
《机器学习基石》第9节课学习笔记
第9节课 Linear Regression
- 本节课本学习了机器学习最常见的一种算法:Linear Regression(线性回归)。这是学习《机器学习基石》中学到的第二种算法,第一种是PLA算法。先学习了线性回归问题,再学习的线性回归算法,最后有个泛化问题(数学推导那块没太懂)。所以本节课特别重要,希望通过本节课学习对线性回归有自己初步的了解。
(一)线性回归问题
1.之前学习PLA算法时讲了信用卡发放的例子,利用机器学习来决定是否给用户发放信用卡。这里仍引入信用卡的例子,例如,信用卡额度预测问题:特征是用户的信息(年龄,性别,年薪,当前债务,...),来解决给用户发放信用卡额度的问题,这就是一个线性回归问题。

2.令用户特征集为d维的X,加上常数项,维度为d+1与权重w的线性组合即为Hypothesis,记为h(x)。线性回归的预测函数取值在整个实数空间,这跟线性分类不同。
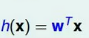
3.线性回归假设的思想是:寻找这样的直线/平面/超平面,使得输入数据的残差最小。
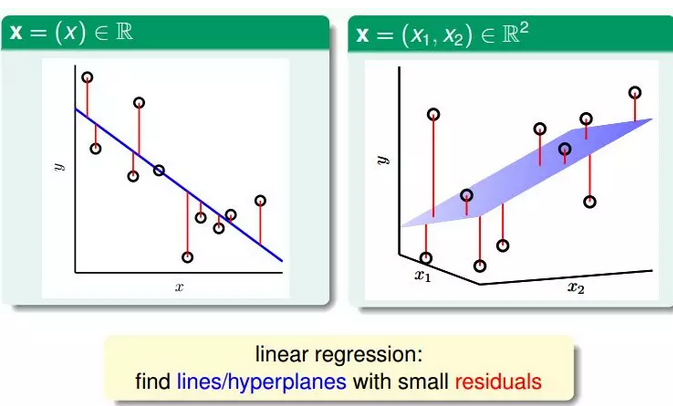
根据上图,在一维或者多维空间里,线性回归的目标是找到一条直线(对应一维)、一个平面(对应二维)或者更高维的超平面,使样本集中的点更接近它,也就是残留误差Residuals最小化。
4.最常用的错误测量方式是squared error:

(二)线性回归算法
1.squared error 的矩阵表示:

2.Ein 是连续可微的凸函数,可以通过偏微分求极值的方法来求参数向量w。

3.求得Ein(w) 的偏微分:
![]()
4.另上式等于0,即可以得到向量w。

上面分两种情况来求解w:当XTX(X 的转置乘以X) 可逆时,可以通过矩阵运算直接求得w;不可逆时,直观来看情况就没这么简单。
实际上,无论哪种情况都可以很容易得到结果。
因为许多现成的机器学习/数学库帮我们处理好了这个问题,只要我们直接调用相应的计算函数即可。有些库中把这种广义求逆矩阵运算成为 pseudo-inverse。
5.我们可以总结线性回归算法的步骤:

(三)泛化问题
1.现在,可能有这样一个疑问,就是这种求解权重向量的方法是机器学习吗?或者说这种方法满足我们之前推导VC Bound,即是否泛化能力强Ein≈Eout?

有两种观点:①这不属于机器学习范畴。②这属于机器学习范畴。
2.下面通过介绍一种更简单的方法,证明linear regression问题是可以通过线下最小二乘法方法计算得到好的Ein和Eout的。(多理解)

①首先,我们根据平均误差的思想,把Ein(wLIN)写成如图的形式,
②下面从几何图形的角度来介绍帽子矩阵H的物理意义。
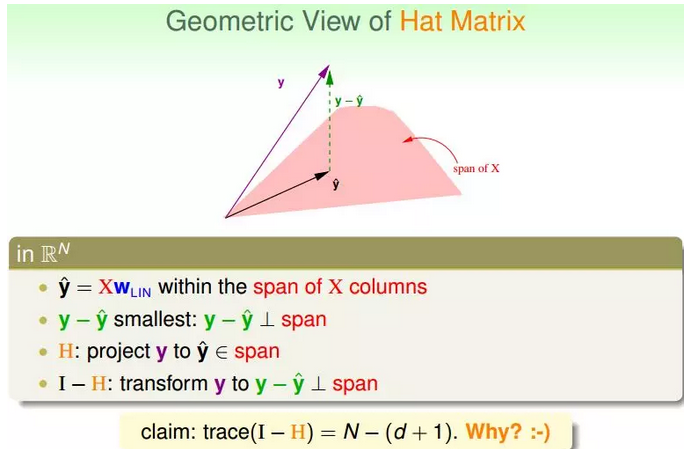
图中,y是N维空间的一个向量,粉色区域表示输入矩阵X乘以不同权值向量w所构成的空间,根据所有w的取值,预测输出都被限定在粉色的空间中。向量y^就是粉色空间中的一个向量,代表预测的一种。y是实际样本数据输出值。
机器学习的目的是在粉色空间中找到一个y^,使它最接近真实的y,那么我们只要将y在粉色空间上作垂直投影即可,投影得到的y^即为在粉色空间内最接近y的向量。这样即使平均误差E¯最小。
③在存在noise的情况下,上图变为:
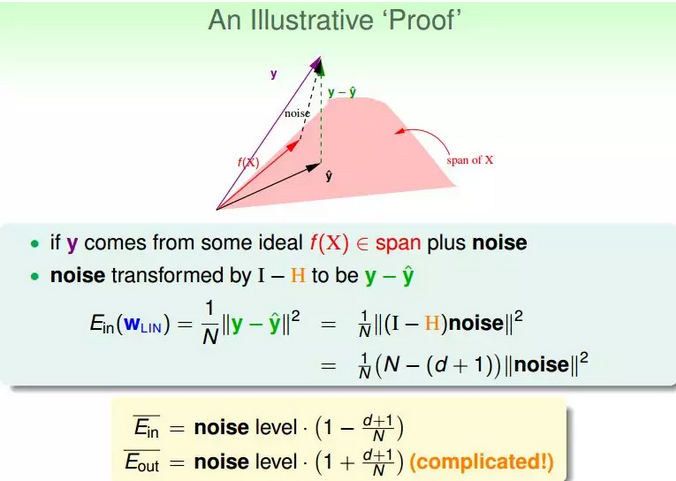
图中,粉色空间的红色箭头是目标函数f(x),虚线箭头是noise,可见,真实样本输出y由f(x)和noise相加得到。
④我们把E¯in与E¯out画出来,得到学习曲线:
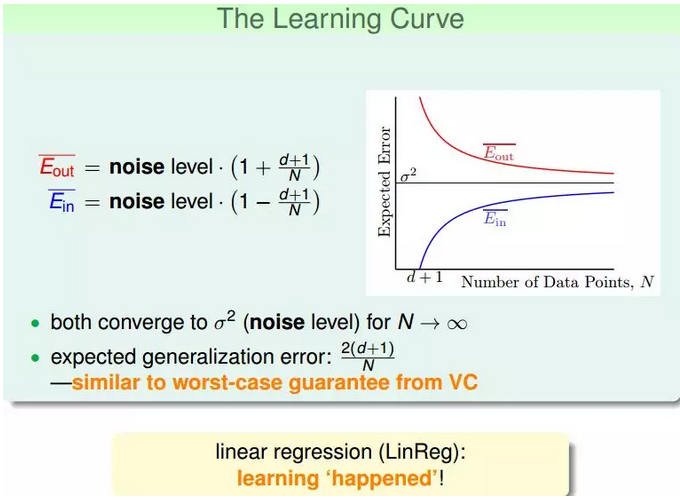
当N足够大时,E¯in与E¯out逐渐接近,满足E¯in≈E¯out,且数值保持在noise level。这就类似VC理论,证明了当N足够大的时候,这种线性最小二乘法是可以进行机器学习的。
3.故线性回归属于机器学习算法:
① 对Ein 进行优化。
②得到Eout 约等于 Ein。
③本质上还是迭代提高的:pseudo-inverse 内部实际是迭代进行的。
(四)线性回归与线性分类器(弄懂)
1.之前介绍的线性分类问题使用的Error Measure方法用的是0/1 error。那么线性回归的squared error是否能够应用到线性分类问题上。

2.下图展示了两种错误的关系,一般情况下,squared error曲线在0/1 error曲线之上。即
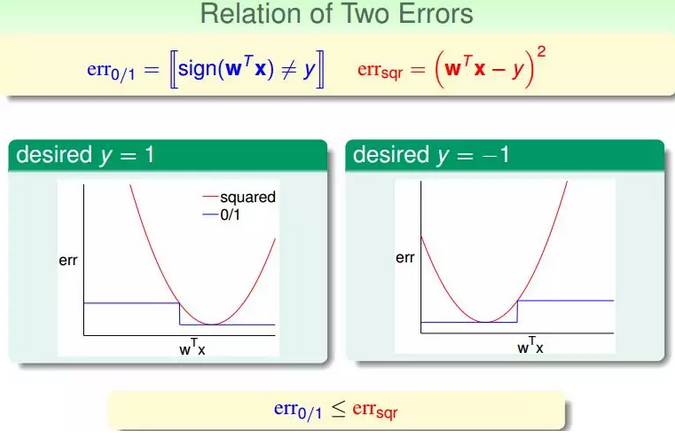
3.根据之前的VC理论,Eout的上界满足:

结论:之所以能够通过线程回归的方法来进行二值分类,是由于回归的squared error 是分类的0/1 error 的上界,我们通过优化squared error,一定程度上也能得到不错的分类结果;或者,更好的选择是,将回归方法得到的w 作为二值分类模型的初始w 值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号