
VIT transformer 论文讲解
首先将图片分为16*16的小格
如果直接将图片作为transformer的输入,会有一个问题,序列长度太大,vit将很多图片打成了16*16的patch ,将一个patch作为一个元素
图片224*224
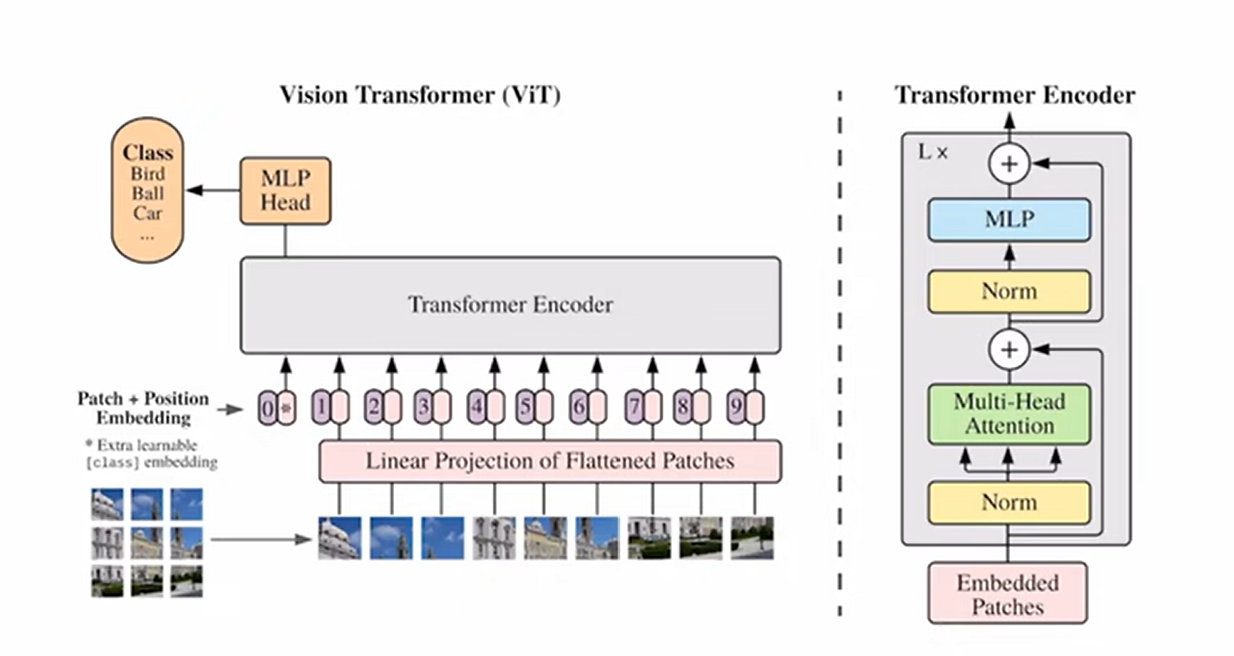
vit 的全局图
vit = position embedding + class embedding + patch + transformer
也可以用global average pooling 获取全局图片的特征然后分类。但本文用class 输出分类
vit encoder 公式:
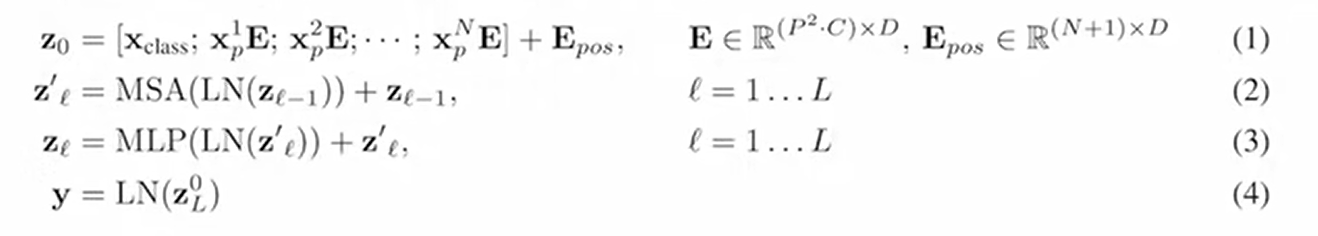
MLP:输入层,输入几维向量就有几个神经元
隐藏层,函数f 可以是常用的sigmoid函数或者tanh函数:具体实现方法,查找表法或cordic算法
输出层,可以将隐藏层到输出层看成一个多分类的逻辑回归即softmax函数
所以整个的单隐藏层MLP 输出=G(b2+w2(s(b1+X·W1)))
输入和输出都固定,唯一能设置隐藏层有多大,好像是2048
加激活函数目的:防止输出线性化,若线性化后就成了单层感知机
一般为sigmoid函数(0-1) 也有tanh函数(-1,1)
若是多隐藏层一般设置先多后少的维度,单隐藏层一般先多
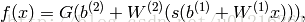
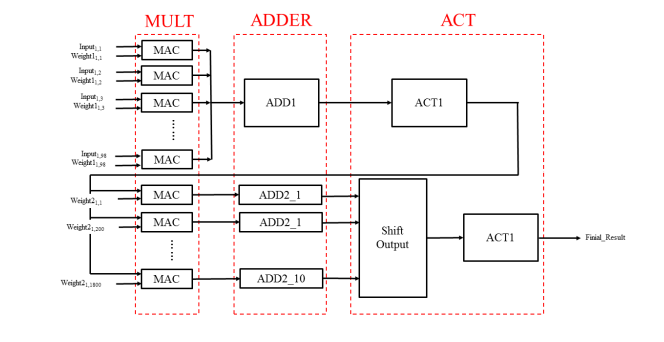
上面一部分是输入层-隐藏层模块,下面是隐藏层-输出层模块。
???
adder_ready,
done, lut_layer_done, Y_sample,
output wire [3:0] addr_img_I,
output wire [9:0] addr_byte_I_byte_W1;
output wire [7:0] addr_img_W1_byte_W2;
output wire done;
output wire [15:0] lut_output1,lut_output2;
以上是顶层模块的外部信号,
接下来是顶层模块的内部信号
注意力层对应的输出512维度向量,w1投影成2048,再残差连接w2投影成512,只有一个MLP,每个MLP的权重是一样的,作用于不同的向量
VITMLP:一个像素点就对应一个神经元
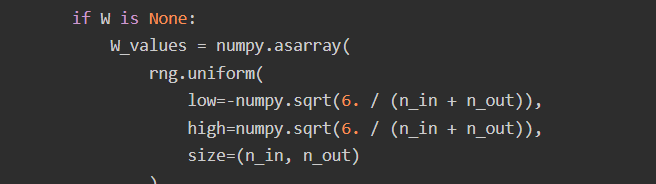 w矩阵n_in行,n_out列
w矩阵n_in行,n_out列
利用梯度下降确定参数
1.将整体图片分割
2.将每个图片先拉成一维(拉到patch_dim维度,patch_dim = channel * patch_height *patch_width),其次通过linear层(例如将256映射到758上)embedding size = 758
3.①先生成一个cls符号的token embedding ②生成所有序列的位置编码 ③token embedding + 位置编码 为什么位置编码:1)为了确保输出固定
2)位置编码为什么可以和patch embedding 相加 记住就行
4.encoder
5.将cls拿出进行多分类化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律