
机器学习笔记之支持向量机
一、支持向量机概述
支 持 向 量 机 ( Support Vector Machine,SVM ) 是 一 类 按 监 督 学 习 (supervised learning)方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
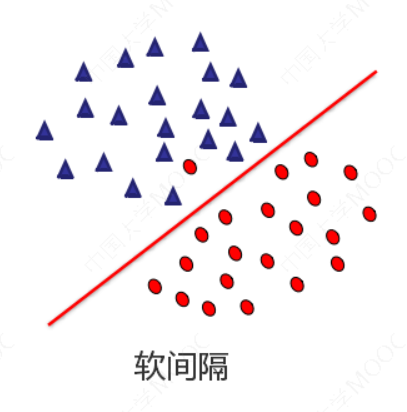
假如数据是完全的线性可分的,那么学习到的模型可以称为硬间隔支持向量机。换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误。
硬间隔、软间隔和非线性 SVM:
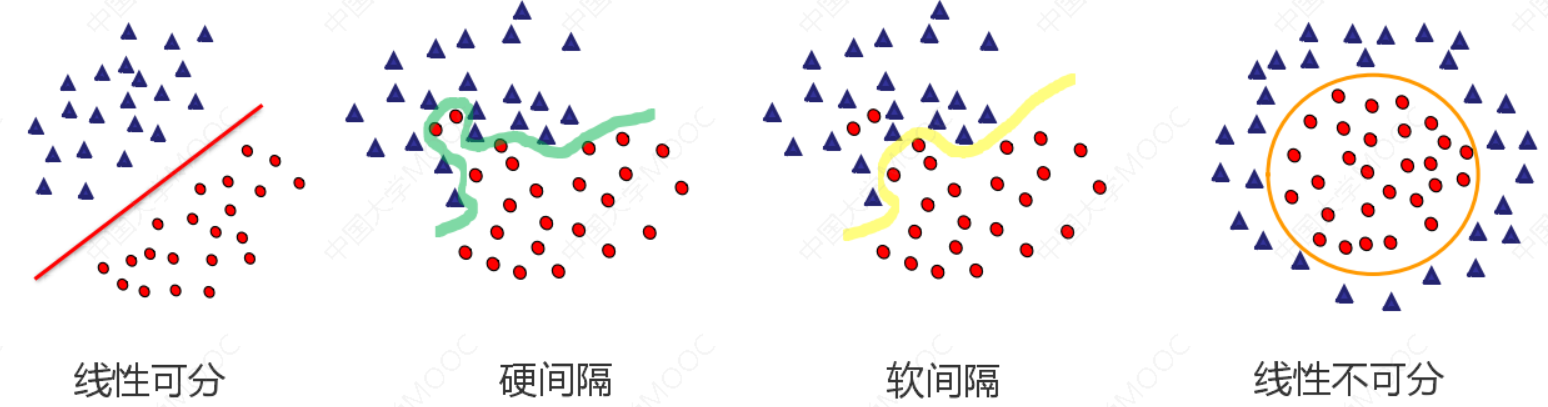
1.1 算法思想
找到集合边缘上的若干数据(称为支持向量(Support Vector)),用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大。
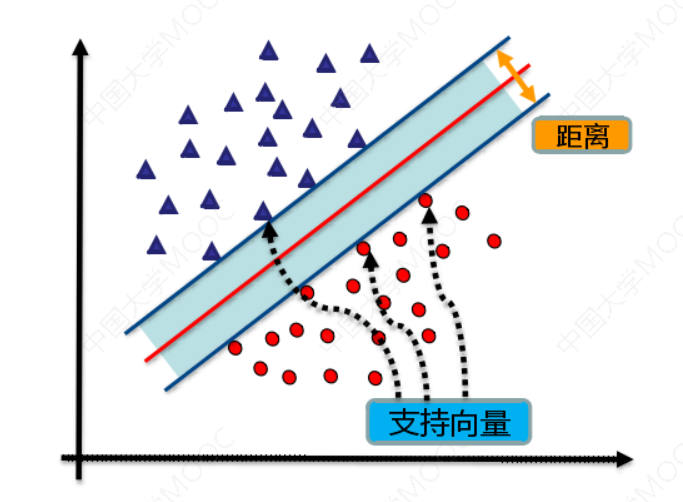
1.2 背景知识
任意超平面可以用下面这个线性方程来描述:
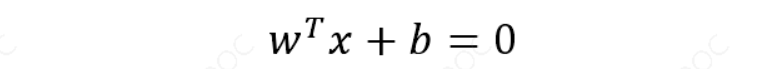
二维空间点 (𝑥, 𝑦)到直线 𝐴𝑥 + 𝐵𝑦 + 𝐶 = 0的距离公式是:
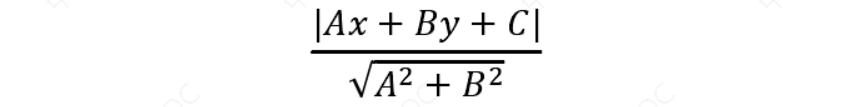
扩展到 𝑛 维空间后,点 𝑥 = (𝑥1, 𝑥2… 𝑥𝑛) 到超平面$𝑤^𝑇𝑥 + 𝑏 = 0 $的距离为:
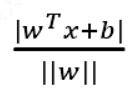
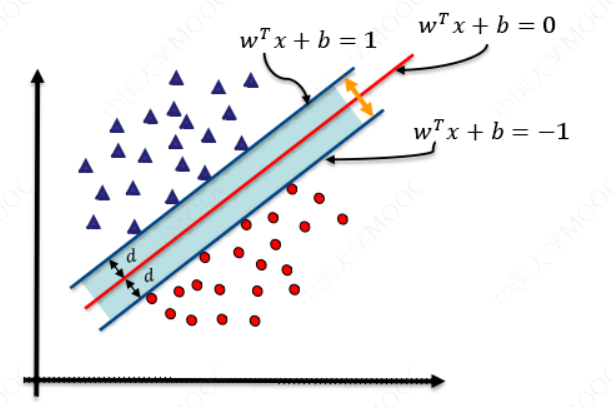
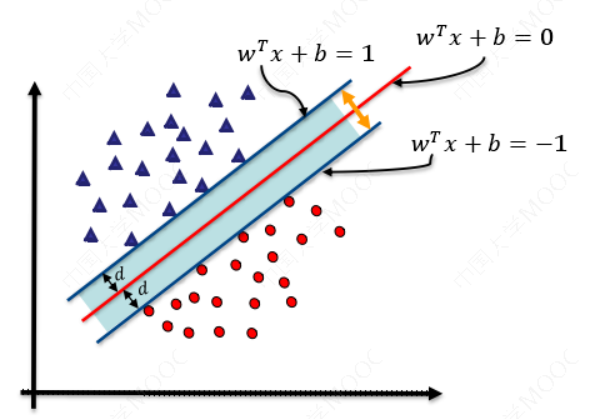
如图所示,根据支持向量的定义我们知道,支持向量到超平面的距离为 𝑑,其他点到超平面的距离大于 𝑑。每个支持向量到超平面的距离可以写为:

如图所示,根据支持向量的定义我们知道,支持向量到超平面的距离为 𝑑,其他点到超平面的距离大于 𝑑。
于是我们有这样的一个公式:
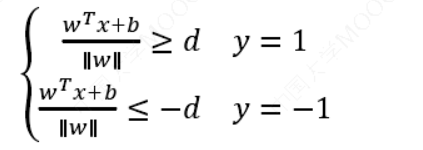
我们暂且令𝑑为 1(之所以令它等于 1,是为了方便推导和优化,且这样做对目标函数的优化没有影响),将两个方程合并,我们可以简写为:\(𝑦(𝑤^𝑇𝑥 + 𝑏) ≥ 1\)
至此我们就可以得到最大间隔超平面的上下两个超平面:
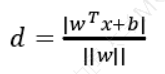
二、线性可分支持向量机
2.1 背景知识
点到面的距离公式:
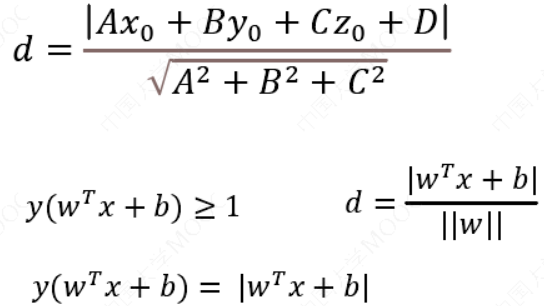
支持向量机的最终目的是最大化𝑑
函数间隔:
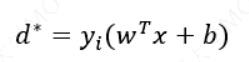
几何间隔:当数据被正确分类时,几何间隔就是点到超平面的距离
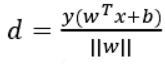
为了求几何间隔最大,SVM基本问题可以转化为求解:
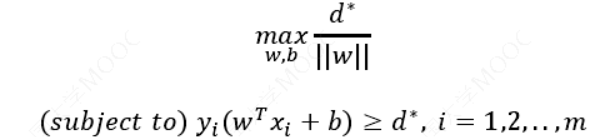




三、线性支持向量机
若数据线性不可分,则可以引入松弛变量𝜉 ≥ 0,使函数间隔加上松弛变量大于等于1 ,则目标函数:
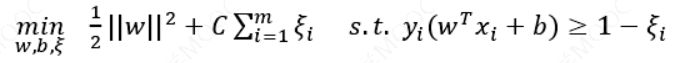
对偶问题:
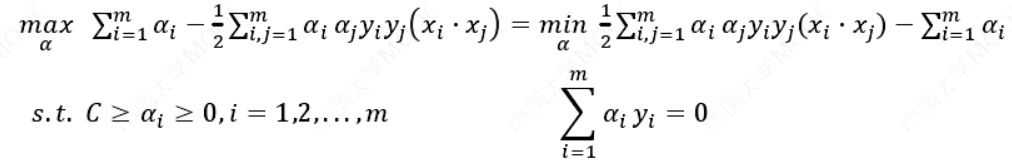
𝐶为惩罚参数, 𝐶 值越大 ,对分类的惩罚越大。跟线性可分求解的思路一致。同样这里先用拉格朗日乘子法得到拉格朗日函数,再求其对偶问题。
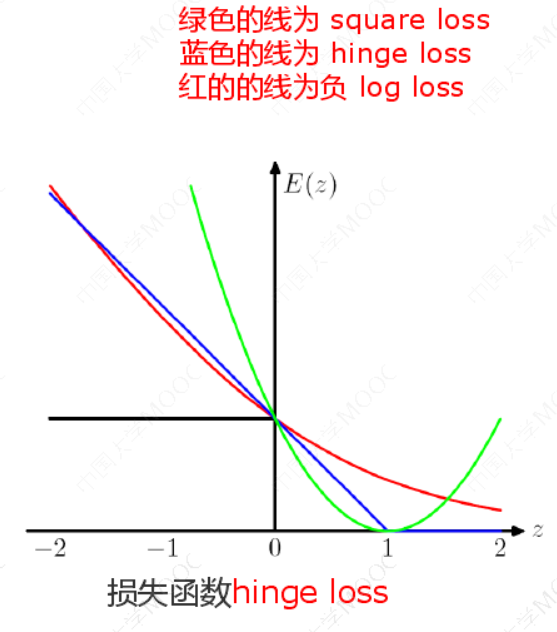
𝜉 为"松弛变量",即hinge损失函数。每一个样本都有一个对应的松弛变量,表征该样本不满足约束的程度。
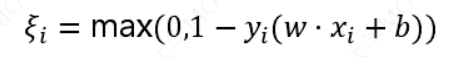
求解原始最优化问题的解𝑤∗和𝑏∗,得到线性支持向量机.
其分离超平面为:
𝑤∗𝑇𝑥 + 𝑏∗= 0
分类决策函数为:
𝑓(𝑥) = sign (𝑤∗𝑇𝑥 + 𝑏∗)
线性可分支持向量机的解𝑤∗唯一,但𝑏∗不唯一。对偶问题是:
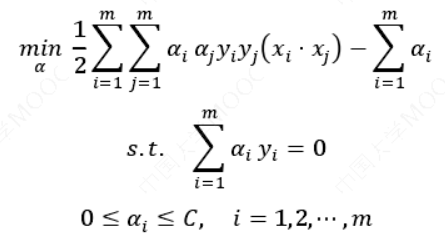
解出后,代入超平面模型:
𝑤∗𝑇𝑥 + 𝑏∗= 0
可得:
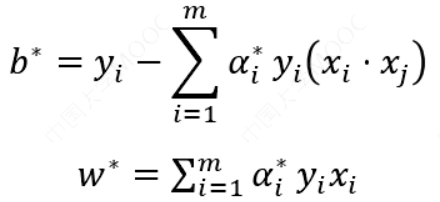
四、线性不可分支持向量机
4.1 核技巧
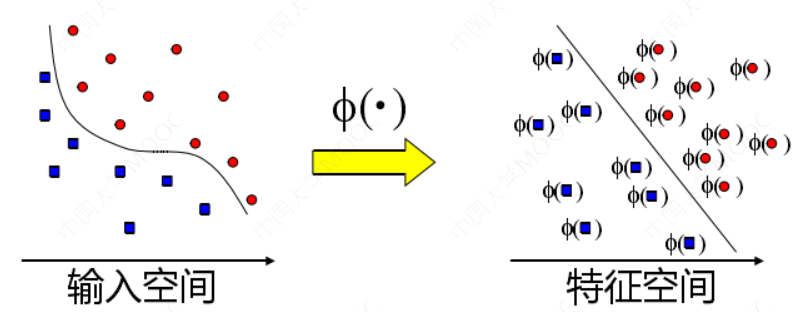
在低维空间计算获得高维空间的计算结果,满足高维,才能在高维下线性可分。 我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行,即用核函数来替换当中的内积。
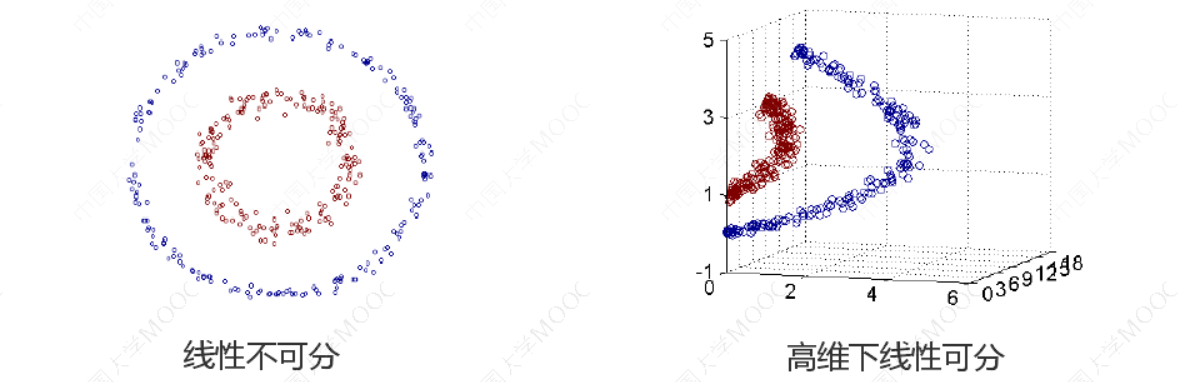
4.2 核技巧
用核函数来替换原来的内积:
即通过一个非线性转换后的两个样本间的内积。具体地,𝐾(𝑥, 𝑧)是一个核函数,或正定核,意味着存在一个从输入空间到特征空间的映射,对于任意空间输入的𝑥, 𝑧 有:
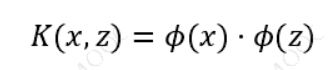
在线性支持向量机学习的对偶问题中,用核函数𝐾(𝑥, 𝑧)替代内积,求解得到的就是非线性支持向量机:
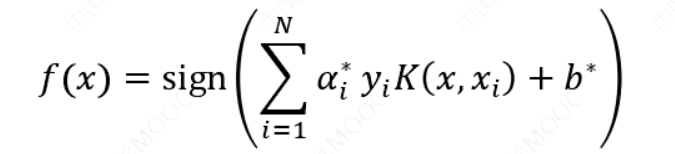
4.3 常用核函数
线性核函数:
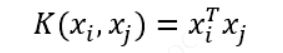
多项式核函数:
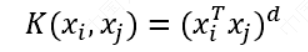
高斯核函数:
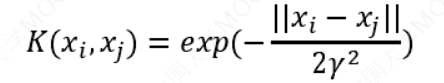
这三个常用的核函数中,只有高斯核函数是需要调参的.
4.4 SVM的超参数
𝛾越大,支持向量越少,𝛾值越小,支持向量越多。其中 C是惩罚系数,即对误差的宽容度。 C越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。

五、总结
下面是一些SVM普遍使用的准则:
𝑛为特征数,𝑚为训练样本数。
(1)如果相较于𝑚而言,𝑛要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果𝑛较小,而且𝑚大小中等,例如𝑛在 1-1000 之间,而𝑚在10-10000之间,使用高斯核函数的支持向量机。
(3)如果𝑛较小,而𝑚较大,例如𝑛在1-1000之间,而𝑚大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
六、参考资料
-
Prof. Andrew Ng. Machine Learning. Stanford University
-
《统计学习方法》,清华大学出版社,李航著,2019年出版
-
《机器学习》,清华大学出版社,周志华著,2016年出版
-
Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer-Verlag, 2006
-
Stephen Boyd, Lieven Vandenberghe, Convex Optimization, Cambridge University Press, 2004
