
《机器学习基石》第5节课学习笔记
第5节课 Training versus Testing
- 本节课我更加深入的学习了机器学习的可行性。可以机器学习拆分为两个核心问题:Ein(g)≈Eout(g)和Ein(g)≈0。针对这两个问题展开了探讨,主要针对批量的二元分类问题。后面对成长函数和突破点的介绍没有看懂,还需要进一步理解。
1.上节课机器学习可行性的回顾
(1)一个重要公式:
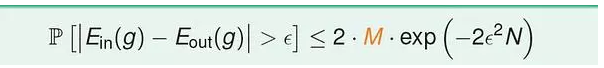
(2)机器学习流程图:
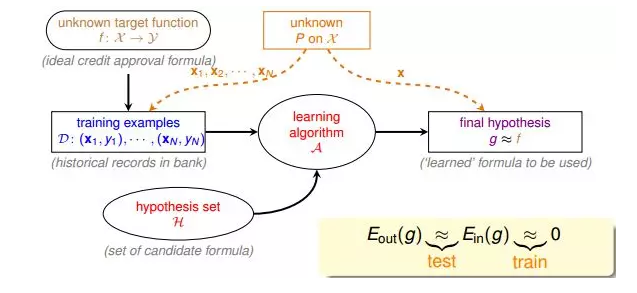
该流程图中,训练样本D和最终测试h的样本都是来自同一个数据分布,这是机器能够学习的前提。另外,训练样本D应该足够大,且hypothesis set的个数是有限的,这样根据霍夫丁不等式,才不会出现Bad Data,保证Ein≈Eout,即有很好的泛化能力。同时,通过训练,得到使Ein最小的h,作为模型最终的矩g,g接近于目标函数。
2. 我们把机器学习的主要目标分成两个核心的问题:

机器学习可行的一个条件是hypothesis set的个数M是有限的,那M跟上面这两个核心问题有什么联系呢?
首先,当M很小的时候,上节课介绍的霍夫丁不等式,得到Ein(g)≈Eout(g),即能保证第一个核心问题成立。但M很小时,演算法A可以选择的hypothesis有限,不一定能找到使Ein(g)足够小的hypothesis,即不能保证第二个核心问题成立。当M很大的时候,同样由霍夫丁不等式,Ein(g)与Eout(g)的差距可能比较大,第一个核心问题可能不成立。而M很大,使的演算法A的可以选择的hypothesis就很多,很有可能找到一个hypothesis,使Ein(g)足够小,第二个核心问题可能成立。
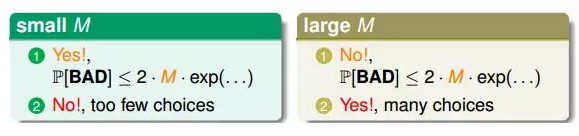
M的选择直接影响机器学习的两个核心问题是否满足,不能太大也不能太小。
3.具体的探讨(涉及到霍夫丁不等式,这块比较重要)
(1)霍夫丁不等式:

其中,M表示hypothesis的个数。每个hypothesis下的BAD events
Bm级联的形式满足下列不等式:

当M=∞时,上面不等式右边值将会很大,似乎说明BAD events很大,Ein(g)与Eout(g)也并不接近。但是BAD events Bm级联的形式实际上是扩大了上界,union bound过大。这种做法假设各个hypothesis之间没有交集,这是最坏的情况,可是实际上往往不是如此,很多情况下,都是有交集的,也就是说M实际上没那么大,如下图所示:
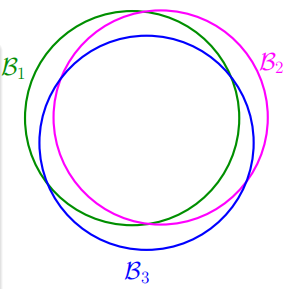
也就是说union bound被估计过高了(over-estimating)。
所以,我们的目的是找出不同BAD events之间的重叠部分,也就是将无数个hypothesis分成有限个类别。
(2)批量二元分类问题的探讨(如何将无数个hypothesis分成有限)
例子:假如平面上用直线将点分开,也就跟PLA一样。如果平面上只有一个点x1,那么直线的种类有两种:一种将x1划为+1,一种将x1划为-1:
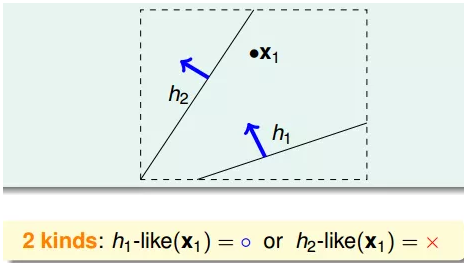
如果平面上有两个点x1、x2,那么直线的种类共4种:x1、x2都为+1,x1、x2都为-1,x1为+1且x2为-1,x1为-1且x2为+1:
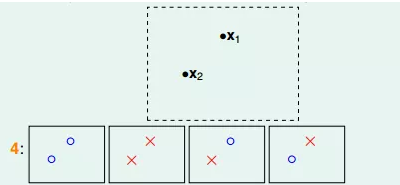
如果平面上有三个点x1、x2、x3,那么直线的种类共8种:
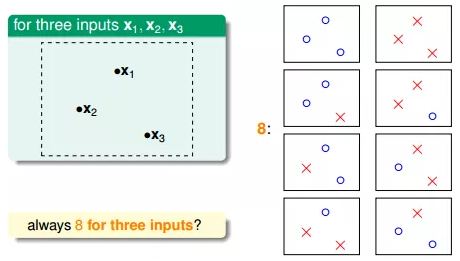
但是,在三个点的情况下,也会出现不能用一条直线划分的情况:
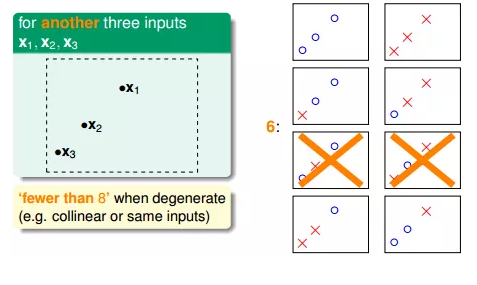
也就是说,对于平面上三个点,不能保证所有的8个类别都能被一条直线划分。那如果是四个点x1、x2、x3、x4,我们发现,平面上找不到一条直线能将四个点组成的16个类别完全分开,最多只能分开其中的14类,即直线最多只有14种:
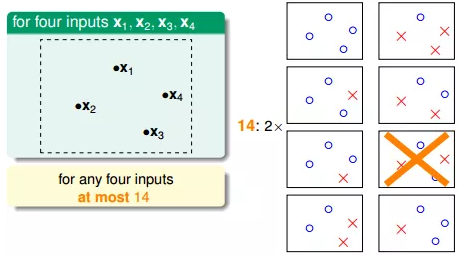
由此可以推论出平面上线的种类是有限的,由一个点,两个点推论到N个点,有效直线数量总是小于2的N次方。(这一块不是太懂)
如下图:

4.新的名词:二分类和成长函数(这一部分没有理解)
(1)定义关于数据规模N 的成长函数(growth function):数据规模为N 时,可能的dichotomy 的数量,记为m(N)。
下面列举几种成长函数:

(2)突破点(break point):对于某种假设空间H,如果m(k)<2^k, 则k 是它的突破点。
注意:如果k 是突破点,那么k+1, k+2, ... 都是突破点。

对于感知机,不知道它的生长函数,但是知道它的第一个突破点是4, m(4)=14 < 16
突破点是一个很重要的概念。
以下有个例题可以更好的理解成长函数和突破点:
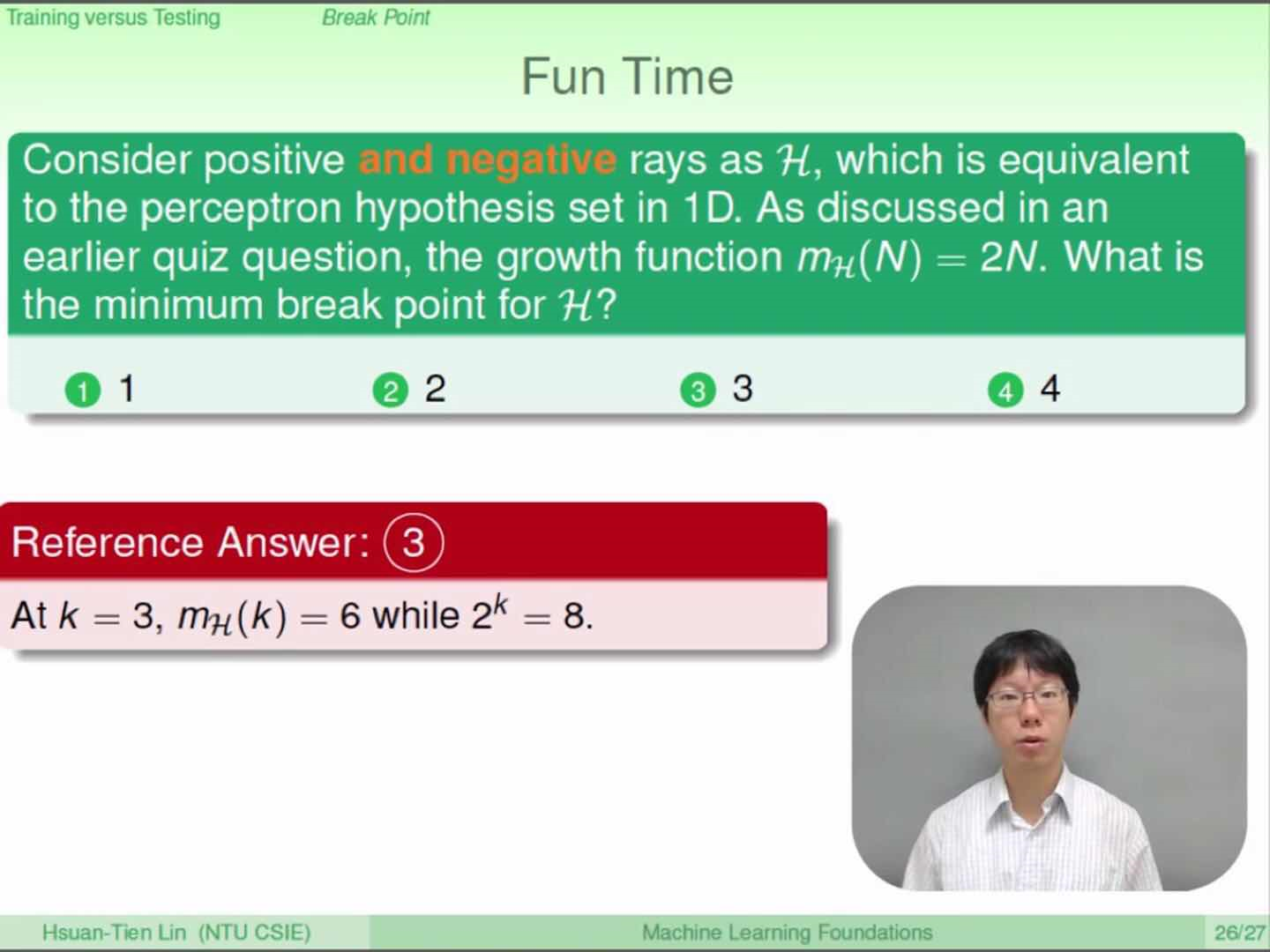
以上例题中k=3是突破点,其中mH(N)=2N是成长函数,因为6和8有落差,根据定义对于某种假设空间H,如果m(k)<2^k, 则k 是它的突破点。
希望借助以上这个例题可以更好的理解成长函数和突破点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号