
机器学习之朴素贝叶斯
一、贝叶斯方法
1.1 贝叶斯方法-背景知识
贝叶斯分类:是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
先验概率:根据以往经验和分析得到的概率。我们用𝑃(𝑌)来代表在没有训练
数据前假设𝑌拥有的初始概率。
后验概率:根据已经发生的事件来分析得到的概率。以𝑃(𝑌|𝑋)代表假设𝑋 成
立的情下观察到𝑌数据的概率,因为它反映了在看到训练数据𝑋后𝑌成立的置信度。
联合概率:联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。𝑋与𝑌的联合概率表示为𝑃(𝑋, 𝑌 ) 、𝑃(𝑋𝑌) 或𝑃(𝑋 ∩ 𝑌) 。
假设𝑋和𝑌都服从正态分布,那么𝑃(𝑋 < 5, 𝑌 < 0)就是一个联合概率,表示 𝑋 < 5, 𝑌 < 0两个条件同时成立的概率,表示两个事件共同发生的概率。
1.2 贝叶斯方法
贝叶斯公式:

朴素贝叶斯法是典型的生成学习方法。生成方法由训练数据学习联合概率分布 𝑃(𝑋, 𝑌),然后求得后验概率分布𝑃(𝑌|𝑋)。具体来说,利用训练数据学习𝑃(𝑋|𝑌)和𝑃(𝑌)的估计,得到联合概率分布:𝑃(𝑋, 𝑌)=𝑃(𝑋|𝑌) 𝑃(𝑌)
二、朴素贝叶斯原理
2.1 判别模型和生成模型
监督学习方法又分为生成方法(Generative approach)和判别方法(Discriminative approach),所学到的模型分别称为生成模型(Generative Model)和判别模型(Discriminative Model)。

2.2 朴素贝叶斯法是典型的生成学习方法
生成方法由训练数据学习联合概率分布 𝑃(𝑋, 𝑌),然后求得后验概率分布𝑃(𝑌|𝑋)。具体来说,利用训练数据学习𝑃(𝑋|𝑌)和𝑃(𝑌)的估计,得到联合概率分布:𝑃(𝑋, 𝑌)=𝑃(𝑌)𝑃(𝑋|𝑌),概率估计方法可以是极大似然估计或贝叶斯估计。
2.3 朴素贝叶斯法的基本假设是条件独立性。
\(P(X = x|Y = c_k) = P(x^{(1)}, ⋯ , x^{(n)}|y^k) = \prod^{n}_{j=1}P(x^{(j)}|Y=c_k)\)
\({c_k}\)代表类别,k代表类别个数
这是一个较强的假设。由于这一假设,模型包含的条件概率的数量大为减少,朴素贝叶斯法的学习与预测大为简化。因而朴素贝叶斯法高效,且易于实现。其缺点是分类的性能不一定很高。
2.4 朴素贝叶斯法利用贝叶斯定理与学到的联合概率模型进行分类预测
我们要求的是𝑃(𝑌|𝑋),根据生成模型定义我们可以求𝑃(𝑋, 𝑌)和𝑃(𝑌)假设中的
特征是条件独立的。这个称作朴素贝叶斯假设。
如果给定𝑍的情况下,𝑋和𝑌条件独立,形式化表示为:
\(𝑃(𝑋|𝑍) = 𝑃(𝑋|𝑌, 𝑍)\)
也可以表示为:
\(𝑃(𝑋, 𝑌|𝑍) = 𝑃(𝑋|𝑍)𝑃(𝑌|𝑍)\)
用于文本分类的朴素贝叶斯模型,这个模型称作多值伯努利事件模型。在这个模型中,我们首先随机选定了邮件的类型𝑝(𝑦),然后一个人翻阅词典的所有词,随机决定一个词是否出现依照概率𝑝(\(𝑥^{(1)}\)|𝑦),出现标示为1,否则标示为0 。假设有50000个单词,那么这封邮件的概率可以表示为:
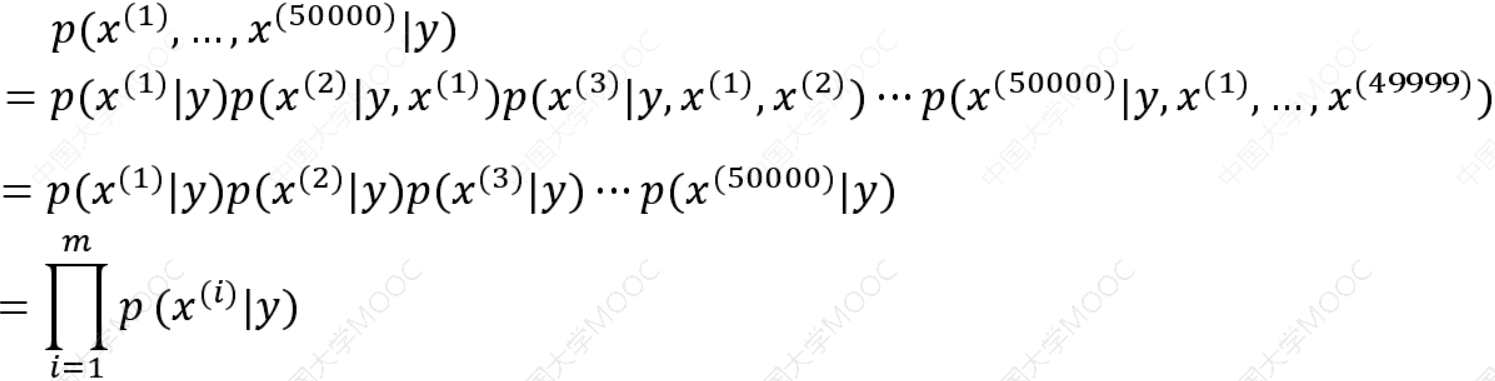
独立性:将输入𝑥分到后验概率最大的类𝑦。后验概率最大等价于0-1损失函数时的期望风险最小化。
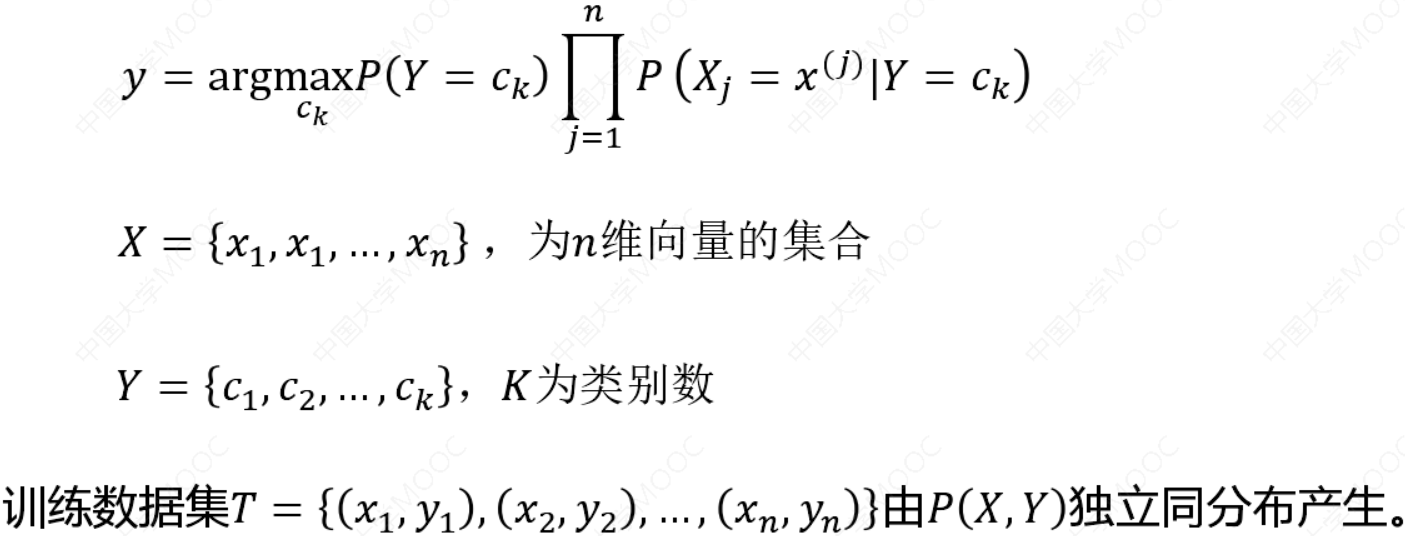
朴素贝叶斯法对条件概率分布作了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯法也由此得名。具体地,条件独立性假设是:
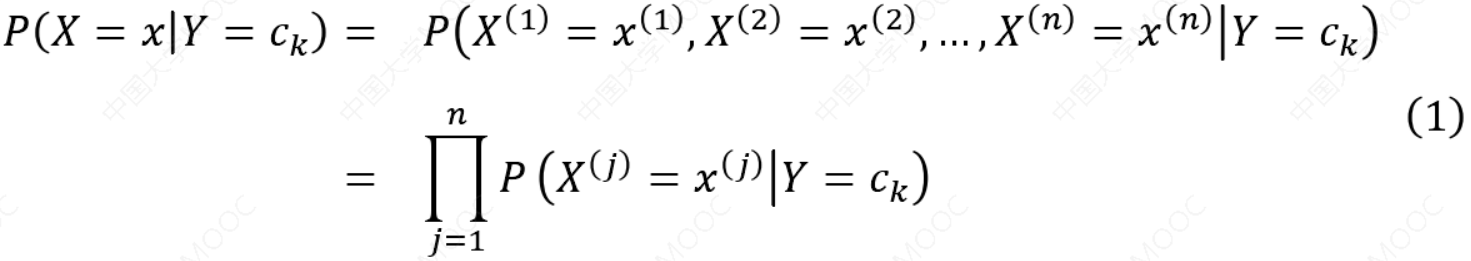
朴素贝叶斯法分类时,对给定的输入𝑥,通过学习到的模型计算后验概率分布𝑃 𝑌 = 𝑐𝑘𝑋 = 𝑥 ,将后验概率最大的类作为𝑥的类输出。
根据贝叶斯定理:
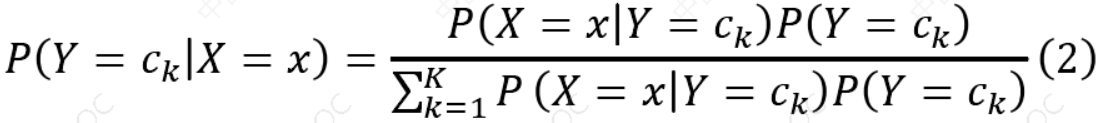
可以计算后验概率:
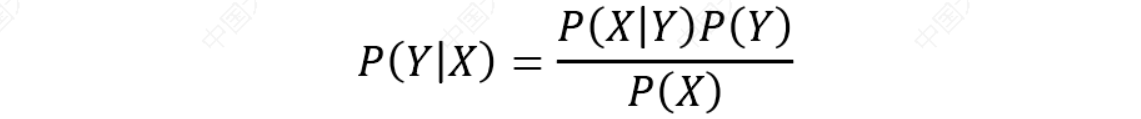
将式(1)代入公式(2),可以得到:
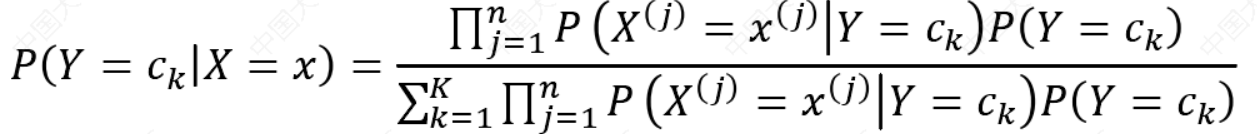
贝叶斯分类器可以表示为:
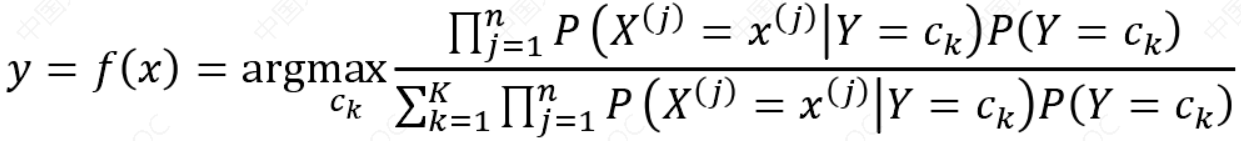
上式中分母中\({𝑐_𝑘}\)都是一样的,即不会对结果产生影响,即
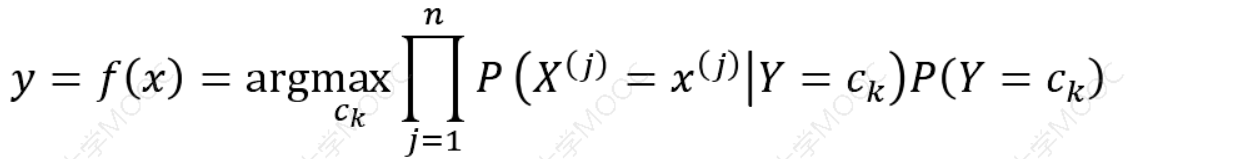
三、朴素贝叶斯案例
假设我们正在构建一个分类器,该分类器说明文本是否与运动(Sports)有关。我们的训练数据有5句话:
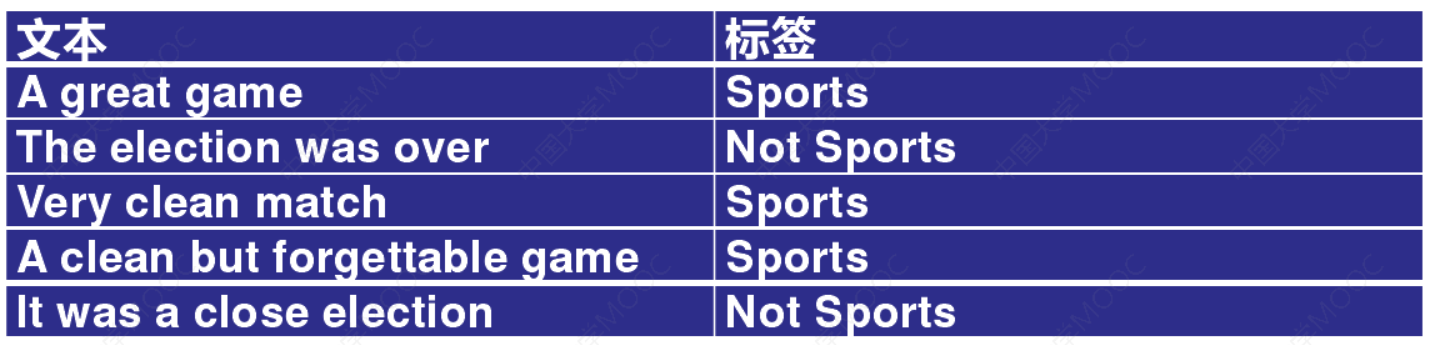
我们想要计算句子“A very close game”是 Sports 的概率以及它不是 Sports 的概率。即𝑃( Sports | a very close game )这个句子的类别是Sports的概率。特征:单词的频率,已知贝叶斯定理𝑃(𝑌|𝑋) =\(\frac{𝑃(𝑋|𝑌)𝑃(𝑌)}{𝑃(𝑋)}\),则:

由于我们只是试图找出哪个类别有更大的概率,可以舍弃除数,只是比较𝑃( a very close game | Sports ) × 𝑃( Sports ) 和𝑃( a very close game | Not Sports ) × 𝑃( Not Sports )
我们假设一个句子中的每个单词都与其他单词无关。
𝑃( a very close game )= 𝑃(𝑎) × 𝑃( very ) × 𝑃( close ) × 𝑃( game)
𝑃( 𝑎 𝑣𝑒𝑟𝑦 𝑐𝑙𝑜𝑠𝑒 𝑔𝑎𝑚𝑒|𝑆𝑝𝑜𝑟𝑡𝑠)= 𝑃(𝑎| 𝑆𝑝𝑜𝑟𝑡𝑠 ) × 𝑃( 𝑣𝑒𝑟𝑦 | 𝑆𝑝𝑜𝑟𝑡𝑠) × 𝑃( 𝑐𝑙𝑜𝑠𝑒 | 𝑆𝑝𝑜𝑟𝑡𝑠 ) × 𝑃( 𝑔𝑎𝑚𝑒 | 𝑆𝑝𝑜𝑟𝑡𝑠)
计算每个类别的先验概率:
对于训练集中的给定句子,𝑃 (Sports) 的概率为3/5。𝑃(Not Sports )是2/5。然后计算𝑃 (𝑔𝑎𝑚𝑒 |𝑆𝑝𝑜𝑟𝑡𝑠 )就是“game”有多少次出现在Sports的样本,然后除以sports为标签的文本的单词总数(3+3+5=11)因此,𝑃(𝑔𝑎𝑚𝑒 |𝑆𝑝𝑜𝑟𝑡𝑠)=2/11。“close”不会出现在任何sports样本中!那就是说𝑃(𝑐𝑙𝑜𝑠𝑒|𝑆𝑝𝑜𝑟𝑡𝑠) = 0。
通过使用一种称为拉普拉斯平滑的方法:我们为每个计数加1,因此它永远不会为零。为了平衡这一点,我们将可能单词的数量添加到除数中,因此计算结果永远不会大于1。
在这里的情况下,可能单词是['a', 'great', 'very', 'over', 'it', 'but', 'game', 'election','clean', 'close', 'the', 'was', 'forgettable', 'match']。
由于可能的单词数是14,因此应用平滑处理可以得到𝑃( game | sports ) =
\(\frac{2+1}{11+14}\)。
拉普拉斯平滑是一种用于平滑分类数据的技术。引入拉普拉斯平滑法来解决零概率问题,通过应用此方法,先验概率和条件概率可以写为:
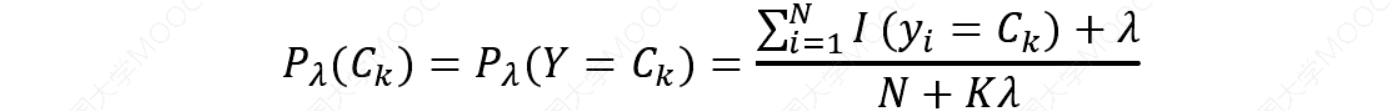
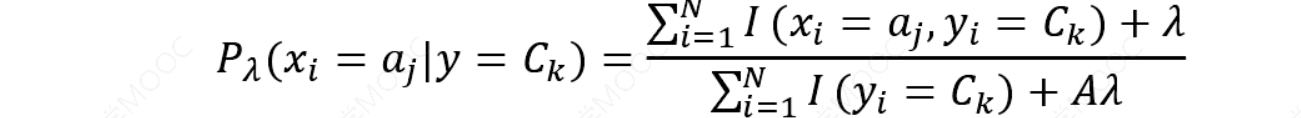
其中𝐾表示类别数量,𝐴表示\(𝑎_𝑗\)中不同值的数量通常𝜆 = 1。
加入拉普拉斯平滑之后,避免了出现概率为0的情况,又保证了每个值都在0到1的范围内,又保证了最终和为1的概率性质。

𝑃(𝑎| Sports ) × 𝑃( very | Sports ) × 𝑃( close | Sports ) × 𝑃( game | Sports ) × 𝑃(Sports )= 2.76 × \(10^{−5}\)= 0.0000276
𝑃(𝑎| Not Sports ) × 𝑃( very | Not Sports ) × 𝑃( close | Not Sports )× 𝑃( game | Not Sports ) × 𝑃( Not Sports)= 0.572 × \(10^{−5}\)= 0.00000572
四、朴素贝叶斯代码实践
最常用的GaussianNB是高斯贝叶斯分类器。它假设特征的条件概率分布满足高斯分布:
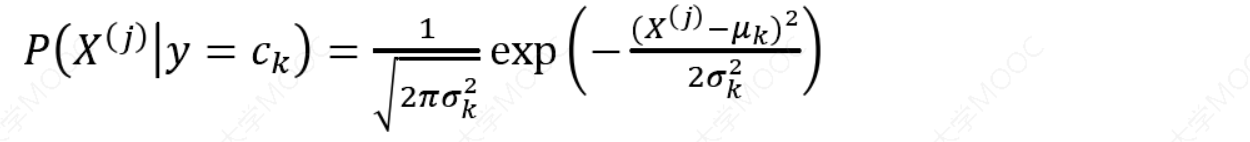
数学期望(mean):𝜇
方差:\(𝜎^2 =\frac{\sum(𝑋−𝜇)^2}{N}\)
其他贝叶斯分类器:
- MultinomialNB是多项式贝叶斯分类器,它假设特征的条件概率分布满足多项式分布;
- BernoulliNB是伯努利贝叶斯分类器。它假设特征的条件概率分布满足二项分布
最常用的GaussianNB是高斯朴素贝叶斯分类器的scikit-learn实现。
五、参考资料
- Prof. Andrew Ng. Machine Learning. Stanford University
- 《统计学习方法》,清华大学出版社,李航著,2019年出版
- 《机器学习》,清华大学出版社,周志华著,2016年出版
- Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer-Verlag, 2006
- Stephen Boyd, Lieven Vandenberghe, Convex Optimization, Cambridge University Press, 2004
- https://www.icourse163.org/course/WZU-1464096179

 浙公网安备 33010602011771号
浙公网安备 33010602011771号