使用Python+TensorFlow2构建基于卷积神经网络(CNN)的ECG心电信号识别分类(四)
在上一篇文章中,我们已经对心电信号进行了预处理,将含有噪声的信号变得平滑,以便分类。本篇文章我们将正式开始利用深度学习对心电信号进行分类识别。
卷积神经网络
不论是传统机器学习,还是深度学习,分类的依据都是不同类别的数据中包含的不同特征。要进行分类识别就需要对数据的特征进行提取,但是二者的提取方式并不相同。对于传统的机器学习而言,数据的特征需要设计者或专业人员针对其特性进行手动提取,而深度学习则可以自动提取每类数据中的不同特征。对于卷积神经网络CNN而言,能够自动提取特征的关键在于卷积操作。经过卷积操作提取的特征往往会有冗余,并且多次卷积会使神经网络的参数过多不便于训练,所以CNN往往会在卷积层的后面跟上一个池化层。经过多次的卷积和池化后,较低层次的特征就会逐步构成高层次的特征,最后神经网络根据提取出的高层次特征进行分类。
另外需要指出的是,为什么在心电信号分类中可以使用CNN呢。这是因为CNN具有的卷积操作具有局部连接和权值共享的特征。
- 局部连接:用于区别不同种类的图片所需的特征只是整张图片中的某些局部区域,因此在进行卷积操作时使用的卷积核(感受野)可以只是几个不同小区域,而不必使用整张图片大小的卷积核(全连接)。这样做不仅可以更好地表达不同的特征,还能起到减少参数的作用。例如下图,左边是使用全连接的神经网络,右边是使用局部连接卷积核的网络。
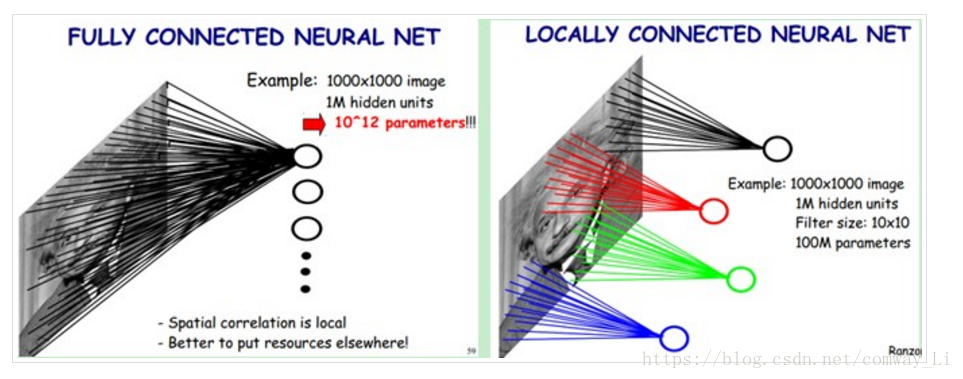
- 权值共享:对于一类图片而言,他们拥有相似的特征,但是每张图片中特征的位置可能会有偏移。比如不同的人脸照片中眼睛的位置可能会有变化,很少有两张照片眼睛的位置完全重合。对一张图片进行卷积操作时,可以有多个卷积核来提取不同的特征,但一个卷积核在进行移动的过程中其权值是保持不变的(当然不同卷积核的权值不共享)。这样既能保证特征提取不受位置的影响,还能减少参数的数量。
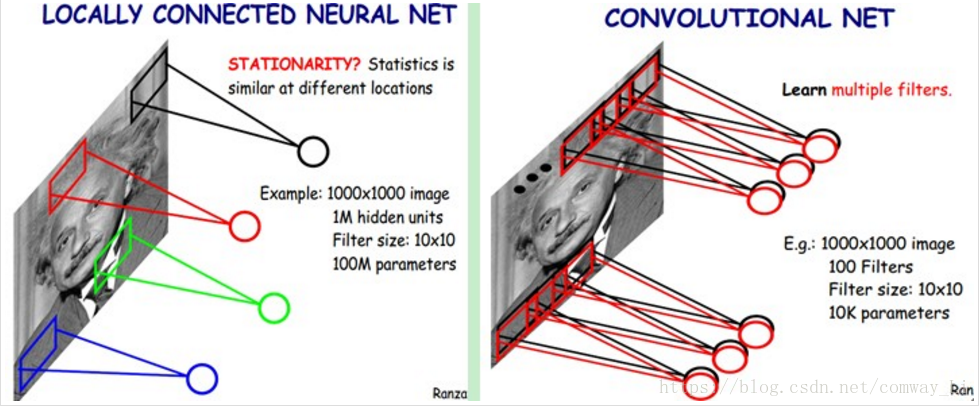
而心电信号虽然是一维的,但是其中的特征也满足局部连接和权值共享的条件,因此我们可以采用卷积神经网络对其分类。
构建深度学习的数据集
巧妇难为无米之炊,虽然我们已经有了预处理过的心电数据,但是这样的数据是无法拿来直接进行分类学习的。所以我们要先构建符合深度学习模型使用的数据集。转换的过程是首先从一条心电信号中切分出符合要求的心拍作为样本,然后将python list转为numpy array,再经过乱序和切分,最终构成可供深度学习使用的数据集。这里我们使用tf.keras提供的接口,可以直接使用numpy数组类型,而不用再转成TensorFlow的DataSet对象,对于训练过程而言也更加简单。
心拍的切分需要找到QRS波尖峰所在的位置。由于我们只训练网络模型,我们这里直接使用MIT-BIH数据集提供的人工标注,并在尖峰处向前取99个信号点、向后取200个信号点,构成一个完整的心拍。如果需要对真实测量的信号进行识别分类,还要设计心拍的检测算法,后续我也可能会继续做。
数据集根据用途分为训练集、验证集和测试集。训练集用于训练参数模型,验证集用于模型训练中准确率和误差(损失函数)的检验,测试集用于训练完成后对训练效果的最终检验。可以类比学习、测验和考试。这三者的数据结构都一致,只是包含的数据内容不同,每个训练集都包含数据和标签两部分内容。数据是预处理后切分出的若干心拍的列表,标签是每个心拍样本对应的心电类型。
首先将上一篇的预处理步骤封装成一个函数:
# 小波去噪预处理
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
然后将读取数据和标注、心拍切分封装成一个函数:
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
print("正在读取 " + number + " 号心电数据...")
record = wfdb.rdrecord('ecg_data/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
# 小波去噪
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('ecg_data/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
# 去掉前后的不稳定数据
start = 10
end = 5
i = start
j = len(annotation.symbol) - end
# 因为只选择NAVLR五种心电类型,所以要选出该条记录中所需要的那些带有特定标签的数据,舍弃其余标签的点
# X_data在R波前后截取长度为300的数据点
# Y_data将NAVLR按顺序转换为01234
while i < j:
try:
lable = ecgClassSet.index(Rclass[i])
x_train = rdata[Rlocation[i] - 99:Rlocation[i] + 201]
X_data.append(x_train)
Y_data.append(lable)
i += 1
except ValueError:
i += 1
return
需要注意的是,上面的函数并没有返回值,这是因为我们装载心拍数据和样本的列表X_data、Y_data包含了所有心电记录中符合要求的心拍,需要从函数外传入,并将得到的数据直接附加在列表末尾。这样将心电信号的编号、X_data、Y_data一同传入,就能将所需数据保存在X_data和Y_data中。
下面将所有心拍信号(因为102和104没有MLII导联故去除)读取到dataSet和lableSet两个列表中,经过上面函数后,dataSet和lableSet都是一个(92192)的一维列表。其中dataSet中的每一个元素都是一个numpy的数组,数组中是一个元素都是一个心拍的300个信号点,lableSet中的每一个元素是dataSet中一个数组对应的标签值(NAVLR对应01234)。reshape后将dataSet变为(92192,300)的列表,将lableSet变为(92192,1)的列表。然后对这两个列表进行乱序处理,但是要保证二者之间的对应关系不改变。思路是先将两个列表进行竖直方向的堆叠,变为一个列表train_ds,然后对其进行乱序处理,再拆分出乱序后的数据X和标签Y。
由于tf.keras可以将输入的数据集自动划分成训练集和测试集,所以只需要分出测试集即可。思路是先生成92192(总心拍个数)个数的随机排列列表,然后截取其中前30%个值作为索引,然后在数据集和标签集中取出下标为这些索引的值,即得到测试数据集X_test和测试标签集Y_test。
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115', '116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208', '210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230', '231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
# 转numpy数组,打乱顺序
dataSet = np.array(dataSet).reshape(-1, 300)
lableSet = np.array(lableSet).reshape(-1, 1)
train_ds = np.hstack((dataSet, lableSet))
np.random.shuffle(train_ds)
# 数据集及其标签集
X = train_ds[:, :300].reshape(-1, 300, 1)
Y = train_ds[:, 300]
# 测试集及其标签集
shuffle_index = np.random.permutation(len(X))
test_length = int(RATIO * len(shuffle_index)) # RATIO = 0.3
test_index = shuffle_index[:test_length]
train_index = shuffle_index[test_length:]
X_test, Y_test = X[test_index], Y[test_index]
X_train, Y_train = X[train_index], Y[train_index]
return X_train, Y_train, X_test, Y_test
经过上面的函数后,X,Y为总体数据集和标签集,X_test,Y_test为测试数据集和标签集,验证数据集和测试集使用tf.keras接口自动划分。这样用于深度学习的数据集就已经构建好了。
深度学习识别分类
通常来说,深度学习神经网络的训练过程编程较为复杂,但是我们这里使用tf.keras高级接口,可以很方便地进行深度学习网络模型的构建。
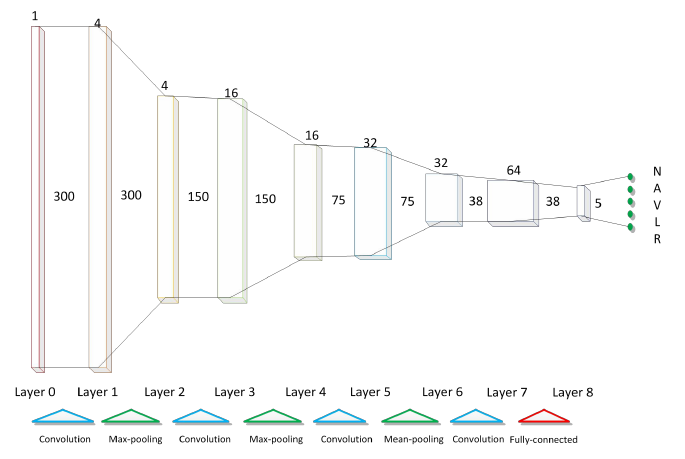
首先我们构建网络结构,具体结构如下图所示:
# 构建CNN模型
def buildModel():
newModel = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(300, 1)),
# 第一个卷积层, 4 个 21x1 卷积核
tf.keras.layers.Conv1D(filters=4, kernel_size=21, strides=1, padding='SAME', activation='relu'),
# 第一个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),
# 第二个卷积层, 16 个 23x1 卷积核
tf.keras.layers.Conv1D(filters=16, kernel_size=23, strides=1, padding='SAME', activation='relu'),
# 第二个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),
# 第三个卷积层, 32 个 25x1 卷积核
tf.keras.layers.Conv1D(filters=32, kernel_size=25, strides=1, padding='SAME', activation='relu'),
# 第三个池化层, 平均池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.AvgPool1D(pool_size=3, strides=2, padding='SAME'),
# 第四个卷积层, 64 个 27x1 卷积核
tf.keras.layers.Conv1D(filters=64, kernel_size=27, strides=1, padding='SAME', activation='relu'),
# 打平层,方便全连接层处理
tf.keras.layers.Flatten(),
# 全连接层,128 个节点
tf.keras.layers.Dense(128, activation='relu'),
# Dropout层,dropout = 0.2
tf.keras.layers.Dropout(rate=0.2),
# 全连接层,5 个节点
tf.keras.layers.Dense(5, activation='softmax')
])
return newModel
然后使用model.compile()构建;model.fit()训练30轮,批大小为128,划分验证集的比例为0.3,设置callback进行训练记录的保存;model.save()保存模型;model.predict_classes()预测。完整代码可以取本人的GitHub仓库查看,地址在文章(一)中。
def main():
# X_train,Y_train为所有的数据集和标签集
# X_test,Y_test为拆分的测试集和标签集
X_train, Y_train, X_test, Y_test = loadData()
if os.path.exists(model_path):
# 导入训练好的模型
model = tf.keras.models.load_model(filepath=model_path)
else:
# 构建CNN模型
model = buildModel()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
# 定义TensorBoard对象
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# 训练与验证
model.fit(X_train, Y_train, epochs=30,
batch_size=128,
validation_split=RATIO,
callbacks=[tensorboard_callback])
model.save(filepath=model_path)
# 预测
Y_pred = model.predict_classes(X_test)
对心电信号的深度学习识别分类至此结束,识别率可达99%左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号