
transformer 论文讲解
序列转录模型:给一个序列生成另外一个序列
本文仅仅使用了注意力集中机制没有用循环或者卷积
RNN缺点:1)无法并行 2)起初的隐藏信息可能会被丢掉,内存需要很大
起初attention用于将encoder的信息更好的传给decoder
encoder是想输入转变为一系列的向量,将x1-xn变为z1-zn Z是词所对应的向量
自回归:当前状态的输入需要依赖过去状态的输出
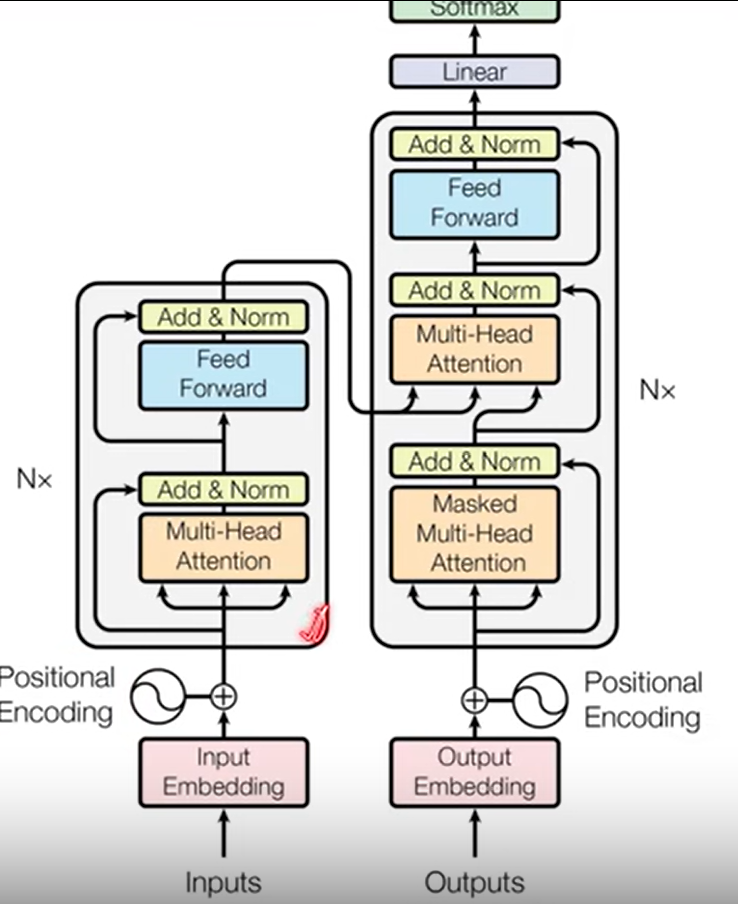
encoder: input embedding 嵌入层:输入变成一个个向量
编码层由6层构成,其中每一层分两个子层,一个时多头注意力层,另一个是MLP(多层感知机包含输入、隐含、输出层)
残差连接(一是解决梯度消失的问题,二是解决权重矩阵的退化问题):H(x)=F(x)+x;
layernorm 和 batchnorm的区别 layernorm每次取出样本,然后在该样本中取均值和方差。
decoder: 做的自回归,预测时,不能看到后面时刻的输出,但注意力机制可以看到后面时刻的输入,所以采用带掩码的注意力机制,保证训练和预测时是一样的
注意力函数(他是将q,kv对映射成输出的一个函数):q,k,v q改变时最后的v会随之而改变 输出output是v的加权和,维度是一样的,而权重是由v所对应的k和q的相似度(compatible function)得来的
本文使用的注意力机制是q和k 分别长为Dk,v长为Dv,q和k做内积,值越大相似度越高,再除以√Dk再用softmax来得到权重
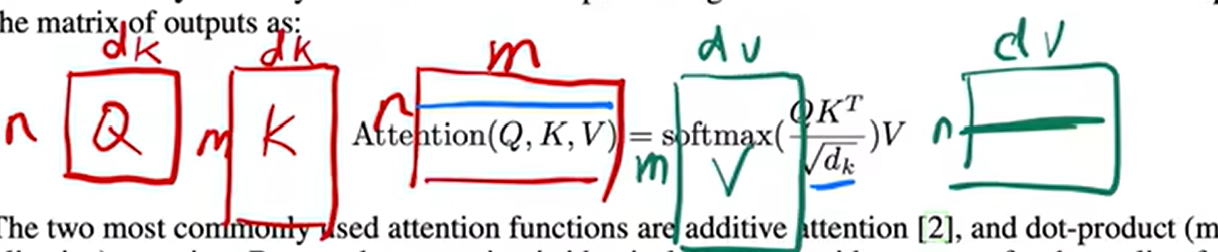
具体的实现框图
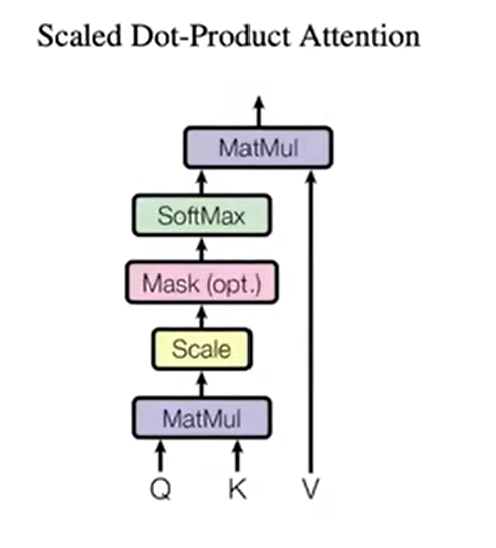 mask:t时间的qt,kt以后的值都转换成非常大的负指数,softmax后就会接近于0
mask:t时间的qt,kt以后的值都转换成非常大的负指数,softmax后就会接近于0
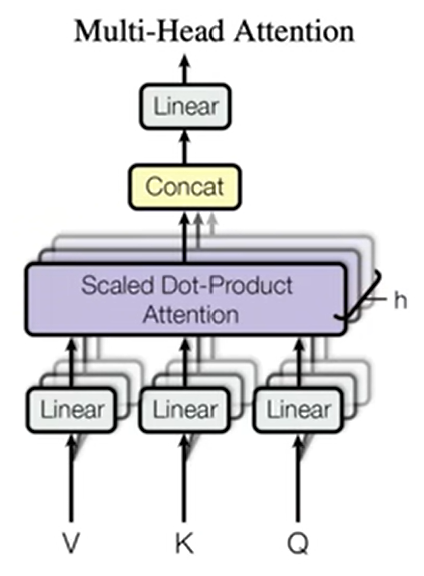 线性层目的低纬化,3D变平面,最后再合在一起
线性层目的低纬化,3D变平面,最后再合在一起
multihead 公式没懂
编码器的输出为key and value 解码器的第二个输入为attention
feed forward:
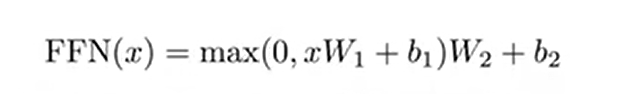
单隐藏层MLP,用pytorch实现时,两个线性层放在一起,不需要改参数(输入3D,输出最后一个维度计算)
RNN 每一层的输入为上一层的输出去传递序列信息,而transformer用attention抓取全局的序列信息最后用MLP识别,但其没有加入时序信息,做法是将时序信息加到输入里,比如第i个词标志数字,具体做法如下
信息里面加时序信息 position embedding 返回一个512带有位置的向量再和信息相加一起输入到多头注意
embedding:任何一个层都学成一个512的向量,编码解码softmax前都要有embedding
d模型宽度,多长的向量,dff隐藏层输出的大小
