6--Python基础
一、简介
Python 是一种解释型、面向对象的语言
Python 的语法和动态类型以及解释性语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言
二、基础语法
2.1、字面量
在代码中被写下来的的固定的值,称之为字面量
Python中有6种常用的值(数据)的类型
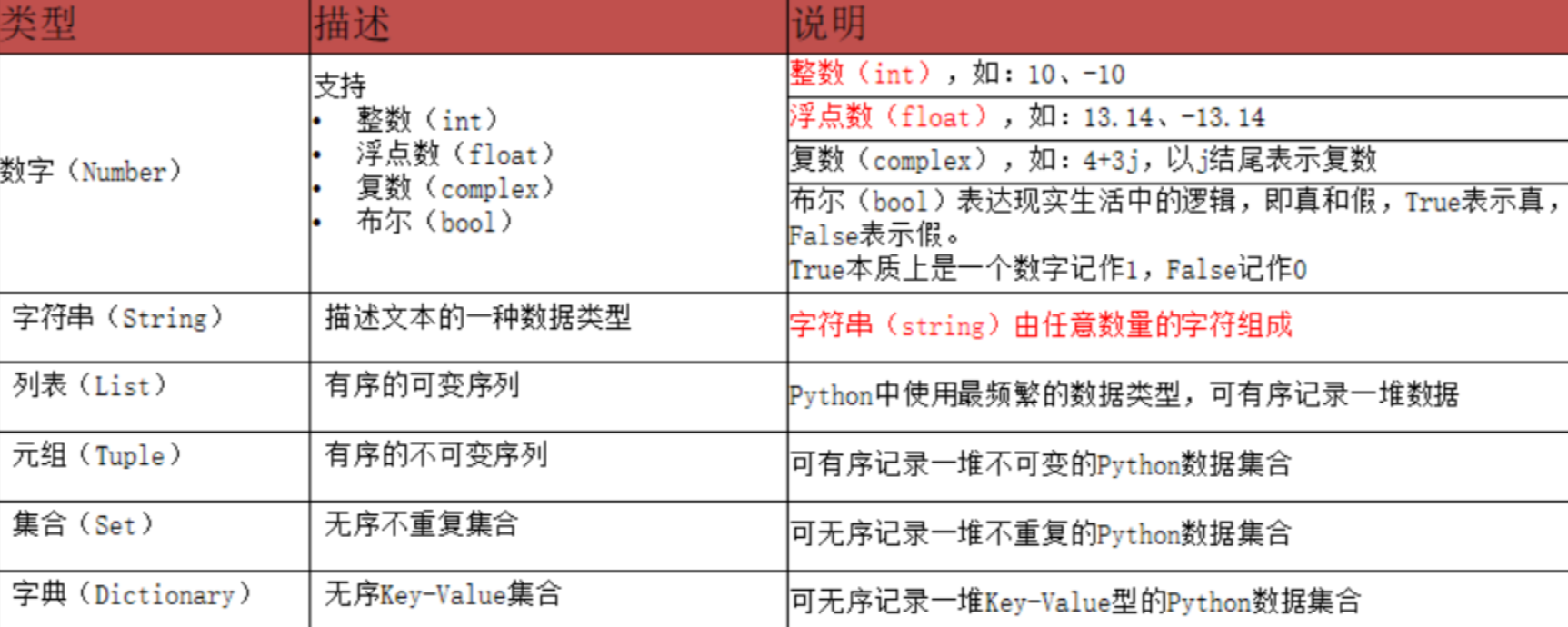
注意:type()语句可以查看变量存储的数据类型
2.2、注释
单行注释:以#开头,#右边的所有文字起辅助说明作用,而不是真正要执行的程序
1 # 单行注释 2 print("Hello World")
注意:#号和注释内容一般以一个空格隔开
多行注释:以一对三个双引号括起来
1 """ 2 多行注释 3 Python基础 4 内容 5 """ 6 print("Hello World")
2.3、数据类型转换

2.4、标识符
标识符:是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名
标识符命名中,只允许出现:英文 中文 数字 下划线(_)这四类元素
注意:不推荐使用中文,数字不可以开头,且不可使用关键字
2.5、运算符
算术(数学)运算符:

复合赋值运算符:

2.6、字符串
2.6.1、字符串的三种定义方式
1 单引号定义法:name = 'Python' 2 双引号定义法:name = "Python" 3 三引号定义法:name = """Python"""
其中,单引号定义法,可以内含双引号; 双引号定义法,可以内含单引号 ;并且可以使用转义字符(\)来将引号解除效用,变成普通字符串
2.6.2、字符串拼接
1 name = "Tom" 2 print("Hello" + name)
注意:字符串无法和非字符串变量进行拼接
1 name = "Tom" 2 print("Hello" + name,end='')
默认print语句输出内容会自动换行,在print语句中加上 end=‘’ 即可输出不换行
2.6.3、字符串格式化
通过如下语法,完成字符串和变量的快速拼接
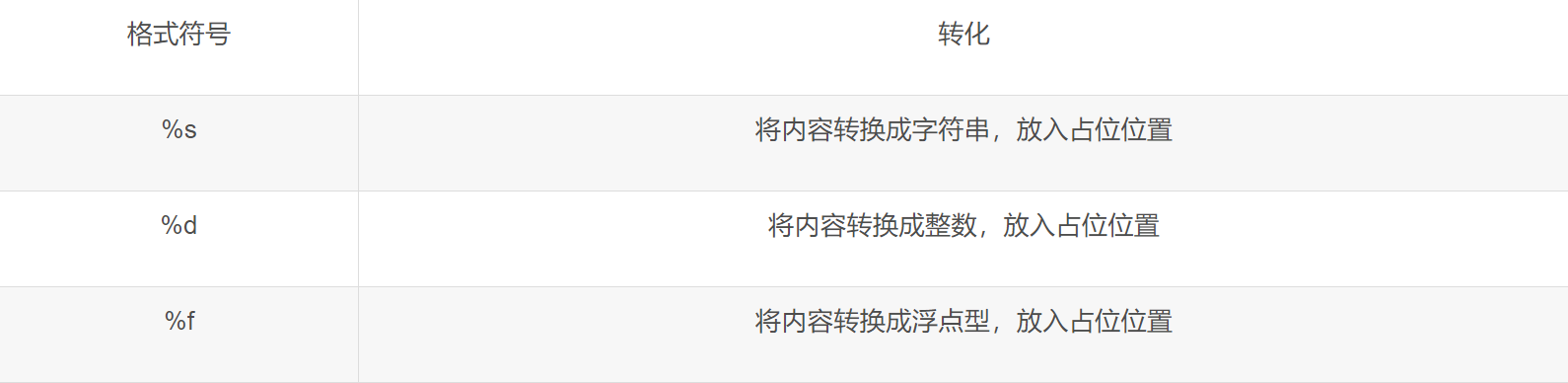
如下代码,完成字符串、整数、浮点数,三种不同类型变量的占位
1 name = "软件工程" 2 year = 2000 3 time = 23.11 4 message = "课程:%s,成立于:%d,已有:%f年" % (name,year,time) 5 print(message) 6 7 输出结果: 8 课程:软件工程,成立于:2000,已有:23.110000年
其中% 表示占位符,且在无需使用变量进行数据存储的时候,可以直接格式化表达式(变量的位置放入表达式),简化代码
2.6.4、格式化的精度控制
使用辅助符号"m.n"来控制数据的宽度和精度
m,控制宽度,要求是数字,如果设置的宽度小于数字自身,则不生效
n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:%5d:表示将整数的宽度控制在5位,如数字11,就会变成:[空格][空格][空格]11,用三个空格补足宽度
%5.2f:表示将宽度控制为5,将小数点精度设置为2,小数点和小数部分也算入宽度计算。如对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
2.6.5、字符串快速格式化
通过语法:f"内容{变量}"的格式来快速格式化
1 name = "软件工程" 2 year = 2000 3 time = 23.11 4 print(f"课程:{name},成立于:{year},已有:{time}年") 5 6 输出结果: 7 课程:软件工程,成立于:2000,已有:23.11年
注意:这种写法不做精度控制, 不理会类型原样输出
2.7、数据输入
使用input()语句可以从键盘获取输入
1 name = input("你的名字是:") 2 print("我的名字是:" + name) 3 4 输出结果: 5 你的名字是:小李 6 我的名字是:小李
注意:无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型
三、判断语句
3.1、if-else语句
1 age = 20 2 if(age >= 18): 3 print("我成年了") 4 else: 5 print("我还没有成年")
归属于if判断的代码语句块,需在前方填充4个空格缩进
Python通过缩进判断代码块的归属关系
3.2、if-elif-else语句
1 amount = 400 2 if amount < 100: 3 print("没有优惠") 4 elif 100 <= amount < 300: 5 print("打八折") 6 elif 300 <= amount < 500: 7 print("打七折") 8 else: 9 print("打六折")
四、循环语句
4.1、while循环
1 i = 0 2 while i < 10: 3 print("Hello World") 4 i += 1
4.2、for循环
1 name = "xiaoli" 2 for x in name: 3 print(x)
4.3、range语句
用于获得一个数字序列
语法1:range(num)
1 从0开始,到num结束(不含num本身)
语法2:range(num1, num2)
1 从num1开始,到num2结束(不含num2本身)
语法3:range(num1, num2, step)
1 从num1开始,间隔step到num2结束(不含num2本身)
1 for i in range(0,10,2): 2 print(i) 3 4 输出结果: 5 0 6 2 7 4 8 6 9 8
五、函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段
函数的定义:
1 def 函数名(传入参数) 2 函数体 3 return 返回值
注意:如果函数没有使用return语句返回数据,会返回None这个字面量;在if判断中,None等同于False;定义变量,但暂时不需要变量有具体值,可以用None来代替
使用 global关键字可以在函数内部声明变量为全局变量
六、数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素。 每一个元素,可以是任意类型的数据
6.1、list(列表)
基本语法:
1 # 定义列表字面量 2 [元素1,元素2,元素3,...] 3 4 # 定义列表变量 5 变量名称 = [元素1,元素2,元素3,...] 6 7 # 定义空列表 8 变量名称 = [] 9 变量名称 = list()
列表的方法:
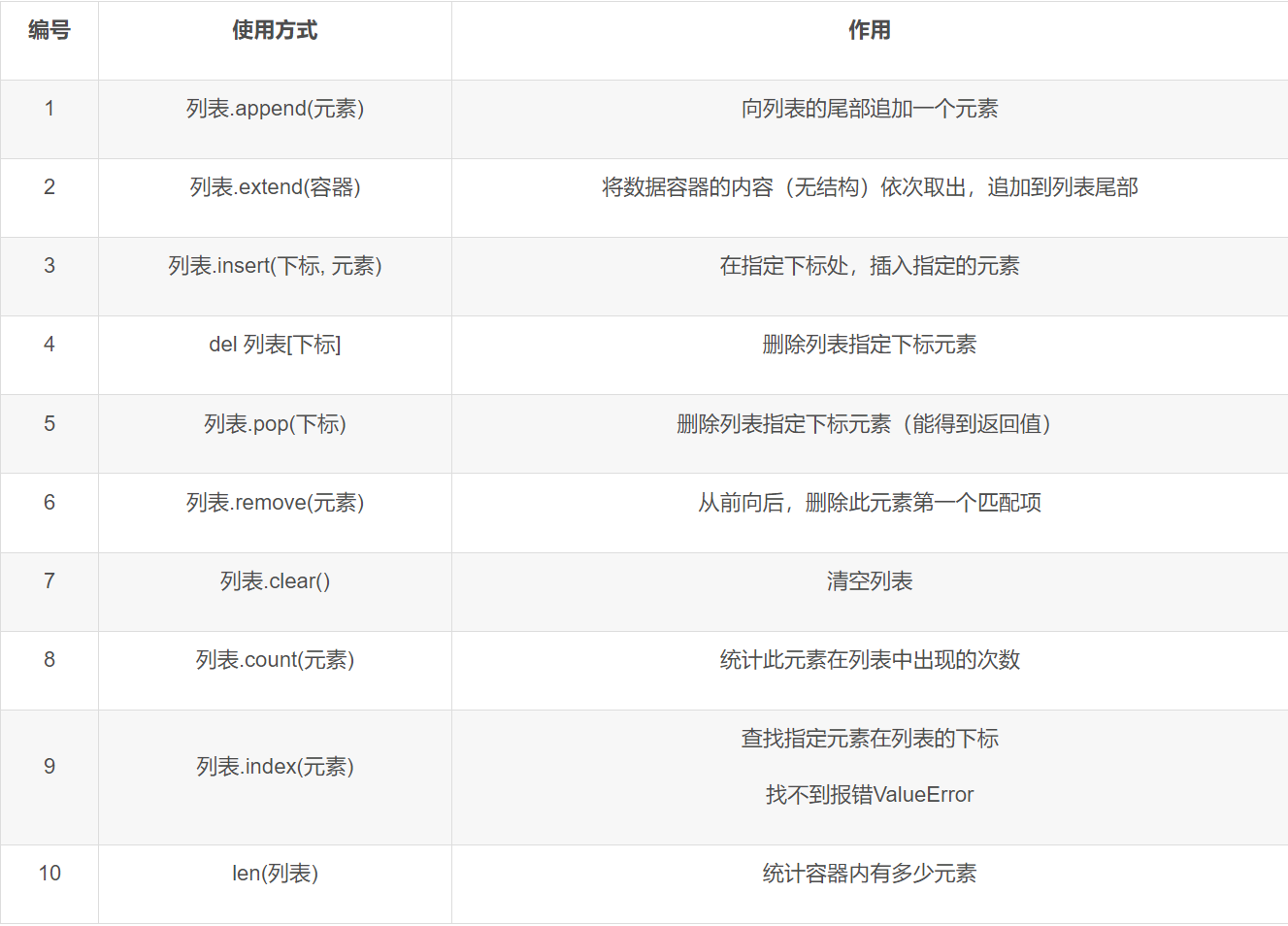
列表的特点:
- 可以容纳多个数据 (上限为2^63-1、9223372036854775807个)
- 可以容纳不同类型的数据 (混装 )
- 数据是有序存储的 (有下标序号)
- 允许重复数据存在
- 可以修改 (增加或删除元素等 )
6.2、tuple(元祖)
基本语法:
1 # 定义元祖字面量 2 (元素,元素,...,元素) 3 4 # 定义元祖变量 5 变量名称 = (元素,元素,...,元素) 6 7 # 定义空元祖 8 变量名称 = () 9 变量名称 = tuple() 10 11 # 定义一个元素的元祖 12 t1 = ('Hello',)
注意: 元组只有一个数据,则这个数据后面必须要添加逗号
元祖的方法:

元祖的特点:
- 不可以修改元祖的内容,否则会直接报错
- 但可以修改元祖内的list的内容(修改、增加或删除元素等)
6.3、字符串
字符串的方法:

字符串的特点:
- 字符串容器可以容纳的类型是单一的,只能是字符串类型
- 字符串不可以修改,如果必须要修改,只能得到一个新的字符串,旧的字符串是无法修改
6.4、序列的切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列
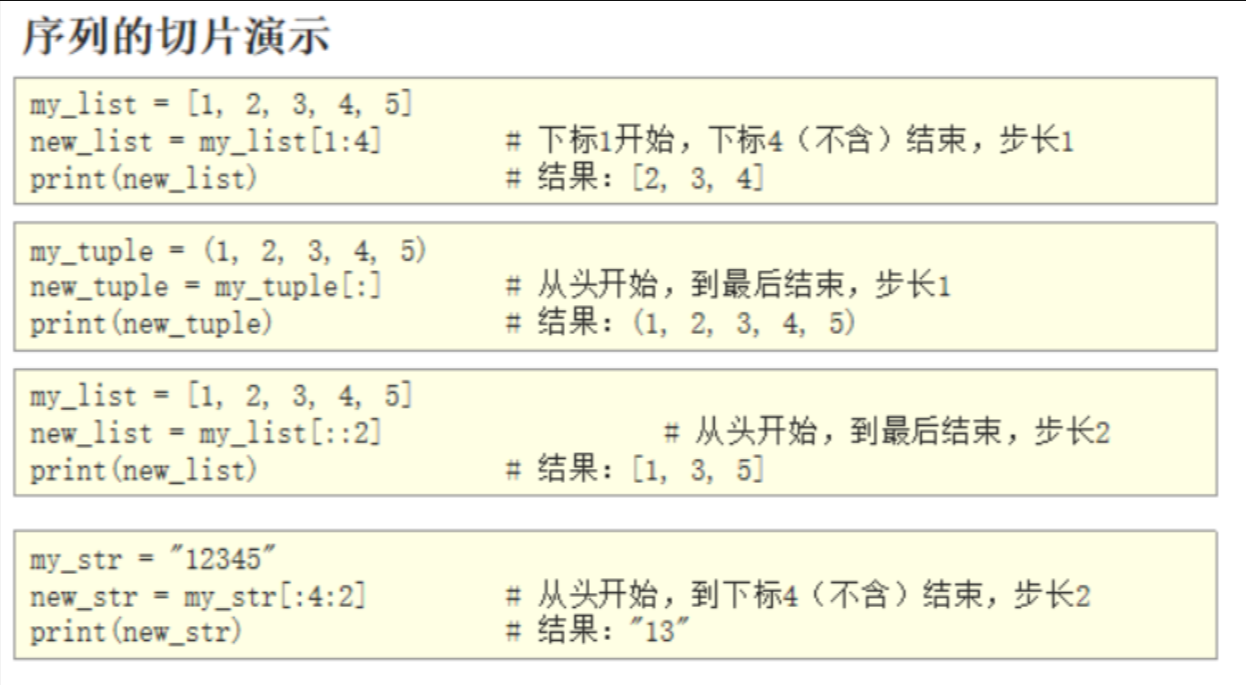
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示到何处结束,可以留空,留空视作截取到结尾
- 步长表示依次取元素的间隔
- 步长为负数表示反向取(注意,起始下标和结束下标也要反向标记)
6.5、set(集合)
基本语法:
1 # 定义集合字面量 2 {元素,元素,...,元素} 3 4 # 定义集合变量 5 变量名称 = {元素,元素,...,元素} 6 7 # 定义空集合 8 变量名称 = set()
集合的方法:

集合的特点:
相较于列表、元组、字符串来说,不支持元素的重复(自带去重功能),并且内容无序
6.6、dict(字典)
基本语法:
1 # 定义字典字面量 2 {key:value,key:value,...,key:value} 3 4 # 定义字典变量 5 变量名称 = {key:value,key:value,...,key:value} 6 7 # 定义空变量 8 变量名称 = {} 9 变量名称 = dict()
字典的操作:

字典的特点:
- 键值对的Key和Value可以是任意类型(Key不可为字典)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
- 字典不可用下标索引,而是通过Key检索Value
6.7、数据容器的通用操作
特点对比:
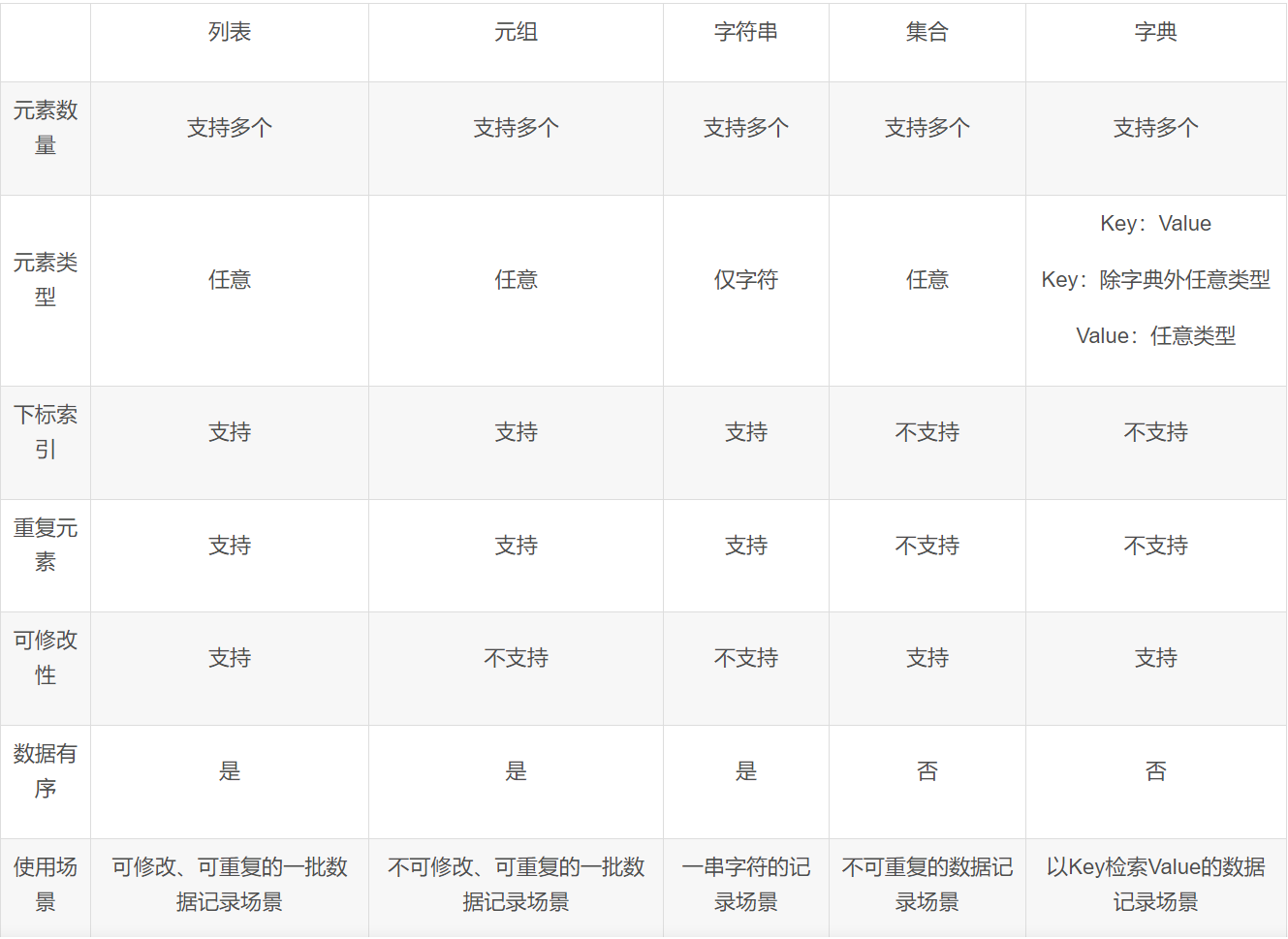
通用功能:

七、Python函数进阶
7.1、函数多返回值
1 def test_return(): 2 return 1,2 3 4 x, y = test_return() 5 print(x) # 结果:1 6 print(y) # 结果:2
按照返回值的顺序,写对应顺序的多个变量接收即可,变量之间用逗号隔开
7.2、函数多种传参方式
7.2.1、位置参数
调用函数时根据函数定义的参数位置来传递参数
1 def user_info(name,age,gender): 2 print(f'我的名字是{name},年龄是{age},性别是{gender}') 3 4 user_info('Tom',20,'男')
传递的参数和定义的参数的顺序及个数必须一致
7.2.2、关键字参数
函数调用时通过 “键=值” 形式来传递参数
1 def user_info(name,age,gender): 2 print(f'我的名字是{name},年龄是{age},性别是{gender}') 3 4 # 关键字传参 5 user_info(name='小明',age=20,gender='男') 6 # 可以不按照固定顺序 7 user_info(age=20,gender='男',name='小明') 8 # 可以和位置参数混用,位置参数必须在前,且匹配参数顺序 9 user_info('Tom',age=20,gender='男')
7.2.3、缺省参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
注意:所有位置参数必须出现在默认参数前,包括函数定义和调用
1 def user_info(name,age,gender='女'): 2 print(f'我的名字是{name},年龄是{age},性别是{gender}') 3 4 user_info('小李',22) 5 user_info('小李',22,'女')
函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值
7.2.4、不定长参数
不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
不定长参数的类型: ①位置传递 ②关键字传递
①位置传递
1 def user_info(*args): 2 print(args) 3 4 # ('Jack',) 5 user_info('Jack') 6 # ('Jack', 18) 7 user_info('Jack',18)
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),这就是位置传递
②关键字传递
1 def user_info(**kwargs): 2 print(kwargs) 3 4 # {'name': '小张', 'age': 20, 'gender': '男'} 5 user_info(name='小张',age=20,gender='男')
参数是“键=值”形式的形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典
7.2.5、函数作为参数传递
1 def test_func(compute): 2 result = compute(1,2) 3 print(result) 4 5 def compute(x,y): 6 return x + y 7 8 test_func(compute) # 结果:3
7.3、匿名函数
函数的定义中
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用
无名称的匿名函数,只可临时使用一次
匿名函数定义语法:
lambda 传入参数:函数体(一行代码)
- lambda 是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
- 函数体,就是函数的执行逻辑,注意只能写一行,无法写多行代码
1 def test_func(compute): 2 result = compute(1,2) 3 print(result) 4 5 test_func(lambda x,y: x+y) # 结果:3
八、Python文件操作
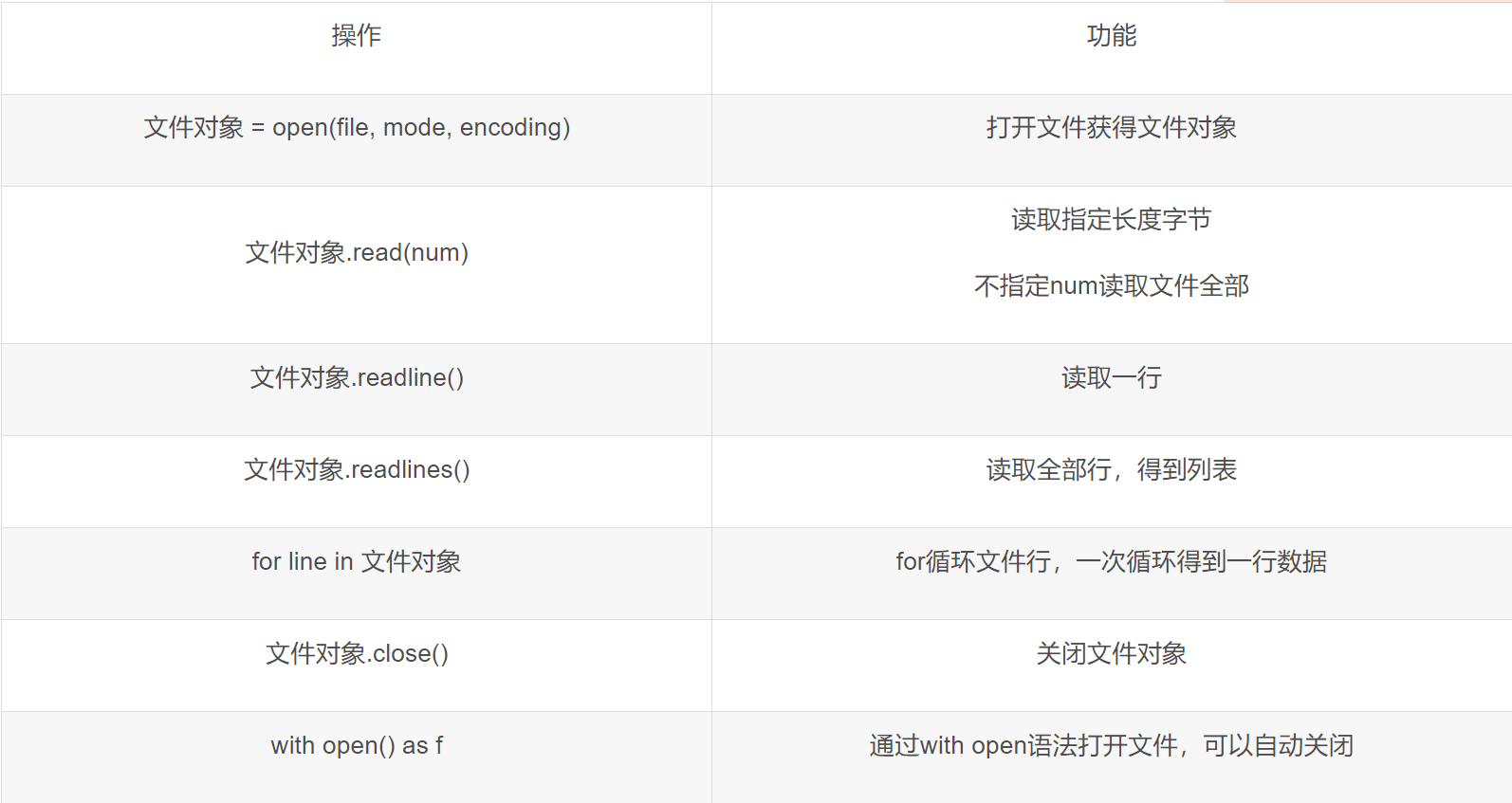
8.1、文件的读取
mode常用的三种基础访问模式:

8.2、文件的写入
1 # 1.打开文件 2 f = open('1.txt','w') 3 # 2.写入文件 4 f.write('Hello World') 5 # 3.内容刷新 6 f.flush()
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件,频繁的操作硬盘,会导致效率下降
九、Python异常、模块与包
9.1、异常的捕获
在可能发生异常的地方进行捕获,当异常出现的时候,提供解决方式,而不是任由其导致程序无法运行
1 try: 2 可能要发生异常的语句 3 except[异常 as 别名:] 4 出现异常的准备手段 5 [else:] 6 未出现异常时应做的事情 7 [finally:] 8 不管出不出现异常都会做的事情
异常的种类多种多样,如果想要不管什么类型的异常都能捕获到,那么使用:except Exception as e:
9.2、Python模块
模块(Module),是一个 Python 文件,以 .py 结尾,模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的导入方式:
1 [from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
自定义模块:
每个Python文件都可以作为一个模块,模块的名字就是文件的名字
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,但是在模块导入的时候都会自动执行`test`函数的调用
解决方案:
1 def test(a,b): 2 print(a + b) 3 4 # 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用 5 if __name__ == '__main__': 6 test(1,1)
如果一个模块文件中有`_ _all_ _`变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素
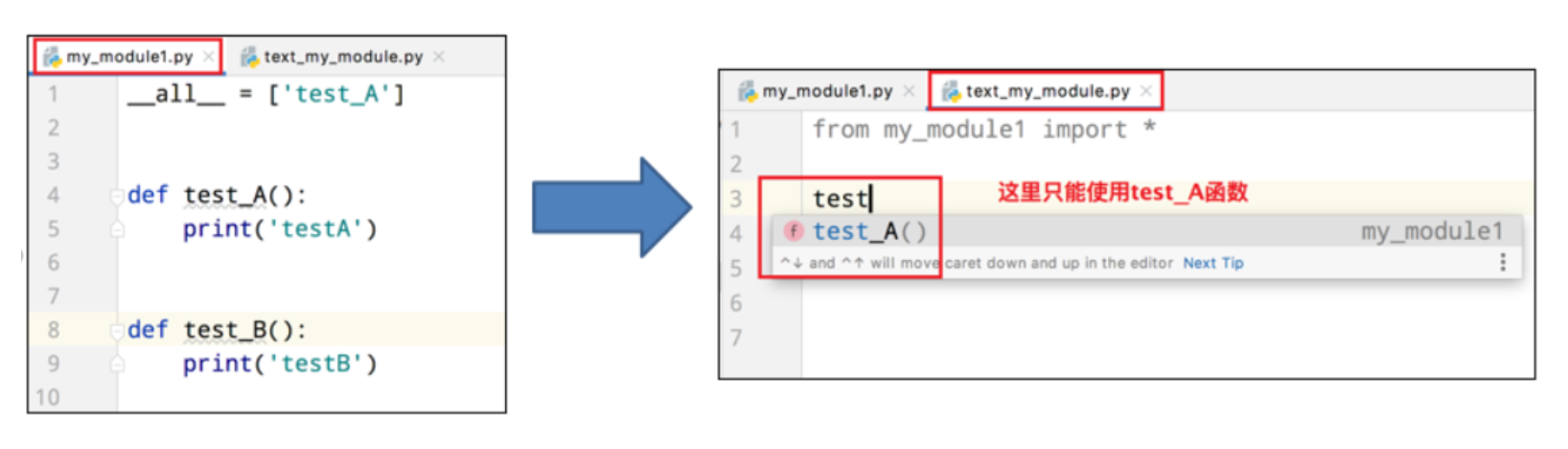
9.3、Python包
从物理上看,包就是一个文件夹,在该文件夹下自动创建了一个 _ _init_ _.py 文件,该文件夹可用于包含多个模块文件
从逻辑上看,包的本质依然是模块
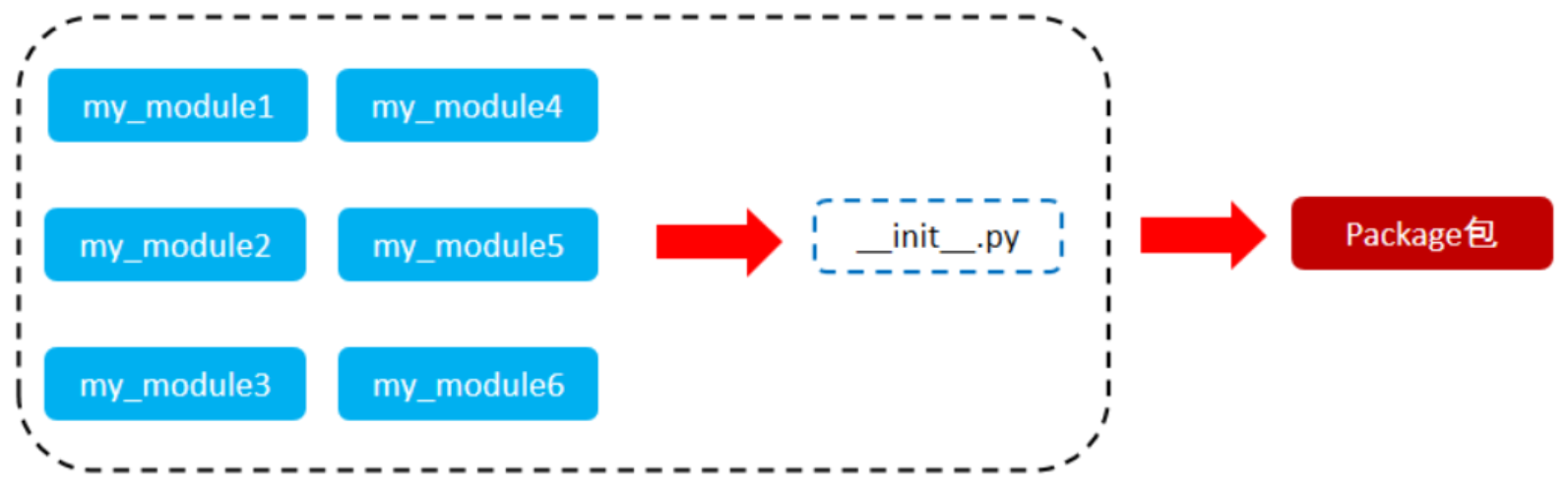
当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块
导入包:
1. import 包名.模块名 调用:包名.模块名.目标
2. from 包名 import * 必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表
十、面向对象
10.1、成员方法

在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法

方法和函数功能一样, 有传入参数、返回值,只是方法的使用格式不同:
1 # 函数的使用: 2 num = add(1,2) 3 # 方法的使用: 4 student = Student() 5 num = student.add(1,2)
在类中定义成员方法和定义函数基本一致,但仍有细微区别:
1 def 方法名(self,形参1,...,形参N): 2 方法体
可以看到,在方法定义的参数列表中,有一个:self关键字 ,它是成员方法定义的时候必须填写的,但是传参的时候可以忽略它
- 它用来表示类对象自身的意思
- 当我们使用类对象调用方法时,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
10.2、构造方法
基于类创建对象的语法:对象名 = 类名称()
Python类可以使用:_ _init_ _() 方法,称之为构造方法
在创建类对象(构造类)的时候,会自动执行,并将传入参数自动传递给__init__方法使用
1 class Student: 2 name = None 3 age = None 4 tel = None 5 6 def __init__(self,name,age,tel): 7 self.name = name 8 self.age = age 9 self.tel = tel 10 print("Student类创建了一个对象") 11 12 stu = Student("小李",24,"1352546")
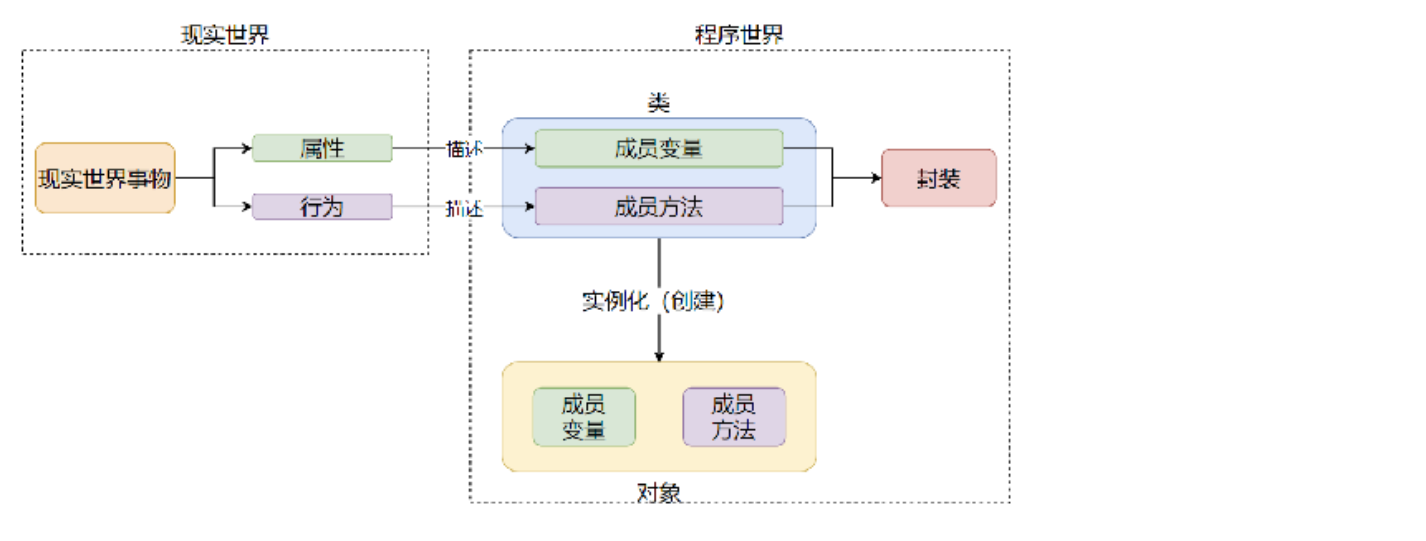
10.3、封装
面向对象编程,是基于模板(类)去创建实体(对象),使用对象完成功能开发
面向对象包含3大主要特性:封装 继承 多态
将现实世界事物在类中描述为属性和方法,即为封装
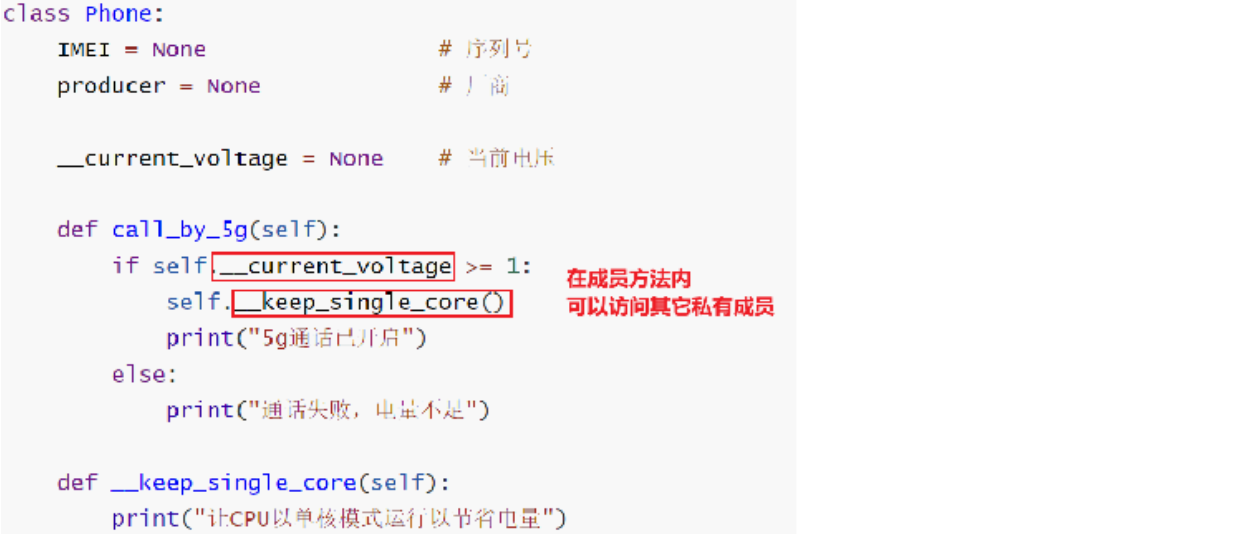
现实事物有部分属性和行为是不公开对使用者开放的,同样在类中描述属性和方法的时候也需要达到这个要求,就需要定义私有成员了
成员变量和成员方法的命名均以 _ _ 作为开头即可

私有成员无法被类对象使用,但是可以被其它的成员使用
10.4、继承
继承:将从父类那里继承(复制)来成员变量和成员方法(不含私有)
单继承:

多继承:
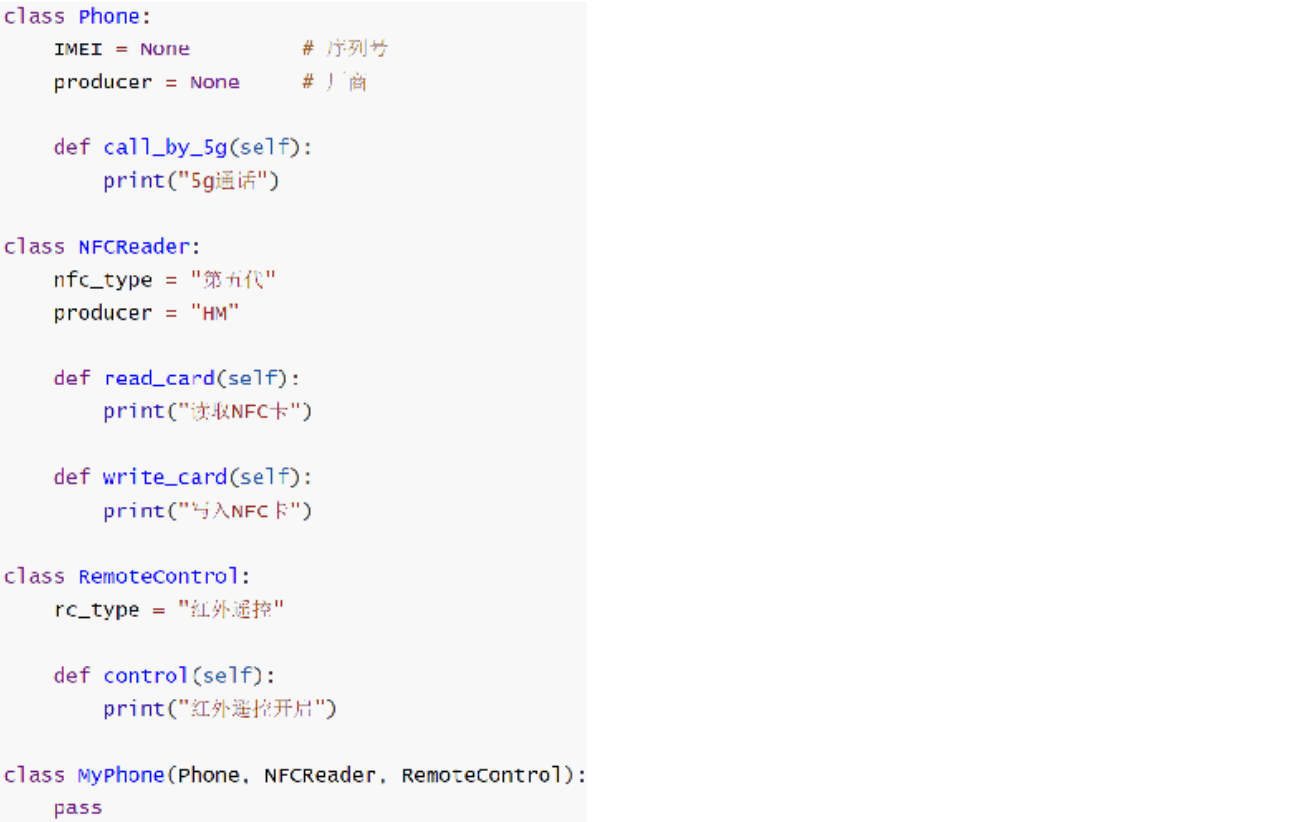
多个父类中,如果有同名的成员,那么默认以继承顺序(从左到右)为优先级
pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容、空的意思
复写:
子类继承父类的成员属性和成员方法后,如果对其“不满意”,那么可以进行复写。即在子类中重新定义同名的属性或方法即可

一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员
如果需要使用被复写的父类的成员,需要特殊的调用方式:
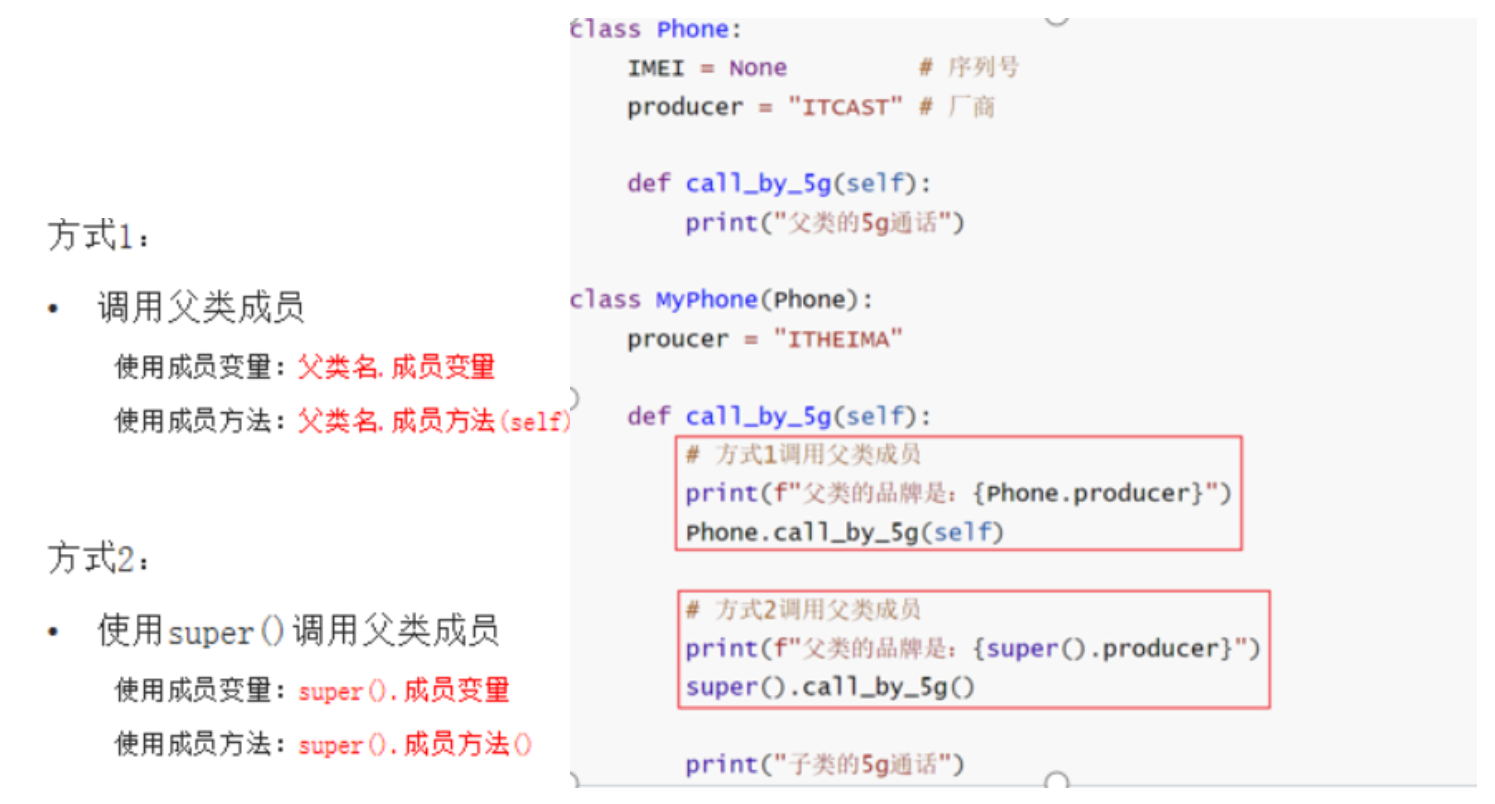
注意:只能在子类内调用父类的同名成员,子类的类对象直接调用会调用子类复写的成员
10.5、多态
多态:指的是完成某个行为时,使用不同的对象会得到不同的状态,多态常作用在继承关系上
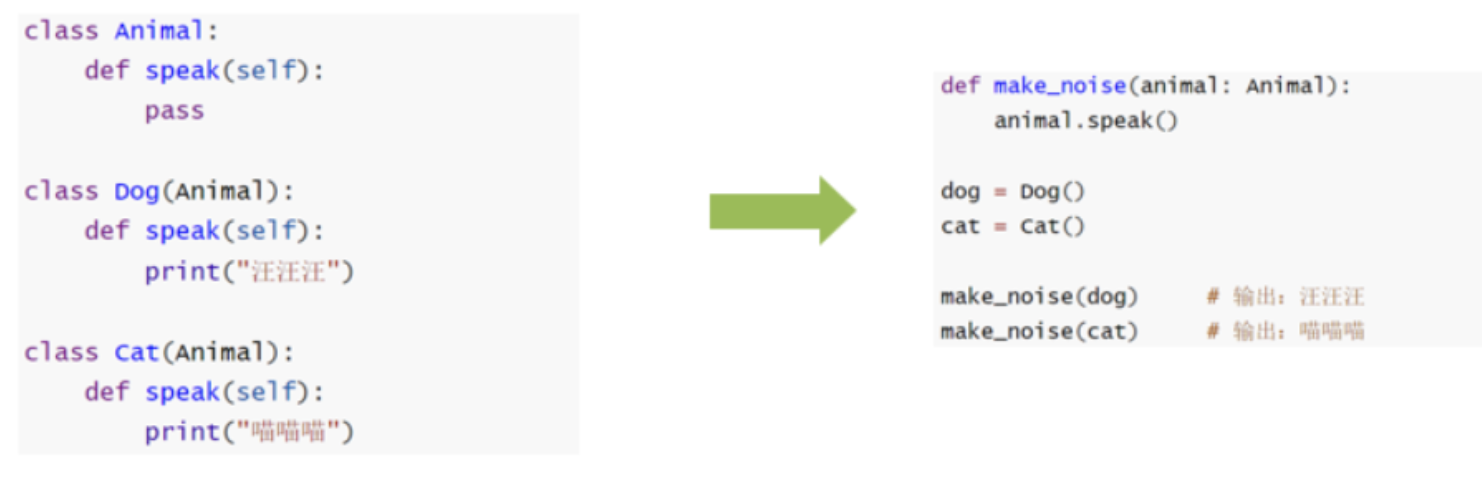
抽象类(接口):含有抽象方法的类称之为抽象类
抽象方法:方法体是空实现的(pass)称之为抽象方法
抽象类多用于做顶层设计(设计标准),以便子类做具体实现,要求子类必须复写(实现)父类的一些方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号