MYSQL
概述、安装使用机器简单操作
Mysql数据库
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- Mysql是开源的,所以不需要支付额外的费用。
- Mysql支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL使用标准的SQL数据语言形式。
- Mysql可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- Mysql是可以定制的,采用了GPL协议,可以修改源码来开发自己的Mysql系统。
Mysql安装
想要使用MySQL来存储并操作数据,则需要做几件事情:
a. 安装MySQL服务端
b. 安装MySQL客户端
c. 【客户端】连接【服务端】
d. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
下载 http://dev.mysql.com/downloads/mysql/ 安装 windows: 点点点 Linux: yum install mysql-server Mac: 点点点
windows
1、下载
MySQL Community Server 5.7.17 http://dev.mysql.com/downloads/mysql/
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:D:\Mysql\mysql-5.7.17-winx64
3、初始化
在D:\Mysql\mysql-5.7.17-winx64目录下新建data目录
MySQL解压后的 bin 目录下有一大堆的可执行文件,执行如下命令初始化数据:
cd c:\mysql-5.7.16-winx64\bin mysqld --initialize-insecure
4、启动Mysql服务
因为重复的进入可执行文件目录比较繁琐,如想日后操作简便,可以做如下操作。
a.添加环境变量
将MySQL可执行文件添加到环境变量中,从而执行执行命令
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】 如: C:\Program Files (x86)\Parallels\Parallels Tools\Applications;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;C:\Python27;C:\Python35;D:\Mysql\mysql-5.7.17-winx64\bin
这样,再启动服务的时候,仅仅需要
# 启动MySQL服务,在终端输入
mysqld
# 连接MySQL服务,在终端输入:
mysql -u root -p
b. 将Mysql服务制作成windows服务
上一步虽然解决了一些问题,但不够彻底,因为在执行【mysqld】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题
# 制作MySQL的Windows服务,在终端执行此命令: "D:\Mysql\mysql-5.7.17-winx64\bin\mysqld" --install # 移除MySQL的Windows服务,在终端执行此命令: "D:\Mysql\mysql-5.7.17-winx64\bin\mysqld" --remove
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令
# 启动MySQL服务
net start mysql
# 关闭MySQL服务
net stop mysql
5、启动MySQL客户端并连接MySQL服务
由于初始化时使用的【mysqld --initialize-insecure】命令,其默认未给root账户设置密码
# 终端命令提示符 # 连接MySQL服务器 mysql -u root -p # 提示请输入密码,直接回车
然后出现下图
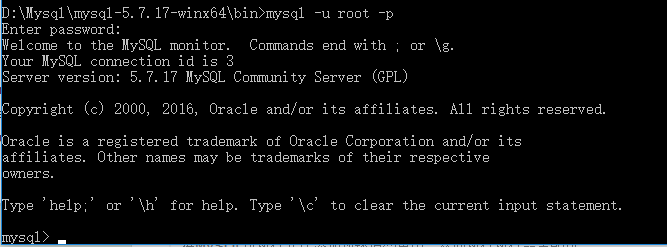
此刻,MySQL服务端已经安装成功并且客户端已经可以连接上.
MySQL数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
下面的表显示了需要的每个整数类型的存储和范围

日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
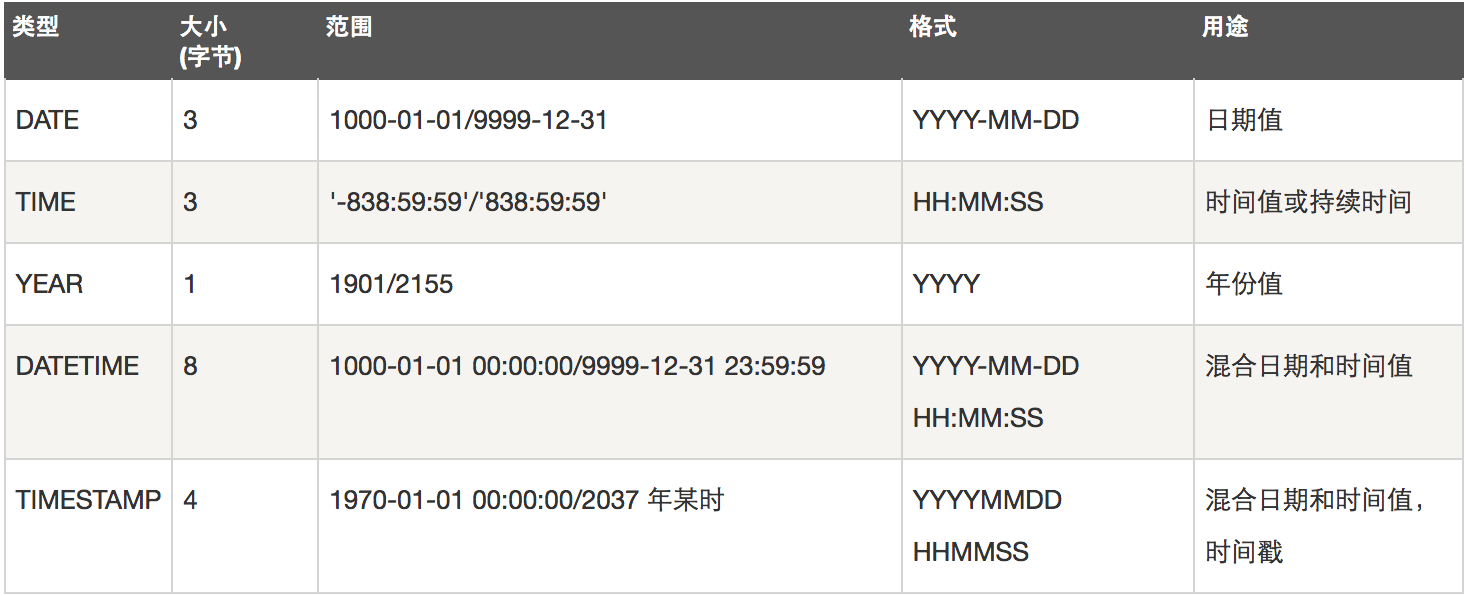
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
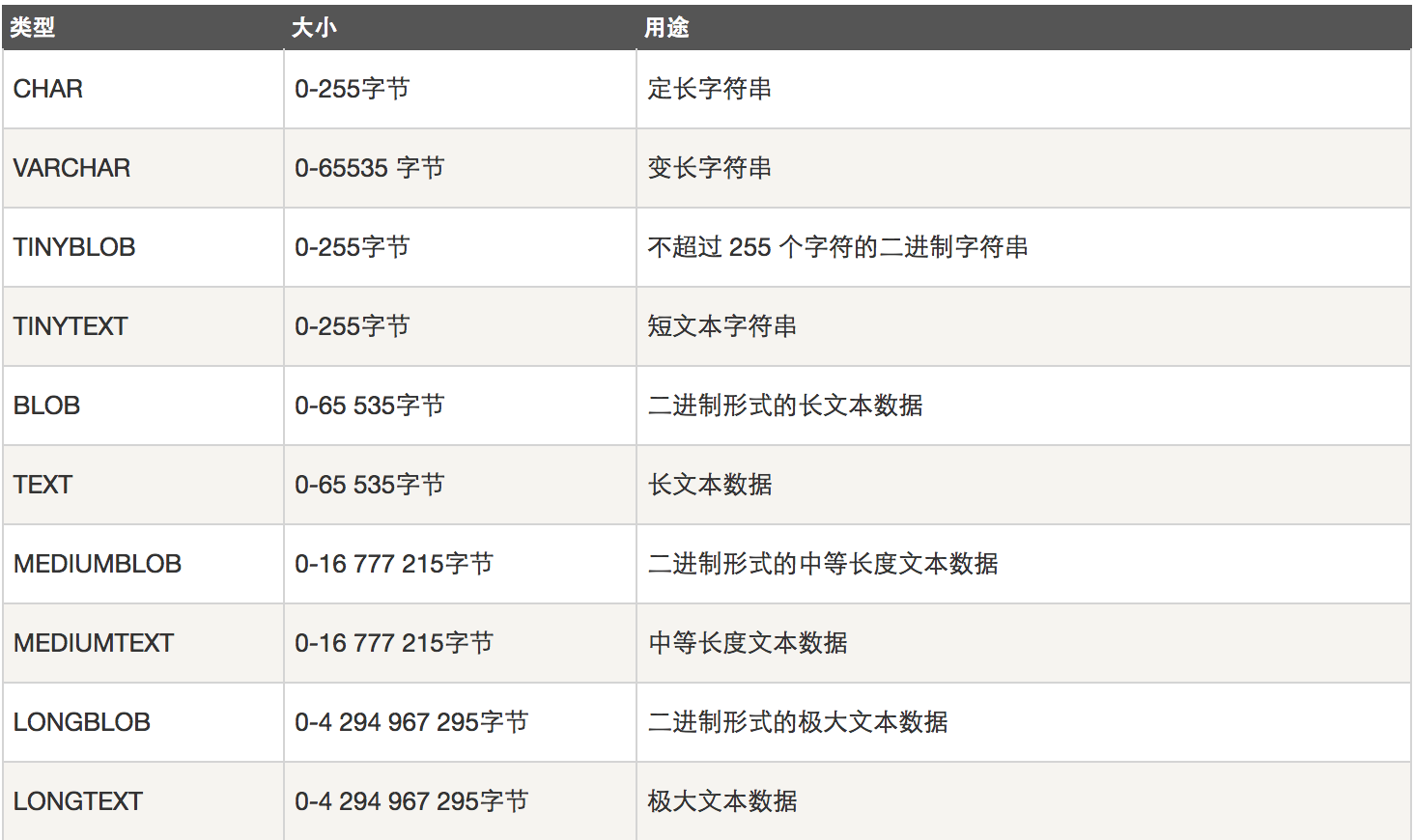
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
Mysql密码破解
如果我们遗忘了mysql的登陆密码,也是容易去解决的。
通过查找mysql的配置文件 my.cnf (注意其是否关联其它文件,再去修改)
# 编辑文件 /etc/my.cnf下, 如下填加 [mysqld] skip-grant-tables # 重启Mysql,使得参数生效 service mysqld restart # 登陆 mysql -u root 回车即登陆 # 修改密码 a. 通过sql语句将密码改好之后,再将配置文件中 skip-grant-tables去掉 b. 再次重启数据库
数据库及表操作、多表查询、索引、事务、py链接MySQL
- 数据库操作
- 数据表操作
- 外键约束
- 多表查询
- 索引
- 事务
- python连接Mysql
数据库操作
此操作针对windows环境下
该操作再Mysql服务器启动以及客户端连接之后
对数据库操作之前,引申一些较为听的懂的白话
概念 数据库(文件夹) 数据库表(文件) 数据行(文件中的一行数据) 一个数据库就是一个文件夹
1、显示数据库
show databases; -- 后面记得跟英文字符的分号
show create database 数据库名称; -- 查看数据库创建信息
默认数据库:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据
2、创建数据库


show databases; --查看当前Mysql都有那些数据,根目录都有那些文件夹 create database 数据库名; --创建文件夹 use 数据库名; --使用选中数据库,进入目录 show tables; --查看当前数据库下都有那些表 create table 表名(nidint, namevarchar(20), pwdvarchar(64)); --创建数据库表 /*阐释 相当于创建一个tb1的表 有nid,name,pwd三列 nid int 为int类型 varchar(20) 为字符类型最多20*/ select * from 表名; --查看表中的所有数据 insert into 表名(nid, name, pwd) values(1, 'alex', '123'); --插入数据
3、修改数据库
alter databases 数据库名称 character set utf8; -- 修改数据库编码格式
4、删除数据库
drop database [if exists] db_name;
5、用户管理
显示当前使用的数据库中所有表:show tables;
PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
show databases; use mysql; show tables; 可以看到mysql下有多少张表 user表是用户表 desc user; 查看user表有多少列 select host,user from user; 可以看到用户
创建用户 create user '用户名'@'IP地址' identified by '密码'; 删除用户 drop user '用户名'@'IP地址'; 修改用户 rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';; 修改密码 set password for '用户名'@'IP地址' = Password('新密码')
数据表操作
1、创建数据表
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGINE=InnoDB DEFAULT CHARSET=utf8 -- ENGINE=InnoDB 表示引擎 后为默认编码格式为utf
-- 是否可空,null表示空,非字符串 not null -- 不可空 null -- 可空
-- 默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1(
nid int not null defalut 2,
num int not null
)
-- 主键,一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
create table tb1(
nid int not null auto_increment primary key,
num int null
)
或
create table tb1(
nid int not null,
num int not null,
primary key(nid,num)
)
-- 自增,如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列)
create table tb1(
nid int not null auto_increment primary key,
num int null
)
或
create table tb1(
nid int not null auto_increment,
num int null,
index(nid)
)
-- 对于自增列,必须是索引(含主键)。
-- 对于自增可以设置步长和起始值
show session variables like 'auto_inc%';
set session auto_increment_increment=2;
set session auto_increment_offset=10;
shwo global variables like 'auto_inc%';
set global auto_increment_increment=2;
set global auto_increment_offset=10;
2、查看数据表
show tables; -- 显示当前数据库所有表 desc 表名; -- 查看表结构 show create table 表名 -- 查看完整表创建信息
3、修改表结构
--增加列(字段) --添加多字段用逗号隔开进行 alter table 表名 add 列名 类型 [约束条件]; --删除列(字段) --多字段删除也用逗号隔开,无需加数据类型 alter table 表明 drop 列名1,列名2...; --修改列(字段) --列类型修改 alter table 表名 modify 列名 类型 [约束条件][first|after 列名]; --列名称修改 alter table 表名 change 原列名 新列名 类型 [约束条件][first|after 列名];
4、修改表名
rename table 原表名 to 新表名;
5、删除表
drop table 表名;
表记录操作
1、增
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 set 列名=值,列名=值...; -- insert into 表 (列名,列名...) select (列名,列名...) from 表
2、删
delete from 表名 where 字段键值对 ; delete from 表名 ; truncate table 表名;
-- 如不进行筛选,则删除表的所有记录(表依旧存在) -- delete 逐条删除,留下空表 -- truncate 先删除表,而后copy一个与之前相同的空表
3、改
update 表名 set name = "aaa" where id =9;
-- 多条可以用逗号隔开进行修改 -- 进行筛选则单独对筛选的那部分进行修改 -- 不进行筛选,则修改所有符合的部分
4 查
select * from 表 -- 查看表中的所有数据 select * from 表 where id > 1 -- 筛选id大于1的所有数据 select nid,name,gender as gg from 表 where id > 1 -- 查看id大于1的nid,name,gender的三个
字段 as ... 表示进行别名设置
A、条件 select * from 表 where id > 1 and name != 'alex' and num = 12; -- 筛选id>1且name不为alex且num为12的数据 select * from 表 where id between 5 and 16; -- 筛选id值在5到16范围内的数据 select * from 表 where id in (11,22,33) -- 筛选id值为11或22或33的数据 select * from 表 where id not in (11,22,33) -- 反之 select * from 表 where id in (select nid from 表) B、SQL通配符 select * from 表 where name like '%le%' -- 选取name包含有le的所有数据 select * from 表 where name like 'ale_' -- ale开头的所有(一个字符) select * from 表 where name regexp "^[awv]"; -- 选取name以'a'、'w'或'v'开始的所有数据 select * from tb where name regexp "^[a-c]"; -- 选取name以a到c开头范围内的所有的数据 select * from tb where name regexp "^[^a-c]";-- 选取name非以a到c开头的所有数据 C、限制 select * from tb limit 2; -- 前2行 select * from tb limit 2,2; -- 从第2行开始的后2行 select * from tb limit 2 offset 2; -- 从第2行开始的后2行 D、排序 select * from tb order by name asc; -- 按照name升序排列 select * from tb order by name desc; -- 按照name降序排列 E、分组 select * from tb group by name; -- 根据名字分组 select * from tb group by 2; -- 根据第2个字段分组 select * from employee_tbl group by name having id>4; -- 根据名字分组且id大于4的数据 -- where作用于分组前,having作用于分组后且可以用聚合函数,在where中就不行 F、聚合函数(经常作用于分组查询配合使用) SUM(字段) -- 求和 COUNT(字段) -- 次数统计 AVG(字段) -- 平均值 MAX(字段) -- 最大 MIN(字段) -- 最小
WHERE子句中的条件
= -- 等于 <> -- 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != > -- 大于 < -- 小于 >= -- 大于等于 <= -- 小于等于 BETWEEN-- 在某个范围内 LIKE -- 搜索某种模式 IN -- 指定针对某个列的多个可能值 WHERE子句中的条件
以上都只是单表性的查询,例如模拟在实际生活中,会有一张员工表,而员工会有其归属的部门,那么相应的也会有一张部门表.在其中相应的俩者之间会有一种相应的关联,那么这里引申了外键及多表查询
外键约束
外键可以理解为一种约束,它有以下限制(FOREIGN KEY为创建外键的关键词)
注意:作为外键一定要和关联主键的数据类型保持一致
- FOREIGN KEY 约束用于预防破坏表之间连接的行为。
- FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
创建外键、
-- 1、建立从表的时候就和主表建立外键
CREATE TABLE TABLE_NAME(
'字段' 类型,
'字段' 类型,
... ...
FOREIGN KEY (从表字段) REFERENCES 主表(字段)
);
-- 2、建表完成之后,也可以通过sql语句和主表建立联系
ALTER TABLE 从表 ADD CONSTRAINT 外键名称(形如:FK_从表_主表) FOREIGN KEY (从表字段) REFERENCES 主表(字段);
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称
-- 创建表 班级表和学生表 CREATE TABLE class( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), priece INT ); DESC class; INSERT INTO class(name,priece) VALUES ("python",15800), ("linux",14800), ("go",16800), ("java",18800); SELECT * FROM class; CREATE TABLE student (sid INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), age INT, sex TINYINT(1), class_id INT, FOREIGN KEY (class_id) REFERENCES class(id)); SHOW CREATE TABLE student; DESC student; INSERT INTO student(name,age,sex,class_id) VALUES ("tony1",18,0,1), ("tony2",19,1,1), ("tony3",17,1,2), ("tony4",19,1,3), ("tony5",19,0,2), ("tony6",20,1,4); SELECT * FROM student2; CREATE TABLE student2(sid INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), age INT, sex TINYINT(1), class_id INT); -- 建表之后添加外键 ALTER TABLE student2 ADD CONSTRAINT a1 FOREIGN KEY (class_id) REFERENCES class(id); SHOW CREATE TABLE student2; -- 这样绑定的class_id超出class的id则不让插入 INSERT INTO student2(name, age, sex, class_id) VALUES ("tony8",17,0,1); -- 删除外键 ALTER TABLE student2 DROP FOREIGN KEY a1; -- 删除外键之后,则可以插入超出class id范围的数据 INSERT INTO student2(name, age, sex, class_id) VALUES ("tony9",17,0,5); DEMO
多表查询
join 用于把来自两个或多个表的行结合起来。
不同的 SQL JOIN 类型:
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行(mysql不支持全外连接,而是使用union与union all)
无对应关系则不显示
select A.num, A.name, B.name
from A,B
Where A.nid = B.nid
无对应关系则不显示
select A.num, A.name, B.name
from A inner join B
on A.nid = B.nid
A表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A left join B
on A.nid = B.nid
B表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A right join B
on A.nid = B.nid
索引
1、概述
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
2、分类
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 主键索引:加速查询 + 列值唯一 + 表中只有一个(不可以有null)
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
索引合并:使用多个单列索引组合查询搜索
覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
a、普通索引
创建表直接指定索引 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX ix_name (username(length)) );
# 表外创建索引
CREATE INDEX indexName ON mytable(username(length));
# 修改表结构
ALTER mytable ADD INDEX indexName ON (username(length));
# 创建唯一索引 CREATE UNIQUE INDEX indexName ON mytable(username(length))
# 删除索引 DROP UNIQUE INDEX 索引名 ON 表名
c、主键索引
# 创建主键索引
CREATE TABLE t1(
id INT PRIMARY KEY,
name VARCHAR(16)
);
OR
CREATE TABLE t1(
id INT NOT NULL,
name VARCHAR(16),
PRIMARY KEY(id)
);
# 添加主键 ALTER TABLE 表名 DROP PRIMARY KEY;
# 删除主键 ALTER TABLE 表名 DROP PRIMARY KEY; ALTER TABLE 表名 MODIFY 列名 类型,DROP PRIMARY KEY;
d、组合索引
组合索引是多个列组合成一个索引来查询
应用场景:频繁的同时使用多列来进行查询,如:where name = 'Tony' and age = 18。

# 创建表
CREATE TABLE demo(
nid INT NOT NULL auto_increment PRIMARY KEY ,
name VARCHAR(32) NOT NULL,
age INT NOT NULL
)
# 创建组合索引
CREATE INDEX ix_name_age ON demo(name,age);
如上创建组合索引之后,查询一定要注意:
- name and email -- >使用索引,name一定要放前面
- name -- >使用索引
- email -- >不使用索引
注意:同时搜索多个条件时,组合索引的性能效率好过于多个单一索引合并。
e、全文索引
# 创建全文索引
CREATE TABLE emp3 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
FULLTEXT INDEX index_resume (resume)
);
3、相关
# 显示索引信息 SHOW INDEX FROM table_name;
事务
1、概述
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务,但是一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。!
- 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
- 事务用来管理insert,update,delete语句
一般来说,事务是必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
- 1、事务的原子性:一组事务,要么成功;要么撤回。
- 2、稳定性 : 有非法数据(外键约束之类),事务撤回。
- 3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候吧事务保存到日志里。
2、事务操作
- 开启事务 start transaction
- 回滚事务 rollback
- 提交事务 commit
- 保留点 savepoint
delimiter \\ -- 此条可更改SQL语句结束符 create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; DELETE from tb1; insert into tb2(name)values('seven'); COMMIT; -- SUCCESS set p_return_code = 0; END\\ delimiter ;
py连接MySQL
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同
1、下载安装
pip3 install pymysql
2、操作使用
执行SQL
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,))
# 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
获取查询数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts")
# 获取第一行数据
row_1 = cursor.fetchone()
# 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode='relative') # 相对当前位置移动
- cursor.scroll(2,mode='absolute') # 相对绝对位置移动
fetch数据类型
关于默认获取的数据是元祖类型,如果想要或者字典类型的数据,即:
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') # 游标设置为字典类型 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) r = cursor.execute("call p1()") result = cursor.fetchone() conn.commit() cursor.close() conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号