【分享】面试官:说下Redis 主从同步原理
1.MYISAM 和 Innodb 差别
1. InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
2. InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
3. InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的 叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要 两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为 主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索 引保存的是数据文件的指针。主键索引和辅助索引是独立的。
4. InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可, 速度很快;
5. InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁 住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默 认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
6. 每个 MyISAM 在磁盘上存储成三个文件。分别为:表定义文件、数据文件、索引文 件。InnoDB 是单文件,文件大小受操作系统的限制
7. MyISAM:不支持 fulltext 索引,innodb 支持
8. MyISAM 支持支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空 格,会被去掉)、动态表、压缩表。InnoDB 需要更多的内存和存储,它会在主内存中建 立其专用的缓冲池用于高速缓冲数据和索引。
9. 可移植性,MyISAM 是存储在文件中,迁移很方便,InnoDB 有各种日志,免费的方 案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时 候就相对痛苦了。
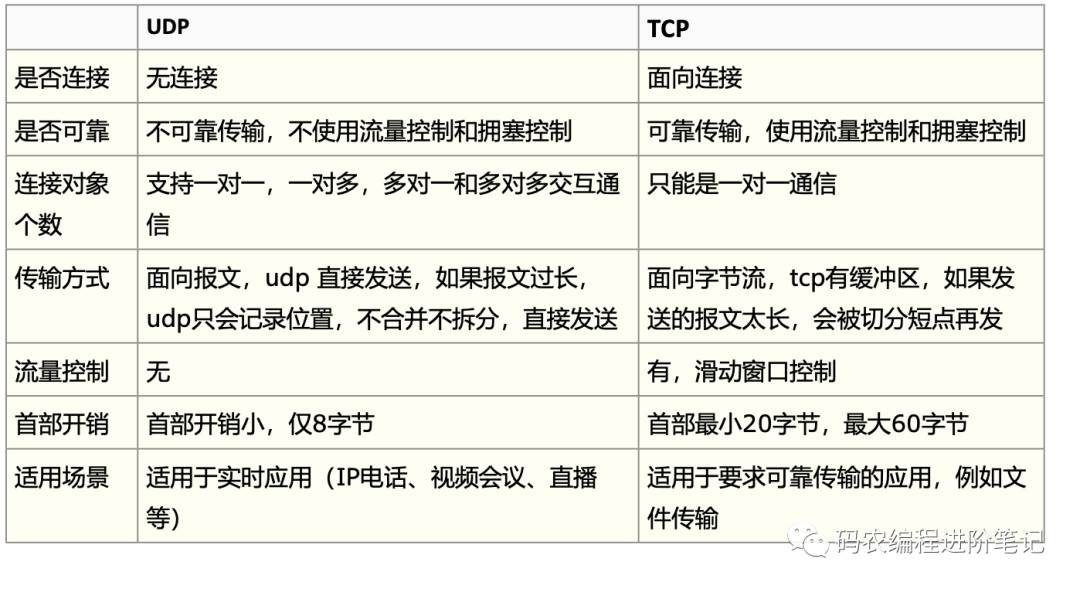
2.Tcp 和 udp 的区别:
1. tcp是面向连接的,而udp是无连接就发送数据的,tcp 的三次握手,四次挥手,所以 tcp 面向链接,而udp就是一个数据报带着目的ip和端口,直接发送。
2. tcp传输时是可靠的,udp传输时是不可靠的。tcp有个以字节为单位的滑动窗口,它 把要发送的数据都以字节形式存储在这个滑动窗口当中。每次发送完窗口的数据后,都 会先保留数据,只有当收到对方的数据确认收到信号时再清除这些数据,如果超时没有 收到确认信号的话就要重传。这就是tcp的确认重传机制。
3. udp 适合快速传输不太重要但实时性要求比较高的大数据,比如实时的视频传输,而 tcp 适合传输可靠的内容。
4. 基于tcp的应用层协议:http,https,ftp,telnet 基于udp :dns,tftp
5. 一个TCP数据包报头的大小是20字节,UDP数据报报头是8个字节。TCP报头中包含 序列号,ACK号,数据偏移量,保留,控制位,窗口,紧急指针,可选项,填充项,校 验位,源端口和目的端口。而UDP报头只包含长度,源端口号,目的端口,和校验和。6. TCP有流量控制。在任何用户数据可以被发送之前,TCP需要三数据包来设置一个套 接字连接。TCP处理的可靠性和拥塞控制。另一方面,UDP不能进行流量控制。
3.Http 和 https 的区别
1、https协议需要到ca申请证书,一般免费证书很少,需要交费。2、http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密 传输协议。3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80, 后者是443。4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行 加密传输、身份认证的网络协议,比http协议安全。
4.Include 和 require 区别
这两者是语言结构,不是函数,他们都可以直接引用参数,而不是括号内引用参数
include在用时加载,一般放在代码段中,出错时继续执行下面的代码
require一般放在脚本最前面,会一开始就读取,出错时停止运行代码
_once 是已加载的不加载
5.Epoll select poll 区别
(1)select==>时间复杂度O(n) 它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至 全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进 行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时 间就越长。最多支持 1024 个fd。
(2)poll==>时间复杂度O(n) poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对 应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的. poll的 实现和select非常相似,只是描述fd集合的方式不同,poll 使用 pollfd 结构而不是select 的 fd_set 结构,其他的都差不多。
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎 样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的, 此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多 个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应 的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件 就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负 责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠 和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中, 并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒 着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为 空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current 往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只 挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个 epoll内部定义的等待队列)。这也能节省不少的开销。
Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进 程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索 引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
6.New self 和 new static 的区别:
-
new self()和new static()的区别只有在继承中才能体现出来,如果没有任何继承, 那么这两者是没有区别的。
-
在继承中,new self()返回的实例是万年不变的,无论谁去调用,都返回同一个类 的实例,而new static()则是由调用者决定的。
7.Git reset 和 git revert 区别
git reset 会失去后面的提交,而 git revert 是通过反做的方式重新创建一个新的提交, 而保留原有的提交,git reset 之后需要 git push -f 强制提交,不建议使用
8.Do while while foreach for 区别
Do while 和while类似,do while 会不管条件真假先执行一次,while 条件为真才执 行,foreach 循环为先读取整块数据,然后再循环,而 for 主要用于限制循环次数 例如循环数组,while 是移动内部指针,foreach 是对数组副本进行操作,而 foreach 在读操作比较快,在写操作比较慢,因为 php 的 引用计数写时复制 的特性
9.Mysql 事务中脏读和幻读的区别:
脏读(Dirty Read): 脏读是指一个事务读到了另一个未提交事务修改过的数据。幻读(Phantom Read): 所谓幻读,指的是当某个事务在读取某个范围内的记录 时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录 时,会读取到之前没有读到的数据。
事务的四个隔离级别:Read Uncommitted(读取未提交内容),Read Committed(读取提交内容),Repeatable Read(可重读),Serializable(可串行 化),其中未提交读会产生脏读,未提交读、提交读、可重复读会产生幻读情况
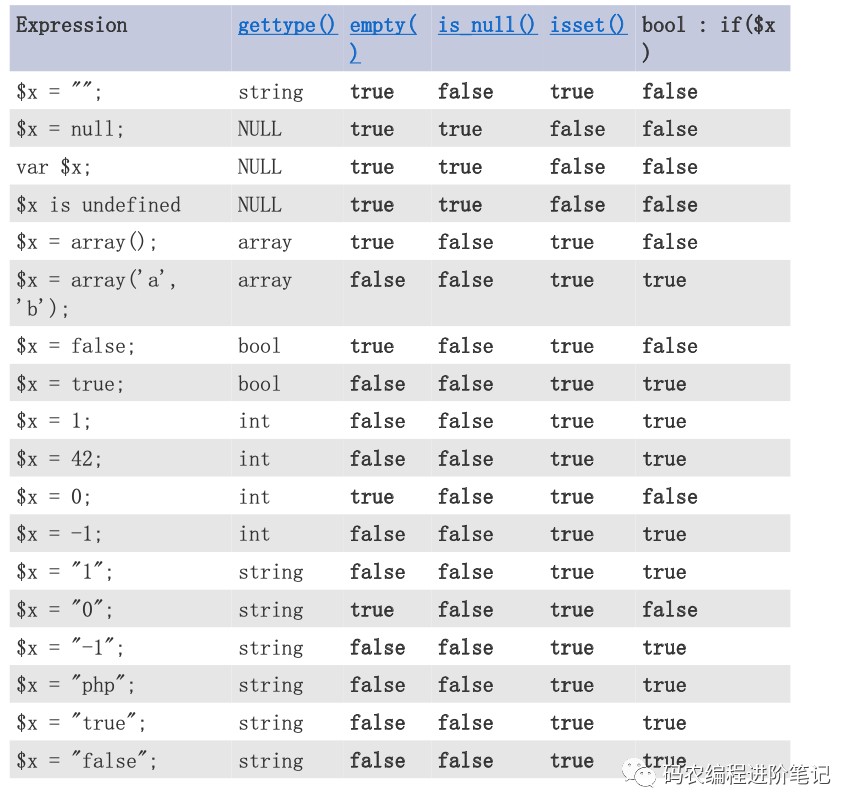
10.Isset empty gettype is_null 区别
11.Redis 主从同步原理
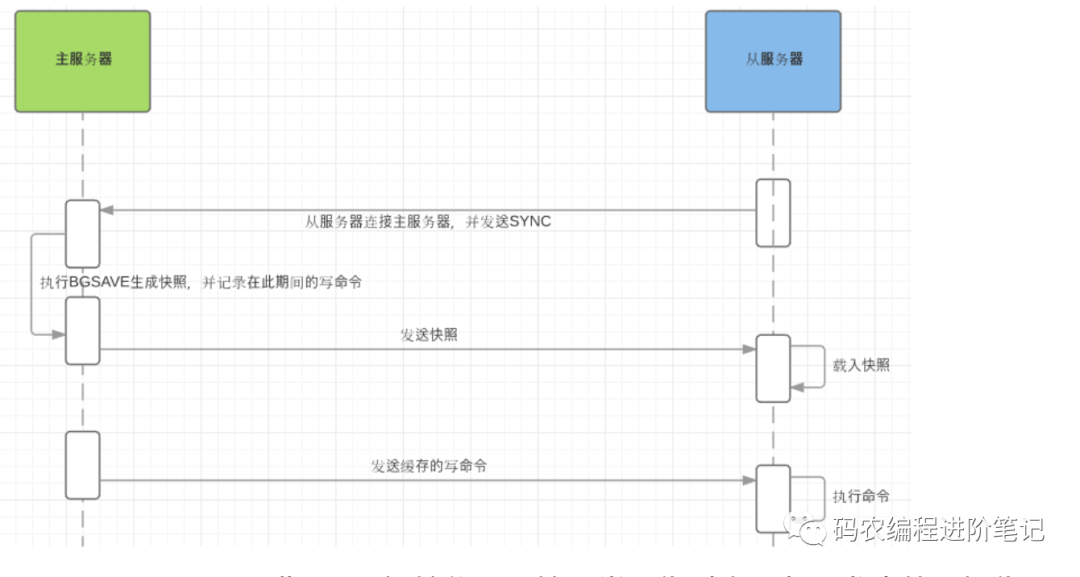
Slave 初始化中是全量同步,
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记 录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录 被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命 令;
全量之后是增量同步:指Slave初始化后开始正常工作时主服务器发生的写操作同 步到从服务器的过程。
额外信息:
1)一个master可以有多个slave,slave也可以有多个slave,组成树状结构2)主从同步不会阻塞master,但是会阻塞slave。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞不能处理client的请求;3)主从同步可以用来提高系统的可伸缩性,我们可以用多个slave专门处理client的读请求,也可以用来做简单的数据冗余或者只在slave上进行持久化从 而提升集群的整体性能。
12.redo undo 日志和事务执行中崩溃的重放
redo log 包括两部分:一个是内存中的日志缓冲( redo log buffer ),另一个是磁盘上
的日志文件( redo logfile)。
mysql 每执行一条 DML(增删改) 语句,先将记录写入 redo log buffer,后续某个时 间点再一次性将多个操作记录写到 redo log file。这种 先写日志,再写磁盘 的技术就 是 MySQL wal(预写式日志),在计算机操作系统中,用户空间( user space )下的缓冲 区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间( kernel space )缓冲区( OS Buffer )。
因此, redo log buffer 写入 redo logfile 实际上是先写入 OS Buffer ,然后再通过系 统调用 fsync() 将其刷到 redo log file中。
undo-log 保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版 本并发控制下的读(MVCC),也即非锁定读。在事务开始之前,将当前事务的版本生 成undo-log,undo也会产生redo日志来保证undo-log的可靠性。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录 时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它 记录一条对应相反的update记录。
在恢复时,对于已经COMMIT的事务使用redo log进行重做,对于没有 COMMIT的事务,使用undo log进行回滚.
13.Php 长网址转成短网址
<?php
//短网址生成算法
class ShortUrl
{
//字符表
public static $charset = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
//编码
public static function encode($url)
{
$key = 'abc'; //加盐
$urlhash = md5($key . $url);
$len = strlen($urlhash);
//将加密后的串分成4段,每段4字节,对每段进行计算,一共可以生成四组短连接
for ($i = 0; $i < 4; $i++) {
$urlhash_piece = substr($urlhash, $i * $len / 4, $len / 4);
//将分段的位与0x3fffffff做位与,0x3fffffff表示二进制数的30个1,即30位 以后的加密串都归零
//此处需要用到hexdec()将16进制字符串转为10进制数值型,否则运算会不正常
$hex = hexdec($urlhash_piece) & 0x3fffffff;
//域名根据需求填写
$short_url = "http://t.cn/";
//生成6位短网址
for ($j = 0; $j < 6; $j++) {
//将得到的值与0x0000003d,3d为61,即charset的坐标最大值
$short_url .= self::$charset[$hex & 0x0000003d];
//循环完以后将hex右移5位
$hex = $hex >> 5;
}
$short_url_list[] = $short_url;
}
return $short_url_list;
}
}
//示例
$url = "http://www.sunbloger.com/";
$short = ShortUrl::encode($url);
print_r($short);更好的长短网址转换方案是长网址插入数据库,得到id,十进制的 id 转成 62 进制的值,保存起来对应关系,可逆可查。
赞赏码


非学,无以致疑;非问,无以广识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号