使用Python+TensorFlow2构建基于卷积神经网络(CNN)的ECG心电信号识别分类(二)
心律失常数据库
目前,国际上公认的标准数据库包含四个,分别为美国麻省理工学院提供的MIT-BIH(Massachusetts Institute of Technology-Beth Israel Hospital Database, MIT-BIH)数据库、美国心脏学会提供的AHA( American heart association,AHA)数据库、欧共体CSE( Common Standards for Quantitative Electrocardiograph,CSE)数据库、欧洲ST-T数据库。
当前使用最广泛且被学术界普遍认可的据库为MIT-BIH心律失常数据库。此数据库中囊括了所有类型的心电信号并且数量丰富,为本文关于心电信号的自动分类研究提供了实验数据。下面对该数据库作详细的说明。
MT-BIH心律失常数据库拥有48条心电记录,且每个记录的时长是30分钟。这些记录来自于47名研究对象。这些研究对象包括25名男性和22名女性,其年龄介于23到89岁(其中记录201与202来自于同一个人)。信号的采样率为360赫兹,AD分辨率为11比特。对于每条记录来说,均包含两个通道的信号。第一个通道一般为MLⅡ导联(记录102和104为V5导联);第二个通道一般为V1导联(有些为V2导联或V5导联,其中记录124号为Ⅴ4导联)。为了保持导联的一致性,往往在研究中采用MLⅡ导联。本文选取MLⅡ导联心电信号进行研究分析。
数据库中的每条记录均包括三个文件,即:头文件、数据文件和注释文件。
(1)头文件头文件[.hea] 通过ASCII码存储方式记录信号的采样频率、采样频率、数据格式使用的导联信息、采样频率、研究者的性别、年龄以及疾病种类等
(2)数据文件数据文件[.dat] 通过二进制的方式存储信号,每三个字节存储两个数值(两导联数据交替存储),每个数值大小是12bit
(3)注释文件注释文件[.atr] 是由专家对信号进行人工标注,并且根据二进制格式进行数据的存储
关于MIT-BIH数据库的一些常用网站
-
MIT-BIH数据库的官方网站:https://ecg.mit.edu/
-
MIT-BIH数据库下载:https://www.physionet.org/content/mitdb/1.0.0/
-
ZIP包下载链接:Download the ZIP file (73.5 MB)
-
官网上关于该数据库的详细介绍网址:https://archive.physionet.org/physiobank/database/html/mitdbdir/intro.htm#symbols。
-
百度百科上的介绍也较为详细,需要对其格式做深入了解的读者可以参考:https://baike.baidu.com/item/MIT-BIH。
-
每条信号的基础信息可以查询https://www.physionet.org/physiobank/database/html/mitdbdir/mitdbdir.htm
-
数据库中每条心电信号中的心拍类型表:https://archive.physionet.org/physiobank/database/html/mitdbdir/tables.htm#allbeats
-
MIT-BIH心电数据可视化网站:https://www.physionet.org/lightwave/?db=mitdb/1.0.0
-
官方网站的可视化工具读取展示MIT-BIH数据:https://archive.physionet.org/cgi-bin/atm/ATM
官方网站提供的可视化工具中有许多数据库,请选择mitdb数据库。
相比之下更推荐使用倒数第二个网站进行查看。
统一术语称呼
我在阅读心电相关论文的时候,常常由于不同文章之间对同一事物的称呼不同而感到困扰。为避免在本文中出现类似情况,现将术语称呼统一如下。
- 一条心电数据(记录、信号):将编号为100,101...的数据称为一条心电数据(记录),包含了该编号中的所有导联数据。由于本文仅使用MLII导联的数据作为深度学习的训练数据,因此在本文中也特指一条心电数据中的MLII导联部分。
- 心拍:如文章(一)中图片所示,将一个完整的心电波形称为一个心拍。
- 信号点(值):连续的心电波形图其实是由一系列频率固定的不连续采样点构成的,将每个采样点称为信号点(值)。
心电数据的读取
下载数据库到本地后打开,你会发现.dat文件中全部都是乱码,这是由于MIT-BIH数据库采用了自定义的format212格式进行编码。所以在读取心电数据的时候,我们需要用到Python中的一个工具包:wfdb。
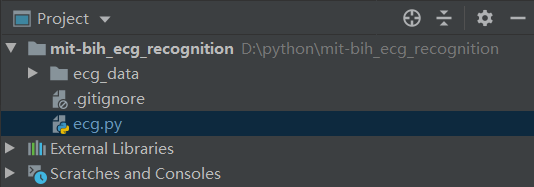
在Pycharm中新建工程,并将下载好的心电数据集按如图所示的目录结构进行放置。其中ecg_data为心电数据集的文件夹。
在该工程配置的Python环境中安装wfdb包。
pip install wfdb
关于wfdb包的详细使用请参考其官方文档,这里用代码的形式给出一些常用操作。
# 读取编号为data的一条心电数据
def read_ecg_data(data):
'''
读取心电信号文件
sampfrom: 设置读取心电信号的起始位置,sampfrom=0表示从0开始读取,默认从0开始
sampto:设置读取心电信号的结束位置,sampto = 1500表示从1500出结束,默认读到文件末尾
channel_names:设置设置读取心电信号名字,必须是列表,channel_names=['MLII']表示读取MLII导联线
channels:设置读取第几个心电信号,必须是列表,channels=[0, 3]表示读取第0和第3个信号,注意信号数不确定
'''
# 读取所有导联的信号
record = wfdb.rdrecord('../ecg_data/' + data, sampfrom=0, sampto=1500)
# 仅仅读取“MLII”导联的信号
# record = wfdb.rdrecord('../ecg_data/' + data, sampfrom=0, sampto=1500, channel_names=['MLII'])
# 仅仅读取第0个信号(MLII)
# record = wfdb.rdrecord('../ecg_data/' + data, sampfrom=0, sampto=1500, channels=[0])
# 查看record类型
print(type(record))
# 查看类中的方法和属性
print(dir(record))
# 获得心电导联线信号,本文获得是MLII和V1信号数据
print(record.p_signal)
print(np.shape(record.p_signal))
# 查看导联线信号长度,本文信号长度1500
print(record.sig_len)
# 查看文件名
print(record.record_name)
# 查看导联线条数,本文为导联线条数2
print(record.n_sig)
# 查看信号名称(列表),本文导联线名称['MLII', 'V1']
print(record.sig_name)
# 查看采样率
print(record.fs)
'''
读取注解文件
sampfrom: 设置读取心电信号的起始位置,sampfrom=0表示从0开始读取,默认从0开始
sampto:设置读取心电信号的结束位置,sampto=1500表示从1500出结束,默认读到文件末尾
'''
annotation = wfdb.rdann('../ecg_data/' + data, 'atr')
# 查看annotation类型
print(type(annotation))
# 查看类中的方法和属性
print(dir(annotation))
# 标注每一个心拍的R波的尖锋位置的信号点,与心电信号对应
print(annotation.sample)
# 标注每一个心拍的类型N,L,R等等
print(annotation.symbol)
# 被标注的数量
print(annotation.ann_len)
# 被标注的文件名
print(annotation.record_name)
# 查看心拍的类型
print(wfdb.show_ann_labels())
# 画出数据
draw_ecg(record.p_signal)
# 返回一个numpy二维数组类型的心电信号,shape=(65000,1)
return record.p_signal
在这些函数中,使用最多的是通过record=wfdb.rdrecord来获取心电数据信息,以及通过annotation=wfdb.rdann来获取心拍类型信息。需要注意的是record的类型是一个(65000,1)的二维数组,需要先将其转换成一维数组才可以对其进行预处理,关于预处理的这部分内容将在下篇文章中进行叙述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号