


《机器学习基石》第11节课学习笔记
第11节课 Linear Models for Classification
- 本节课主要学习了分类问题的三种线性模型:linear classification(线性分类)、linear regression(线性回归)和logistic regression(逻辑回归)。首先比较了这三种模型,然后介绍了比梯度下降算法更加高效的SGD算法来进行logistic regression分析(这一块没有掌握好)。最后讲解了两种多分类方法,一种是OVA,另一种是OVO。(两种分类方法好好理解以下,可以带例子去理解概念)
(一)三种线性模型
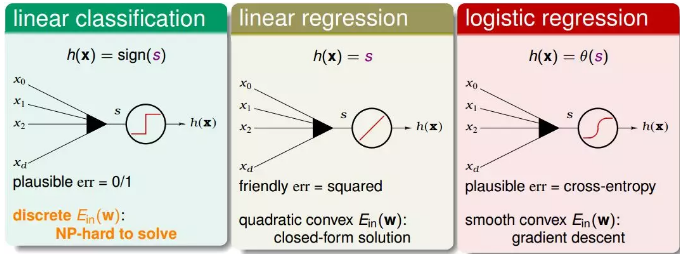
1.本质上讲,线性分类(感知机)、线性回归、逻辑斯蒂回归都属于线性模型,因为它们的核心都是一个线性score 函数:
![]()
只是三个model 对其做了不同处理:
线性分类对s 取符号;线性回归直接使用s 的值;逻辑斯蒂回归将s 映射到(0,1) 区间。
2.三种模型的hypothesis
(1)linear classification(线性分类模型)。
线性分类模型的hypothesis为h(x)=sign(s),取值范围为{-1,+1}两个值,它的err是0/1的,所以对应的Ein(w)是离散的,并不好解,这是个NP-hard问题。
(2)linear regression(线性回归模型)。
线性回归模型的hypothesis为h(x)=s,取值范围为整个实数空间,它的err是squared的,所以对应的Ein(w)是开口向上的二次曲线,其解是closed-form的,直接用线性最小二乘法求解即可。
(3logistic regression(逻辑回归模型)。
逻辑回归模型的hypothesis为h(x)=θ(s),取值范围为(-1,1)之间,它的err是cross-entropy的,所有对应的Ein(w)是平滑的凸函数,可以使用梯度下降算法求最小值。
3.为了更方便地比较三个model,对其error function 做一定处理:

这样,三个error function 都变成只有y*s 这一项“变量”。
通过曲线来比较三个error function (注意:cross-entropy 变为以2为底的scaled cross-entropy)

很容易通过比较三个error function 来得到分类的0/1 error 的上界:
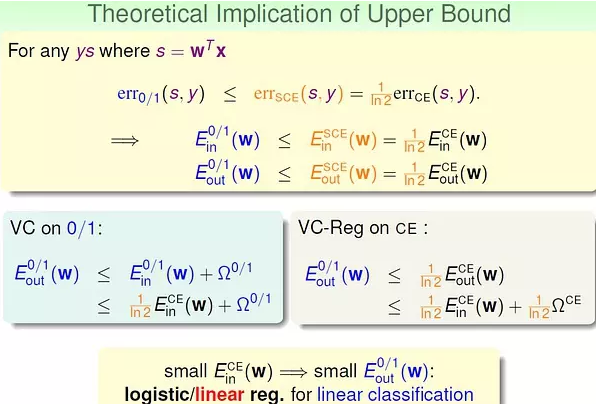
这样,我们就理解了通过逻辑斯蒂回归或线性回归进行分类的意义。(还是需要多看这一块的视频讲解)
4.三种模型的优缺点
优点:在数据线性可分时高效且准确。
缺点:只有在数据线性可分时才可行,否则需要借助POCKET 算法(没有理论保证)。
(2)线性回归
优点:最简单的优化(直接利用矩阵运算工具)
缺点:ys 的值较大时,与0/1 error 相差较大(loose bound)。
(3)逻辑斯蒂回归
优点:比较容易优化(梯度下降)
缺点:ys 是非常小的负数时,与0/1 error 相差较大。

(二)随机梯度下降 (Stochastic Gradient Descent)(好好理解)
1.定义:随机梯度下降算法每次迭代只找到一个点,计算该点的梯度,作为我们下一步更新w的依据。这样就保证了每次迭代的计算量大大减小,我们可以把整体的梯度看成这个随机过程的一个期望值。

2.随机梯度下降可以看成是真实的梯度加上均值为零的随机噪声方向。单次迭代看,好像会对每一步找到正确梯度方向有影响,但是整体期望值上看,与真实梯度的方向没有差太多,同样能找到最小值位置。
随机梯度下降的优点是减少计算量,提高运算速度,而且便于online学习;缺点是不够稳定,每次迭代并不能保证按照正确的方向前进,而且达到最小值需要迭代的次数比梯度下降算法一般要多。

3.对于logistic regression的SGD,它的表达式为:

我们发现,SGD与PLA的迭代公式有类似的地方,如下图所示:


这种方法在统计上的意义是:进行足够多的更新后,平均的随机梯度与平均的真实梯度近似相等。
注意:在这种优化方法中,一般设定一个足够大的迭代次数,算法执行这么多的次数时我们就认为已经收敛。(防止不收敛的情况)
(三)多类别分类
1.引例:之前我们一直讲的都是二分类问题,本节主要介绍多分类问题,通过linear classification来解决。假设平面上有四个类,分别是正方形、菱形、三角形和星形,如何进行分类模型的训练:
①首先我们可以想到这样一个办法,就是先把正方形作为正类,其他三种形状都是负类,即把它当成一个二分类问题,通过linear classification模型进行训练,得出平面上某个图形是不是正方形,且只有{-1,+1}两种情况。然后再分别以菱形、三角形、星形为正类,进行二元分类。这样进行四次二分类之后,就完成了这个多分类问题。
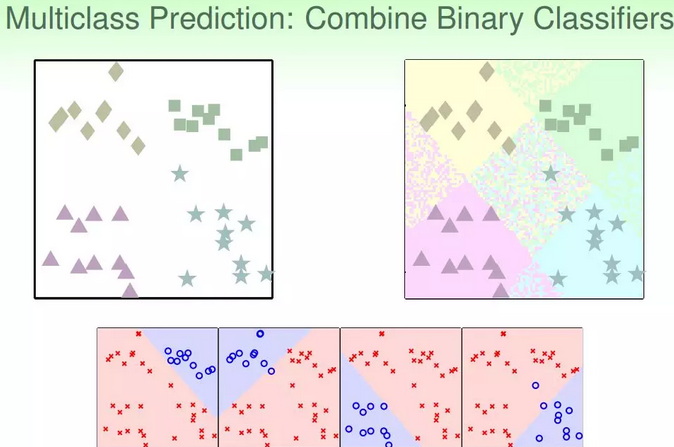
②但是,这样的二分类会带来一些问题,有时候没法正确分类。针对这种问题,我们可以使用另外一种方法来解决:soft软性分类,即不用{-1,+1}这种binary classification,而是使用logistic regression,计算某点属于某类的概率、可能性,去概率最大的值为那一类就好。
③改进:soft classification的处理过程和之前类似,同样是分别令某类为正,其他三类为负,不同的是得到的是概率值,而不是{-1,+1}。最后得到某点分别属于四类的概率,取最大概率对应的哪一个类别就好。效果如下图所示:
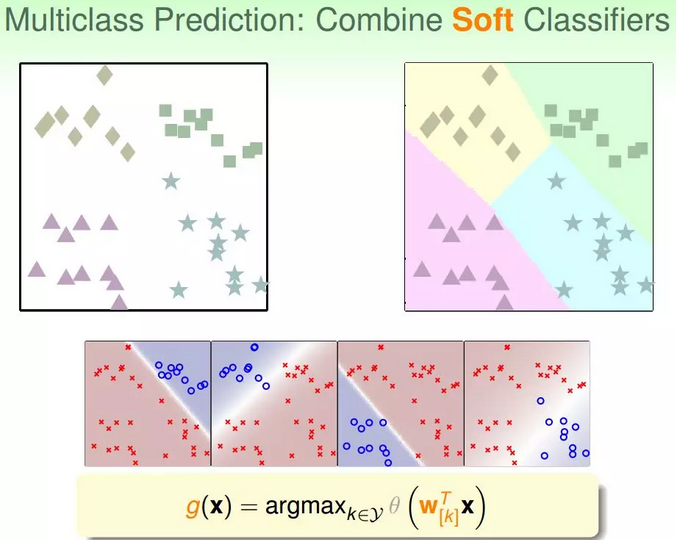
2.定义:这种多分类的处理方式,我们称之为OVA。
这种方法的优点是简单高效,可以使用logistic regression模型来解决;
缺点是如果数据类别很多时,那么每次二分类问题中,正类和负类的数量差别就很大,数据不平衡unbalanced,这样会影响分类效果。
但是,OVA还是非常常用的一种多分类算法。

(四)另一种多类别分类
1.这种方法叫做One-Versus-One(OVO),对比上面的OVA 方法。
2.基本方法:每轮训练时,任取两个类别,一个作为+1,另一个作为-1,其他类别的数据不考虑,这样,同样用二值分类的方法进行训练;目标类有k个时,需要 k(k-1)/2 轮训练,得到 k(k-1)/2 个分类器。
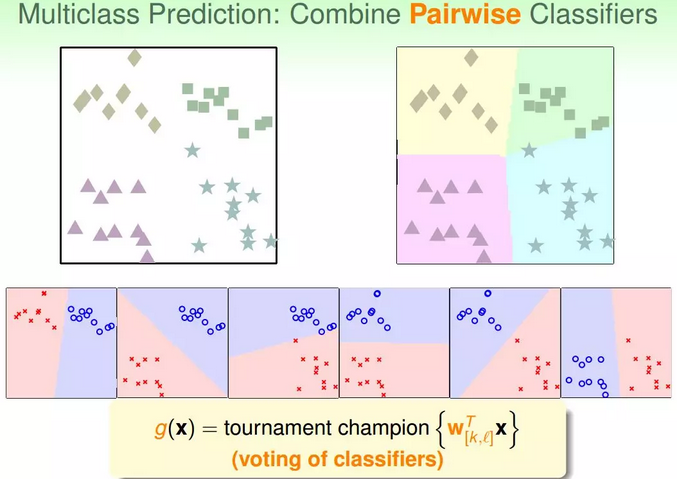
3.预测:对于某个x,用训练得到的 k*(k-1)/2 个分类器分别对其进行预测,哪个类别被预测的次数最多,就把它作为最终结果。即通过“循环赛”的方式来决定哪个“类”是冠军。
显然,这种方法的优点是每轮训练面对更少、更平衡的数据,而且可以用任意二值分类方法进行训练;缺点是需要的轮数太多(k*(k-1)/2),占用更多的存储空间,而且预测也更慢。

总结:OVA 和 OVO 方法的思想都很简单,可以作为以后面对多值分类问题时的备选方案,并且可以为我们提供解决问题的思路。
