


《机器学习基石》第10节课学习笔记
第10节课 Logistic Regression
- 本节课继续学习了回归的问题,线性回归重点是求解了w 的解析方案(通过pseudo-inverse 求解w)。而这节课学习了另一个很重要的方法,逻辑斯蒂回归(logistic regression)。里面涉及到的数学意义,需要自己多钻研,涉及到回归优化,梯度问题(不太懂)等等,需要多下功夫好好去理解。
(一)逻辑斯蒂回归问题
1.引例:一个心脏病预测的问题:根据患者的年龄、血压、体重等信息,来预测患者是否会有心脏病。很明显这是一个二分类问题,其输出y只有{-1,1}两种情况。
二元分类,一般情况下,理想的目标函数f(x)>0.5,则判断为正类1;若f(x)<0.5,则判断为负类-1。
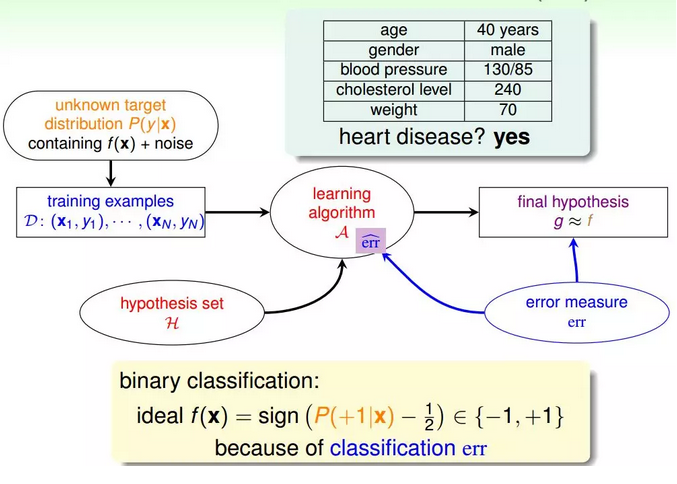
2.但是,如果我们想知道的不是患者有没有心脏病,而是到底患者有多大的几率是心脏病。这表示,我们更关心的是目标函数的值(分布在0,1之间),表示是正类的概率(正类表示是心脏病)。这个值越接近1,表示正类的可能性越大;越接近0,表示负类的可能性越大。

对于软性二分类问题,理想的数据是分布在[0,1]之间的具体值,但是实际中的数据只可能是0或者1,我们可以把实际中的数据看成是理想数据加上了噪声的影响。
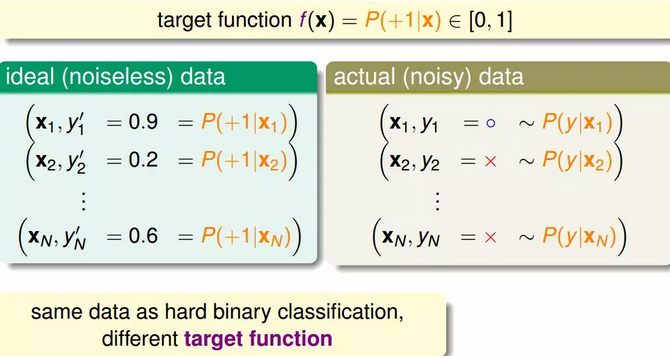
3.在二值分类中,我们通过w*x 得到一个"score" 后,通过取符号运算sign 来预测y 是+1 或 -1。而对于当前问题,我们如同能够将这个score 映射到[0,1] 区间,问题似乎就迎刃而解了。
逻辑斯蒂回归选择的映射函数是S型的sigmoid 函数。
sigmoid 函数: f(s) = 1 / (1 + exp(-s)), s 取值范围是整个实数域, f(x) 单调递增,0 <= f(x) <= 1。
于是,我们有:
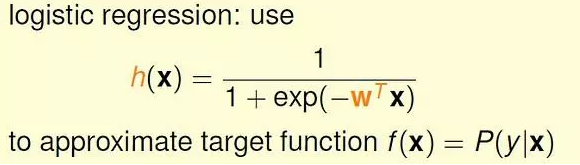
(二)逻辑回归的error
1.现在我们将逻辑回归与之前讲的线性回归、线性分类做个比较:
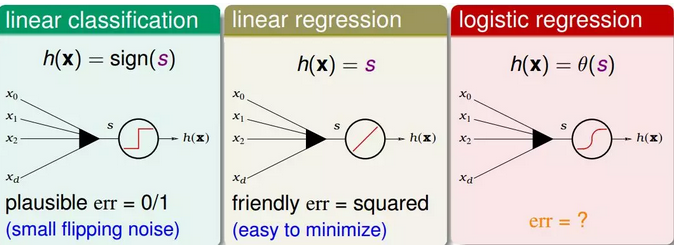
①linear classification(线性分类)的误差使用的是0/1 err;
②linear regression(线性回归)的误差使用的是squared err。
那么logistic regression的误差该如何定义呢?
2.介绍一下“似然性”的概念:
①首先式子如下:

②如果将w代入的话:
③为了把连乘问题简化计算,我们可以引入ln操作,让连乘转化为连加:
④接着,我们将maximize问题转化为minimize问题,添加一个负号就行,并引入平均数操作1/N:
⑤将logistic function的表达式带入,那么minimize问题就会转化为如下形式:
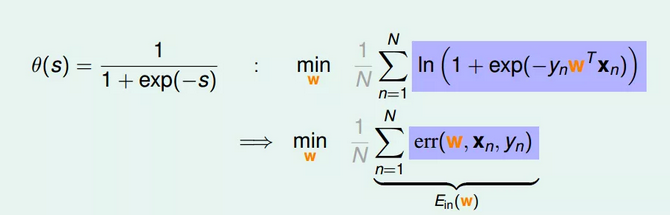
⑥至此,我们得到了logistic regression的err function,称之为cross-entropy error交叉熵误差:

(三)梯度问题(需要好好理解)
1.我们已经推导了Ein的表达式,那接下来的问题就是如何找到合适的向量w,让Ein最小。
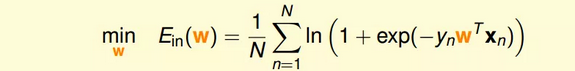
2.Logistic Regression的Ein是连续、可微、二次可微的凸曲线(开口向上),根据之前Linear Regression的思路,我们只要计算Ein的梯度为零时的w,即为最优解。

3.对Ein计算梯度,学过微积分的都应该很容易计算出来:

4.最终得到的梯度表达式为:

5.想要上式等于零,或者sigmoid 项恒为0,这时要求数据时线性可分的(不能有噪音)。
否则,需要迭代优化。直观的优化方法:

(四)关于梯度下降法
1.梯度下降法是最经典、最常见的优化方法之一。
要寻找目标函数曲线的波谷,采用贪心法:想象一个小人站在半山腰,他朝哪个方向跨一步,可以使他距离谷底更近(位置更低),就朝这个方向前进。这个方向可以通过微分得到。
选择足够小的一段曲线,可以将这段看做直线段,那么有:

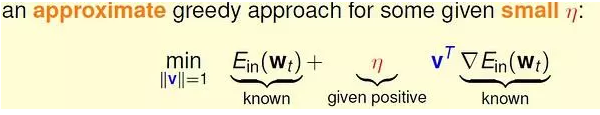
2.梯度下降的精髓:

之所以说最优的v 是与梯度相反的方向,想象一下:如果一条直线的斜率k>0,说明向右是上升的方向,应该向左走;反之,斜率k<0,向右走。
解决的方向问题,步幅也很重要。步子太小的话,速度太慢;过大的话,容易发生抖动,可能到不了谷底。
显然,距离谷底较远(位置较高)时,步幅大些比较好;接近谷底时,步幅小些比较好(以免跨过界)。距离谷底的远近可以通过梯度(斜率)的数值大小间接反映,接近谷底时,坡度会减小。
因此,我们希望步幅与梯度数值大小正相关。
原式子可以改写为:

3.总结一下基于梯度下降的Logistic Regression算法步骤如下:
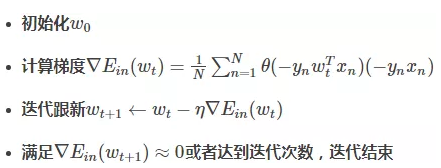

注:关于梯度这两小节课的视频需要多看几遍,弄懂过程。
