消息队列 ActiveMQ 、RocketMQ 、RabbitMQ 和 Kafka 如何选择?
消息队列(MQ)
在百度百科中,消息队列(MQ)是这么解释的:“消息队列”是在消息的传输过程中保存消息的容器(可存可取)。
它是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰和降低系统耦合性。
异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比较串行处理,减少处理时间;
应用耦合:多应用通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
限流消峰:广泛应用于秒查或抢购活动中,避免某一刻流量过导致应用系统挂掉的情况;
目前使用较多的消息队列有 ActiveMQ 、RocketMQ 、RabbitMQ 和 Kafka 等。
消息队列的两种模式
消息队列包括两种模式:点对点模式 和 发布/订阅模式。
1)点对点模式
点对点模式下包括三个角色:
消息队列
发送者 (生产者)
接收者(消费者)

消息发送者生产消息发送到queue中,然后消息接收者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);
发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
2)发布/订阅模式
发布/订阅模式下包括三个角色:
角色主题(Topic)
发布者(Publisher)
订阅者(Subscriber)

发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
发布/订阅模式特点:
每个消息可以有多个订阅者;
发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
异步处理
具体场景:用户为了使用某个应用,进行注册,系统需要发送注册邮件和注册短信。
对于该流程有两种处理方式:并行和串行。
1)串行处理:写入注册信息后,先发送注册邮件,再发送注册短信。

这种方式下,需要等发送短信处理完成后才完成注册。
2)并行处理:写入注册信息后,同时处理发邮件和发短信。

这种方式下,需要等发送短信和发送邮件处理完成后才完成注册。
假设上面三个子系统处理耗时均为:50ms,且不考虑网络延迟,系统卡顿等因素,则总的处理时间为:
串行:50ms + 50ms + 50 ms = 150ms
并行:50ms + 50ms = 100ms
使用消息队列结果将如何呢?

若使用消息队列,写入完注册信息后,再将信息写入消息队列就能直接返回成功给客户端了,然后注册完成。
现在总的响应时间依赖于写入消息队列的时间,而写入消息队列的时间是很快的,基本可以忽略不计。因此总的处理时间相比串行提高了 2 倍,相比并行提高了 1 倍。
应用解耦
具体场景:A 系统每次产生数据时,都要将数据发给 BC 两个系统(通过接口调用)。这个时候新增了一个 D 系统,如下图:

在这个场景中,A 系统和其他几个系统乱七八糟的耦合在一起,当 A 系统中产生一条数据时,需要将数据发给各个系统。
每次项目中新增了系统,A 系统都需要修改代码,还要时刻担心那个系统挂掉了,信息没发送过去要不要重发,那个系统又不要该数据了,这时求 A 系统负责人的心理阴影...
如果使用 MQ,A 系统产生一条数据后,只需要插入到 MQ 里面去,那个系统需要就去 MQ 里消费。如果新增了一个系统,那么订阅 MQ 的消息即可;同理那个系统不再需要该数据,那么只要取消订阅就行了。

通过一个 MQ, Pub/Sub 发布订阅消息模型,A 系统就跟其他系统实现解耦了。
限流削峰
具体场景:某电商网站开展秒杀活动,一般由于瞬间访问暴增,服务器收到请求过大,可能出现无法处理请求或崩溃的情况。
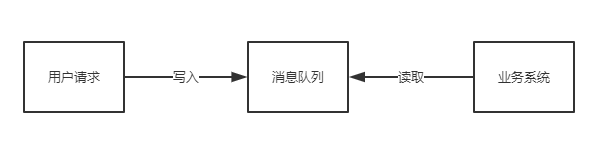
加入消息队列后,系统就可以从消息队列中读取数据,相当于做了一次缓冲,超出系统处理之外的请求会积压在消息队列中,等高峰期已过,就会快速将积压在队列中的数据处理完。
消息队列有什么优缺点
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?如何保证消息队列的高可用,可以点击这里查看。
系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已。
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。
RabbitMQ/ActiveMQ/RocketMQ/Kafka对比
这里列举了上述四种消息队列的差异对比(图片来源:https://www.cnblogs.com/javalyy/p/8856731.html):
图片来源(https://doocs.gitee.io/advanced-java/#/docs/high-concurrency/why-mq)
总结
一般业务系统要引入 MQ,最早大家都是用 ActiveMQ,但是现在大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,不推荐使用。
中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择,大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是高性能分布式、大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准。
广泛来说,电商、金融等对事务性要求很高的,可以考虑RabbitMQ和RocketMQ,对性能要求高的可考虑Kafka
赞赏码


非学,无以致疑;非问,无以广识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号