
20169203 《Linux内核原理与分析》 第十周作业
本周主要是对课本的学习
对于进程地址空间 先回顾一下内核地址空间
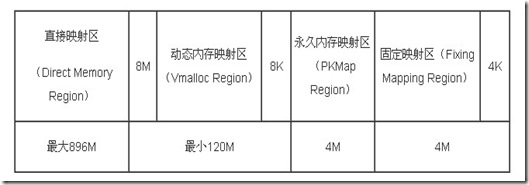
直接映射区:线性空间中从3G开始最大896M的区间,为直接内存映射区,该区域的线性地址和物理地址存在线性转换关系:线性地址=3G+物理地址。
动态内存映射区:该区域由内核函数vmalloc来分配,特点是:线性空间连续,但是对应的物理空间不一定连续。vmalloc分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
永久内存映射区:该区域可访问高端内存。访问方法是使用alloc_page(_GFP_HIGHMEM)分配高端内存页或者使用kmap函数将分配到的高端内存映射到该区域。
固定映射区:该区域和4G的顶端只有4k的隔离带,其每个地址项都服务于特定的用途,如ACPI_BASE等。
对于进程地址空间
linux采用虚拟内存管理技术,每一个进程都有一个3G大小的独立的进程地址空间,这个地址空间就是用户空间。每个进程的用户空间都是完全独立、互不相干的。进程访问内核空间的方式:系统调用和中断。
创建进程等进程相关操作都需要分配内存给进程。这时进程申请和获得的不是物理地址,仅仅是虚拟地址。
实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请页机制”产生“缺页”异常,从而进入分配实际页框的程序。该异常是虚拟内存机制赖以存在的基本保证,它会告诉内核去为进程分配物理页,并建立对应的页表,这之后虚拟地址才实实在在的映射到了物理地址上。
内核使用内存描述符结构表示进程的地址空间,由结构体mm_struct结构体表示,定义在linux/sched.h中,
mm_users记录了正在使用该地址的进程数目(比如有两个进程在使用,那就为2)。mm_count是该结构的主引用计数,只要mm_users不为0,它就为1。但其为0时,后者就为0。这时也就说明再也没有指向该mm_struct结构体的引用了,这时该结构体会被销毁。内核之所以同时使用这两个计数器是为了区别主使用计数器和使用该地址空间的进程的数目。mmap和mm_rb描述的都是同一个对象:该地址空间中的全部内存区域。不同只是前者以链表,后者以红黑树的形式组织。所有的mm_struct结构体都通过自身的mmlist域连接在一个双向链表中,该链表的首元素是init_mm内存描述符,它代表init进程的地址空间。另外需要注意,操作该链表的时候需要使用mmlist_lock锁来防止并发访问,该锁定义在文件kernel/fork.c中。内存描述符的总数在mmlist_nr全局变量中,该变量也定义在文件fork.c中。
对于页高速缓存和页回写,页高速缓存是Linux内核实现的一种主要磁盘缓存,它主要用来减少对磁盘的IO操作,具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问写缓存有三种策略:不缓存,高速缓存不缓存任何写操作,跳过缓存写到磁盘上,同时使缓存中数据失效。写透缓存,自动更新内存缓存,同时也更新磁盘文件。“回写”,写操作直接写到缓存中,后端存储不会立刻直接更新,将页高速缓存中被写入的页面标记成“脏”,由回写进程将脏页写回磁盘。
linux的缓存回收是通过选择干净的页进行简单的替换,如果缓存中没有足够的干净页面,内核将强制的进行回写操作,以便腾出更多的干净页。而最难的是决定什么页应该被回收,回收算法有两种,如下:
最近最少使用算法(LRU),LRU回收策略跟踪每个页面的访问踪迹,以便能回收最老时间戳的页面,该策略的良好效果源自缓存的数据越久未被访问,则以后被访问的可能行越不大,但是对于很多很多文件被访问一次后不再访问,LRU则会效率底下。
双链策略,linux实际使用的是一个经过改进的LRU,称为双链策略,它维护两个链表:活跃链表和非活跃链表。活跃链表中的不会被换出,而非活跃链表中的会被换出。两个链表都被伪LRU规则维护:页面从尾部加入,从头部移除。并且两个链表需要维护平衡,如果活跃链表过多,则会把活跃链表表头的页面加入非活跃链表的尾部,以便能被回收。双链表解决的传统LRU算法中对仅一次的访问困境。这种链表也称为LRU/2,更多的是LRU/n,表示有n个链表。

