如何设计微博点赞功能数据库?
一、如何设计微博点赞功能数据库?
明星的一条微博的点赞数可能有几十万,甚至百万以上。那么这个「点赞功能」(会记录谁点了赞),新浪微博的数据库是如何设计的呢?
网上说用到了 Redis,那么难道是直接用 Redis 保存的(指的是持久化保存)?还是说逻辑处理在 Redis 中,之后会定时同步/持久化到 MySQL 等磁盘数据库?
概括一下:就是想弄明白「点赞」这种数据量庞大的功能,数据库是如何设计、保存的呢?
没设计过微博,也不懂新浪是怎么搞的,纯粹按照我们做流式监测项目的经验做一个设计思路。
队列后面另一条路事件流,直接将微博点赞事件数据作为原始数据写入到大数据平台,例如hdfs,但是写入前,做一个类似hudi,parquet列格式,方便存储进hdfs的数据查询,也方便后续批量统计。
这样点赞总数总是来自当日总数和非当天统计总数之和,当日总数是实时增量的,不去理会是否正确,做好批量统计比对就一定能保证隔天以后点赞总数的准确性。如下图所示:
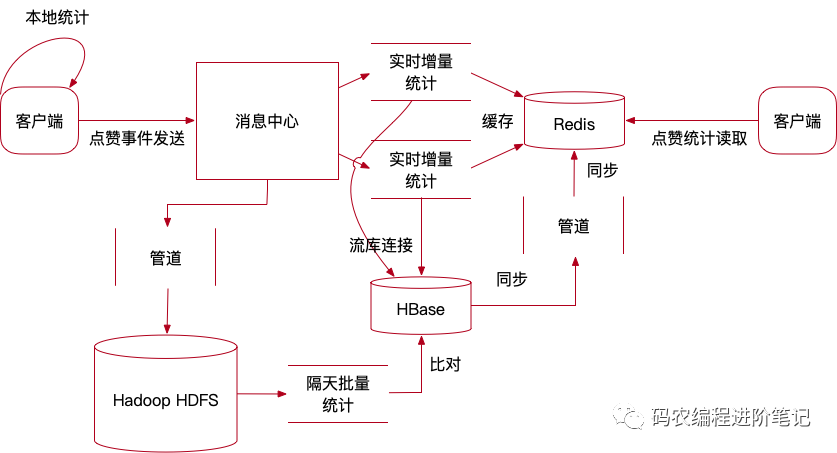
上述仅仅是一个思路,可以同时解决微博点赞统计准确性和点赞访问性能两个指标,实际业务肯定比这个思路复杂千百倍,但总之给大家一个理解参考的方向。
二、如何选择实时采集数据的数据库?
前提:数据采集24小时连续不断,更新或插入数据库操作的频率大概在每秒1000+。
采集数据主要是看应用场景,如果是采集数据按周期整存整取,批量读取分析的话,用分布式文件系统,数据量够大,写入非常快,直接上Hadoop hdfs
但是若数据采集到,不仅要做离线分析,还需要实时的回放查找,那么对于这种情况最好的方法就是使用时序数据库,例如opentsdb,它是基于HBASE,因此底层还是依赖Hadoop hdfs。
如果觉得写得不错,文章对你有用,请在文末「在看,分享和赞」三连击
赞赏码


非学,无以致疑;非问,无以广识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号