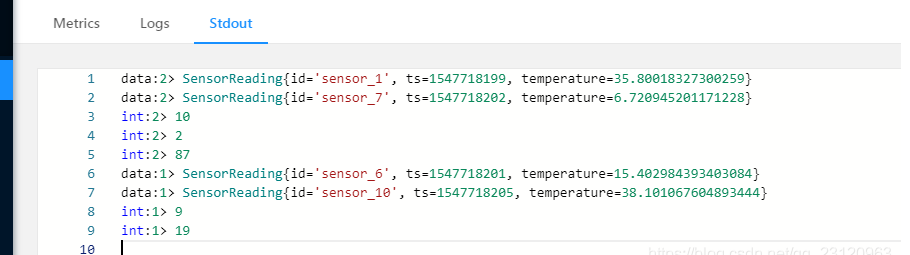
# 主程序 import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Arrays; /** * @ClassName CollectionSourceTest * @Description 从集合中读取数据 * @Author Administrator * @Version 1.0 **/ public class CollectionSourceTest { public static void main(String[] args) throws Exception { // 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从集合读取数据 DataStream<SensorReading> dataStream = env.fromCollection(Arrays.asList( new SensorReading("sensor_1", 1547718199L, 35.80018327300259), new SensorReading("sensor_6", 1547718201L, 15.402984393403084), new SensorReading("sensor_7", 1547718202L, 6.720945201171228), new SensorReading("sensor_10", 1547718205L, 38.101067604893444) )); // 直接读取元素 DataStream<Integer> integerDataStream = env.fromElements(10, 9, 2, 19, 87); // 输出 设置每个stream的前缀标识 dataStream.print("data"); integerDataStream.print("int"); // 执行 设置StreamJob名字 env.execute("CollectionSourceTest"); } }
执行结果:
POJO和JavaBean规范:
1) JavaBean的规范如下:
a.实现 java.io.Serializable 接口.
b.是一个公共类,类中必须存在一个无参数的构造函数,提供对应的setXxx()和getXxx()方法来存取类中的属性.
2) Flink的POJO规范如下:
a.该类是公有的(public)和独立的(没有非静态内部类)
b.该类拥有公有的无参构造器
c.该(以及所有超类)中的所有非静态,非transient字段都是公有的(非final的),或者具有遵循JavaBean对于getter和setter命名规则的公有getter和setter方法.
案例:从文件读取数据
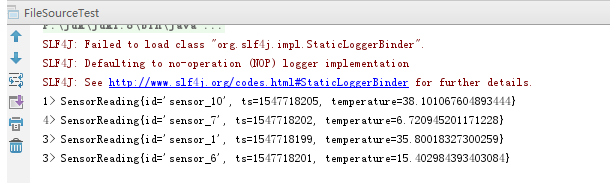
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @ClassName file * @Description TODO * @Author Administrator * @Version 1.0 **/ public class FileSourceTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> dataStream = env.readTextFile(fpath); // 转换成SensorReading DataStream<SensorReading> sensorReadingDataStream = dataStream.map(line -> { String[] split = line.split(","); return new SensorReading(split[0], Long.valueOf(split[1]), Double.valueOf(split[2])); }); sensorReadingDataStream.print(); env.execute(); } }
运行结果:
从Kafka读取数据
针对不同版本的Kafka,Flink有对应的connectors,请参考这里.
当前案例版本Flink1.10.1 Kafka1.1.0
# pom <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.10.1</version> </dependency>
# 主程序 import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import java.util.Properties; /** * @ClassName KafkaSourceTest * @Description 消费kafka信息 * @Author Administrator * @Version 1.0 **/ public class KafkaSourceTest { public static void main(String[] args) throws Exception { // 创建流式执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Kafka信息 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092"); properties.setProperty("group.id", "FlinkKafkaSourceTest"); // 添加kafka source DataStream<String> kafkaDataStream = env.addSource(new FlinkKafkaConsumer<String>("patrick", new SimpleStringSchema(), properties)) .setParallelism(6); System.out.println("kafkaDataStream parallelism: "+kafkaDataStream.getParallelism()); kafkaDataStream.print(); env.execute(); } }
创建消费者查看消费情况:

# 注意 # 创建分区数为3副本为2的topic kafka-topics.sh --zookeeper hadoop1:2181 --create --replication-factor 2 --partitions 3 --topic patrick # 控制台生成消息 kafka-console-producer.sh --broker-list hadoop1:9092 --topic patrick
自定义数据源
需要实现接口 org.apache.flink.streaming.api.functions.source.SourceFunction
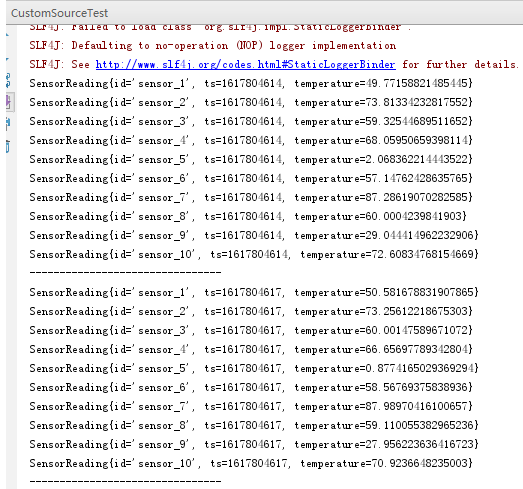
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.util.*; import java.util.concurrent.TimeUnit; /** * @ClassName CustomSourceTest * @Description 自定义Source * @Author Administrator * @Version 1.0 **/ public class CustomSourceTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<SensorReading> dataStream = env.addSource(new MySensorSourceFunction(), "MySensorSourceFunction"); dataStream.print(); env.execute(); } /** * 生产传感器数据 */ public static class MySensorSourceFunction implements SourceFunction<SensorReading>{ private boolean running = true; /** * 产生数据 * @param ctx * @throws Exception */ @Override public void run(SourceContext<SensorReading> ctx) throws Exception { Random random = new Random(); // 这里想按照传感器最后面的ID来按序输出, 所以使用TreeMap并自定义比较器 Map<String, Double> sensorTemp = new TreeMap<String, Double>((o1, o2)->{ Integer s1 = Integer.valueOf(o1.split("_")[1]); Integer s2 = Integer.valueOf(o2.split("_")[1]); return s1.compareTo(s2); }); // 定义10个传感器并为其设置初始温度 for (int i=0; i<10; ++i){ sensorTemp.put("sensor_"+(i+1), 60+random.nextGaussian()*20); } while (running){ for(String sensorId : sensorTemp.keySet()){ Double newTemp = sensorTemp.get(sensorId)+random.nextGaussian(); sensorTemp.put(sensorId, newTemp); // 发送数据 ctx.collect(new SensorReading(sensorId, System.currentTimeMillis()/1000, newTemp)); } System.out.println("--------------------------------"); // 控制发送频率 TimeUnit.SECONDS.sleep(3); } } @Override public void cancel() { running=false; } } }
Transform
基本算子(map,flatMap,filter)
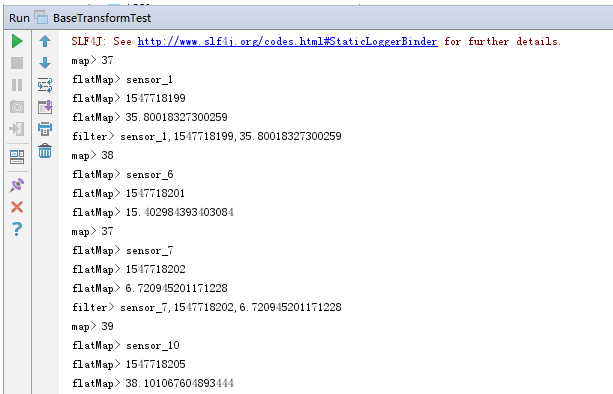
import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @ClassName BaseTransformTest * @Description 基本算子 map flatMap filter * @Author Administrator * @Version 1.0 **/ public class BaseTransformTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 1. map 将每行数据转换成每行的字符串长度 DataStream<Integer> mapStream = inputStream.map(value -> value.length()); // 2. flatMap 将每行数据按照逗号分割并输出; 第二个参数是为了指定返回flatMap的返回类型 DataStream<String> flatMapStream = inputStream.flatMap((String value, Collector<String> out) -> { for (String field : value.split(",")) { out.collect(field); } }, TypeInformation.of(String.class)); // 3. filter 只输出sensorId是奇数的数据 DataStream<String> filterStream = inputStream.filter(value -> Integer.valueOf(value.split(",")[0].split("_")[1]) % 2 != 0); // 输出 mapStream.print("map"); flatMapStream.print("flatMap"); filterStream.print("filter"); env.execute(); } }
分组(keyBy)+滚动聚合算子(Rolling Aggregation)
1) 分组算子如下:
DataStream->KeyedStream:逻辑上将一个流分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的.
KeyedStream才有聚合算子(其并行度依赖于前置的DataStream),不能单独设置并行度),普通的DataStream是没有的,但是KeyedStream依旧继承于DataStream.
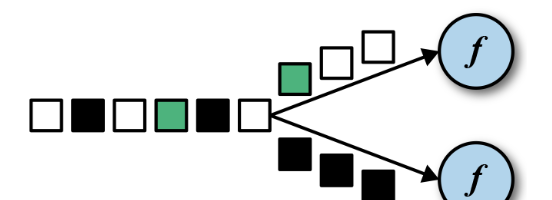
2) 滚动算子如下:
这些算子可以针对KeyedStream的每一个支流做聚合
sum(),min(),max(),minBy(),maxBy()
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @ClassName RollTransformTest * @Description keyBy + RollingAggregation * @Author Administrator * @Version 1.0 **/ public class RollTransformTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); // keyBy分组获取KeydStream 聚合API在KeydStream才有 只有当输入类型是Tuple时keyBy分组这里才能写数字 KeyedStream<SensorReading, Tuple> keyedStream = dataStream.keyBy("id"); // KeyedStream<SensorReading, String> keyedStream = dataStream.keyBy(data -> data.getId()); // KeyedStream<SensorReading, String> keyedStream = dataStream.keyBy(SensorReading::getId); // 滚动聚合 获取温度最大的 // max会更新temperature值, 其他值不变 // maxBy是获取temperature值最大的那条数据 DataStream<SensorReading> resultMaxStream = keyedStream.max("temperature"); DataStream<SensorReading> resultMaxByStream = keyedStream.maxBy("temperature"); // resultMaxStream.print("resultMaxStream"); resultMaxByStream.print("resultMaxByStream"); // 分组求最大值 dataStream.keyBy("id").sum("temperature").map(data->data.getId()+"\t"+data.getTemperature()).print(); // // 全局求所有温度 仅限练习API操作 // dataStream.map(data->new Tuple2("", data), Types.TUPLE(Types.STRING, Types.POJO(SensorReading.class))) // .keyBy(0).sum("f1.temperature") // .map(d->((SensorReading)d.f1).getTemperature()) // .print(); env.execute(); } }
Reduce算子
KeyedStream->DataStream:一个分组数据流的聚合操作.合并当前的元素和上次聚合的结果,产生一个新的值.返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果.
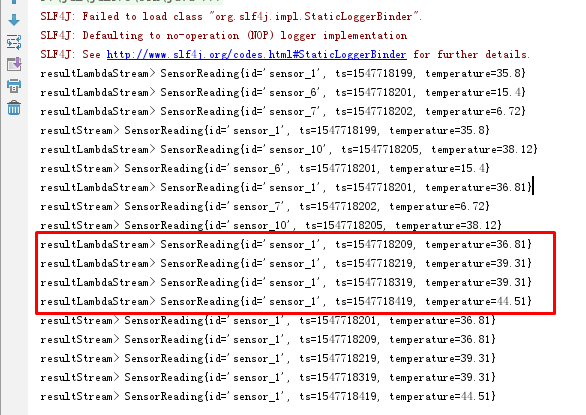
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @ClassName ReduceTransformTest * @Description TODO * @Author Administrator * @Version 1.0 **/ public class ReduceTransformTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); // keyBy分组获取KeydStream 聚合API在KeydStream才有 只有当输入类型是Tuple时keyBy分组这里才能写数字 KeyedStream<SensorReading, Tuple> keyedStream = dataStream.keyBy("id"); // reduce操作 获取最新时间戳+最大温度值 DataStream<SensorReading> resultStream = keyedStream.reduce(new ReduceFunction<SensorReading>() { @Override public SensorReading reduce(SensorReading value1, SensorReading value2) throws Exception { return new SensorReading(value1.getId(), value2.getTs(), Math.max(value1.getTemperature(), value2.getTemperature())); } }); // 采用lambda函数 DataStream<SensorReading> resultLambdaStream = keyedStream.reduce((currState, newValue) -> new SensorReading(currState.getId(), newValue.getTs(), Math.max(currState.getTemperature(), newValue.getTemperature()))); resultStream.print("resultStream"); resultLambdaStream.print("resultLambdaStream"); env.execute(); } }
多流操作算子 Split+Select
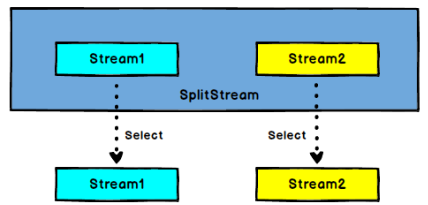
1) Split算子
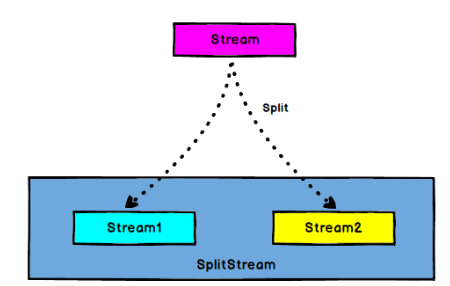
DataStream->SplitStream:根据某些特征把一个DataStream拆分成两个或者多个DataStream
1) Select算子
SplitStream->DataStream:从一个SplitStream中获取一个或者多个DataStream.需求:传感器数据按照温度高低(以37度为界),拆分成两个流.
Connect+map(CoMapFunction)
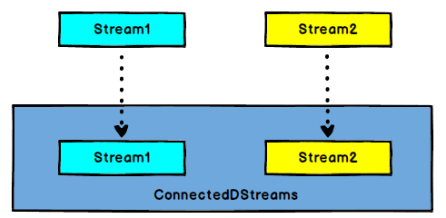
1) Connect算子
DataStream,DataStream->ConnectedStreams:连接两个保持他们的类型的数据流,两个数据流被Connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立.
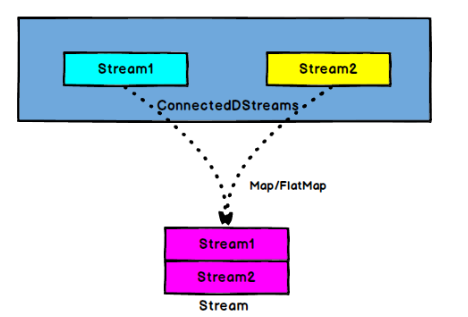
2) map(CoMapFunction)算子
ConnectedStream->DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStream中的每一个Stream分别进行map和flatMap处理.
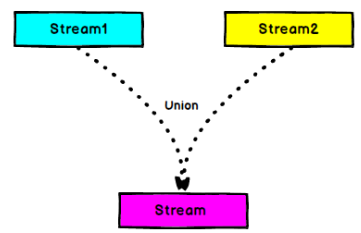
Union
DataStream->DataStream:对两个或者两个以上的DataStream进行union操作.产生一个包含所有的DataStream元素的新DataStream
Connect和Union的区别:
1) Union之前两个流的类型必须一样,Connect可以不一样,在之后的CoMap中再调整成为一样的
2) Connect只能操作两个流,Union可以多个.
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.collector.selector.OutputSelector; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.SplitStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoMapFunction; import java.util.Collections; /** * @ClassName SplitTransformTest * @Description 分流操作 * @Author Administrator * @Version 1.0 **/ public class MultipleTransformTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); // 1.1 分流 split 实际上通俗地说是打标 当然每条数据可能有多个标记 SplitStream<SensorReading> splitStream = dataStream.split(new OutputSelector<SensorReading>() { @Override public Iterable<String> select(SensorReading value) { return value.getTemperature()>37? Collections.singletonList("high") : Collections.singletonList("low"); } }); // 1.2 获取 select 从SplitStream中获取对应标签数据 DataStream<SensorReading> highStream = splitStream.select("high"); DataStream<SensorReading> lowStream = splitStream.select("low"); DataStream<SensorReading> allStream = splitStream.select("high", "low"); // 输出 // highStream.print("high"); // lowStream.print("low"); // allStream.print("all"); // 2.1 不同数据类型合流 connect 只能合并两条流,但是两条流的数据类型可以不是一样的 // 将高温流转换成 Tuple2<String, Double> DataStream<Tuple2<String, Double>> warningStream = highStream.map(new MapFunction<SensorReading, Tuple2<String, Double>>() { @Override public Tuple2<String, Double> map(SensorReading value) throws Exception { return new Tuple2<String, Double>(value.getId(), value.getTemperature()); } }); ConnectedStreams<Tuple2<String, Double>, SensorReading> connectedStream = warningStream.connect(lowStream); // 2.2 map(CoMapFunction) 合并流 DataStream<Object> coMapStream = connectedStream.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() { @Override public Object map1(Tuple2<String, Double> value) throws Exception { return new Tuple3<String, Double, String>(value.f0, value.f1, "warning"); } @Override public Object map2(SensorReading value) throws Exception { return new Tuple2<String, String>(value.getId(), "normal"); } }); // coMapStream.print(); // 3. 将相同数据类型的两个或两个以上的流进行合并 union highStream.union(lowStream, allStream).print(); env.execute(); } }
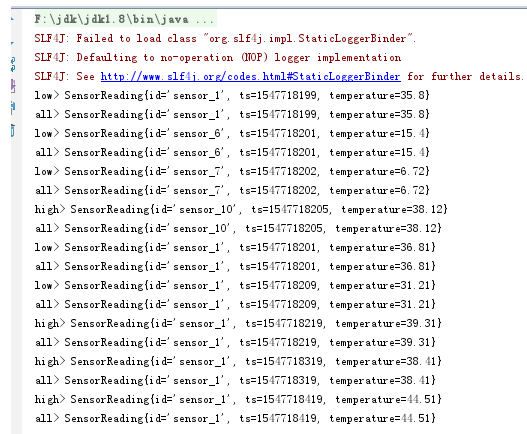
流式转换关系图:
Sink
Flink没有类似于spark中foreach方法,让用户进行迭代的操作。所有对外的输出操作都要利用Sink完成。最后通过类似如stream.addSink(new MySink(xxxx))完成整个任务最终输出操作。
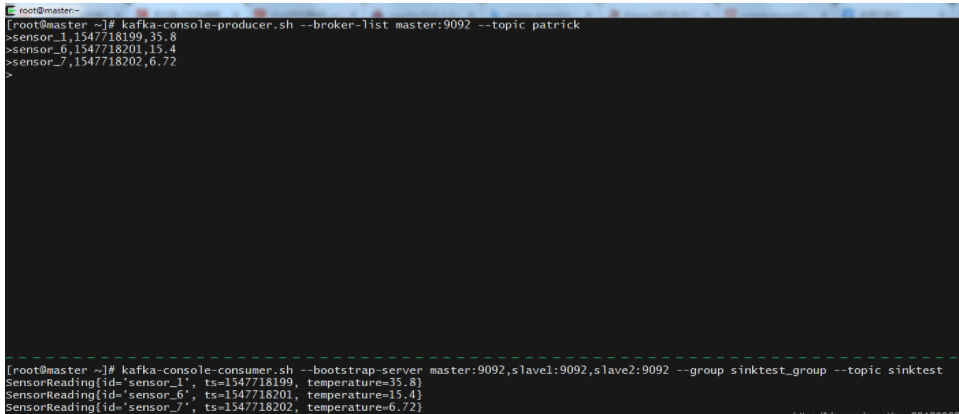
Kafka
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import java.util.Properties; /** * @ClassName KafkaSinkTest * @Description KafkaSink测试 * @Author Administrator * @Version 1.0 **/ public class KafkaSinkTest { public static void main(String[] args) throws Exception { // 创建流式执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Kafka信息 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092"); properties.setProperty("group.id", "FlinkKafkaSourceTest"); // 添加kafka source DataStream<String> kafkaDataStream = env.addSource(new FlinkKafkaConsumer<String>("patrick", new SimpleStringSchema(), properties)) ; // 先通过map转换成SensorReading的字符串 DataStream<String> dataStream = kafkaDataStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])).toString(); }); dataStream.addSink(new FlinkKafkaProducer<String>( "hadoop1:9092,hadoop2:9092,hadoop3:9092", "sinktest", new SimpleStringSchema())); env.execute(); } }
# 控制台生成消息 kafka-console-producer.sh --broker-list hadoop1:9092 --topic patrick # 用命令行消费消息 kafka-console-consumer.sh --bootstrap-server hadoop1:9092 --group sinktest_group --topic sinktest
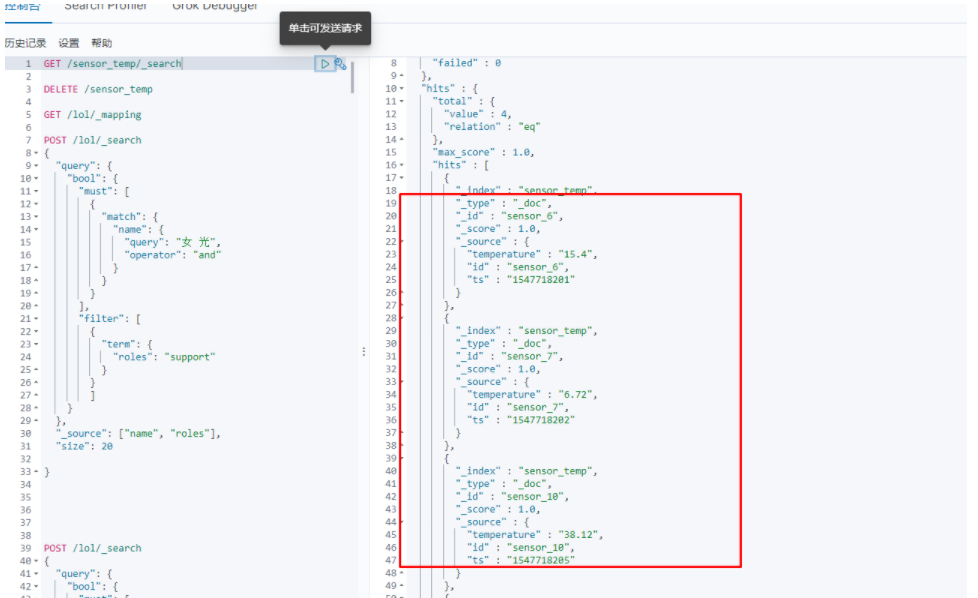
执行结果图如下所示。那么该Flink程序相当于做了ETL工作从Kafka的一个topic传输到另一个topic
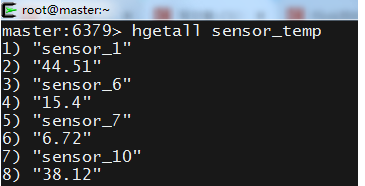
Redis
# pom <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.0</version> </dependency>
# 主程序 import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; /** * @ClassName RedisSinkTest * @Description 输出到Redis * @Author Administrator * @Version 1.0 **/ public class RedisSinkTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); // 定义Jedis连接配置 FlinkJedisPoolConfig jedisPoolConfig = new FlinkJedisPoolConfig.Builder() .setHost("hadoop1") .setPort(6379) .build(); dataStream.addSink( new RedisSink<>(jedisPoolConfig, new MyRedisMapper())); env.execute(); } public static class MyRedisMapper implements RedisMapper<SensorReading>{ // 例如将每个传感器对应的温度值存储成哈希表 hset key field value @Override public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.HSET, "sensor_temp"); } @Override public String getKeyFromData(SensorReading data) { return data.getId(); } @Override public String getValueFromData(SensorReading data) { return data.getTemperature().toString(); } } }
ElasticSearch
# pom <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7_2.11</artifactId> <version>${flink.version}</version> </dependency>
import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction; import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer; import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink; import org.apache.http.HttpHost; import org.elasticsearch.client.Requests; import java.util.ArrayList; import java.util.HashMap; import java.util.List; /** * @ClassName EsSinkTest * @Description 输出到ES * @Author Administrator * @Version 1.0 **/ public class EsSinkTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); // 定义ES连接配置 List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("master", 9200)); dataStream.addSink(new ElasticsearchSink.Builder<>(httpHosts, new MyEsSinkFunction()).build()); env.execute(); } public static class MyEsSinkFunction implements ElasticsearchSinkFunction<SensorReading>{ @Override public void process(SensorReading element, RuntimeContext ctx, RequestIndexer indexer) { HashMap<String, String> sourceMap = new HashMap<>(); sourceMap.put("id", element.getId()); sourceMap.put("ts", element.getTs().toString()); sourceMap.put("temperature", element.getTemperature().toString()); indexer.add(Requests.indexRequest("sensor_temp") // 指定文档ID 不指定则ES默认生成 .id(element.getId()) .source(sourceMap)); } } }
JDBC
为了保证高效这里使用到了Druid连接池。
但是在Flink的1.11版本已经有了官方的JDBC连接器
# pom <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.10</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.6</version> </dependency>
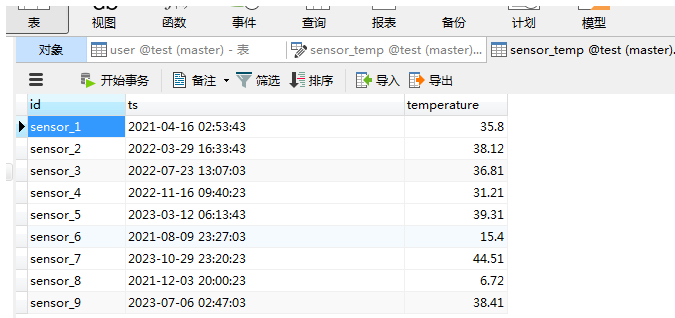
import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; import com.patrick.examples.apitest.beans.SensorReading; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import org.apache.flink.streaming.api.functions.sink.SinkFunction; import javax.sql.DataSource; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; import java.sql.Timestamp; import java.util.Properties; import java.util.concurrent.TimeUnit; /** * @ClassName JdbcSinkTest * @Description 自定以Sink输出到Mysql * @Author Administrator * @Version 1.0 **/ public class JdbcSinkTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); String fpath = "F:\\FlinkDemo\\src\\main\\resources\\sensor.txt"; // 从文件读取数据 DataStream<String> inputStream = env.readTextFile(fpath); // 先通过map转换成SensorReading DataStream<SensorReading> dataStream = inputStream.map(value -> { String[] fields = value.split(","); return new SensorReading(fields[0], Long.valueOf(fields[1]), Double.valueOf(fields[2])); }); dataStream.addSink(new MyJDBCSink()).setParallelism(5).name("JDBCSink"); env.execute(); } public static class MyJDBCSink extends RichSinkFunction<SensorReading>{ private DruidDataSource dataSource; public static final String INSERT_SQL = "INSERT INTO `sensor_temp` (`id`, `ts`, `temperature`) VALUES (?, ?, ?)"; @Override public void open(Configuration parameters) throws Exception { // 创建JDBC连接 Properties properties = new Properties(); properties.setProperty(DruidDataSourceFactory.PROP_URL, "jdbc:mysql://hadoop1:3306/test?useUnicode=true&characterEncoding=utf-8"); properties.setProperty(DruidDataSourceFactory.PROP_USERNAME, "root"); properties.setProperty(DruidDataSourceFactory.PROP_PASSWORD, "000000"); properties.setProperty(DruidDataSourceFactory.PROP_DRIVERCLASSNAME, "com.mysql.jdbc.Driver"); // 使用Druid连接池 这样在处理每个event获取连接时就是线程安全的,且效率也会比较高 // 当然到JDBCSink的每个分区里都是线程安全的,每个分区对应一个线程,每个线程都调用自己的open方法 dataSource = (DruidDataSource)DruidDataSourceFactory.createDataSource(properties); System.out.println(getRuntimeContext().getTaskNameWithSubtasks()+" "+dataSource); System.out.println(getRuntimeContext().getTaskNameWithSubtasks()+" "+dataSource.getClass()); // 只有第一个任务才执行删除表内容的操作 if(getRuntimeContext().getIndexOfThisSubtask()==0){ deleteRecords(); }else{ // 这里只是保证先删除表, 实际上在生产环境上这个根本没有作用,因为是并发,先后顺序不可控的 TimeUnit.SECONDS.sleep(5); } } @Override public void close() throws Exception { } @Override public void invoke(SensorReading value, Context context) throws Exception { insertSensorReading(value); } // 删除表 private void deleteRecords() throws SQLException { try(Connection connection = dataSource.getConnection(); PreparedStatement preparedStatement = connection.prepareStatement("delete from sensor_temp"); ){ boolean execute = preparedStatement.execute(); } } // 添加记录 private void insertSensorReading(SensorReading value) throws SQLException { try(Connection connection = dataSource.getConnection(); PreparedStatement preparedStatement = connection.prepareStatement(INSERT_SQL); ){ preparedStatement.setString(1, value.getId()); preparedStatement.setTimestamp(2, new Timestamp(value.getTs())); preparedStatement.setDouble(3, value.getTemperature()); boolean execute = preparedStatement.executeUpdate() == 1?true:false; System.out.println(getRuntimeContext().getTaskNameWithSubtasks()+" 处理SQL "+value+" 结果是 "+execute + "连接是"+connection.toString()); } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号