【面试】50道经典计算机网络面试题
1. HTTP 常用的请求方式,区别和用途?
-
GET: 发送请求,获取服务器数据
-
POST:向 URL 指定的资源提交数据
-
PUT:向服务器提交数据,以修改数据
-
HEAD: 请求页面的首部,获取资源的元信息
-
DELETE:删除服务器上的某些资源。
-
CONNECT:建立连接隧道,用于代理服务器;
-
OPTIONS:列出可对资源实行的请求方法,常用于跨域
-
TRACE:追踪请求 - 响应的传输路径
2. HTTP 常用的状态码及含义?
-
1xx:接受的请求正在处理 (信息性状态码)
-
2xx:表示请求正常处理完毕 (成功状态码)
-
3xx:表示重定向状态,需要重新请求 (重定向状态码)
-
4xx:服务器无法处理请求 (客户端错误状态码)
-
5xx:服务器处理请求出错 (服务端错误状态码)
常用状态码如下:
-
101 切换请求协议,从 HTTP 切换到 WebSocket
-
200 请求成功,表示正常返回信息。
-
301 永久重定向,会缓存
-
302 临时重定向,不会缓存
-
400 请求错误
-
403 服务器禁止访问
-
404 找不到与 URI 相匹配的资源。
-
500 常见的服务器端错误
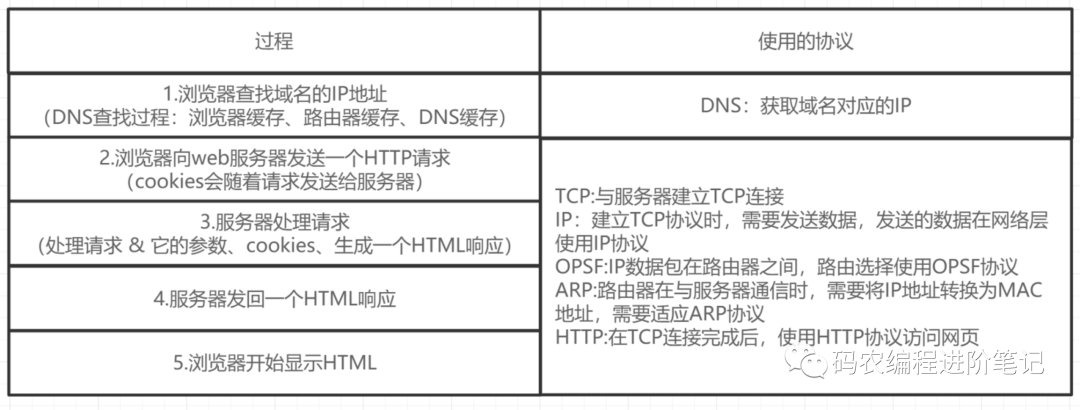
3. 从浏览器地址栏输入 url 到显示主页的过程
-
DNS 解析,查找真正的 ip 地址
-
与服务器建立 TCP 连接
-
发送 HTTP 请求
-
服务器处理请求并返回 HTTP 报文
-
浏览器解析渲染页面
-
连接结束
4. 如何理解 HTTP 协议是无状态的
每次 HTTP 请求都是独立的,无相关的,默认不需要保存上下文信息的。我们来看个便于理解的例子:
有状态:
-
A:今天吃啥子?
-
B:罗非鱼!
-
A:味道怎么样呀?
-
B:还不错,好香。
无状态:
A:今天吃啥子?
B:罗非鱼!
A:味道怎么样呀?
B:?啊?啥?什么鬼?什么味道怎么样?
加下 cookie 这玩意:
-
A:今天吃啥子?
-
B:罗非鱼
-
A:你今天吃的罗非鱼味道怎么样呀?
-
B:还不错,好香。
5. HTTP 1.0,1.1,2.0 的版本区别
HTTP 1.0
-
HTTP 1.0 规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个 TCP 连接,服务器完成请求处理后立即断开 TCP 连接。它也可以强制开启长链接,例如设置 Connection: keep-alive 这个字段
HTTP 1.1
-
引入了长连接,即 TCP 连接默认不关闭,可以被多个请求复用。
-
引入了管道机制(pipelining),即在同一个 TCP 连接里面,客户端可以同时发送多个请求。
-
缓存处理,引入了更多的缓存控制策略,如 Cache-Control、Etag/If-None-Match 等。
-
错误状态管理,新增了 24 个错误状态响应码,如 409 表示请求的资源与资源的当前状态发生冲突。
HTTP 2
-
采用了多路复用,即在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。
-
服务端推送,HTTP 2 允许服务器未经请求,主动向客户端发送资源
6. 说下计算机网络体系结构
计算机网路体系结构主要有 ISO 七层模型、TCP/IP 四层模型、五层体系结构
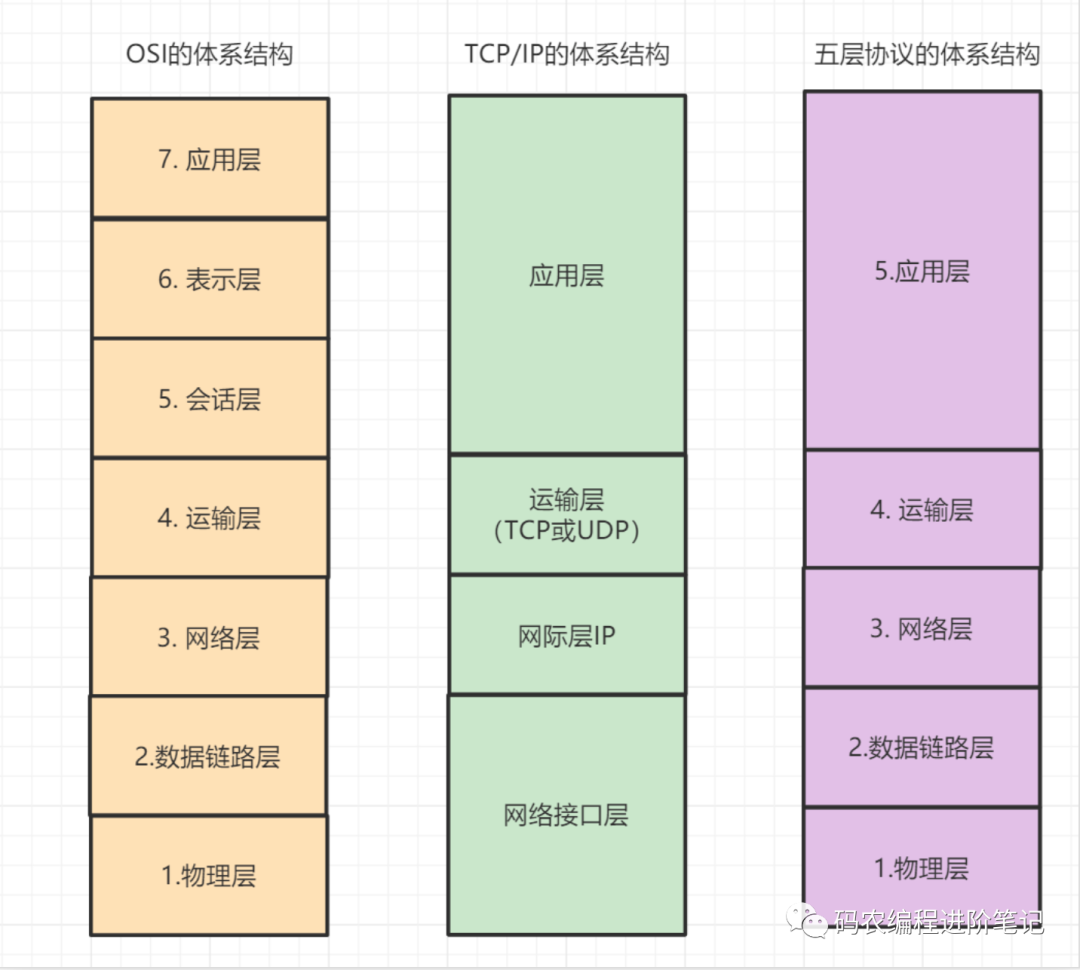
ISO 七层模型
ISO 七层模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。
-
应用层:网络服务与最终用户的一个接口,协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
-
表示层:数据的表示、安全、压缩。
-
会话层:建立、管理、终止会话。对应主机进程,指本地主机与远程主机正在进行的会话
-
传输层:定义传输数据的协议端口号,以及流控和差错校验。协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
-
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择。协议有:ICMP IGMP IP(IPV4 IPV6)
-
数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能。
-
物理层:建立、维护、断开物理连接。
TCP/IP 四层模型
-
应用层:对应于 OSI 参考模型的(应用层、表示层、会话层),为用户提供所需要的各种服务,例如:FTP、Telnet、DNS、SMTP 等
-
传输层:对应 OSI 的传输层,为应用层实体提供端到端的通信功能,保证了数据包的顺序传送及数据的完整性。定义了 TCP 和 UDP 两层协议。
-
网际层:对应于 OSI 参考模型的网络层,主要解决主机到主机的通信问题。三个主要协议:网际协议(IP)、互联网组管理协议(IGMP)和互联网控制报文协议(ICMP)
-
网络接口层:与 OSI 参考模型的数据链路层、物理层对应。它负责监视数据在主机和网络之间的交换。
五层体系结构
-
应用层:通过应用进程间的交互来完成特定网络应用。对应于 OSI 参考模型的(应用层、表示层、会话层),应用层协议很多,如域名系统 DNS,HTTP 协议,支持电子邮件的 SMTP 协议等等。我们把应用层交互的数据单元称为报文。
-
传输层:负责向两台主机进程之间的通信提供通用的数据传输服务。对应 OSI 参考模型的传输层,协议有传输控制协议 TCP 和 用户数据协议 UDP。
-
网络层:对应 OSI 参考模型的的网络层
-
数据链路层:对应 OSI 参考模型的的数据链路层
-
物理层:对应 OSI 参考模型的的物理层层。在物理层上所传送的数据单位是比特。物理层 (physical layer) 的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。
7. POST 和 GET 有哪些区别?
-
请求参数:GET 把参数包含在 URL 中,用 & 连接起来;POST 通过 request body 传递参数。
-
请求缓存:GET 请求会被主动 Cache,而 POST 请求不会,除非手动设置。
-
收藏为书签:GET 请求支持收藏为书签,POST 请求不支持。
-
安全性:POST 比 GET 安全,GET 请求在浏览器回退时是无害的,而 POST 会再次请求。
-
历史记录:GET 请求参数会被完整保留在浏览历史记录里,而 POST 中的参数不会被保留。
-
编码方式:GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
-
参数数据类型:GET 只接受 ASCII 字符,而 POST 没有限制数据类型。
-
数据包: GET 产生一个 TCP 数据包;POST 可能产生两个 TCP 数据包。
8. 在交互过程中如果数据传送完了,还不想断开连接怎么办,怎么维持?
在 HTTP 中响应体的 Connection 字段指定为 keep-alive
9. HTTP 如何实现长连接?在什么时候会超时?
HTTP 如何实现长连接?
-
HTTP 分为长连接和短连接,其实本质上说的是 TCP 的长短连接。TCP 连接是一个双向的通道,它是可以保持一段时间不关闭的,因此 TCP 连接才有真正的长连接和短连接这一个说法。
-
长连接是指的是 TCP 连接,而不是 HTTP 连接。
-
TCP 长连接可以复用一个 TCP 连接来发起多次 HTTP 请求,这样可以减少资源消耗,比如一次请求 HTML,短连接可能还需要请求后续的 JS/CSS/ 图片等
要实现 HTTP 长连接,在响应头设置 Connection 为 keep-alive,HTTP1.1 默认是长连接,而 HTTP 1.0 协议也支持长连接,但是默认是关闭的。
在什么时候会超时呢?
-
HTTP 一般会有 httpd 守护进程,里面可以设置 keep-alive timeout,当 tcp 链接闲置超过这个时间就会关闭,也可以在 HTTP 的 header 里面设置超时时间
-
TCP 的 keep-alive 包含三个参数,支持在系统内核的 net.ipv4 里面设置:当 TCP 连接之后,闲置了 tcp_keepalive_time,则会发生侦测包,如果没有收到对方的 ACK,那么会每隔 tcp_keepalive_intvl 再发一次,直到发送了 tcp_keepalive_probes,就会丢弃该连接。
-
tcp_keepalive_intvl = 15
-
tcp_keepalive_probes = 5
-
tcp_keepalive_time = 1800
10. 讲一下 HTTP 与 HTTPS 的区别。
HTTP,超文本传输协议,英文是 Hyper Text Transfer Protocol,是一个基于 TCP/IP 通信协议来传递数据的协议。HTTP 存在这几个问题:
-
请求信息明文传输,容易被窃听截取。
-
数据的完整性未校验,容易被篡改
-
没有验证对方身份,存在冒充危险
HTTPS 就是为了解决 HTTP 存在问题的。HTTPS,英文是 HyperText Transfer Protocol over Secure Socket Layer,可以这么理解 Https 是身披 SSL (Secure Socket Layer) 的 HTTP,即 HTTPS 协议 = HTTP+SSL/TLS。通过 SSL 证书来验证服务器的身份,并为浏览器和服务器之间的传输数据进行加密。
它们主要区别:
-
数据是否加密: Http 是明文传输,HTTPS 是密文
-
默认端口: Http 默认端口是 80,Https 默认端口是 443
-
资源消耗:和 HTTP 通信相比,Https 通信会消耗更多的 CPU 和内存资源,因为需要加解密处理;
-
安全性: http 不安全,https 比较安全。
11 . Https 流程是怎样的?
-
HTTPS = HTTP + SSL/TLS,即用 SSL/TLS 对数据进行加密和解密,Http 进行传输。
-
SSL,即 Secure Sockets Layer(安全套接层协议),是网络通信提供安全及数据完整性的一种安全协议。
-
TLS,即 Transport Layer Security (安全传输层协议),它是 SSL 3.0 的后续版本。
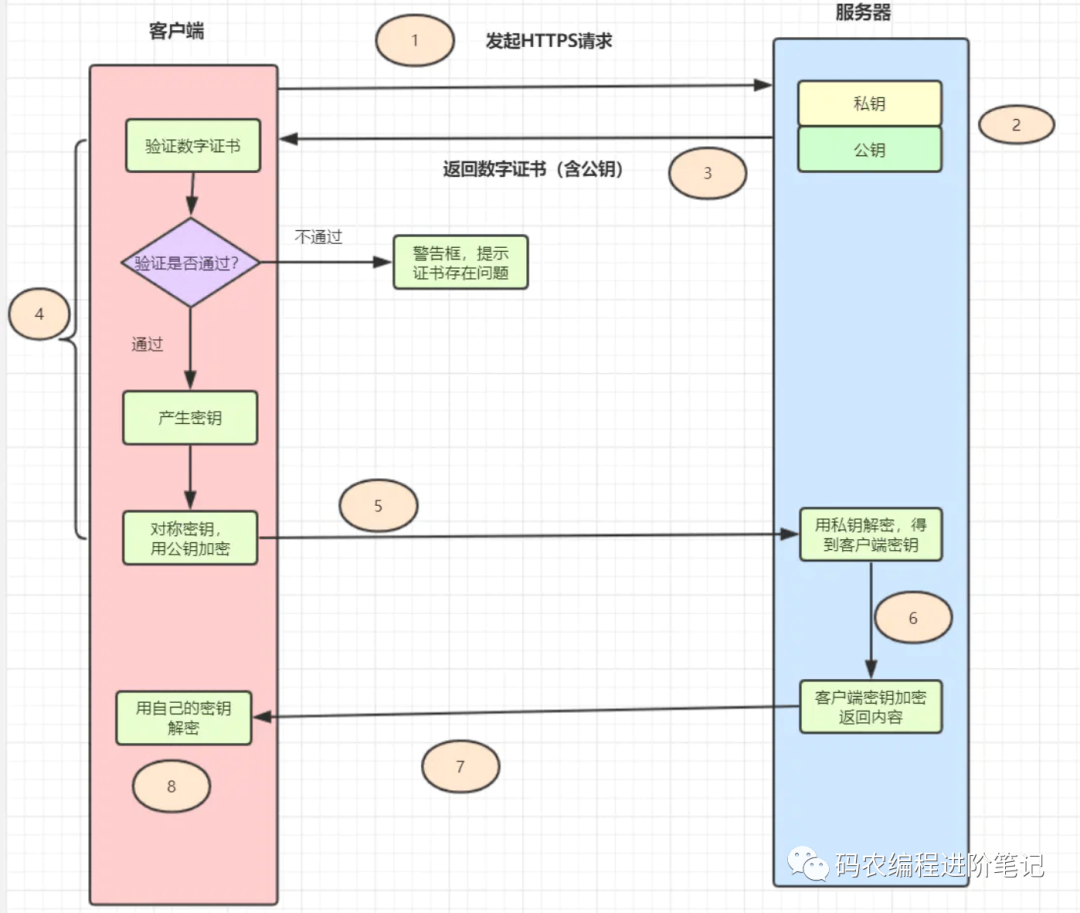
-
用户在浏览器里输入一个 https 网址,然后连接到 server 的 443 端口。
-
服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过。这套证书其实就是一对公钥和私钥。
-
服务器将自己的数字证书(含有公钥)发送给客户端。
-
客户端收到服务器端的数字证书之后,会对其进行检查,如果不通过,则弹出警告框。如果证书没问题,则生成一个密钥(对称加密),用证书的公钥对它加密。
-
客户端会发起 HTTPS 中的第二个 HTTP 请求,将加密之后的客户端密钥发送给服务器。
-
服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后得到客户端密钥,然后用客户端密钥对返回数据进行对称加密,这样数据就变成了密文。
-
服务器将加密后的密文返回给客户端。
-
客户端收到服务器发返回的密文,用自己的密钥(客户端密钥)对其进行对称解密,得到服务器返回的数据。
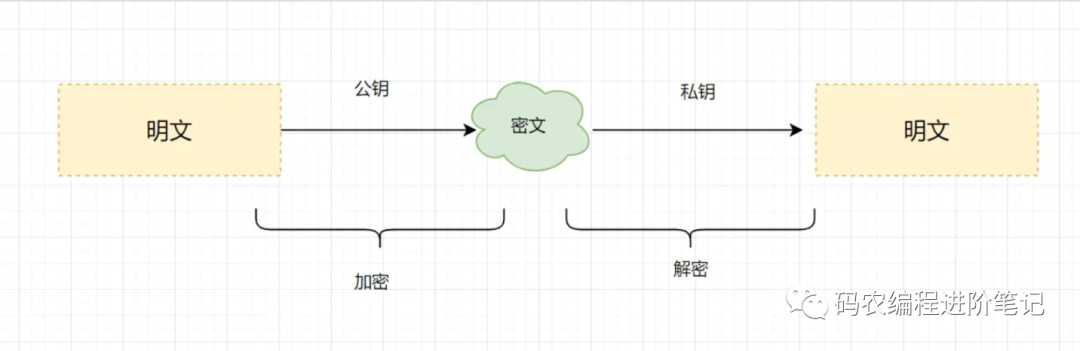
12. 对称加密与非对称加密有什么区别
对称加密:加密和解密使用相同密钥的加密算法。
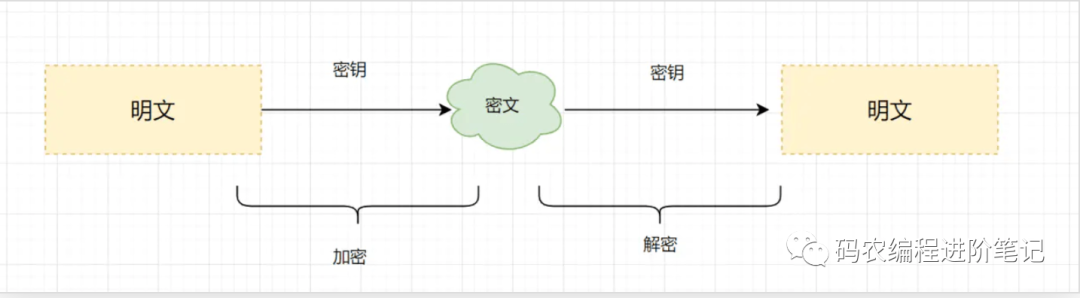
非对称加密:非对称加密算法需要两个密钥(公开密钥和私有密钥)。公钥与私钥是成对存在的,如果用公钥对数据进行加密,只有对应的私钥才能解密。
13. 什么是 XSS 攻击,如何避免?
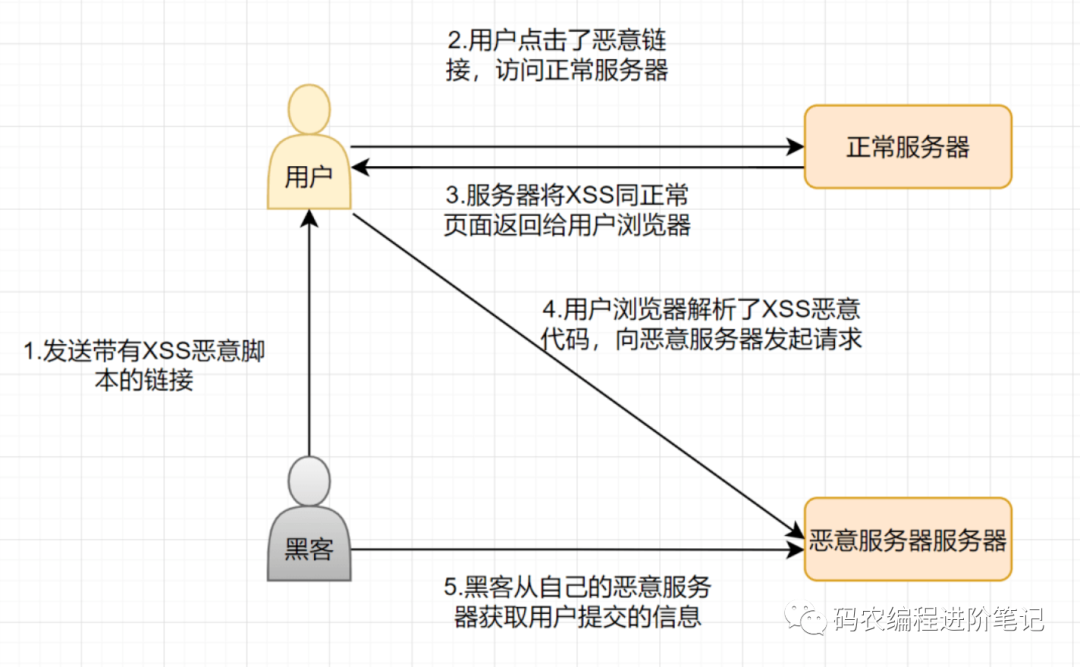
XSS 攻击,全称跨站脚本攻击(Cross-Site Scripting),这会与层叠样式表 (Cascading Style Sheets, CSS) 的缩写混淆,因此有人将跨站脚本攻击缩写为 XSS。它指的是恶意攻击者往 Web 页面里插入恶意 html 代码,当用户浏览该页之时,嵌入其中 Web 里面的 html 代码会被执行,从而达到恶意攻击用户的特殊目的。XSS 攻击一般分三种类型:存储型 、反射型 、DOM 型 XSS
XSS 是如何攻击的?
拿反射型举个例子吧,流程图如下:
如何解决 XSS 攻击问题
-
不相信用户的输入,对输入进行过滤,过滤标签等,只允许合法值。
-
HTML 转义
-
对于链接跳转,如 <a href="xxx" 等,要校验内容,禁止以 script 开头的非法链接。
-
限制输入长度等等
14. 请详细介绍一下 TCP 的三次握手机制
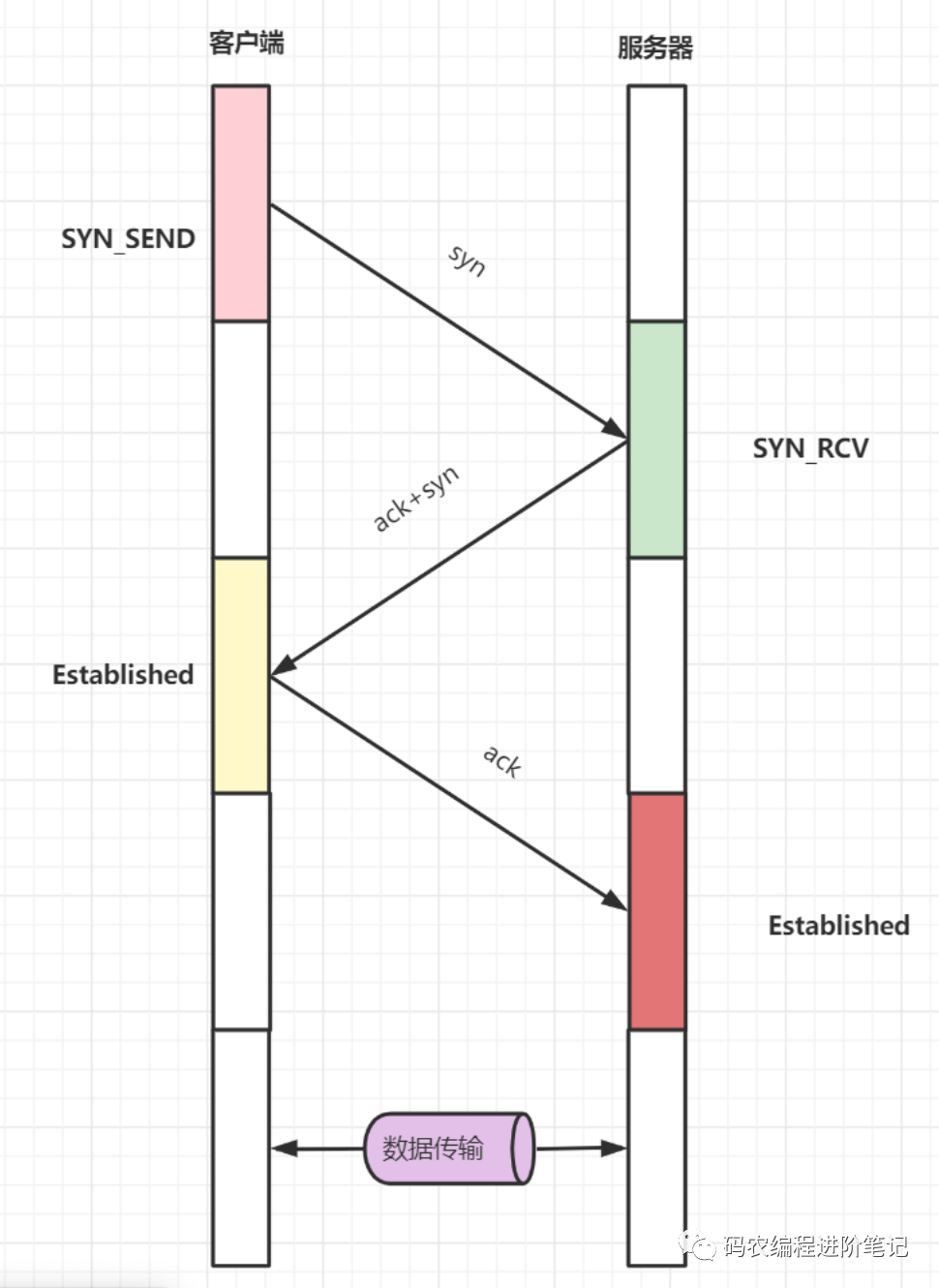
开始客户端和服务器都处于 CLOSED 状态,然后服务端开始监听某个端口,进入 LISTEN 状态
-
第一次握手 (SYN=1, seq=x),发送完毕后,客户端进入 SYN_SEND 状态
-
第二次握手 (SYN=1, ACK=1, seq=y, ACKnum=x+1), 发送完毕后,服务器端进入 SYN_RCV 状态。
-
第三次握手 (ACK=1,ACKnum=y+1),发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时
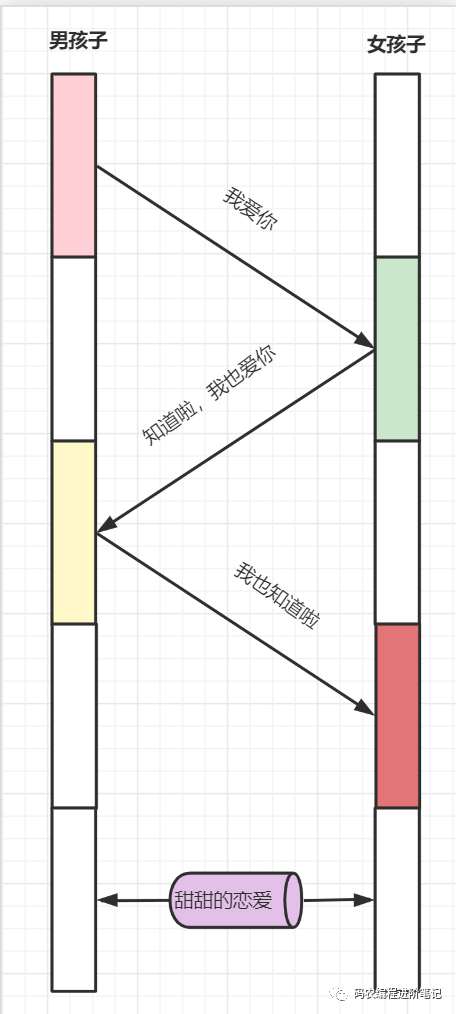
15. TCP 握手为什么是三次,不能是两次?不能是四次?
TCP 握手为什么是三次呢?为了方便理解,我们以谈恋爱为个例子:两个人能走到一起,最重要的事情就是相爱,就是我爱你,并且我知道,你也爱我,接下来我们以此来模拟三次握手的过程:
为什么握手不能是两次呢?
如果只有两次握手,女孩子可能就不知道,她的那句我也爱你,男孩子是否收到,恋爱关系就不能愉快展开。
为什么握手不能是四次呢?
因为握手不能是四次呢?因为三次已经够了,三次已经能让双方都知道:你爱我,我也爱你。而四次就多余了。
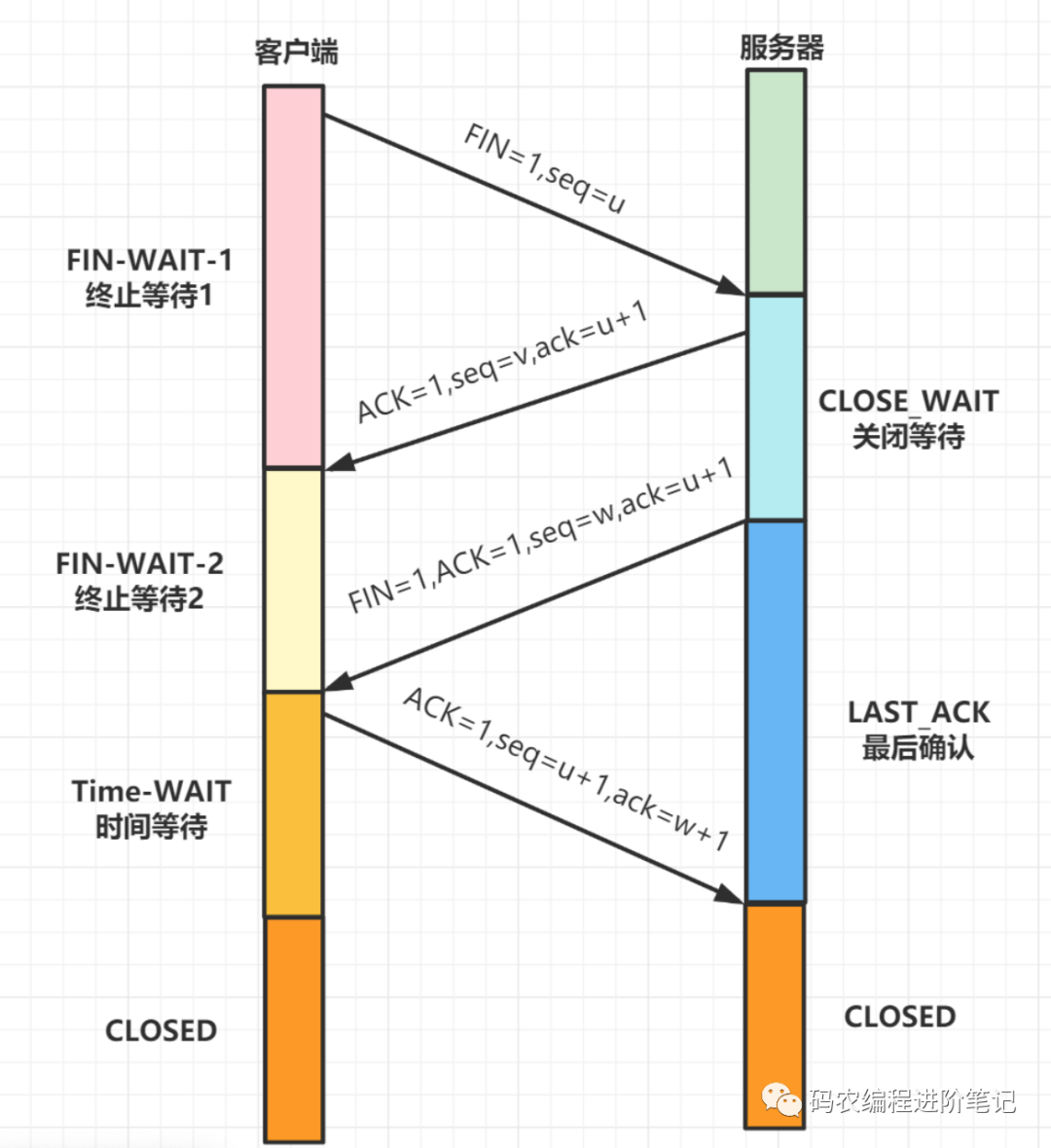
16. TCP 四次挥手过程?
-
第一次挥手 (FIN=1,seq=u),发送完毕后,客户端进入 FIN_WAIT_1 状态
-
第二次挥手 (ACK=1,ack=u+1,seq =v),发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态
-
第三次挥手 (FIN=1,ACK1,seq=w,ack=u+1),发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个 ACK。
-
第四次挥手 (ACK=1,seq=u+1,ack=w+1),客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT 状态,等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
17. TCP 四次挥手过程中,客户端为什么需要等待 2MSL, 才进入 CLOSED 状态
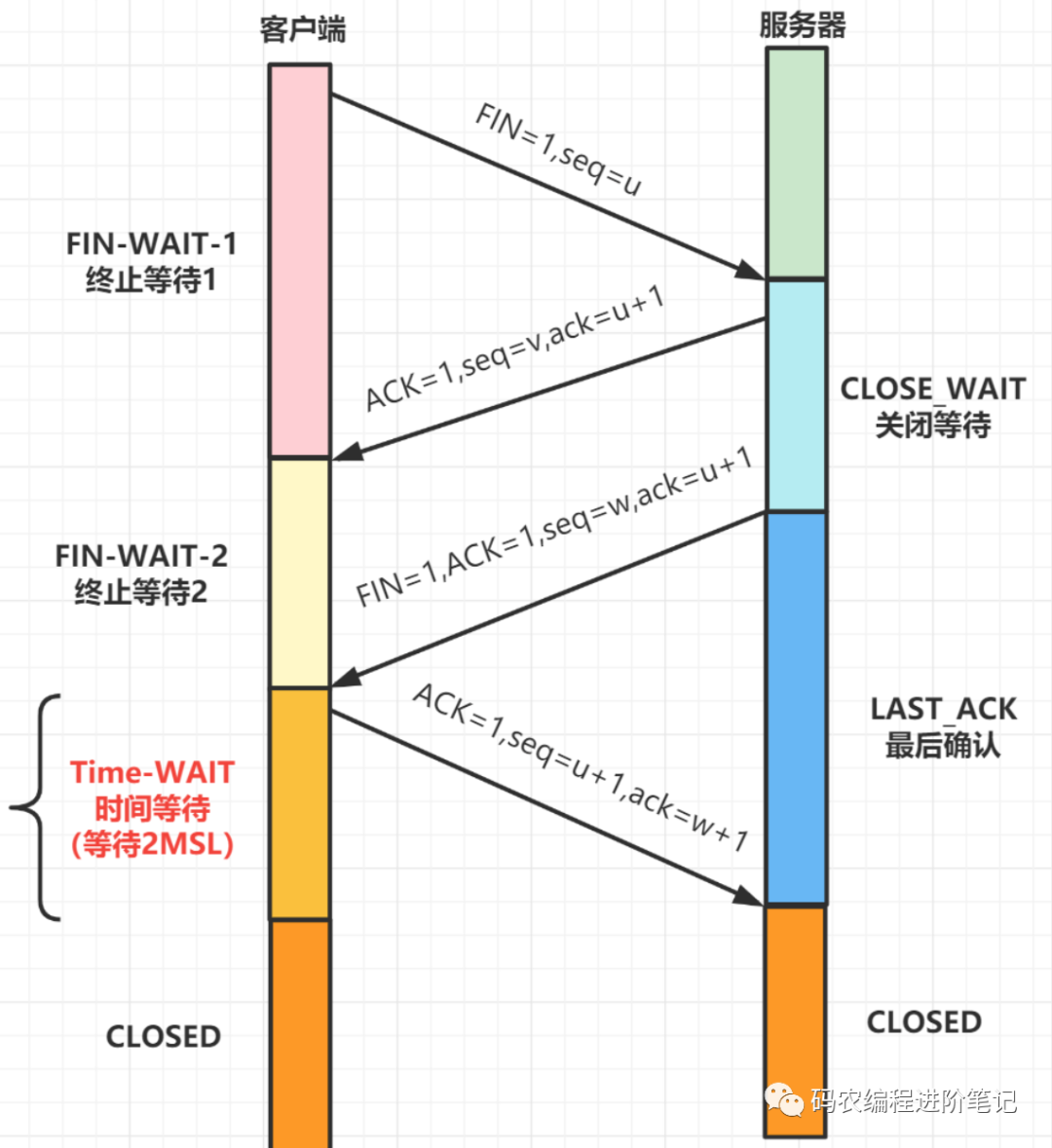
2MSL,2 Maximum Segment Lifetime,即两个最大段生命周期
-
1 个 MSL 保证四次挥手中主动关闭方最后的 ACK 报文能最终到达对端
-
1 个 MSL 保证对端没有收到 ACK 那么进行重传的 FIN 报文能够到达
18. 为什么需要四次挥手?
举个例子吧
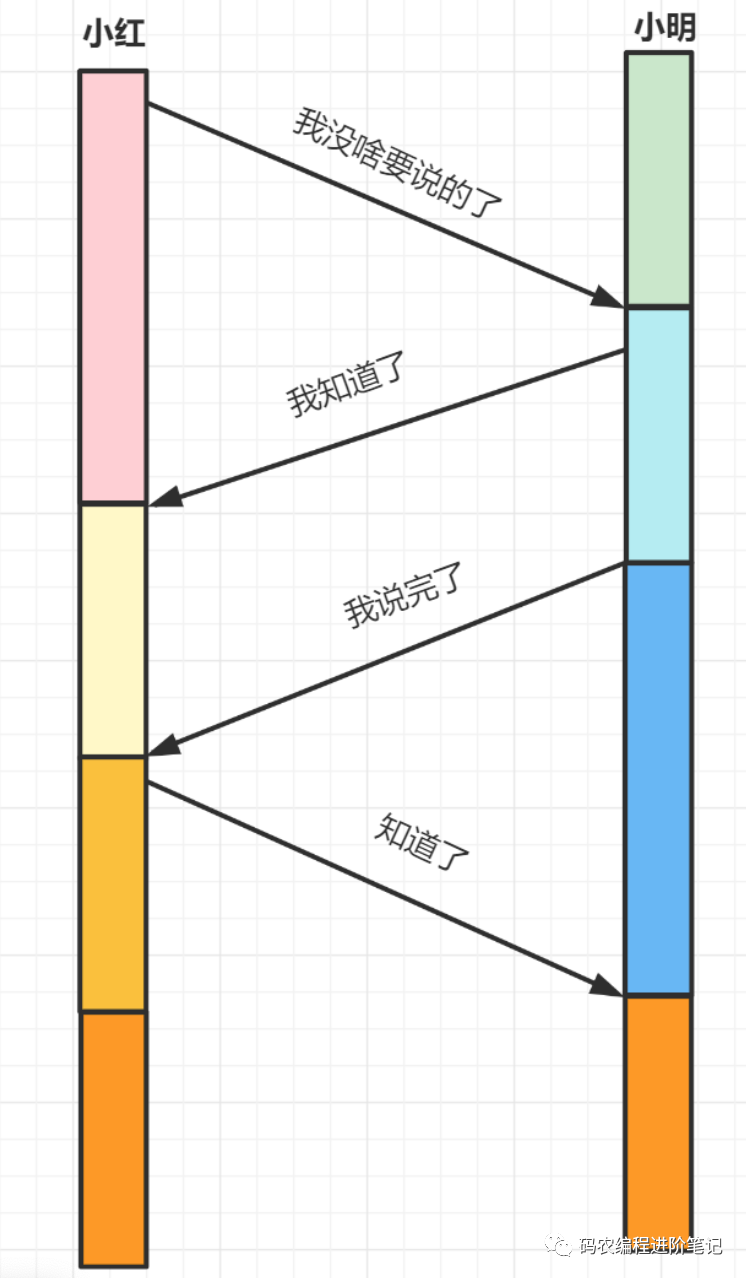
小明和小红打电话聊天,通话差不多要结束时,小红说 “我没啥要说的了”,小明回答 “我知道了”。但是小明可能还会有要说的话,小红不能要求小明跟着自己的节奏结束通话,于是小明可能又叽叽歪歪说了一通,最后小明说 “我说完了”,小红回答 “知道了”,这样通话才算结束。
19. Session 和 Cookie 的区别。
我们先来看 Session 和 Cookie 的定义:
-
Cookie 是服务器发送到用户浏览器,并保存在浏览器本地的一小块文本串数据。它会在浏览器下次向同一服务器再发起请求时,被携带发送到服务器。通常,它用于告知服务端两个请求是否来自同一浏览器,一样用于保持用户的登录状态等。Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
-
session 指的就是服务器和客户端一次会话的过程。Session 利用 Cookie 进行信息处理的,当用户首先进行了请求后,服务端就在用户浏览器上创建了一个 Cookie,当这个 Session 结束时,其实就是意味着这个 Cookie 就过期了。Session 对象存储着特定用户会话所需的属性及配置信息。
Session 和 Cookie 到底有什么不同呢?
-
存储位置不一样,Cookie 保存在客户端,Session 保存在服务器端。
-
存储数据类型不一样,Cookie 只能保存 ASCII,Session 可以存任意数据类型,一般情况下我们可以在 Session 中保持一些常用变量信息,比如说 UserId 等。
-
有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般有效时间较短,客户端关闭或者 Session 超时都会失效。
-
隐私策略不同,Cookie 存储在客户端,比较容易遭到不法获取,早期有人将用户的登录名和密码存储在 Cookie 中导致信息被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
-
存储大小不同, 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie。
来看个图吧:

-
用户第一次请求服务器时,服务器根据用户提交的信息,创建对应的 Session ,请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器,浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名。
-
当用户第二次访问服务器时,请求会自动判断此域名下是否存在 Cookie 信息,如果存在,则自动将 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。
20. TCP 是如何保证可靠性的
-
首先,TCP 的连接是基于三次握手,而断开则是四次挥手。确保连接和断开的可靠性。
-
其次,TCP 的可靠性,还体现在有状态 ;TCP 会记录哪些数据发送了,哪些数据被接受了,哪些没有被接受,并且保证数据包按序到达,保证数据传输不出差错。
-
再次,TCP 的可靠性,还体现在可控制。它有数据包校验、ACK 应答、超时重传 (发送方)、失序数据重传(接收方)、丢弃重复数据、流量控制(滑动窗口)和拥塞控制等机制。
21. TCP 和 UDP 的区别
-
TCP 面向连接((如打电话要先拨号建立连接);UDP 是无连接的,即发送数据之前不需要建立连接。
-
TCP 要求安全性,提供可靠的服务,通过 TCP 连接传送的数据,不丢失、不重复、安全可靠。而 UDP 尽最大努力交付,即不保证可靠交付。
-
TCP 是点对点连接的,UDP 一对一,一对多,多对多都可以
-
TCP 传输效率相对较低,而 UDP 传输效率高,它适用于对高速传输和实时性有较高的通信或广播通信。
-
TCP 适合用于网页,邮件等;UDP 适合用于视频,语音广播等
-
TCP 面向字节流,UDP 面向报文
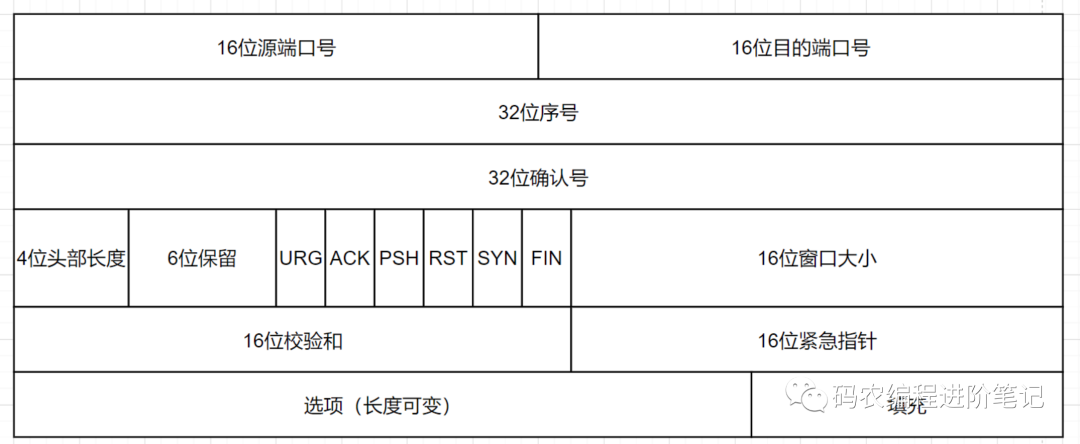
22. TCP 报文首部有哪些字段,说说其作用
-
16 位端口号:源端口号,主机该报文段是来自哪里;目标端口号,要传给哪个上层协议或应用程序
-
32 位序号:一次 TCP 通信(从 TCP 连接建立到断开)过程中某一个传输方向上的字节流的每个字节的编号。
-
32 位确认号:用作对另一方发送的 tcp 报文段的响应。其值是收到的 TCP 报文段的序号值加 1。
-
4 位头部长度:表示 tcp 头部有多少个 32bit 字(4 字节)。因为 4 位最大能标识 15,所以 TCP 头部最长是 60 字节。
-
6 位标志位:URG (紧急指针是否有效),ACk(表示确认号是否有效),PSH(缓冲区尚未填满),RST(表示要求对方重新建立连接),SYN(建立连接消息标志接),FIN(表示告知对方本端要关闭连接了)
-
16 位窗口大小:是 TCP 流量控制的一个手段。这里说的窗口,指的是接收通告窗口。它告诉对方本端的 TCP 接收缓冲区还能容纳多少字节的数据,这样对方就可以控制发送数据的速度。
-
16 位校验和:由发送端填充,接收端对 TCP 报文段执行 CRC 算法以检验 TCP 报文段在传输过程中是否损坏。注意,这个校验不仅包括 TCP 头部,也包括数据部分。这也是 TCP 可靠传输的一个重要保障。
-
16 位紧急指针:一个正的偏移量。它和序号字段的值相加表示最后一个紧急数据的下一字节的序号。因此,确切地说,这个字段是紧急指针相对当前序号的偏移,不妨称之为紧急偏移。TCP 的紧急指针是发送端向接收端发送紧急数据的方法。
23. HTTP 状态码 301 和 302 的区别?
-
301(永久移动)请求的网页已被永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
-
302:(临时移动)服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。
HTTP 状态码 301 与 302 的区别:
-
它们之间关键区别在,资源是否存在有效性;
-
301 资源还在只是换了一个位置,返回的是新位置的内容;
-
302 资源暂时失效,返回的是一个临时的代替页上。
24. 聊聊 TCP 的重传机制
超时重传
TCP 为了实现可靠传输,实现了重传机制。最基本的重传机制,就是超时重传,即在发送数据报文时,设定一个定时器,每间隔一段时间,没有收到对方的 ACK 确认应答报文,就会重发该报文。
这个间隔时间,一般设置为多少呢?我们先来看下什么叫 RTT(Round-Trip Time,往返时间)。
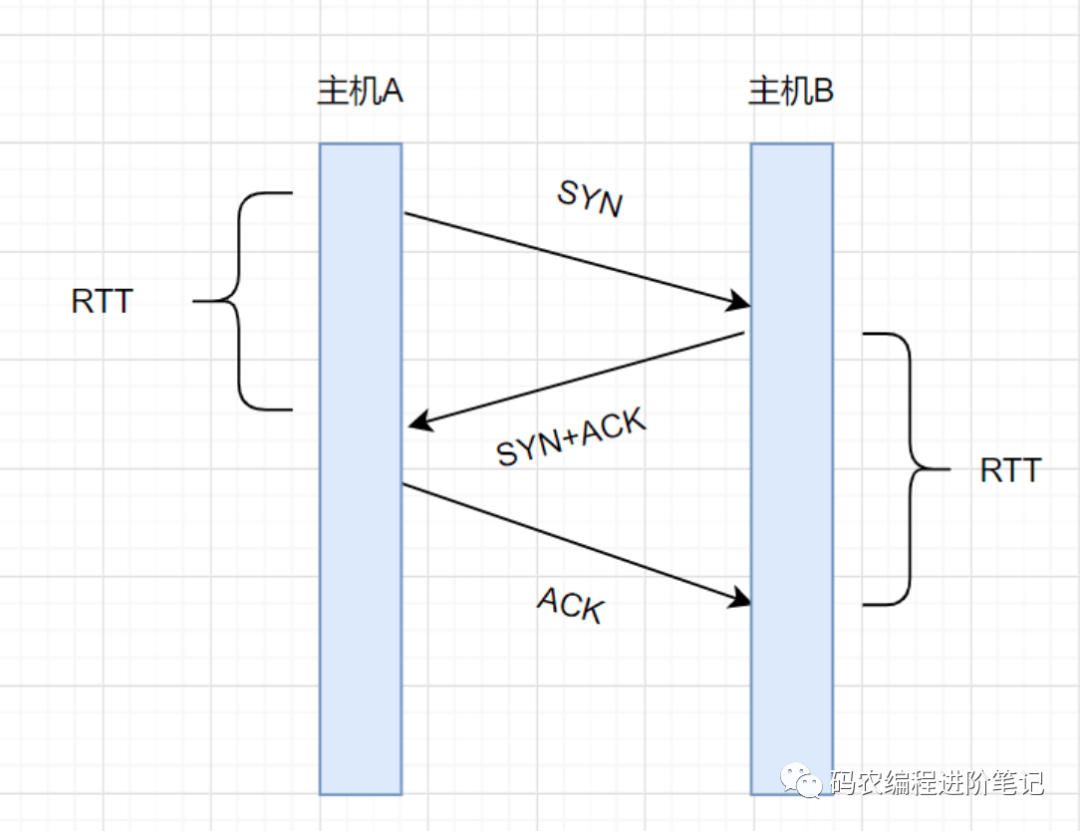
RTT 就是,一个数据包从发出去到回来的时间,即数据包的一次往返时间。超时重传时间,就是 Retransmission Timeout ,简称 RTO。
RTO 设置多久呢?
-
如果 RTO 比较小,那很可能数据都没有丢失,就重发了,这会导致网络阻塞,会导致更多的超时出现。
-
如果 RTO 比较大,等到花儿都谢了还是没有重发,那效果就不好了。
一般情况下,RTO 略大于 RTT,效果是最好的。一些小伙伴会问,超时时间有没有计算公式呢?有的!有个标准方法算 RTO 的公式,也叫 Jacobson / Karels 算法。我们一起来看下计算 RTO 的公式
1. 先计算 SRTT(计算平滑的 RTT)
SRTT = (1 - α) * SRTT + α * RTT //求 SRTT 的加权平均
2. 再计算 RTTVAR (round-trip time variation)
RTTVAR = (1 - β) * RTTVAR + β * (|RTT - SRTT|) //计算 SRTT 与真实值的差距3. 最终的 RTO
RTO = µ * SRTT + ∂ * RTTVAR = SRTT + 4·RTTVAR 其中,α = 0.125,β = 0.25, μ = 1,∂ = 4,这些参数都是大量结果得出的最优参数。
但是,超时重传会有这些缺点:
-
当一个报文段丢失时,会等待一定的超时周期然后才重传分组,增加了端到端的时延。
-
当一个报文段丢失时,在其等待超时的过程中,可能会出现这种情况:其后的报文段已经被接收端接收但却迟迟得不到确认,发送端会认为也丢失了,从而引起不必要的重传,既浪费资源也浪费时间。
并且,TCP 有个策略,就是超时时间间隔会加倍。超时重传需要等待很长时间。因此,还可以使用快速重传机制。
快速重传
快速重传机制,它不以时间驱动,而是以数据驱动。它基于接收端的反馈信息来引发重传。
一起来看下快速重传流程:
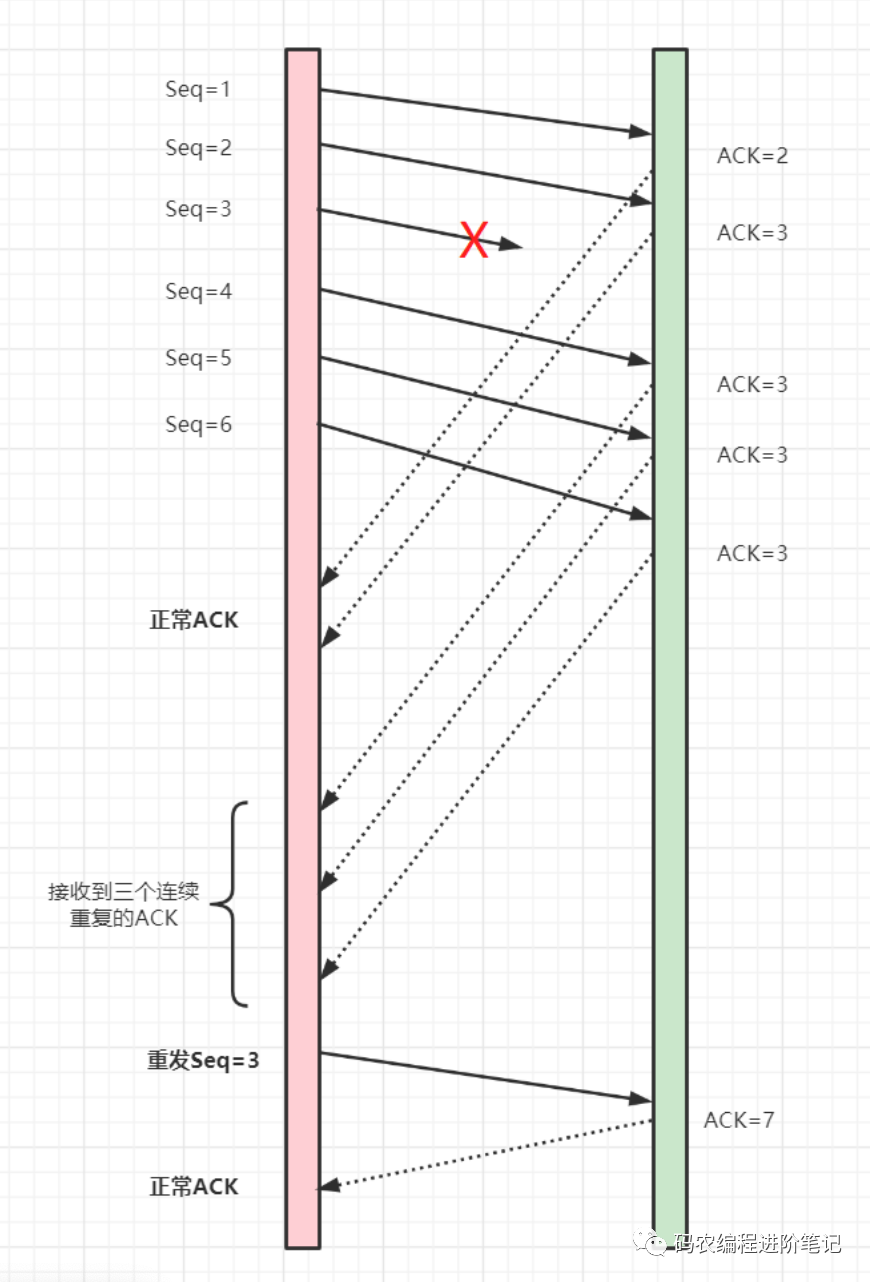
发送端发送了 1,2,3,4,5,6 份数据:
-
第一份 Seq=1 先送到了,于是就 Ack 回 2;
-
第二份 Seq=2 也送到了,假设也正常,于是 ACK 回 3;
-
第三份 Seq=3 由于网络等其他原因,没送到;
-
第四份 Seq=4 也送到了,但是因为 Seq3 没收到。所以 ACK 回 3;
-
后面的 Seq=4,5 的也送到了,但是 ACK 还是回复 3,因为 Seq=3 没收到。
-
发送端连着收到三个重复冗余 ACK=3 的确认(实际上是 4 个,但是前面一个是正常的 ACK,后面三个才是重复冗余的),便知道哪个报文段在传输过程中丢失了,于是在定时器过期之前,重传该报文段。
-
最后,接收到收到了 Seq3,此时因为 Seq=4,5,6 都收到了,于是 ACK 回 7.
但快速重传还可能会有个问题:ACK 只向发送端告知最大的有序报文段,到底是哪个报文丢失了呢?并不确定!那到底该重传多少个包呢?
是重传 Seq3 呢?还是重传 Seq3、Seq4、Seq5、Seq6 呢?因为发送端并不清楚这三个连续的 ACK3 是谁传回来的。
带选择确认的重传(SACK)
为了解决快速重传的问题:应该重传多少个包 ? TCP 提供了 SACK 方法(带选择确认的重传,Selective Acknowledgment)。
SACK 机制就是,在快速重传的基础上,接收端返回最近收到的报文段的序列号范围,这样发送端就知道接收端哪些数据包没收到,酱紫就很清楚该重传哪些数据包啦。SACK 标记是加在 TCP 头部选项字段里面的。
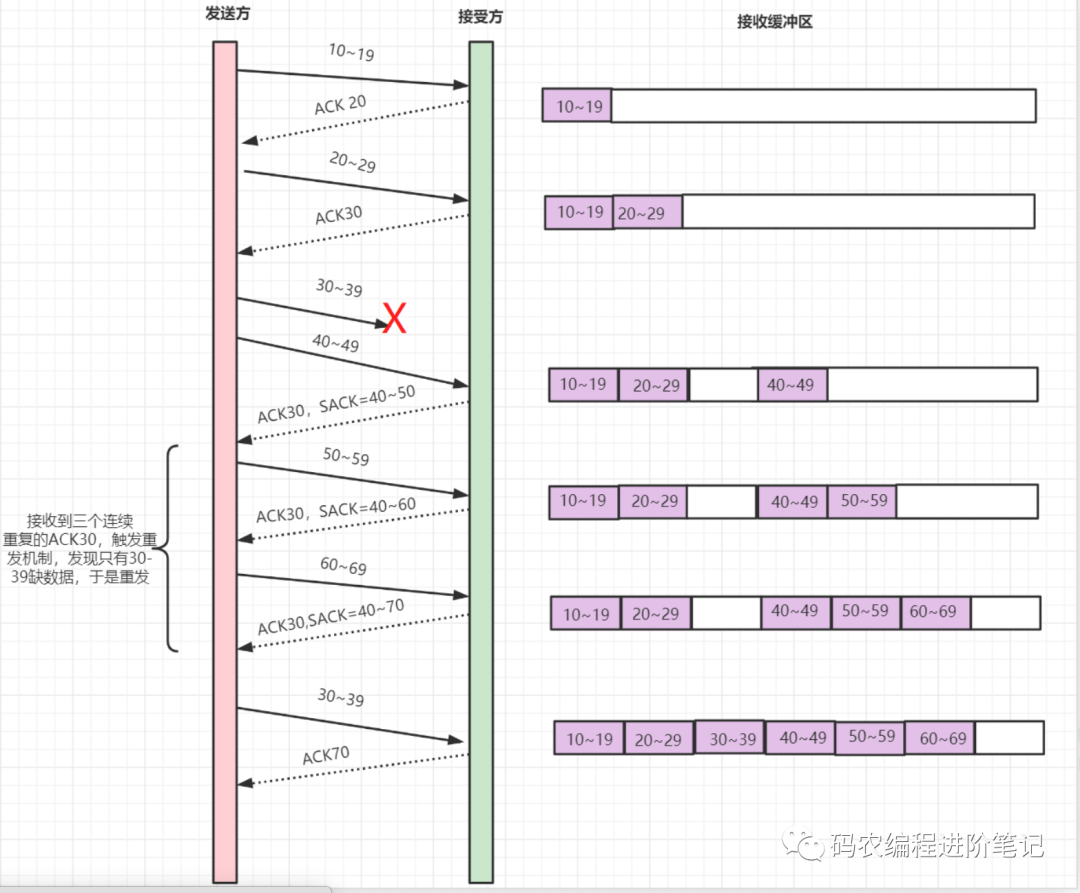
如上图中,发送端收到了三次同样的 ACK=30 的确认报文,于是就会触发快速重发机制,通过 SACK 信息发现只有 30~39 这段数据丢失,于是重发时就只选择了这个 30~39 的 TCP 报文段进行重发。
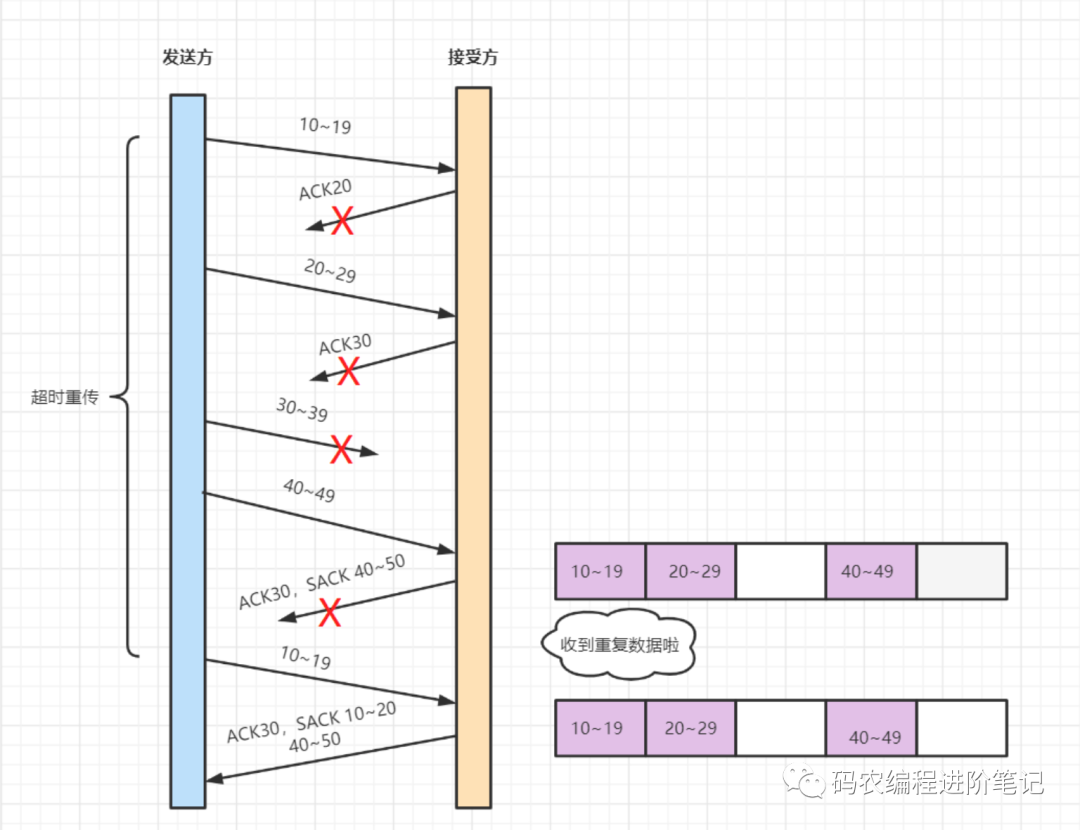
D-SACK
D-SACK,即 Duplicate SACK(重复 SACK),在 SACK 的基础上做了一些扩展,,主要用来告诉发送方,有哪些数据包自己重复接受了。DSACK 的目的是帮助发送方判断,是否发生了包失序、ACK 丢失、包重复或伪重传。让 TCP 可以更好的做网络流控。来看个图吧:
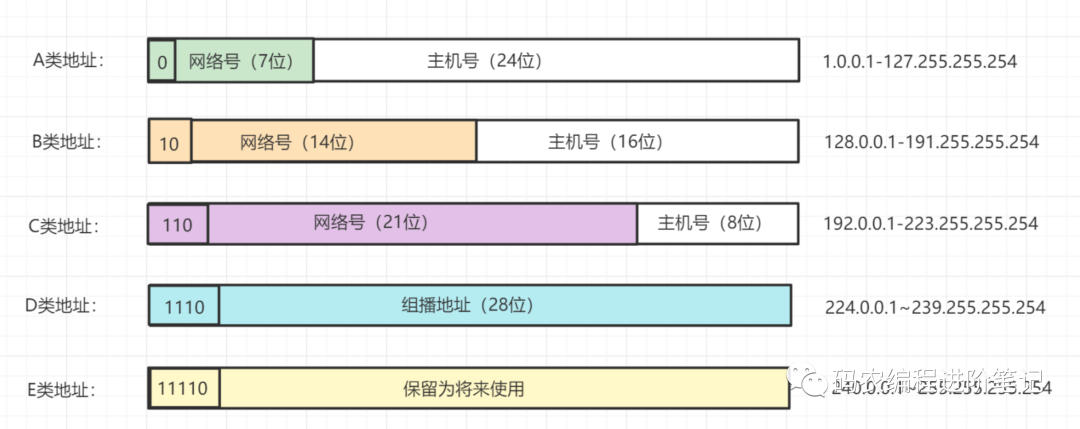
25. IP 地址有哪些分类?
一句话概括,IP 地址 = 网络号 + 主机号。
-
网络号:它标志主机(或路由器)所连接到的网络,网络地址表示属于互联网的哪一个网络
-
主机号:它标志该主机(或路由器),主机地址表示其属于该网络中的哪一台主机
IP 地址 分为 A,B,C,D,E 五大类:
-
A 类地址 (1~126):以 0 开头,网络号占前 8 位,主机号占后 24 位。
-
B 类地址 (128~191):以 10 开头,网络号占前 16 位,主机号占后 16 位。
-
C 类地址 (192~223):以 110 开头,网络号占前 24 位,主机号占后 8 位。
-
D 类地址 (224~239):以 1110 开头,保留位多播地址。
-
E 类地址 (240~255):以 11110 开头,保留位为将来使用
链接:https://learnku.com/articles/59484

赞赏码


非学,无以致疑;非问,无以广识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号