
一、内容大纲
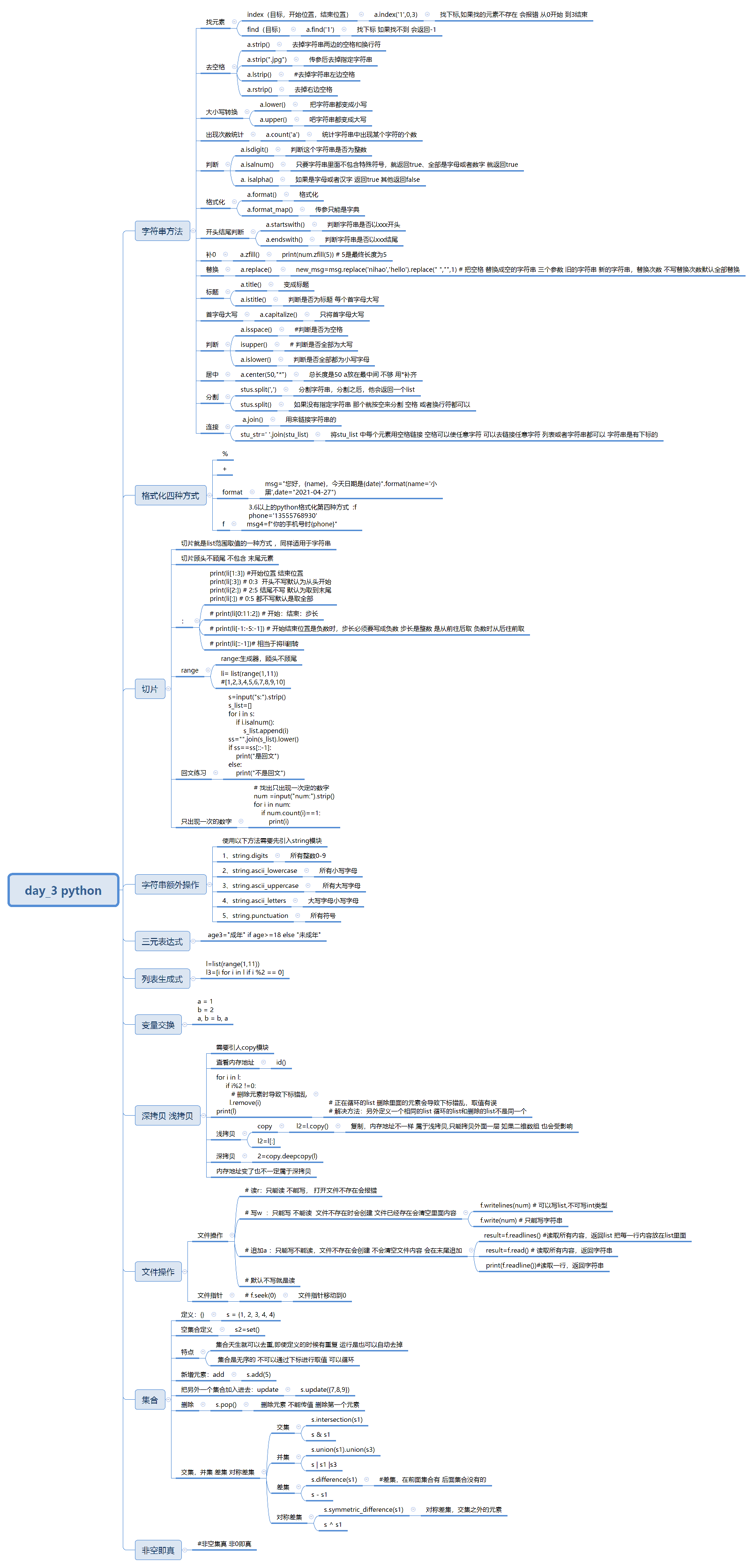
二、字符串方法
2.1普通方法
1.查找元素
index():可以带参数 找不到时会报错
a.index("1",0,3):查找1这个元素 从下标为0开始 找到下标为3
find():找不到返回-1
a.find('1')
2.strip(),lstrip() , rstrip()
(1)不传参时 去掉两边空格换行符
a.strip()
(2)传参时,去掉指定元素
a.strip(".jpg"
(3)lstrip():去掉左侧空格或者换行符
a.lstrip()
(4)rstrip():去掉右侧空格或者换行符
a.rstrip()
3.大小写转换
(1)转化为大写:lower()
print(a.lower())
(2)转化为小写:upper()
print(a.upper())
(3)只将首字母大写:capitalize()
print(a.capitalize()) # 只将首字母大写
(4)判断是否全部为大写:isupper()
print(a.isupper()) # 判断是否全部为大写
(5)判断是否全部为小写:idlower()
print(a.islower()) # 判断是否全部都为小写字母
4.统计某个字符出现次数:count()
print(a.count('a')) # 统计字符串中出现某个字符的个数
5.其他判断
(1)是否为整数判断:isdigit()
print(a.isdigit()) # 判断这个字符串是否为整数
(2)是否包含特殊字符判断:isalnum()
print(a.isalnum()) # 只要字符串里面不包含特殊符号,就返回true、全部是字母或者数字 就返回true
(3)是否全部为字幕或者汉字判断: isalpha()
print(a. isalpha()) # 如果是字母或者汉字 返回true 其他返回false
6.格式化
(1)format()
msg="您好,{name},今天日期是{date}".format(name='小黑',date="2021-04-27")
(2)format_map()# 传参只能是字典
msg="您好,{name},今天日期是{date}".format_map({'name':"xiaohei", "date":"2021-04-27"})
(3)格式化的四种方式
第一种:+号链接
第二种:%号连接
第三种:format形式
第四种:3.6以上的python格式化第四种方式 :f
phone='13555768930'
msg4=f"你的手机号时{phone}"
7.开头结尾判断:
(1)startswith():判断是否以xxx开头
msg='您好 老师'
print(msg.startswith("您好"))
(2)endswith():判断是否以xxx结束
a='a.jpg'
print(a.endswith('jpg')
8.补0:zfill():
num='51'
print(num.zfill(5)) # 5是最终长度为5
9.替换:replace(旧字符串,新字符串, 替换次数)
msg="nihao,nice to meet you"
new_msg=msg.replace('nihao','hello').replace(" ","",1) # 把空格 替换成空的字符串 三个参数 旧的字符串 新的字符串,替换次数 不写替换次数默认全部替换
print(new_msg)
10.标题方法
(1)设置为标题: title()
a="abc"
print( a.title()) # 变成标题
(2)判断是否为标题: istitle()
print(a.istitle()) # 判断是否为标题 每个首字母大写
11.空格方法
(1)判断是否为空格:isspace()
print(a.isspace()) #判断是否为空格
12.center()方法
print(a.center(50,"*")) #总长度是50 a放在最中间 不够 用*补齐
13.分割:split(),返回值是一个list
stus="小黑, 小白, 小兰"
print(stus.split(',')) # 分割字符串,分割之后,他会返回一个list
print(stus.split())# 如果没有指定字符串 那个就按空来分割 空格 或者换行符都可以
14.连接:join()
stu_list=['小黑','小白','小兰']
stu_str=' '.join(stu_list) # 将stu_list 中每个元素用空格链接
print(stu_str)
2.2字符串额外方法:string模块
1.引入string模块
import string
2.获得所有整数:string.digits
3.获得所有的大写字母:string.ascii_lowercase
4.获得所有小写字母: string.ascii_uppercase
5.获得所有字母:string.letters
6.获得所有特殊字符:string.punctuation
import string
print(string.digits) # 所有整数0-9
print(string.ascii_lowercase)#所有小写字母
print(string.ascii_uppercase)# 所有大写字母
print(string.ascii_letters)# 大写字母小写字母
print(string.punctuation) #所有符号
三、切片
1.切片:切片就是list范围取值的一种方式 ,同样适用于字符串
(1)切片顾头不顾尾 开始位置或者结束位置不写 默认从头开始或者取到结束
li = [1, 2, 3, 4, 5]
print(li[1:3]) #开始位置 结束位置
print(li[:3]) # 0:3 开头不写默认为从头开始
print(li[2:]) # 2:5 结尾不写 默认为取到末尾
print(li[:]) # 0:5 都不写默认是取全部
(2)步长 负数 以及翻转
print(li[0:11:2]) # 开始:结束:步长
print(li[-1:-5:-1]) # 开始结束位置是负数时,步长必须要写成负数 步长是正数 是从前往后取 负数时从后往前取
print(li[::-1])# 相当于将li翻转
2.生成器:
range(),顾头不顾尾
转化为list:
list=list(range(1,10)) 结果:[1,2,3,4,5,6,7,8,9],不包含10
3.回文练习:回文就是翻转后和原来保持一致
s=input("输入回文").strip()
s_list=[]
for i in s:
if i.isalnum():
s_list.append(i)
print(s_list)
if s_list==s_list[::-1]:
print("是回文")
else:
print("不是回文")
4.找出只出现一次的数字
nums=input("请输入数字:")
for i in nums:
if nums.count(i)==1:
print(i)
break
四、深拷贝,浅拷贝
1.循环删除list元素问题
正在循环的list 删除里面的元素会导致下标错乱,取值有误
解决方法:另外定义一个相同的list 循环的list和删除的list不是同一个
错误:
l = [1, 1, 2, 3, 5, 5, 6, 7, 8]
for i in l:
if i%2 !=0:
# 删除元素时导致下标错乱
l.remove(i)
print(l)
正确:
l = [1, 1, 2, 3, 5, 5, 6, 7, 8]
l2 = [1, 1, 2, 3, 5, 5, 6, 7, 8]
for i in l2:
if i%2 !=0:
# 删除元素时导致下标错乱
l.remove(i)
print(l)
2.深拷贝与浅拷贝
(1)模块引入:使用copy方法需要引入copy模块
(2)浅拷贝:内存地址变了 也不一定是深拷贝,如果l为多维数组 copy只能拷贝外层 里面也会受影响
l2=copy.copy(l)
l2=l[:]
例:
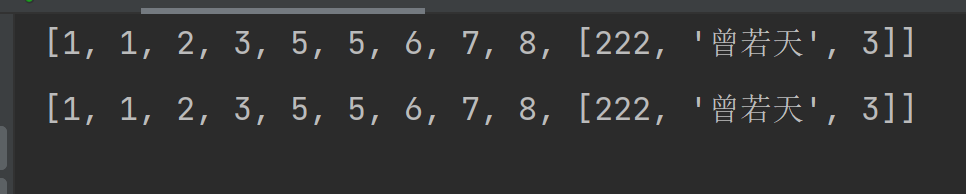
l = [1, 1, 2, 3, 5, 5, 6, 7, 8,[222,333,3]]
l2=copy.copy(l)
l2[-1][1]="曾若天"
print(l)
print(l2)
结果:
(3)深拷贝
l2=copy.deepcopy(l)
例:
l = [1, 1, 2, 3, 5, 5, 6, 7, 8,[222,333,3]]
l2=copy.deepcopy(l)
l2[-1][1]="曾若天"
print(l)
print(l2)
结果:l不受影响

(4)查看内存地址:id()
print(id(l))
print(id(l2))
五、三元表达式,列表生成式,变量交换
1.三元表达式:对if..else..的简写 不支持多条件判断
age=17
age3="成年" if age>=18 else "未成年"
2.列表生成式:对循环的简写 满足条件的i写入l3
l=list(range(1,11))
l3=[i for i in l if i %2 == 0]
3.变量交换
(1)变量交换
a = 1
b = 2
a, b = b, a
(2)中间变量
temp=None
temp=b
b=a
a=temp
print(a,b)
(3):计算
a=a+b
b=a-b
a=a-b
print(a,b)
4.非空即真 非0即真
a=''
b=[]
c={}
d=0
f=None
均为假
六、集合
6.1定义
1.定义:
(1)使用{}定义
s = {1, 2, 3, 4, 4}
(2)空集合定义:s=set()
s2=set()
2.特点:
(1)集合天生就可以去重,即使定义的时候有重复 运行是也可以自动去掉
(2)集合是无序的 不可以通过下标进行取值 可以循环
6.2操作
1.新增元素:add()
s.add(5)
2.把另一个元素加入进去:update()
s.update({7,8,9})
3.删除元素:pop() 删除第一个元素
s.pop()
6.3交集,并集, 差集,对称差集
1.交集:intersection()或者&
print(s.intersection(s1)) #交集
print(s & s1) #交集
2.并集:union()或者 |
print(s.union(s1).union(s3)) # 并集
print(s | s1 |s3) # 并集
3.差集(在前面集合有 后面集合没有的):difference()或者 -
print(s.difference(s1)) #差集,在前面集合有 后面集合没有的
print(s - s1) #差集
4.对称差集:symmetric_difference()或者 ^
print(s.symmetric_difference(s1)) # 对称差集,交集之外的元素
print(s ^ s1)# 对称差集,交集之外的元素
七、文件操作
7.1打开文件:
打开文件:open 需要指定编码格式:encoding="utf-8"
文件打开后需要关闭:close()
f= open("a.txt","w",encoding="utf-8")
f.close()
7.2 读:r:只能读 不能写, 打开文件不存在会报错
1.不写是默认为r
2.read():读取全部 返回字符串
f=open("a.txt", encoding="utf-8")
result=f.read()
3.readlines():读取全部 返回list
f=open("a.txt", encoding="utf-8")
result=f.readlines()
4.readline():读取一行,返回字符串
f=open("a.txt", encoding="utf-8")
result=f.readline()
6.文件指针: seek(0):当有多个读取方法时 前面一个读取完成后 后面无法读取到内容 需要使用文件指针将文件指针变为0 从头开始
print(f.readline())
print("f.read",f.read())
# 文件指针移动到0
f.seek(0)
print("f.readlines",f.readlines())
f.close()
7.3 写w:只能写 不能读 文件不存在时会创建 文件已经存在会清空里面内容
1.writelines():可以写list,字符串类型 不支持int类型
2.write():只能写入字符串
7.4 追加a:
只能写不能读,文件不存在会创建 不会清空文件内容 会在末尾追加
7.4例题
[1,2,3] 写入文件中并且换行
nums=[str(i) +"\n" for i in num]
f.writelines(nums)
f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号