牛客网算法工程师能力评估
牛客网算法工程师能力评估
题目来源:https://www.nowcoder.com/test/200/summary
1、递归算法x(x(8))需要调用几次函数x(int n)?
class program
{
static void Main(string[] args)
{
int i;
i = x(x(8));
}
static int x(int n)
{
if (n <= 3)
return 1;
else
return x(n - 2) + x(n - 4) + 1;
}
}
A、9 B、12 C、18 D、24
选C。根据题意,易得x(3) = x(2) = x(1) = x(0) = 1
x(8) = x(6) +x(4) +1
= x(4) + x(2) +1 + x(2) + x(0) +1 + 1
= x(2) + x(0) +1 + 1 + 1 +1 + 1 +1 + 1
= 9
x(8) 这个就调用了9次函数x(int n),同理可得x(9)也是调用了9次,函数x(int n)所以总共18次。
2、下列关于数的宽度优先搜索算法描述错误的是?
A、从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止
B、常采用先进后出的栈来实现算法
C、空间的复杂度为O(V+E),因为所有节点都必须被储存,其中V是节点的数量,E是边的数量
D、时间复杂度为O(V+E),因为必须寻找所有到可能节点的所有路径,其中V是节点的数量,E是边的数量
选B。为了让先搜索结点的邻结点也先搜索,只能使用先进先出的队列的思想。宽度优先搜索算法常用于图。
3、在有序表(12,24,36,48,60,72,84)中二分查找关键字72时所需进行的关键字比较次数是多少?
A、1 B、2 C、3 D、4
选B。正确的二分查找应该是一次折半后,high=middle-1 或者 low=middle+1;所以第一次查找时 high=6,low=0; middle= 0+6/2 = 3,即48;第二次查找时 high=6, low =3+1; middle = 4+(6-4)/2 = 5,即72,查出所找关键字,故答案为B、2次
4、下面关于B-和B+树的叙述中,不正确的是
A、B-树和B+树都是平衡的多叉树
B、B-树和B+树都可用于文件的索引结构
C、B-树和B+树都能有效地支持顺序检索
D、B-树和B+树都能有效地支持随机检索
选C。B树的定义是这样的,一棵m阶的B树满足下列条件:(1)每个结点至多有m棵子树;(2)除根结点外,其他每个非叶子结点至少有m/2棵子树;(3)若根结点不是叶子结点,则至少有两棵子树;(4)所有叶结点在同一层上。B树的叶结点可以看成一种外部结点,不包含任何信息;(5)所有的非叶子结点中包含的信息数据为:(n,p0,k1,p1,k2,P2,…,kj-1,Pj-1)其中,ki为关键字,且满足kiki+1;pi为指向子树根结点的指针,并且Pi-1所指的子树中的所有结点的关键字均小于ki,Pj-1所指的子树中的所有结点的关键字均大于kj-1。B+树是应文件系统所需而出现的一种B树的变型树,其主要区别是一棵非叶子结点有n个子树就有n个关键字,这些关键字的作用是索引;所有的叶子结点包含了全部关键字的信息,以及指向这些关键字记录的指针,且叶子结点本身的关键字的大小自小而大顺序链接。从上述的特点中我们知道,这两种树都是平衡的多分树,它们都可以用于文件的索引结构,但B树只能支持随机检索,而B+树是有序的树,既能支持随机检索,又能支持顺序检索。
5、具有3个结点的二叉树有几种形态?
A、4
B、5
C、6
D、7
6、已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为多少?
A、DGEBFHAC
B、DGEBHFCA
C、DEGHBFCA
D、DEGBHACF
选B。前序遍历确定根节点,中序遍历确定左右子树。
A, (BDEG,CFH)
(B,(D,EG));(C,( ,FH))
(E,(G ,)); (F,(H,))
7、已知数据表A中每个元素距其最终位置不远,为节省时间排序,应采用什么方法排序?
A、堆排序
B、插入排序
C、快速排序
D、直接选择排序
选B。插入排序:如果平均每个元素离最终位置相距c个元素,则其复杂度为O(cn),一共n趟,每次比较c次;
快速排序:最好的、平均的复杂度都是O(nlog(n)),如果每次选择的中间数都最小或最大,那就是最坏的情况,复杂度是O(n*n);所以快速排序和元素的位置没有关系,跟选择的中间数有关。
堆排序:复杂度一直是O(nlog(n));
直接选择排序:跟元素位置没有关系,都要遍历n遍,每遍找出最小或最大数来,复杂度是O(n*n);
8、将N条长度均为M的有序链表进行合并,合并以后的链表也保持有序,时间复杂度为()?
A、O(N * M*logN)
B、O(N*M)
C、O(M)
D、以上都不正确
选A。1、两两合并链表。合并链表复杂度 * 一次合并次数 * 所有合并次数。两两合并的复杂度会指数递增,合并数会指数递减。一共应该是log(N)次。前面的合并复杂度较高。所以一般不采用该方法来合并链表。2、利用堆来合并,( O(N) + O(log N * N )) * M。先利用最链表第一个数,N个数建立堆,复杂度 O (N), 重构堆,并排序,复杂度 O(logN * N ), 每个链表M个数,上述两步重复M次。结果为M * (O(N) + O(logN * N))= O (M * N * logN)
9、有2n个人排队进电影院,票价是50美分。在这2n个人当中,其中n个人只有50美分,另外n个人有1美元(纸票子)。愚蠢的电影院开始卖票时1分钱也没有。 问: 有多少种排队方法 使得 每当一个拥有1美元买票时,电影院都有50美分找钱 ?
注: 1美元=100美分 拥有1美元的人,拥有的是纸币,没法破成2个50美分
A、(2n)!/[n!n!]
B、(2n)!/[n!(n+1)!]
C、(2n)!/[n!(n-1)!]
D、(2n + 1)!/[n!(n-1)!]
选B。卡特兰数
10、T(n) = 25T(n/5)+n^2的时间复杂度?
A、O(n^2*(lgn))
B、O(n^2)
C、O(lgn)
D、O(n*n*n)
选A。T(n) = 25*T(n/5) + n^2= 25*( 25*T(n/25) + (n/5)2 ) + n^2 = 5^4*T(n/52) + 2*n^2 = 5^(2k)*T(n/5k) + k*n^2 根据主方法,有T(n) = aT(n/b)+O(n^d), 则a=5^(2k), b=5k, d=2, a=b^d。所以T(n)=O(n^d*(lgn))=O(n^2(lgn))。
11、连续整数之和为1000的共有几组?
A、3
B、4
C、5
D、8
选B。设从n加到m和为1000,则(n+m)(m-n+1)/2=1000,即(n+m)(m-n+1)=2000,即把2000分解成两个数的乘积,且这两个数为一奇一偶。2000=(2^4)*(5^3),于是奇数可能为5^0,5^1,5^2,5^3,即有四组解。
12、一个有序数列,序列中的每一个值都能够被2或者3或者5所整除,1是这个序列的第一个元素。求第1500个值是多少?
A、2040
B、2042
C、2045
D、2050
选C。2、3、5的最小公倍数是30。[ 1, 30]内符合条件的数有22个。如果能看出[ 31, 60]内也有22个符合条件的数,那问题就容易解决了。也就是说,这些数具有周期性,且周期为30。第1500个数是:1500/22=68 1500%68=4。也就是说:第1500个数相当于经过了68个周期,然后再取下一个周期内的第4个数。一个周期内的前4个数:2,3,4,5。
故,结果为68*30=2040+5=2045
故,结果为68*30=2040+5=2045
13、写出a*(b-c*d)+e-f/g*(h+i*j-k)的逆波兰表达式。
A、a(b-c*d)*+e-(f/g(h+i*j-k)*)
B、a(b-(cd*))*+e-(fg/(h+ij*-k)*)
C、a(bcd*-)*+e-(fg/hij*+k-*)
D、abcd*-*e+fg/hij*+k-*-
选D。表达式一般由操作数、运算符组成,例如算术表达式中,通常把运算符放在两个操作数的中间,这称为中缀表达式,如A+B。波兰数学家Jan Lukasiewicz提出了另一种数学表示法,它有两种表示形式:把运算符写在操作数之前,称为波兰表达式或前缀表达式,如+AB;把运算符写在操作数之后,称为逆波兰表达式或后缀表达式,如AB+;
![]()
将中缀表达式转换成后缀表达式算法:
1、从左至右扫描中缀表达式。
2、若读取的是操作数,则判断该操作数的类型,并将该操作数存入操作数堆栈
3、若读取的是运算符
(1) 该运算符为左括号"(",则直接存入运算符堆栈。
(2) 该运算符为右括号")",则输出运算符堆栈中的运算符到操作数堆栈,直到遇到左括号为止。
(3) 该运算符为非括号运算符:
(a) 若运算符堆栈栈顶的运算符为括号,则直接存入运算符堆栈。
(b) 若比运算符堆栈栈顶的运算符优先级高或相等,则直接存入运算符堆栈。
(c) 若比运算符堆栈栈顶的运算符优先级低,则输出栈顶运算符到操作数堆栈,并将当前运算符压入运算符堆栈。
4、当表达式读取完成后运算符堆栈中尚有运算符时,则依序取出运算符到操作数堆栈,直到运算符堆栈为空。
逆波兰表达式求值算法:
1、循环扫描语法单元的项目。
2、如果扫描的项目是操作数,则将其压入操作数堆栈,并扫描下一个项目。
3、如果扫描的项目是一个二元运算符,则对栈的顶上两个操作数执行该运算。
4、如果扫描的项目是一个一元运算符,则对栈的最顶上操作数执行该运算。
5、将运算结果重新压入堆栈。
6、重复步骤2-5,堆栈中即为结果值。
故选D14、下列关于线性表,二叉平衡树,哈希表存储数据的优劣描述错误的是?
A、哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);
B、线性表实现相对比较简单
C、平衡二叉树的各项操作的时间复杂度为O(logn)
D、平衡二叉树的插入节点比较快
选D。哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。在平衡二叉树中插入结点要随时保证插入后整棵二叉树是平衡的,所以可能需要通过一次或多次树旋转来重新平衡这个树。
15、下面程序的功能是输出数组的全排列。请填空。
void perm(int list[], int k, int m)
{
if ( )
{
copy(list,list+m,ostream_iterator<int>(cout," "));
cout<<endl;
return;
}
for (int i=k; i<=m; i++)
{
swap(&list[k],&list[i]);
( );
swap(&list[k],&list[i]);
}
}
A、k!=m 和 perm(list,k+1,m)
B、k==m 和 perm(list,k+1,m)
C、k!=m 和 perm(list,k,m)
D、k==m 和 perm(list,k,m)
选B。k==m and perm(list,k+1,m);for循环的作用是为先把index值为k的元素后面的元素一次与index为k的元素交换,相当于得到index为k的元素可能的取值情况,然后使用递归得到index为k+1的元素位置可能的所有取值。然而对index为k的位置元素进行取值的时候,操作过后需要还原避免取下一个值的时候错误,因此就有了第二个swap操作。由上分析可知,第一个空格应该为k==m,当index值到了m的时候输出即可,因为index为m后面已经没有元素与其进行对调。
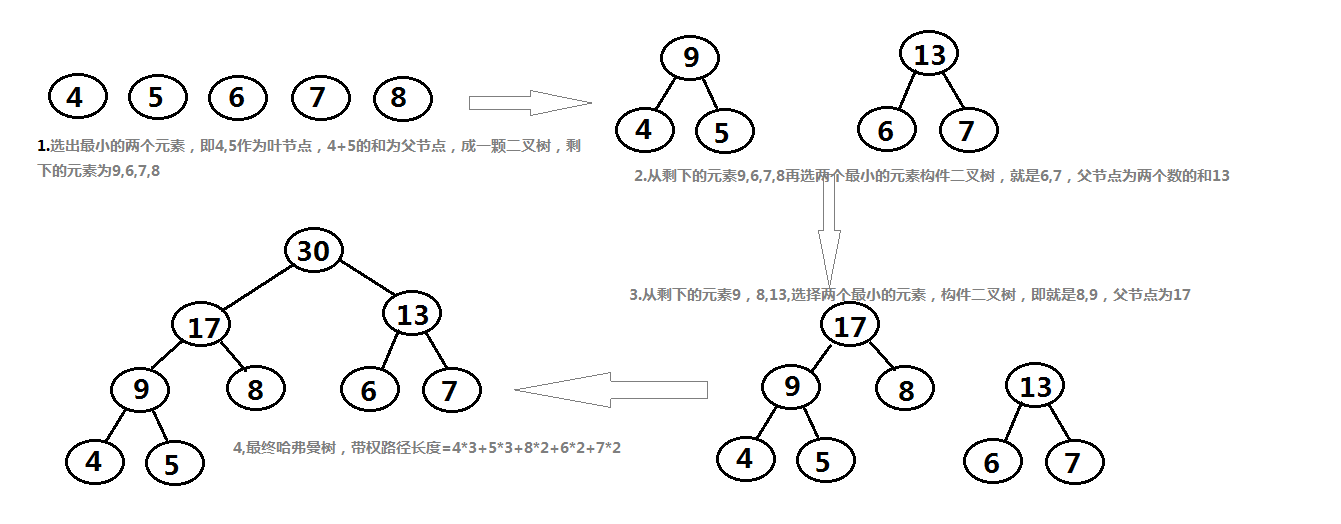
18、若以{4,5,6,7,8}作为叶子结点的权值构造哈夫曼树,则其带权路径长度是()。
A、24
B、30
C、53
D、69
选D。
19 用某种排序方法对关键字序列(25,84,21,47,15,27,68,35,20)进行排序,
序列的变化情况采样如下: 20,15,21,25,47,27,68,35,84 15,20,21,25,35,27,47,68,84 15,20,21,25,27,35,47,68,84 请问采用的是以下哪种排序算法()
A、选择排序
B、希尔排序
C、归并排序
D、快速排序
选D。首先第一步以25为基础,小于25的放在25的左边,大于25的放在25的右边
得到20,15,21,25,47,27,68,35,84
第二步在25的两边分别进行快速排序,左边以20为基数,右边以47为基数
得到15,20,21,25,35,27,47,68,84
第三步将,35,27这个子序列排序,
得到15,20,21,25,27,35,47,68,84
20、设某课二叉树中有360个结点,则该二叉树的最小高度是()
A、10
B、9
C、8
D、7
选B。设二叉树的高度为n,则有: 2^n-1>360
2^(n-1) -1<360 且n为正整数 n=9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号