20169203 《Linux内核原理与分析》 第九周作业
对于本周的实验部分Linux内核如何装载和启动一个可执行程序,先理解一个可执行程序是如何创建的
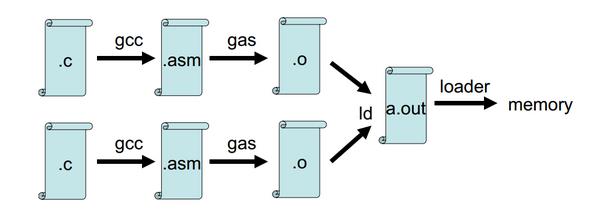
C代码(.c) - 经过编译器预处理,编译成汇编代码(.asm) - 汇编器,生成目标代码(.o) - 链接器,链接成可执行文件(.out) - OS将可执行文件加载到内存里执行。
- 预处理
gcc -E -o hello.cpp hello.c -m32 预处理(文本文件)
预处理负责把include的文件包含进来及宏替换等工作
-
编译
gcc -x cpp-output -S -o hello.s hello.cpp -m32 编译成汇编代码(文本文件) -
汇编
gcc -x assembler -c hello.s -o hello.o -m32 汇编成目标代码(ELF格式,二进制文件,有一些机器指令,只是还不能运行) -
链接
gcc -o hello hello.o -m32 链接成可执行文件(ELF格式,二进制文件)
在hello可执行文件里面使用了共享库,会调用printf,libc库里的函数
gcc -o hello.static hello.o -m32 -static 静态链接
把执行所需要依赖的东西都放在程序内部
在Linux终端中测试可得
lxy@ ~/Code/kernel/lab7$ gcc -E -o test.cpp test.c -m32 //生成预处理中间文件,宏定义替换
lxy@ ~/Code/kernel/lab7$ gcc -x cpp-output -S -o test.s test.cpp -m32 //编译过程,生成汇编代码
lxy@ ~/Code/kernel/lab7$ gcc -x assembler -c test.s -o test.o -m32 //汇编器,将汇编文件生成目标文件
lxy@ ~/Code/kernel/lab7$ gcc -o test test.o -m32 //链接成可执行文件,使用共享库
lxy@ ~/Code/kernel/lab7$ gcc -o test.static test.o -m32 -static //执行静态链接 (libC)
lxy@ ~/Code/kernel/lab7$ ls -lh
total 784K
-rwxrwxr-x 1 lxy lxy 7.3K 11月 17 22:45 test
-rw-rw-r-- 1 lxy lxy 231 11月 17 15:26 test.c
-rw-rw-r-- 1 lxy lxy 38K 11月 17 22:43 test.cpp
-rw-rw-r-- 1 lxy lxy 1.3K 11月 17 22:45 test.o
-rw-rw-r-- 1 lxy lxy 1.1K 11月 17 22:44 test.s
-rwxrwxr-x 1 lxy lxy 723K 11月 17 22:46 test.static
下面使用gdb跟踪分析一个execve系统调用内核处理函数sys_execve
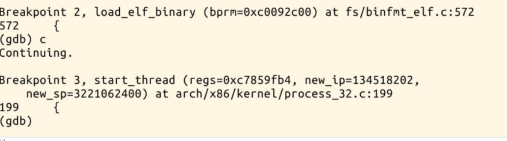

通过gdb调试分析可以知道对于execve系统调用的执行流程是sys_execve -> do_execve -> do_execve_common -> exec_binprm -> search_binary_handler -> load_binary ->load_elf_binary (也执行了elf_format)-> start_thread。当系统调用execve时,系统陷入内核,这时会创建一个新的用户态堆栈,把命令行参数的内容和环境变量的内容通过指针的方式传递给系统调用内核处理函数的,然后内核处理函数在创建可执行程序新的用户态堆栈的时候,会把这些拷贝到用户态堆栈初始化新的可执行程序的执行上下文环境。这时就加载了新的可执行程序。系统调用exceve返回用户态的时候,就变成了被exceve加载的可执行程序。
首先sys_execve调用了do_execve,该函数将参数和环境变量的数据结构进行修改后调用了do_execve_common。
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execve_common(filename, argv, envp);
}
继续看,do_execve_common函数可以抽象为下面的结构:
int do_execve_common()
{
file = do_open_exec(filename); //打开要加载的可执行文件
...
各种初始化bprm
...
exec_binprm(bprm); //加载程序
}
其中加载程序的exec_binprm函数中,调用了关键的search_binary_handler(bprm),该函数遍历链表来尝试加载目标文件,找到了则执行load_binary.
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
...
目标文件的格式是ELF,所以相应的load_binary为load_elf_binary,该函数可以抽象如下:
load_elf_binary()
{
...
解析ELF文件
...
elf_map(bprm->file, load_bias + vaddr,...) //把目标文件映射到地址空间中
...
if (elf_interpreter) {把elf_entry设置为动态链接器ld的起点}
else {目标文件的入口赋值给elf_entry}
...
start_thread(..., elf_entry, ...);
}
该函数的核心工作一是解析ELF文件,二是把目标文件映射到进程空间中,三是调用start_thread。start_thread实际上在修改了内核堆栈后调用iret返回用户态,把我们返回用户态的位置从int 0x80的下一条指令的位置变成新加载的可执行文件的entry位置(new_ip)。
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
set_user_gs(regs, 0);
regs->fs = 0;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
regs->ip = new_ip;
regs->sp = new_sp;
regs->flags = X86_EFLAGS_IF;
/*
* force it to the iret return path by making it look as if there was
* some work pending.
*/
set_thread_flag(TIF_NOTIFY_RESUME);
}
对于理解进程调度时机跟踪分析进程调度与进程切换的过程的实验
这次实验要理解进程调度时机跟踪分析进程调度与进程切换的过程。
Linux任务切换是通过switch_to实现的。switch_to本身是一个宏,通过利用长跳指令,当长跳指令的操作数是TSS描述符的时候,就会引起CPU的任务的切换,此时,cpu将所有寄存器的状态保存到当前任务寄存器TR所指向的TSS段(当前任务的任务状态段)中,然后利用长跳指令的操作数(TSS描述符)找到新任务的TSS段,然后将其中的内容填写到各个寄存器中,最后,将新任务的TSS选择符更新到TR中。这样系统就正式开始运行新切换的任务了。
在MenOS中对schedule、context_switch、switch_to设置断点,
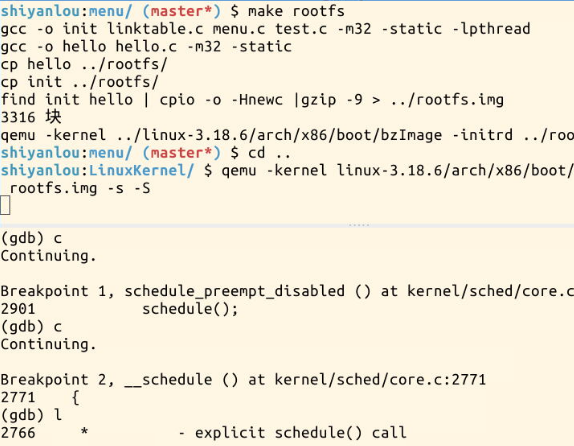

进程切换调用的是schedule()函数,该函数调用了__schedule().
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
__schedule();
}
static void __sched __schedule(void)
{
...
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
...
context_switch(rq, prev, next); /* unlocks the rq */
...
} else {
...
raw_spin_unlock_irq(&rq->lock);
...
}
...
post_schedule(rq);
...
}
对于其中的context_switch()
context_switch {
...
mm = next->mm;
if(!mm) {
next->active_mm = oldmm;
...
}
else
switch_mm(oldmm, mm, next);
...
switch_to(prev, next, prev);
...
}
该函数做了两件事情,第一是切换页表switch_mm,当next进程mm为空(next是内核线程)时,则使用当前进程的页表,否则切换成新进程的页表(用户态地址空间);第二是切换进程switch_to
#define switch_to(prev, next, last) \
do {
unsigned long ebx, ecx, edx, esi, edi; \
asm volatile("pushfl\n\t" /*保存当前进程的flag */ \
"pushl %%ebp\n\t" /* 保存当前进程EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* 保存当前的内核栈顶 */ \
"movl %[next_sp],%%esp\n\t" /* 恢复下一个进程的内核栈顶 */ \
//内核堆栈角度,这里已经切换到next的内核堆栈了
"movl $1f,%[prev_ip]\n\t" /*将标号1放入当前进程的EIP*/ \
"pushl %[next_ip]\n\t" /* 恢复下一个进程的EIP,next内核堆栈的栈顶 */ \ \
"jmp __switch_to\n" /*寄存器传递参数,jmp不压栈EIP*/ \
//EIP角度,这里是新的进程的执行入口
"1:\t" /*switch_to 返回到这里*/ \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), /*字符串标号*/ \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
对于其中的switch_to函数其执行步骤大致为
(1)复制两个变量到寄存器[prev]"a" (prev)[next]"d" (next)
(2)保存进程A的ebp和eflags
(3)保存当前esp到A进程内核描述符中
(4)从next(进程B)的描述符中取出之前从B切换出去时保存的esp_B
(5)把标号为1的指令地址保存到A进程描述符的ip域
(6)将返回地址保存到堆栈,然后调用switch_to()函数,switch_to()函数完成硬件上下文切换
(7)从switch_to()返回后继续从1:标号后面开始执行,修改ebp到B的内核堆栈,恢复B的eflags
(8)将eax写入last,以在B的堆栈中保存正确的prev信息
对于课本的学习主要是对于虚拟文件系统的了解
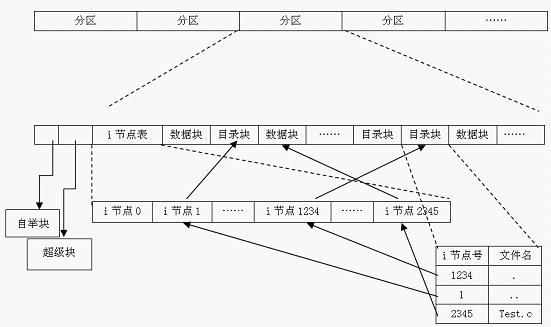
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。为了描述 这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等 也以文件被对待。总之,“一切皆文件”。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节 点数等,存放于磁盘的特定扇区中。